《深入浅出Vue.js》读书笔记
文章目录
- Object的变化侦测
- 如何追踪变化?
- 如何收集依赖?
- 依赖收集在哪里
- 依赖是谁
- `Watcher`是什么
- 如何侦测所有属性
- 总结
- Array的变化侦测
- 如何追踪变化
- 拦截器是什么
- 使用拦截器覆盖Array原型
- 如何收集数组的依赖
- 在哪里那保存数组的依赖
- 收集依赖
- 在拦截器中获取Observer实例
- 侦测数组成员的变化
- 侦测数组新增成员的变化
- 数组的限制
- 总结
- 变化侦测的API实现原理
- `vm.$watch`
- `expOrFn`支持函数的改造
- `watch`的实现
- Watcher的`teardown`方法
- `deep`参数的实现原理
- `vm.$set`
- `target`是数组
- `key`已经存在于`target`
- 新增属性
- `vm.$delete`
- 虚拟DOM
- 为什么要引入虚拟DOM
- Vue中的虚拟DOM
- VNode
- 注释节点
- 文本节点
- 克隆节点
- 元素节点
- 组件节点
- 函数式组件
- patch
- 创建节点
- 删除节点
- 更新节点
- 静态节点
- 新虚拟节点有文本属性
- 新虚拟节点无文本属性
- 更新子节点
- 更新策略
- 优化策略
- 判断节点是否被处理过
- `key`
- 模板编译原理
- 解析器
- 优化器
- 代码生成器
- 解析器
- 解析器内部运行原理
- HTML解析器
- 截取开始标签
- 截取结束标签
- 截取注释
- 截取条件注释
- 截取文本
- 纯文本内容元素的处理
- 整体逻辑
- 文本解析器
- 第十章 优化器
- 找出静态节点并标记
- 找出静态根节点并标记
- 第十一章 代码生成器
- 通过AST生成代码字符串
- 代码生成器的原理
- 生成元素节点
- 生成文本节点
- 生成注释节点
- 第十二章 架构设计
- 第十三章 实例方法与全局API
- 实例方法
- `$on`方法
- `$off`方法
- `$once`方法
- `$emit`方法
- 生命周期方法
- `$forceUpdate`
- `$destory`
- `$nextTick()`
- (1)Vue异步更新
- (2)`$nextTick()`默认使用微任务
- (3)宏任务是可选方案
- (4)返回Promise
- (5)2.6+的更新
- `$mount()`
- 完整版本功能
- 运行时版本功能
- 全局API的原理
- `Vue.extend`
- `Vue.directive`
- `Vue.use`
- `Vue.mixin`
- 生命周期
- 4个阶段
- `new Vue()`发生了什么
- `callHook`函数
- 错误处理
- 初始化实例属性
- 初始化事件
- 初始化Inject
- 初始化状态
- 初始化Props
- 初始化Methods
- 初始化Data
- 初始化Computed
- 新版本计算属性的实现
- 初始化Watcher
- 初始化Provide
- 指令的秘密
- 指令的原理
- `v-if`的原理
- `v-for`的原理
- `v-on`指令
- 自定义指令的实现
- 虚拟DOM钩子函数
- 过滤器的奥秘
- 过滤器的用法
- 过滤器原理
- `resolveFilter`的原理
- 解析过滤器
- 最佳实践
- 添加`key`
- 路由切换组件不变的情况
- 区分Vuex与Props的使用边界
- 避免`v-for`与`v-if`同时使用
- 列表中的某些元素不需要展示
- 隐藏整个列表
Object的变化侦测
Vue中一个状态的依赖不再是具体的DOM节点,而是一个组件。当状态变化后,会通知到组件,组件内部再使用虚拟DOM进行比对。这样可以大大降低依赖数量,从而降低依赖追踪所消耗的内存。
逐步回答下列问题:
如何追踪变化?
使用Object.defineProperty劫持对象的get和set属性,封装成为defineReactive(data, key, value)这样一个函数
如何收集依赖?
