Spring Cloud Data Flow 初尝试
文章目录
- Spring Cloud Data Flow 初尝试
- 安装Spring Cloud Data Flow
- Create Task
- Create Stream
- 参考
Spring Cloud Data Flow 初尝试
安装Spring Cloud Data Flow
在Spring Cloud Data Flow文档中介绍了几种在本地安装Spring Cloud Data Flow的方式。
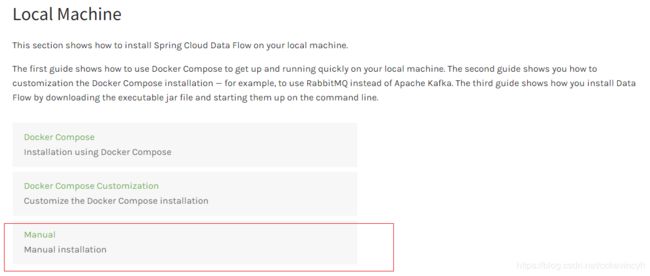
参考:https://dataflow.spring.io/docs/installation/local/
我们这里就尝试使用最后一种方式在本地进行安装。
根据文档上的要求,我们下载好如下的jar包。
![]()
然后我们用如下的命令启动:
start java -jar spring-cloud-dataflow-server-2.5.3.RELEASE.jar
start java -jar spring-cloud-skipper-server-2.4.3.RELEASE.jar
