本文将探讨如何构建一种用于持续集成的架构,我们采用了由简至繁的方法。在每一次将架构复杂化时,我们会给出原先的简单方法的局限性,并验证添加架构的复杂性和/或重构架构是合理的。
本文所给出的终极方法,是Weaveworks探索出的最适合自身的方法。
持续交付
持续交付是以频繁且少量的方式而非一次性大批量的发布去生成软件的方法。
为什么持续交付很重要?将版本持续部署到应用会消除“发布日”的思维模式。理论上讲,版本的完成越是频繁,那么版本的风险也就越低。开发人员还可在代码就绪时更改应用(无论是实现新代码,或是回滚到旧版本)。这意味着可以更快地更改业务,进而使企业更具竞争力。
由于微服务间使用API互相通信,需要保证版本间在一定程度上的向后兼容性,以免必须在团队间做版本同步。
根据Conway定律,软件呈现了其所属企业的结构。因此,微服务和容器不仅体现了技术上的改进,也同等程度上体现了企业的改进。在将一个单体应用分解为微服务时,应使每个微服务可被独立的团队交付。
在本文中,我们将介绍如何使用Kubernetes实现持续交付。
Kubernetes概述
Kubernetes是一种管理容器化应用的容器编排器。正如我们先前所提及的,并不存在使用kubernetes实现持续交付的所谓正确方法。虽然实现持续交付对发布和自动化非常关键,但是Kubernetes并未对该问题提供一种解决方案。
(点击放大图像)
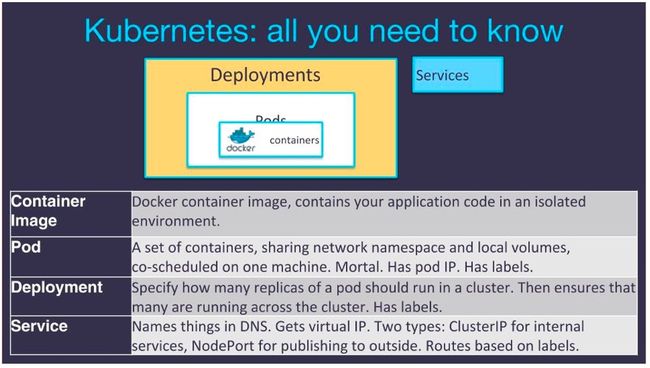
Kubernetes在平台中可创建和管理的最小单元称为Pod。我们从上面的结构图中可以看到,一个Pod中存在着一个Docker容器。Docker容器镜像将应用代码包括在一个隔离的环境中。
Pod是一系列在同一机器上一并调度的容器,它们共享同一网络命名空间。一个容器可与本机通信,并发现位于同一Pod中、绑定于任何端口上的其它容器。
在Google的Tim Hockin看来,Pod并非永生的。他所指的是,如果由于底层硬件故障等原因导致云端机器消失,那么Pod也会随之而消亡。针对Pod也会消亡这一事实,不应将重要服务置于Pod中运行,寄希望于机器不会消失。机器随时都可能会消失,尤其是在云环境中。
应采用的替代做法是将Pod包裹在部署中,由部署指定Pod的数量。例如,可以定义一个部署为具有一个Pod的三个实例,并且这些实例应保持运行。如果当前机器宕机了,部署会将这三个Pod实例置于新的机器上,在其它地方启动它们,并保持它们的运行。
Kubernetes集群是应用实际运行之处。
第一版架构
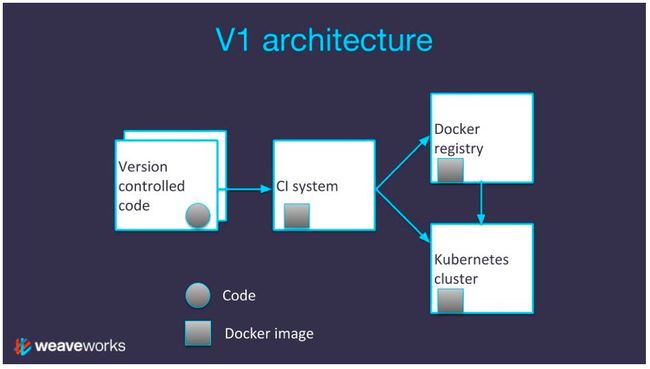
下面介绍第一种部署,也是最简单的一种部署。其中,受版本控制的代码将持续集成系统与Docker Registry联系起来,然后通过持续集成系统将最新的镜像手工部署到Kubernetes集群中。手工部署的命令为:
kubectl apply -f service.yaml