在getter中收集依赖,在setter中触发更新
依赖收集在哪里
首先将依赖保存在一个全局变量上(比如window.target),然后用一个数组来保存收集的依赖。
上述代码封装为Dep类,专门用来管理依赖,它包括addSub、removeSub、depend、notify方法。
Dep会在defineReactive中实例化,在get中depend,在set中notify
class Dep {
constructor() {
this.subs = [];
}
addSub(sub) {
this.subs.push(sub);
}
removeSub(sub) {
if (this.subs.length > 0) {
const index = this.subs.indexOf(sub);
if (index > -1) {
}
}
}
depend() {
if (window.target) {
this.addSub(window.target);
}
}
notify() {
const subs = this.subs.slice();
for (let i = 0; i < subs.length; i++) {
subs[i].update();
}
}
}
依赖是谁
Watcher类,它是抽象出来,用来集中处理各种情况的类。依赖收集阶段只收集这个封装好的类的实例,通知只通知它一个,再由他通知其他地方。
Watcher是什么
Watcher的实现非常巧妙,需要结合代码体会:
class Watcher {
constructor(vm, expOrFn, cb) {
this.vm = vm;
this.cb = cb;
this.getter = parsePath(expOrFn);
this.value = this.get();
}
get() {
window.target = this;
this.value = this.getter.call(this.vm, this.vm);
window.target = undefined;
return this.value;
}
update() {
const oldValue = this.value;
this.value = this.get();
this.cb.call(this.vm, this.value, oldValue);
}
}
(1)在构造方法中,把parsePath的返回值赋值给getter,parsePath的返回值是一个函数,给这个函数传入一个对象,就可以访问这个对象在对应的expOrFn路径下的属性值
(2)在构造方法中,调用get为value赋值,get方法中,将Watcher实例赋值给window.target,然后通过调用上一步的getter方法,获取对象在expOrFn路径下的属性值,并将属性值赋给value。
(3)在读取这个属性值(expOrFn)的时候,会触发属性值的getter,在getter中我们会将window.target收集到依赖dep中,此时window.target已经是watcher实例了,这样就将watcher实例收集到依赖中
(4)update方法是在Dep中的notify方法中被调用的,用来触发Watcher中真正要执行的方法
要注意,在执行new Vue()的时候,会执行一系列的操作并渲染组件到视图上,其中就包括vm._watcher的少处理。在Vue2.0开始,变化侦测的粒度是中等粒度,只会发送通知大搜组件级别,然后组件使用虚拟DOM进行重新渲染。
组件就是一个Vue实例,在实例上的_watcher属性,会监听组件中用到的所有状态,即这个组件内永达so的所有状态的依赖列表都会收集到vm._watcher中。
如何侦测所有属性
上面只能侦测单个属性 ,所以封装了Observer类来递归侦测数据所有的属性(包括子属性),将所有的属性都转换为getter/setter的形式,追踪其变化
class Observer {
constructor(value) {
this.value = value;
if (!Array.isArray(value)) {
// 遍历所有属性
this.walk(value);
}
}
walk(value) {
const keys = Object.keys(value);
for (let i = 0; i < keys.length; i++) {
defineReactive(value, keys[i], value[keys[i]]);
}
}
}
const defineReactive = (data, key, value) => {
// 递归子属性
if (typeof value === 'object') {
new Observer(value);
}
let dep = new Dep();
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get() {
dep.depend();
return value;
},
set(newVal) {
if (newVal === value) {
return;
}
value = newVal;
dep.notify();
}
});
};
总结
(1)通过封装Object.defineProperty方法得到的defineReactive函数来劫持属性的getter和setter,在getter中收集依赖,在setter中触发依赖更新
(2)Dep类用来收集和管理依赖,在getter中depned,在setter中notify
(3)Watcher类就是收集的依赖,实际上是一个订阅器,Watcher会将自己的实例赋值给window.target(全局变量)上,然后去主动访问属性,触发属性的getter,将window.target收集到Dep中,Watcher的update方法会在Dep的notify方法中被调用,触发更新
(4)Obersver类用来将一个对象的所有属性和子属性都变成响应式的,通过递归调用defineReactive来实现
Array的变化侦测
如何追踪变化
使用拦截器,拦截数组可以改变自身的方法,覆盖Array.prototype
拦截器是什么
拦截器要具能够实现原生数组方法的功能,但是提供机会让我们可以插入一些操作:
const arrayProto = Array.prototype;
const arrayMethods = Object.create(arrayProto)
['push', 'pop', 'shift', 'unshift', 'reverse', 'sort', 'splice'].forEach((method) => {
// 缓存原始方法
const original = arrayProto[method];
Object.defineProperty(arrayMethods, method, {
value: function mutator(...args) {
return original.apply(this, args)
},
enumerable: false,
writable: true,
configurable: true
})
});
使用拦截器覆盖Array原型
有两种方法来覆盖,一种是使用__proto__属性,另外一种是当__proto__不被支持的情况下,直接接改写的方法直接设置到被侦测的数组上:
const hasProto = `__proto__` in {};
const arrayKeys = Object.getOwnPropertyNames(arrayMethods);
function def(obj, key, val, enumerable) {
Object.defineProperty(obj, key, {
value: val,
enumerable: !!enumerable,
writable: true,
configurable: true
});
}
export class Observer {
constructor(value) {
this.value = value;
if (Array.isArray(value)) {
const augment = hasProto ? protoAugment : copyAugment;
augment(value, arrayMethods, arrayKeys);
}
}
}
function protoAugment(target, src, keys) {
target.__proto__ = src;
}
function copyAugment(target, src, keys) {
for (let i = 0, l = keys.length; i < l; i++) {
const key = keys[i];
def(target, key, src[key])
}
}
如何收集数组的依赖
这里谈论的数组,本身也是对象的一个属性值,例如:
{
data: {
arr: []
}
}
数组本身的依赖,也是在arr这个key的响应式监听中收集依赖的,所以数组本身的依赖收集也是在getter中收集的,但是触发依赖的过程不光是在setter中,还有在上面改写的数组方法的拦截器中触发
在哪里那保存数组的依赖
数组触发依赖不是在definedProperty和setter中完成的,而是在拦截器中完成的,数组拦截器中无法访问在defineReactive中定义的let dep = new Dep()这个变量,所以Vue将数组的依赖保存了在了Observer的实例属性上:
class Observer {
constructor(value) {
this.value = value;
this.dep = new Dep();
// ......