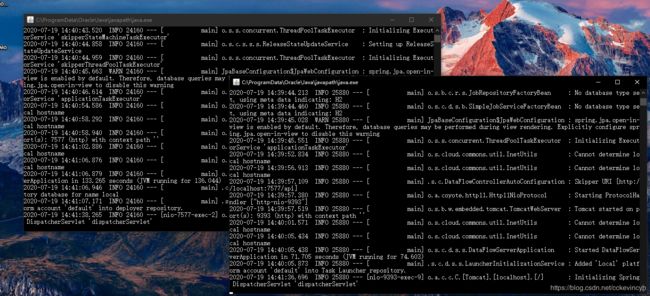
然后我们通过下面的url就可以访问到Spring Cloud Data Flow的dashboard页面了。
http://localhost:9393/dashboard
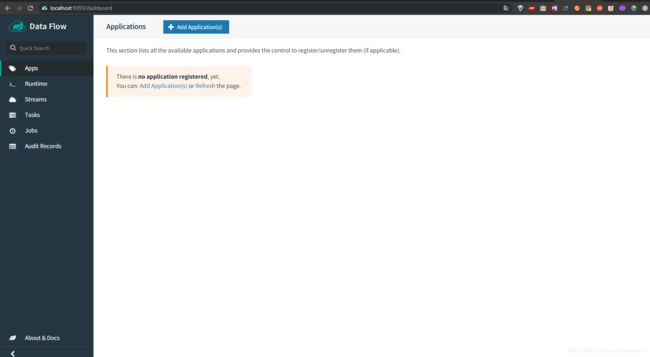
Create Task
然后我们点击左边的菜单栏的Apps,然后我们点击添加application
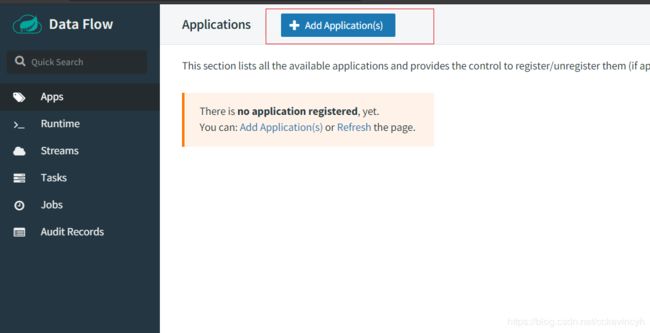
这里展示了几种添加application的方式
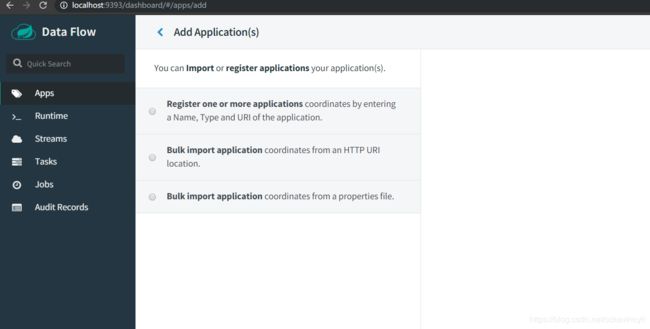
之后我们可以看到如下的页面。然后我们选择第二种方式,并且选择Task Apps(Maven)

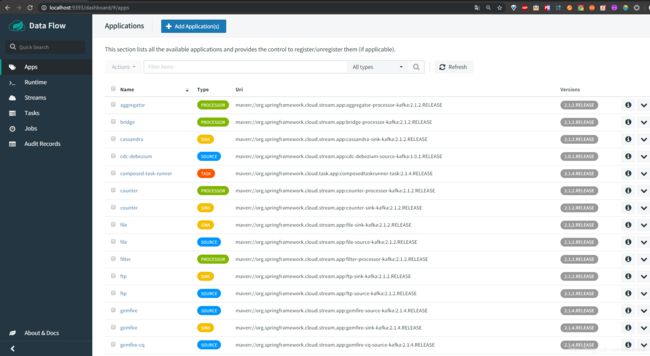
导入完成之后我们可以看到如下页面,上面有一些之前就注册在上面的Task
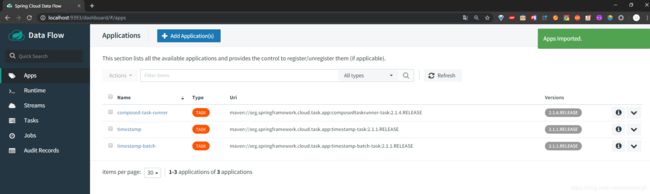
