减少Docker和Kubernetes中的JVM内存占用
##前言
本文记录了如何在 Kubernetes[1] 上减小 JVM 应用容器占用的内存:哪些 JVM 标记更重要,如何正确设置以及如何测量参数对应用内存占用的影响。故事从一个工作中的问题开始。笔者为 Wix[2] 工作,作为数据流团队的一员负责所有的 Kafka[3] 基础设施。最近安排的任务是为 Node.js[4] 服务建立一个 Kafka 客户端代理。
0 问题:Kafka 客户端 sidecar 内存泄漏
笔者的想法是将所有与 Kafka 相关的(生产和消费)操作从一个 Node.js 应用委托给一个独立的 JVM 应用。这种安排是为了适应我司的 Kafka 基础设施 — 客户端greyhound 采用 Scala 开发(开源版本[5])。
借助 sidecar 应用,Scala 代码不需要用其他语言重写,只需要一层薄薄的封装即可。

在生产环境部署 sidecar 后,立刻注意到内存占用飙升:

内存使用统计 — container_memory_working_set_bytes
从上面的表格可以看出,单是 sidecar 占用的内存已经达到了 node 应用容器的4到5倍。这里 sidecar 基于 openjdk 8 运行,统计时包含了 kafka 库。于是开始着手分析原因以及如何减少内存占用。
1 用生产数据实验
创建一个测试程序模仿该 node 应用的 sidecar,以便在不影响生产的前提下进行试验。测试应用包含了相同生产主题(production topic)的所有消费者。
通过将应用的 mxbeans[6] 暴露给 Prometheus[7]/Grafana[8],可以用 heapMemoryUsed 和 nonHeapMemoryUsed 监控内存占用。当然,也可以用 jconsole[9] 或 jvisualvm[10] (JDK8或更高版本默认提供)。
首先试着梳理每个消费者、生产者以及 gRPC[11] 客户端的影响。gRPC 客户端负责调用 node 应用。初步结论:增加或减少单个消费者不会对内存占用有显著影响。
2 JVM 堆标记
接着把注意力转向堆内存分配。有两个重要的 JVM 标志与堆分配有关:-Xms (启动时堆内存大小)和 -Xmx (最大堆内存)。尝试各种不同的组合并记录容器的内存使用情况。

使用不同堆标记时, 容器占用的总内存
结论一:当 Xmx 大于 Xms 时,如果某个应用使用的内存增大,分配的内存堆几乎肯定会达到 Xmx 的限制,导致容器总内存占用增大(参见下图比较)。

Xmx >> Xms
如果设置 Xmx 等于 Xms,由于堆内存大小不会随时间变化增大,从而可以更好地控制内存总量(参见下图比较)。
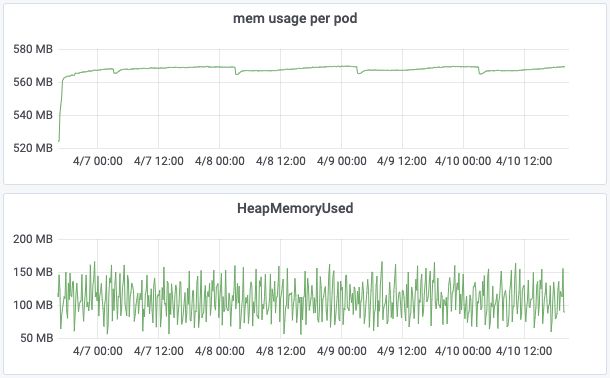
Xmx = Xms
结论二:只要一段时间内 GC 引发的 JVM 暂停时间不超过500ms,就可以放心减小 Xmx。这里使用 Grafana 监视 GC,也可以使用 visualgc[12] 或 gceasy.io[13]。
由 GC 引发的良性 JVM 暂停时间
设置 Xmx 时请注意:如果应用的消息吞吐量变化显著,那么每当有大量消息传入时,应用更容易受到 GC 风暴影响。
3 Kafka 相关调整
Greyhound (Kafka) 消费者有一个内部消息缓冲区可存储200条消息。当缓存消息最大值设为20时,可以注意到堆内存波动范围比 size=200 时更小(总体使用率更低):

bufferMax=200 堆内存使用情况

bufferMax=20 堆内存使用情况
当然,减少缓冲区意味着应用不能更好地处理突发情况。该方案不适合高吞吐量应用。为了弥补这个缺陷,可以将每个 pod 的 greyhound 消费者处理程序的并行性提高一倍,即把处理 Kafka 消息的线程从3个增加到6个。在发生异常情况下,要么为应用增加 prod,要么修改最大缓冲区配置。
把 Kafka 消费者 fetch.max.bytes (总查询消息大小) 从50M减少到5M对内存占用没有显著影响。从 sidecar 应用中提取 greyhound producer 得到的效果一样(这样可以在 DaemonSet 上驻留,从而在 K8s 节点上运行)。
4 减少内存有用的方法
优化后占用内存从 1000M 减少到 500-600M。下面这些有助于减少内存占用:
-
堆分配大小保持一致:
-Xms等于-Xmx; -
减少垃圾数量,例如 减少 Kafka 消息数量;
-
利用 GC: 只要 GC 性能(新生代+老年代)没有显著降低(0.25% CPU时间),可以一直减小
xmx。
哪些行动不会带来(实质性)帮助:
-
减少 KafkaConsumer 的 fetch.max.bytes;
-
移除 Kafka producer;
-
从 gRPC 客户端切换为 Wix 自定义 json-RPC 客户端。
5 接下来的工作
-
调查 GraalVM 本地镜像[14]是否有助于减少内存;
-
比较不同的 GC 实现 (本文使用了 CMS[15],还可以尝试 G1[16]);
-
切换到基于 ZIO[17] 的 greyhound 开源版本减少使用的 Kafka 线程数量;
-
减少每个线程分配的内存(默认每个线程分配1MB)。
笔者会在接下来的文章中记录更多改进。
参考资料
-
Docker 内存资源限制与 Java 堆[18]
-
Java 进程的内存占用[19]