}
}
这样,在getter中和拦截器中都可以访问以依赖了,至于如何依赖,后面介绍。
收集依赖
在getter中收集数组的依赖时,需要访问到Obersver的实例上保存的dep属性,Vue中是通过定义了一个observe方法实现的
function observe(val) {
if (!isObject(val)) {
return;
}
let ob;
if (Object.prototype.hasOwnProperty.call(val, '__proto__') && val instanceof Observer) {
ob = val.__proto__;
} else {
ob = new Observer(val);
}
return ob;
}
首先根据__proto__属性判断数组是不是响应式数据,如果已经是了就不需要再重复创建Obersver的实例,如果不是的话则会创建一个Obersver实例
observe方法会在definedReactive中被调用:
const defineReactive = (data, key, value) => {
let childOb = observe(value);
let dep = new Dep();
Object.defineProperty(data, key, {
enumerable: true,
configurable: true,
get() {
dep.depend();
// 将数组的依赖保存在`Observer`实例上(即value.__ob__.dep)上
if (childOb) {
childOb.dep.depend();
}
return value;
},
set(newVal) {
if (newVal === value) {
return;
}
value = newVal;
dep.notify();
}
});
};
这样数组的依赖就被保存在了Observer实例上,我理解,这个childOb就是为了将数组的依赖保存在Observer实例上(即value.__ob__.dep)存在的,如果没有它数组的依赖无法挂载到Observer实例上,这样数组改变时才可以通过this.__ob__.dep.notify()触发更新
在拦截器中获取Observer实例
在拦截器中的this指向的当前数组的实例,我们希望在this上读取到Observer的实例,Vue的做法是在Observer定义时为数组实例添加了一个__ob__属性,将Observer实例保存到了这个属性上
class Observer {
constructor(value) {
this.value = value;
this.dep = new Dep();
// 将 observer 实例赋到 __ob__属性
def(value, '__ob__', this);
// ...
}
}
__ob__的作用不仅仅是在拦截器中访问Observer的实例,还可以用来标记当前value是否已经被Observer转换为了响应式的数据
在value上标记了__ob__之后,就可以通过value.__ob__来访问Observer的实例,然后通过Observer实例上保存的dep属性来访问收集的数组的依赖:
// 改写数组的原生方法
['push', 'pop', 'shift', 'unshift', 'reverse', 'sort', 'splice'].forEach((method) => {
const original = arrayProto[method];
def(arrayMethods, method, function mutator(...args) {
const result = original.apply(this, args);
// 访问 Observer 实例
const ob = this.__ob__;
// 访问依赖并发送通知
ob.dep.notify();
return result;
});
});
侦测数组成员的变化
在Observer中针对数组类型定义了observerArray方法,这个方法中遍历数组的每个成员,调用前面定义的observe方法,将每个成员都转换为响应式数据:
class Observer {
constructor(value) {
this.value = value;
this.dep = new Dep();
def(value, '__ob__', this);
if (Array.isArray(value)) {
// 拦截数组原生方法
const augment = hasProto ? protoAugment : copyAugment;
augment(value, arrayMethods, arrayKeys);
this.observeArray(value);
} else {
this.walk(value);
}
}
walk(value) {
const keys = Object.keys(value);
for (let i = 0; i < keys.length; i++) {
defineReactive(value, keys[i], value[keys[i]]);
}
}
// 侦测数组中的每一项
observeArray(items) {
for (let i = 0, l = items.length; i < l; i++) {
observe(items[i]);
}
}
}
侦测数组新增成员的变化
数组的push/unshift等方法时可以新增数组内容的,新增数组的内容也需要转换为响应式数据,这个过程是在数组拦截器中完成的
首先要获取到新增的元素,然后对新增的元素通过上面定义的Observer实例上的observeArray方法将新增成员转换为响应式数据:
// 改写数组的原生方法
['push', 'pop', 'shift', 'unshift', 'reverse', 'sort', 'splice'].forEach((method) => {
const original = arrayProto[method];
def(arrayMethods, method, function mutator(...args) {
const result = original.apply(this, args);
const ob = this.__ob__;
let inserted;
switch (method) {
case 'push':
case 'unshift': {
inserted = args;
break;
}
case 'splice': {
inserted = args.slice(2);
break;
}
}
if (inserted) {
ob.observeArray(inserted);
}
ob.dep.notify();
return result;
});
});
数组的限制
对Array的变化时通过拦截原型的方式实现的,这样直接使用下标修改数组,Vue是无法侦测到的,同样直接修改数组的length属性也是不行的
实际上如果使用Object.defineProperty对数组的key做监听也是可以实现上面两种方式的响应式变化的,没有这样做,根据尤雨溪的解释是:
性能代价和获得的用户体验收益不成正比
具体的讨论可以看这篇文章。
总结
Array追踪变化的方式与Object不一样,它是通过方法来改变内容的,所以通过创建拦截器去覆盖数组原型的方式来追踪变化
Array中收集依赖的方式和Object一样,都是在getter中收集,但由于使用依赖的位置不同,数组要在拦截器中向依赖发消息,所以依赖不能像Objet一样保存在defineRactive中,而是保存在了Obersever实例上