虽然在一开始时完全可以使用手动部署,但是此后的部署更新应实现持续集成系统的自动化。持续集成系统通过镜像标签更新Kubernetes,并将更新推送到Kubernetes API。这使得Kubernetes从Docker Registry上拉取(Pull)标签所指向的Docker镜像,并加以部署。
(点击放大图像)
更改的提交
在这样的架构中,如果开发人员使用git push在受版本控制的代码中做了一次更改,持续集成系统将自动完成一次Docker build。持续集成系统会对该Docker镜像做标签,标签所使用的SHA-1哈希对应于推送代码的SHA-1哈希,并赋予了唯一的名字。此后,持续集成系统会将镜像推送到Docker Registry。
Kubectl set image
持续集成系统将运行“kubectl set image”程序提交上述更改。kubectl set image会获取一个运行中的API对象,并告知Kubernetes使用特定的新标签更新持续集成系统。例如,用户可使用kubectl set image更改某个前端服务的当前镜像。
然后,Kubernetes会自动拉取回新的Docker镜像,并替换当前镜像。此外,用户也可以回滚更新,这是Kubernetes内建的一个特性。
实现回滚
只要新的更改被推送到Master分支,就会进而被推送到生产环境。
要回滚该更改,需要再做一次代码更改。开发人员需要从Master分支恢复最近一次提交。当存在合并(Merge)提交时,事情会略为复杂。在理想情况下,用户需重置回最近一次合并前的版本,然后强制推送新的更改。
在推送回滚后,需重构旧版本。持续集成系统将会运转起来,重构该新镜像,并推送新镜像到Docker Registry。该新镜像是旧镜像的一个新拷贝。
不足之处
这种架构方法存在一些不足之处。首先,容器的构建和推送可能会很慢。无论容器是否最大程度上使用了磁盘I/O和网络代码,构建和推送所用时间主要取决于容器中的内容。这对于做回滚是一个问题,因为最终用户为尽快解决问题,需要回滚快速完成。
其次,这种架构耦合紧密,不允许不同的环境(例如开发、试机和生产)处于不同的版本上。对于大多数用户而言,这无疑是一个问题。
下面,我们将尝试对第一版架构进行改进!
第二版架构
(点击放大图像)
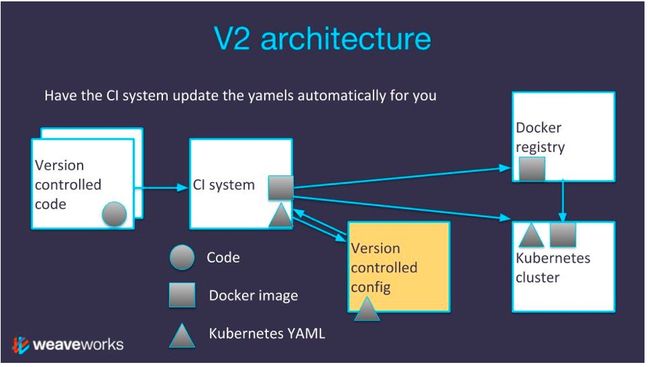
第二版架构是基于第一版的初始架构而构建的,它引入了一个理念,即让版本控制配置独立于其余的应用代码版本库(Repo)。这可使用户将版本控制配置作为整个应用的单一数据源(SSOT,Single Source Of Truth),这表示应用是由所有的微服务组成的。
一种做法是让用户服务和具有这些服务代码的订购服务毗邻于它们的Kubernetes YAML。相对于这种做法,更好的做法是拉取所有这些Kubernetes YAML到一个称为“配置版本库”的集中代码版本库中。
这一点很重要,因为这使得集群被破坏后,用户可从版本控制重构整个集群。现在,如果有人意外地删除了生产集群,该版本控制配置的版本库是恢复应用所唯一必须的。
第二版架构新引入了这样的配置版本库,因此持续集成系统需要多做一些工作。此外,第二版架构与第一版是相同的。
更改的提交
那么在提交了代码更改后,在架构上发生了什么?