接下来我们点击左边菜单栏的Tasks,然后我们点击Create Tasks的按钮
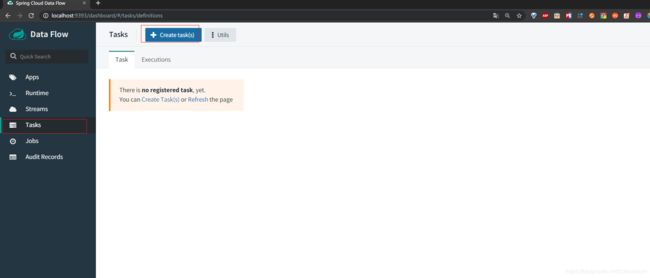
我们来创建一个Task,可以选择之前已经存在的Task,我们就选择timestamp这个Task
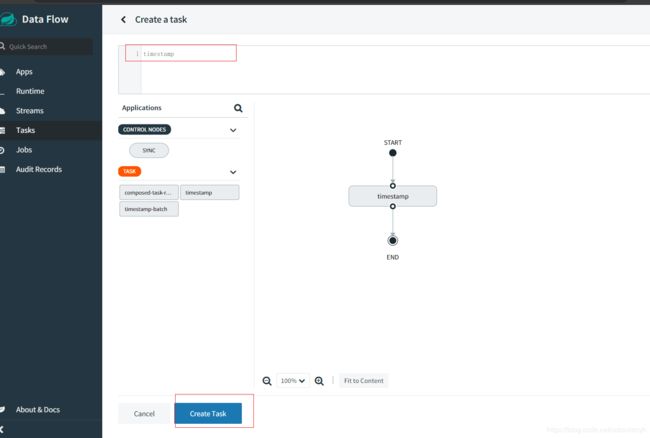
点击Create Task,并给task命名
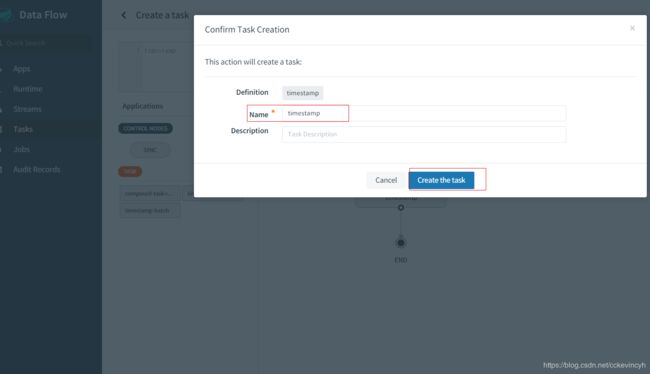
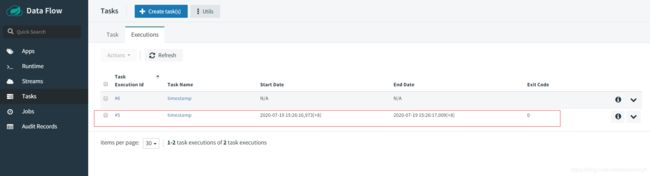
创建完成之后我们就可以看到我们的task显示如下
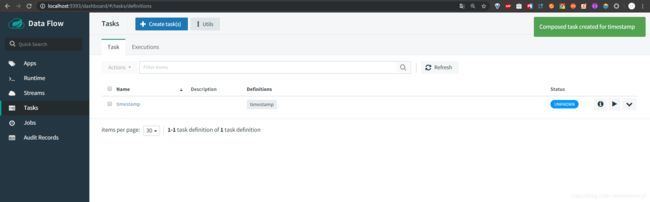
然后我们就可以点击启动按钮去启动我们的task

然后我们点击启动task
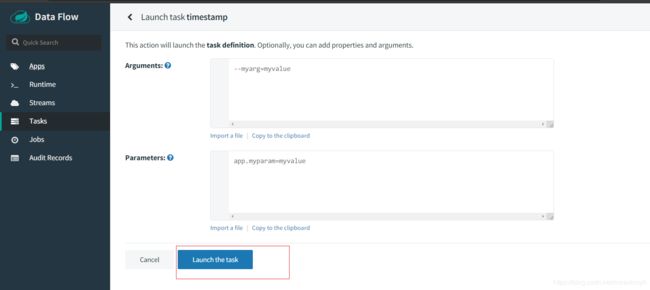
等待task执行
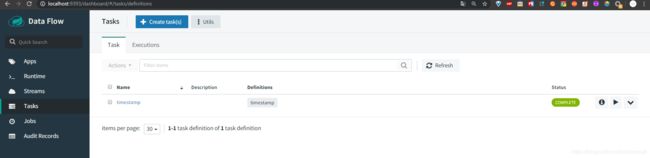
然后我们还可以查看task的detail信息,可以看到他启动的logs