Observer中,把每个侦测了变化的数据都标记__ob__,并把this(Observer实例)保存在__ob__上,这样①可以标记数据是否被侦测了变化,保证每个数据只被侦测一次②通过数数据获取到__ob__,从而拿到Observer上保存的依赖,当拦截到数组发生变化时,向依赖发送通知
除了侦测数组自身的变化外,数组中元素的变化也要侦测。在Observer中判断如果当前被侦测的数据是数组,则调用observerArray方法将数组每个元素都转换为响应式
除了侦测已有数据外,当用户使用push等方法向数组中新增数据时,新增的数据也要进行变化侦测。如果操作数组的是push、unshift、splice方法,则从参数中将数据提取出来,使用observer对新增数据进行变化侦测。
变化侦测的API实现原理
vm.$watch
const unwatch = vm.$watch(expOrFn, callback, [options]);
// 取消观察
unwatch();
expOrFn支持函数的改造
expOrFn表达式只接受以点分割的路径,如果是复杂的表示,可以用函数代替。
vm.$watch是对Watcher的一种封装,目前的Watcher结构不支持expOrFn为函数,进行一点改造:
class Watcher {
constructor(vm, expOrFn, cb) {
this.vm = vm;
this.cb = cb;
// expOrFn 支持函数
if (typeof expOrFn === 'function') {
this.getter = expOrFn;
} else {
this.getter = parsePath(expOrFn);
}
this.value = this.get();
}
get() {
window.target = this;
this.value = this.getter.call(this.vm, this.vm);
window.target = undefined;
return this.value;
}
update() {
const oldValue = this.value;
this.value = this.get();
this.cb.call(this.vm, this.value, oldValue);
}
}
当expOrFn为函数时,函数中所读取的所有Vue实例上的响应式数据都会被Watcher所观察(因为在执行函数时,函数中的变量都会被访问,也就是说所有数据的get都会被执行,也就将这个Watcher收集到dep中)
实际上Vue的计算属性实现原理与
expOrFn支持函数关系很大
watch的实现
这样Watcher可以实现vm.$watch的功能,但是参数deep和immediate需要对Watcher进行改造才可以实现:
Vue.prototype.$watch = function (expOrFn, cb, options) {
const vm = this;
options = options || {};
const watcher = new Watcher(vm, expOrFn, cb, options);
if (options.immediate) {
cb.call(vm, watcher.value);
}
return function unwatch() {
watcher.teardown();
};
};
Watcher的teardown方法
teardown方法用来取消观察数据,本质是把watcher从观察的所有状态的依赖列表中移除,要实现这个方法,需要:
- 在Watcher中记录自己都订阅了谁,也就是
watcher实例被收集进入了哪些Dep里 - 不想继续订阅这些Dep时,循环自己的订阅列表通过Dep来将自己从Dep的依赖列表中移除
这就需要对收集依赖部分的代码进行改造,首先在Watcher中添加addDep方法,用来在watcher中记录自己都订阅过哪些Dep:
class Watcher {
constructor(vm, expOrFn, cb) {
this.vm = vm;
this.cb = cb;
// 记录自己订阅的依赖列表
this.deps = [];
// 依赖列表的 Id
this.depIds = new Set();
// expOrFn 支持函数
if (typeof expOrFn === 'function') {
this.getter = expOrFn;
} else {
this.getter = parsePath(expOrFn);
}
this.value = this.get();
}
addDep(dep) {
const id = dep.id;
if(!this.depIds.has(id)) {
this.depIds.add(id);
this.deps.push(dep);
// 将自己(watcher实例)添加的 dep 的 subs 列表中
dep.addSub(this);
}
}
}
Dep中对应的收集依赖的逻辑也要有所改变:
let uid = 0;
class Dep {
constructor() {
this.id = uid++;
this.subs = [];
}
depend() {
if (window.target) {
// this.addSub(window.target);
window.target.addDep(this)
}
}
}
window.target就是watcher实例,执行addDep方法时,Watcher会记录自己会被哪些Dep通知,Dep也会记录数据变化时需要通知哪些Watcher,这是一个多对多的关系(正因为expOrFn可能是函数,里面可能会订阅多个响应式数据)
这样在Watcher中就可以添加teardown方法来解除观察,通知自己订阅的Dep,让它们把自己从依赖列表中移除掉:
class Watcher {
// 从所有依赖项的 Dep 列表中把自己移除
teardown() {
let i = this.deps.length;
while(i--) {
this.deps[i].removeSub(this)
}
}
}
在Dep中的removeSub方法会把watcher实例从自己的subs中移除掉:
class Dep {
removeSub(sub) {
if (this.subs.length > 0) {
const index = this.subs.indexOf(sub);
if (index > -1) {
return this.subs.splice(index, 1)
}
}
}
}
deep参数的实现原理
deep参数的功能实现,就是除了要触发当前这个被监听数据的收集依赖的逻辑之外,还要把当前监听的这个值在内的所有子值都要触发一遍收集依赖逻辑。
class Watcher {
constructor(vm, expOrFn, cb, options) {
this.vm = vm;
this.cb = cb;
if (options) {
this.deep = !!options.deep;
} else {
this.deep = false;
}
// ...
}
get() {
window.target = this;
this.value = this.getter.call(this.vm, this.vm);
// deep 逻辑
if (this.deep) {
traverse(this.value);
}
window.target = undefined;
return this.value;
}
// ...