持续集成系统会构建一个新的容器镜像,然后持续集成系统(根据代码版本库的响应执行操作)会将更改推送到Docker Register。持续集成系统克隆(Clone)配置版本库的最近版本,对Kubernetes YAML应用更改。之后,持续集成系统将更改部署到Kubernetes集群。最后,Kubernetes集群将镜像从Docker Registry拉取下来。
不足之处
正如我们在前面所提及的,现在大量的工作由持续集成所承担。最好是让架构的每一部分只去做好一件事情,而不是让架构中的某一部分承担了大部分的负担。
其次,对代码的推送依然是触发持续集成系统的唯一可能途径。最好是无需推送代码就可实现回滚。在这个实例中直接使用kubectl做带外(Out of Band)回滚,这意味着开发人员必须手工更新中央配置版本库。这使得该版本库不再是SSOT。
第三版架构
(点击放大图像)
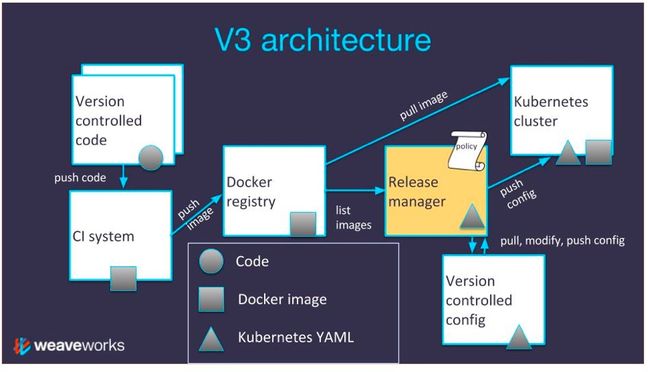
我们已经在第二版架构中实现了如上的复杂性,最好是再进一步添加版本管理器。Weaveworks团队所使用的版本管理器称为Weave Flux,它是一个完全开源的版本管理软件,也是Weave Cloud的一个组成部分。虽然还有Spinnaker等其它类似的产品,但是相比于Spinnaker,Weave Flux在设计上要更为简洁,并且是专门针对容器设计的。
加入版本管理器会进一步地简化架构,它使得每个架构元素只具有单一的职责。软件管理器的作用是观察新容器何时出现在Registry中,进而克隆被版本控制的配置,修改该配置,并将配置推送回版本库以记录下所产生的版本。同时,它还会推送新配置到Kubernetes集群。
更改的提交
现在,持续集成系统已经可以将被版本控制的代码自动构建到容器镜像中,并推送容器镜像到Docker Registry。
版本控制器从配置版本库中拉取Kubernetes YAML并修改它们,并将修改后的版本推送到集群中。之后,Kubernetes拉取回Docker Registry的最近版本。
在上图中,在版本管理器上有一个“纸卷形”的图标,表示了用于不同环境的各种策略。其中,用于试机的策略,可在任何时候发布;用于生产的策略,可使用版本管理器GUI上的按钮手工提交版本。这样,单个微服务版本库和所要发布的策略间不再是紧耦合的。
回滚
在第三版架构中实现回滚非常简单。用户只需告知版本管理器要回滚到最近的版本,其中不需要持续集成系统的任何参与。现在由版本管理器实现对配置的更改。
总结
使用Kubernetes实现持续交付可以很简单,也可以很复杂。微服务应用越是复杂,就越可能需要复杂的架构。虽然实现持续集成并不存在所谓的错误路线,但重要的是实现自动化,建立SSOT,并且有效地实现无需推送新代码更改的回滚。
文章来源:http://www.infoq.com