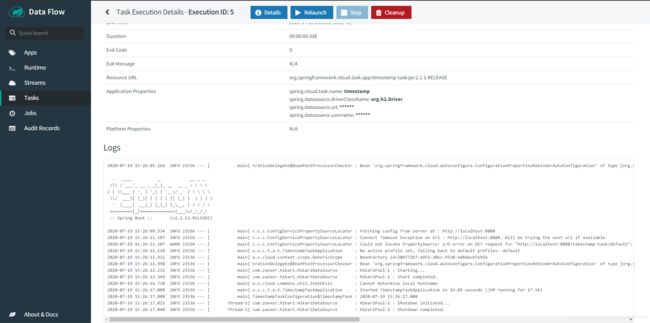
最后等到task执行完毕之后,我们还可以看到他的启动时间和结束时间
Create Stream
在此之前我们需要安装Kafka还有zookeeper。安装的步骤这里就不多介绍了。可以参考:
WINDOWS上KAFKA运行环境安装
然后启动好我们的zookeeper还有kafka。
接下来我们点击左边菜单栏的Apps,然后选择第二项,还有选择Stream Apps(Kafka/Maven),点击导入
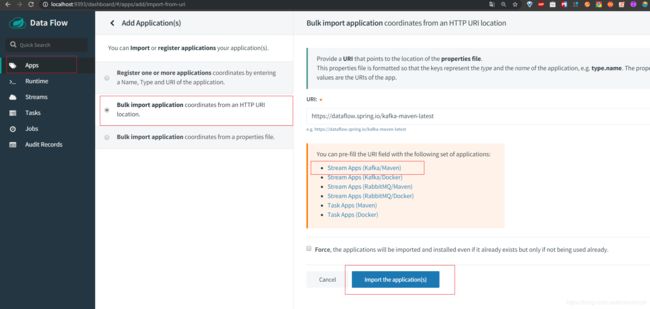
之后就可以看到如下的页面
然后我们点击左边菜单栏的Streams,然后我们创建一个Stream
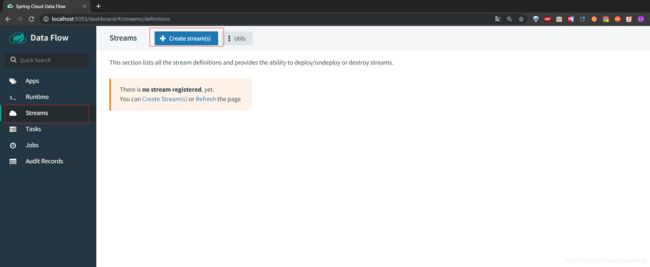
我们想要的目的就是读取一个input file 输出到 output file中,所以我们创建了如下的流程。
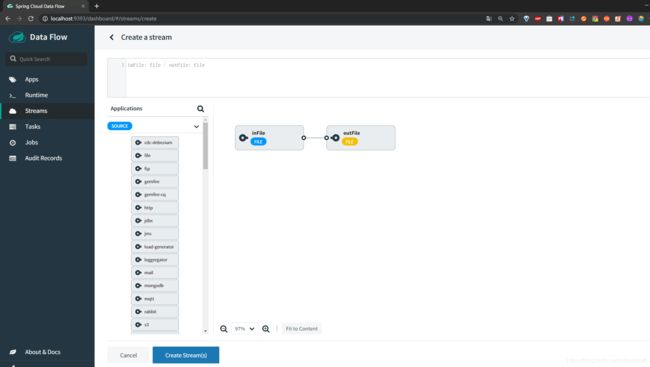
然后我们给我们的stream命名
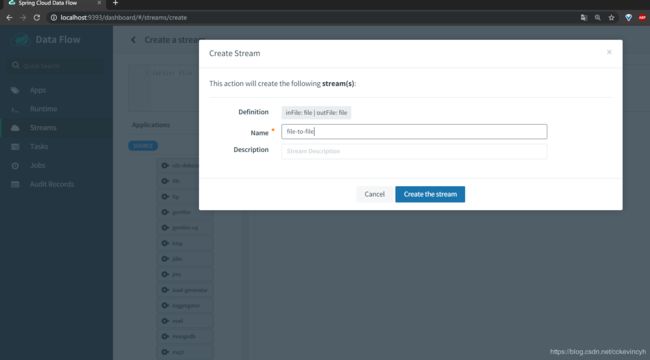