}
traverse方法就是用来递归value的所有子值来触发它们依赖的功能:
// 递归收集依赖
function traverse(val) {
_traverse(val, seenObjects);
seenObjects.clear();
}
function _traverse(val, seen) {
let i, keys;
const isA = Array.isArray(val);
if ((!isA && !isObject(val)) || Object.isFrozen(val)) {
return;
}
if (val.__ob__) {
const depId = val.__ob__.dep.id;
if (seen.has(depId)) {
return;
}
seen.add(depId);
}
if (isA) {
i = val.length;
while (i--) {
_traverse(val[i], seen);
}
} else {
keys = Object.keys(val);
i = keys.length;
while (i--) {
_traverse(val[[keys[i]]], seen);
}
}
}
上面的关键是,当数据的类型为Object时,循环Object中所有的key,然后执行了读取操作,然后再递归子值:
while (i--) {
_traverse(val[[keys[i]]], seen);
}
其中val[[keys[i]]会触发getter,也就是说会触发收集依赖的操作,这时候window.target还未被清空,会将当前的watcher收集进去。
vm.$set
vm.$set(target, key, value);
// target 需要时响应式数据,但不能是Vue实例或者Vue实例的根数据对象
这个API主要是用来避开Vue无法侦测属性被添加的限制。
target是数组
function set(target, key, val) {
// 处理数组的情况
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key);
target.splice(key, 1, val);
return val;
}
}
要注意的是,判断key与数组的长度,如果大于数组的长度,要给数组“扩容”,然后通过改造后的splice方法来收集依赖
key已经存在于target
function set(target, key, val) {
// 处理数组的情况
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key);
target.splice(key, 1, val);
return val;
}
// key 已存在
if (key in target && !(key in Object.prototype)) {
target[key] = val;
return val;
}
}
key已经存在target里,那么这个key实际上已经是响应式的了,这时候直接用key和val直接修改数据就好了
新增属性
function set(target, key, val) {
// 处理数组的情况
if (Array.isArray(target) && isValidArrayIndex(key)) {
target.length = Math.max(target.length, key);
target.splice(key, 1, val);
return val;
}
// key 已存在
if (key in target && !(key in Object.prototype)) {
target[key] = val;
return val;
}
// 新增属性
const ob = target.__ob__;
// target 是 Vue 实例,或者是 Vue 实例的根数据对象
if (target._isVue || (ob && ob.vmCount)) {
process.env.NODE_ENV !== 'production' ** console.warn('...');
return val;
}
if (!ob) {
target[key] = val;
return val;
}
defineReactive(ob.value, key, val);
ob.dep.notify();
return val;
}
先获取target的observer实例,即__ob__属性。然后根据_isVue判断target是否是Vue实例,用ob.vmCount来判断是否是根数据对象(及根节点的数据对象this.$data),这两种情况都不需要处理
如果target.__ob__不存在,那么说明target不是响应式的,也不需要任何处理,直接赋值即可。
如果上面所有条件不满足,才证明用户是为一个响应式数据新增了一个属性,这是用defineReactive来将ob.value(即响应式数据对象)上添加key和value,并且将属性转换为getter/setter的形式,最后想target的依赖发送通知,并返回val
vm.$delete
vm.$delete(target, key)
过程还是比较简单的:
function del(target, key) {
// 先处理数组的情况
if (Array.isArray(target) && isValidArrayIndex(key)) {
// 使用改造后的数组的 splice 方法就可以做到响应式删除,自动向依赖发送更新
target.splice(key, 1);
return;
}
const ob = target.__ob__;
// 如果是 Vue 实例或者是根数据对象,则不能使用这个方法
if (target._isVue || (ob && ob.vmCount)) {
process.env.NODE_ENV !== 'production' ** console.warn('...');
return;
}
// 如果不是自身的属性,那么什么也不操作
if (!Object.prototype.hasOwnProperty.call(target, key)) {
return;
}
delete target[key];
// 如果不是响应式数据,也就不需要向依赖发送通知
if (!ob) {
return;
}
ob.dep.notify();
}
虚拟DOM
为什么要引入虚拟DOM
Vue的依赖订阅机制,可以再一定程度上知道哪些状态发生了变化。在Vue1.0中并没有引入虚拟DOM,当状态发生变化,Vue知道哪些节点使用了这个状态,从而对这些节点进行更新操作,不需要对比
这样做的代价是,粒度太细,导致内存开销过大。
所以在Vue2.0中选择了中等粒度的解决方案,引入了虚拟DOM。组件级别是一个Watcher实例,当状态发生变化时,只能通知到组件,然后组件内部通过虚拟DOM来进行比对和渲染。
Vue中的虚拟DOM
Vue中使用模板来描述状态与DOM间的映射关系。Vue通过编译将模板转换为渲染函数,执行渲染函数就可以得到虚拟节点树,使用这个虚拟节点树来渲染页面。
为了避免整体替换vnode带来的性能浪费,虚拟DOM在做虚拟节点映射到视图的过程中,会与旧的虚拟节点进行比对(diff),找出需要更新的节点来进行DOM操作
虚拟DOM完成的事情也就是:
- 提供与真实DOM节点所对应的虚拟节点vnode
- 将虚拟节点vnode和旧的虚拟节点oldVnode进行比对,然后更新视图
VNode
vnode可以理解为节点描述对象,它描述了怎么样去创建真实的DOM节点,它只是一个普通的对象,是从VNode类实例化的对象。
vnode有不同类型:
- 注释节点
- 文本节点
- 元素节点
- 组件节点
- 函数式组件
- 克隆节点
注释节点
节点:
对应的vnode:
{
text: '注释节点',
isComment: true
}
创建过程:
export const createEmptyVNode = (text) => {
const node = new VNode();
node.text = text;
node.isComment = true;
return node;
};
文本节点
vnode:
{
text: 'Hello Vue',
}
创建过程:
export const createTextVNode = (value) => {
return new VNode(undefined, undefined, undefined, String(value));
};
克隆节点
克隆节点是将享有的节点属性复制到新节点中,让新创建的节点和被克隆节点的属性保持一致,实现克隆效果。作用是优化静态节点和插槽节点
export const cloneVNode = (vnode, deep) => {
const cloned = new VNode(
vnode.tag,
vnode.data,
vnode.children,
vnode.text,
vnode.elm,
vnode.context,
vnode.componentOptions,
vnode.asyncFactory
);
cloned.ns = vnode.ns;
cloned.isStatic = vnode.isStatic;
cloned.key = vnode.key;
cloned.isComment = vnode.isComment;
cloned.isCloned = true;
if (deep && vnode.children) {
cloned.children = cloneVNode(vnode.children);
}
return cloned;
};
克隆节点就是将现有的节点的属性全部复制到新节点中,除了isCloned属性为true
元素节点
元素节点有四个属性:
tag,节点名称,例如ul、pdata,包含节点上的数据,attrs、class、style等children,子节点列表context,当前组件的Vue实例
元素节点:
HelloVue
vnode:
{
children: [VNode, Vnode],
context: {...}
data: {...},
tag: 'p',
...
}
组件节点
组件节点和元素节点类似,有两个独有的属性:
componentOptions,组件节点的选项参数,包含propsData、tag等compontentInstance,Vue实例
函数式组件
与组件节点类似,有特有的属性functionalContext和functionalOptions
patch
patch的目的是修改DOM节点,渲染视图。它不是暴力替换节点,而是在现有的DOM上修改来达到渲染视图的目的,包含三个过程:
- 创建新节点
- 删除废弃节点
- 更新已存在节点
整个patch的过程是:
- 当oldVnode不存在时,直接使用vnode渲染视图
- 当oldVnode和vnode都存在,但不是同一个节点时,使用vnode创建的新DOM元素替换旧的DOM元素
- 当oldVnode和vnode都存在并且是同一个节点时,使用更详细的对比操作来局部更新真实DOM
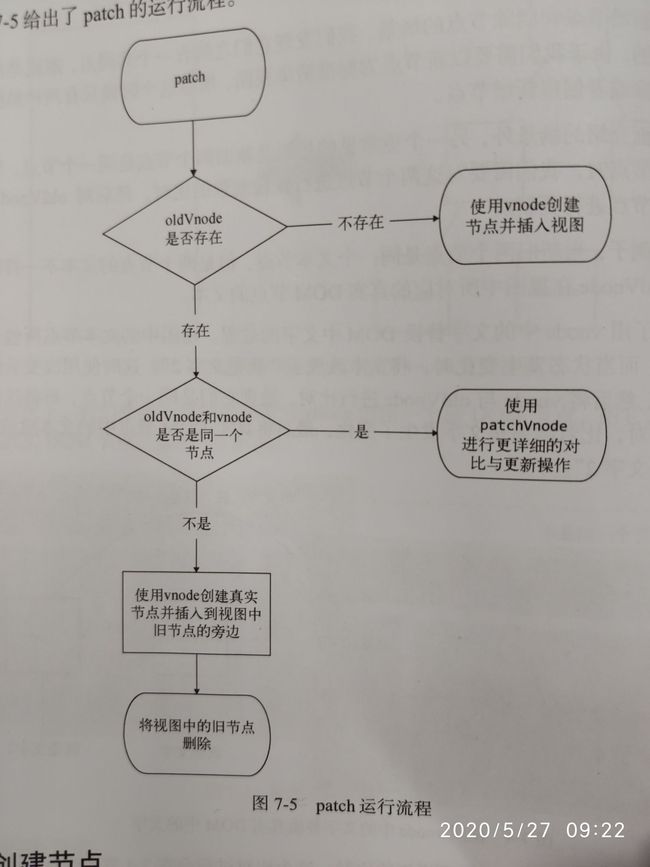
创建节点
只有元素节点、注释节点和文本节点会被创建并插入到DOM中
有tag属性就可以判定是一个元素节点,然后调用document.createElement方法创建真实的元素节点
然后调用parentNode.appendChild来将元素插入到父节点,如果这个父节点已经被渲染到视图,那么插入到这个父节点下的元素也会被渲染到视图
然后需要将元素节点的子节点也创建出来并插入到刚刚创建出的节点下面,这是一个递归过程,需要将vnode的children属性循环一遍,将每个子虚拟节点都执行一遍创建元素的逻辑。
如果vnode的tag属性不存在,并且isComment为true,那么认为是注释节点,调用document.createComment方法,创建注释节点。如果isComment为false,那么就调用document.createTextNode创建真是的文本节点
删除节点
function isDef(v) {
return v !== undefined && v !== null;
}
const nodeOps = {
parentNode(node) {
return node.parentNode;
},
removeNode(node, child) {
node.removeChild(child);
}
};
function removeNode(el) {
const parent = nodeOps.parentNode(el);
if (isDef(parent)) {
nodeOps.removeNode(parent, el);
}
}
nodeOps是对节点操作的封装,目的是为了进行实现跨平台运行时API对接。
更新节点
静态节点
静态节点指的就是渲染到界面上后,无论日后状态如何变化,都不会发生改变的节点
如果新旧两个虚拟节点都是静态节点,如果是的话就可以直接跳过更新节点的过程。
新虚拟节点有文本属性
如果新生成的虚拟节点有text属性,那么无论之前的旧节点的子节点是什么,直接调用setTextContext方法(在浏览器环境下是node.textContext方法)
新虚拟节点无文本属性
这时候新的虚拟节点是一个元素节点,根据是否有children属性,存在两种情况:
(1)新的虚拟节点有children