点击创建完毕之后就可以看到如下的页面

然后我们点击deploy

然后加上一些配置信息
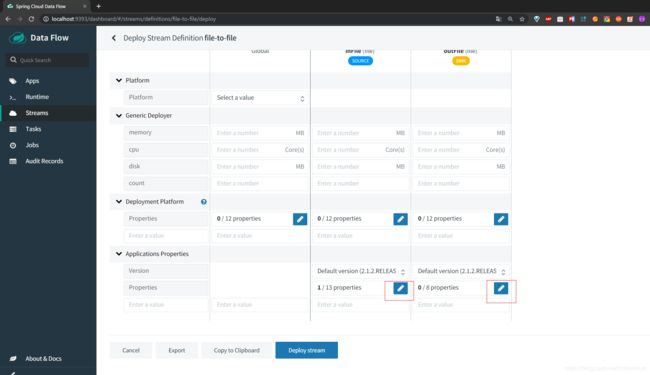
分别给inFile和outFile添加对应的输入和输出的目录

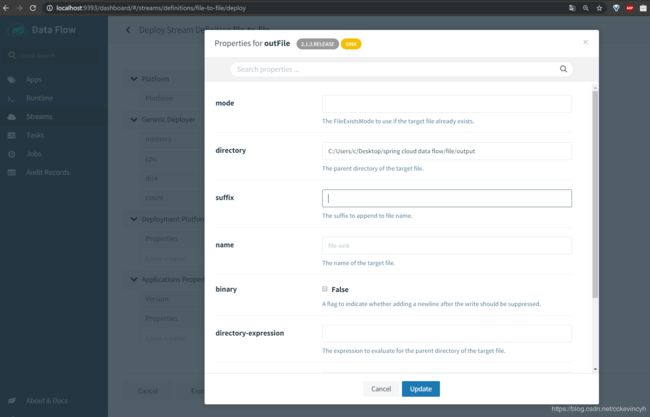
填写完毕之后我们就可以点击Deploy Stream了
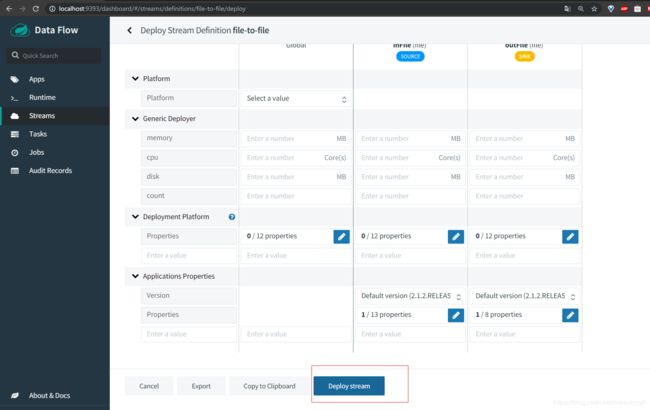
然后我们就可以看到如下的界面
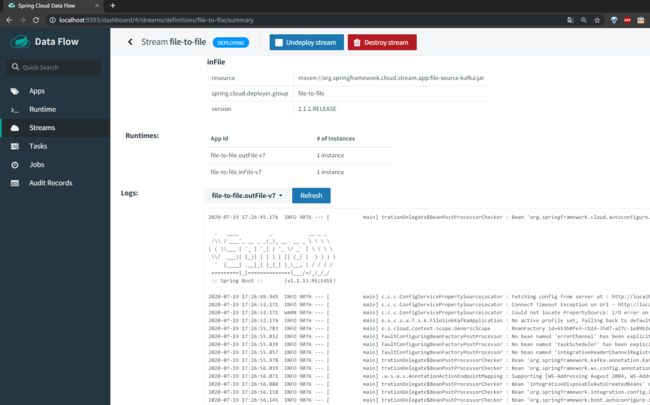
还可以查看detail的信息
可以查看到运行的日志信息
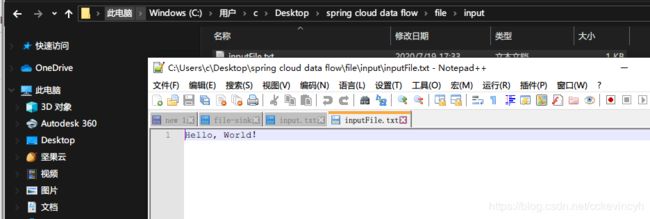
最后我们在input的目录下添加一个inputFile.txt,输入Hello, World!,保存之后我们去看看output的路径。
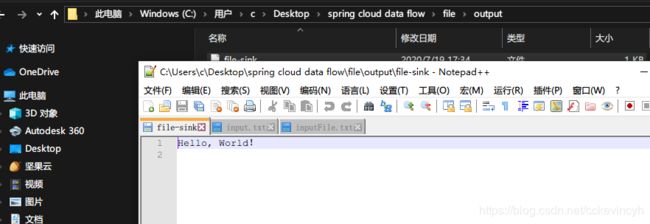
在output的路径中,我们可以看到新生成了一个文件,打开之后我们可以看到里面的内容就是Hello, World!