如果旧的虚拟节点也有children属性,那么需要对新、旧虚拟节点的children进行详细的diff
如果旧的虚拟节点没有children属性,那么旧 的虚拟节点可能是文本节点或者是空标签,如果是文本节点,那么就要将文本清空将其变为空标签,然后将新的虚拟节点的children创建为真实DOM元素插入进去
(2)新的虚拟节点没有children
这时候新的虚拟节点是一个空节点,那么会对旧的虚拟节点进行删除,达到视图中是空标签的目的

更新子节点
更新子节点可以分为四种操作:
- 更新节点
- 新增节点
- 删除节点
- 移动节点
更新子节点要进行循环,先遍历新的子节点列表,每循环到一个新的子节点,就会去旧子节点列表中找和当前节点相同的节点。如果找不到,就进行新增;如果找到了就做更新操作;如果位置不同,就进行移动
更新策略
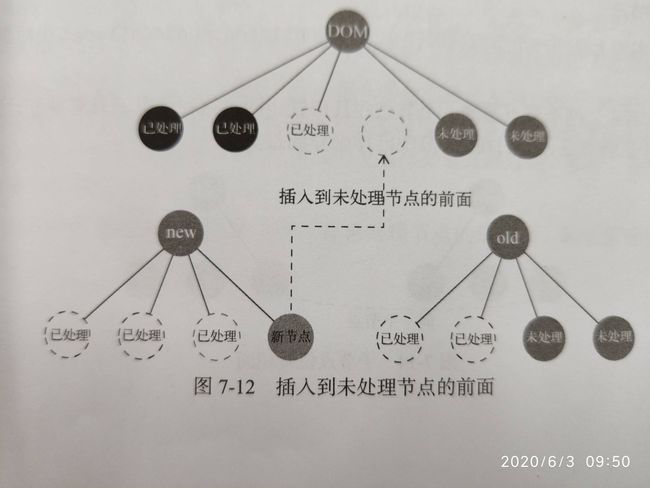
(1)创建子节点
如果在遍历oldChildren时,没有找到本次循环(外层循环)所指向的新子节点相同的节点,那么意味着这个新子节点是一个新增子节点,需要执行创建节点操作,并且插入到oldChildren中所有没有处理的节点的前面
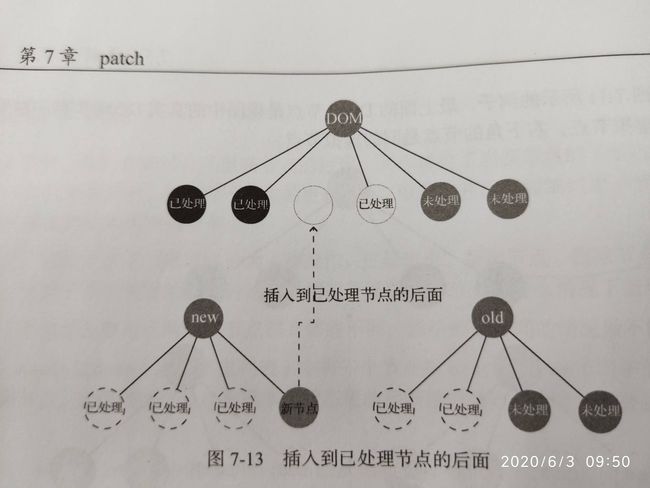
没有插入到所有已处理后节点的后面,是因为有可能会有连续几个新增节点,如果都插入到已处理后的节点的后面,那么插入的顺序是相反的(要注意的是,先遍历后插入,插入是一次性的)
例如,如果有两个新增节点,插入到oldChildRen的没有处理的节点前面,顺序正确:
如果插入到已处理的节点的后面,那么顺序是相反的:
(2)更新子节点
如果两个节点是同一个节点,并且位置相同,那么这时候只需要进行更新操作即可
(3)移动子节点
当新旧节点是同一个节点,但是位置不同时,会进行移动操作,调用的是Node.insertBefore方法
关键是得到将旧的节点移动到的位置,这个位置是当前所有未处理节点的第一个节点
新增和移动节点的位置,都是以未处理节点进行标定位置的
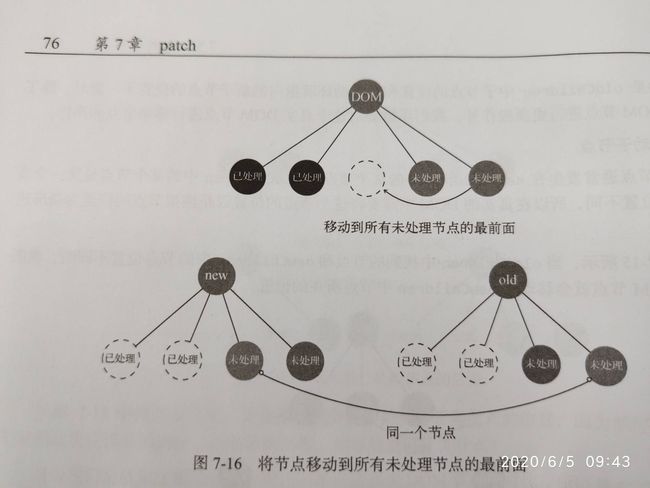
(4)删除子节点
本质上是删除那些oldChildren中存在但是newChildren中不存在的节点
当newChildren中的所有节点都被循环了一遍后,也就是循环结束后,如果oldChildren中还有剩余没被处理的节点,那么这些节点就要被删除
优化策略
可以使用下面四种快速查找节点的方式,这四种方式可以涵盖大多数的节点变化的情况,从而来避免循环oldChildren来查找节点,提升执行速度
- 将『新前』与『旧前』比对
- 将『新后』与『旧后』比对
- 将『新后』与『旧前』对比
- 将『新前』与『旧后』对比
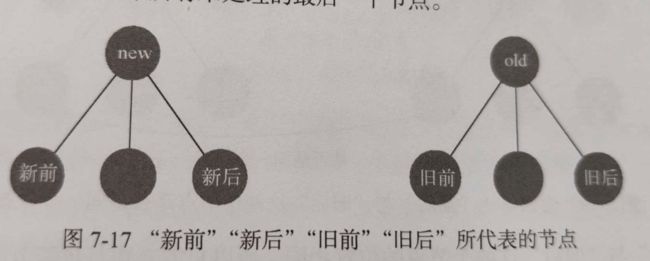
前两种快捷查找方式,不需要执行移动节点的操作,只需要更新节点即可
后两种方式,除了更新节点外,还需要执行移动节点的操作。
在将『新后』与『旧前』对比时,如果二者是通过一个节点,在真实DOM中除了做更新操作外,还需要将节点移动到oldChildren中所有未处理节点的最后面
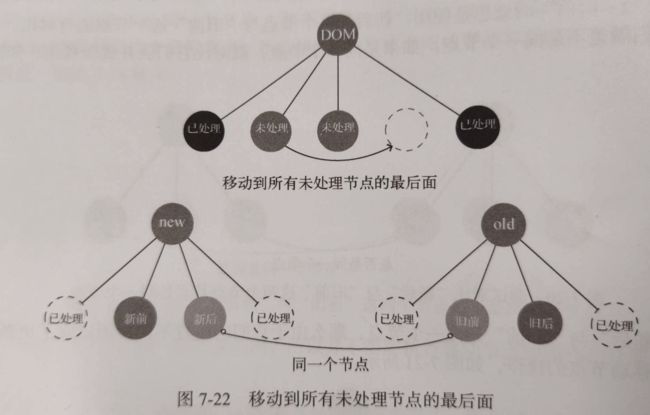
这样移动才能保证下一轮移动时顺序是正确的,即下一轮的新后会在上一轮新后的前面