接下来我们来create一个http stream,把一个http stream输出到file中。
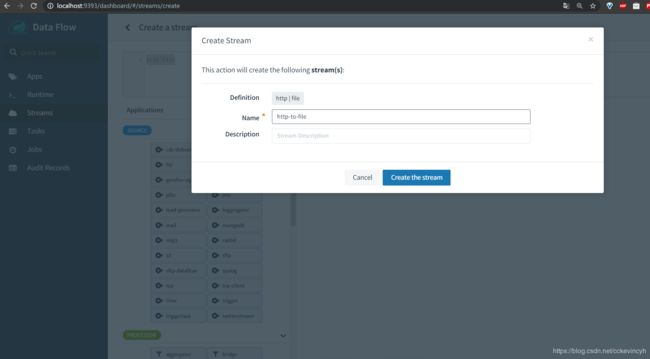
还是一样我们create stream

然后命名为http-to-file
接下来我们进行deploy

配置监听的端口
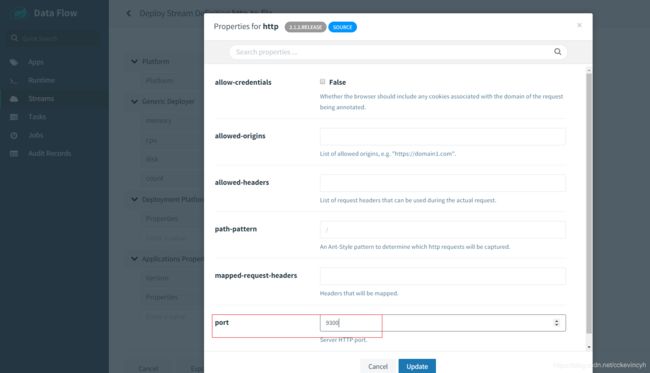
配置输出的文件路径
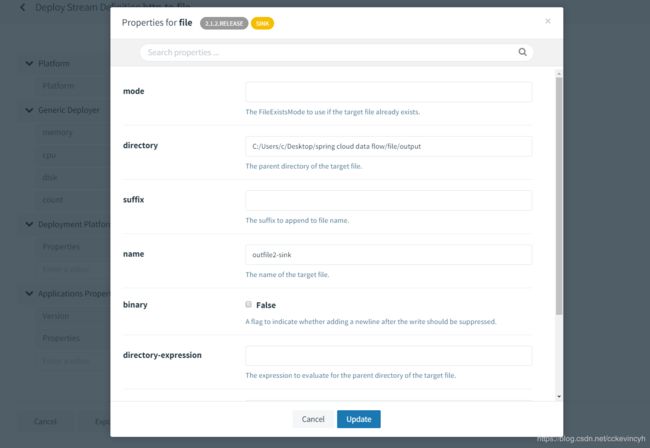
然后通过如下命令发送输出到指定端口
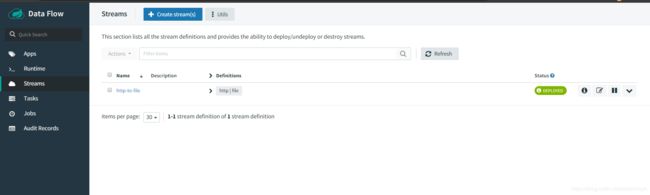
curl --data "DATA1,DATA2,DATA3" -H "Content-Type:text/plain" http://localhost:9300/
然后查看输出的文件路径,就可以看到生成了文件,内容也是显示我们上面输入的数据

参考
Introduction to Spring cloud data flow in 15 minutes