第四种比对方式与与第三种是类似的,需要将节点移动到oldChildren中所有未处理节点的最前面
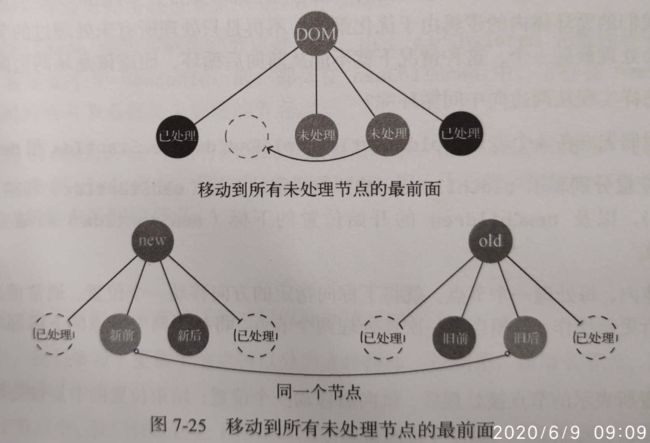
要记住的就是,移动都是以oldChildren中未处理的节点为基准进行,所有已更新过的节点不用管。
如果上面4中比对方式都没有找到相同的节点,那么再去通过循环的方式去oldChildren中详细找一圈
判断节点是否被处理过
实际上,并不是通过节点本身的属性来表示节点是否被处理过,而是通过循环来控制,循环体内只包含未处理过的节点,通过这一特性来实现,将处理过的节点剔除的
通常的遍历,无论是从前到后,或是从后到前,自然而然就会实现上面说的效果,处理后的节点不会进入下一轮循环
但是由于上面提到的优化策略,在循环体内,有可能处理的是未处理节点中的第一个,也可能是最后一个,所以就不能是从前向后循环,而应该是从两边向中间循环
Vue使用了四个变量,来标识循环的起始位置:
oldStartIdxoldEndIdxnewStartIdxnewEndIdx
在循环体内,每处理一个节点,就将下标向指定的方向移动一个位置。处理时一般是对两个节点进行操作,相当于一次处理两个节点,就会将新、就两个节点各向指定方向移动一个位置
oldStartIdx和newStartIdx只能向后移动,oldEndIdx和newEndIdx只能向前移动,当开始位置大于等于结束位置时,说明所有节点都遍历过了,结束循环
while(oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
// 比对节点
}
如果新旧节点数量不一致时,循环不会覆盖所有节点,这样正是预期的结果,如果newChildren中有没遍历的节点(即下标在newStartIdx和newEndIdx之间的节点),那么说明这些节点都是需要新增的节点(即下标在oldStartIdx和oldEndIdx之间的节点),直接插入DOM就行。如果oldChilren中有未遍历的节点,那么这些都是要删除的节点,直接删除即可
这样可以减少一部分遍历次数,提升性能
key
渲染列表时,推荐使用key,因为如果在列表循环时,如果设置了key,那么在oldChildren中循环相同节点时,就不需要通过遍历来查找节点,直接通过key就可以查找到
Vue是推荐在列表渲染时使用key,并且使用key来查找子节点的方式也是排在上面提到的四种快捷查找方式之后,我理解是由于使用key还是需要新建一个key与index索引关系的对象,而那四种快捷查找方式并不需要新建这一个对象,为所有的组件都应key来进行标识,开销太大。而在列表渲染时使用key可以有效的提升列表顺序变化导致的循环遍历
模板编译原理
Vue会将模板编译成虚拟DOM渲染函数,可以分为三个步骤:
- 先将模板解析为AST(Abstract Syntax Tree,抽象语法树)
- 遍历AST标记静态节点(用来避免静态节点的重复渲染)
- 使用AST生成渲染函数
模板编译中抽象出三个模板分别实现上面的三个功能:
- 解析器
- 优化器
- 代码生成器
解析器
解析器的目的就是将将模板解析为AST。解析器内部包含了多个小解析器,通过一个主线将解析器组装到一起
- 文本解析器用来解析带变量的文本
- 过滤器解析器用来解析过滤器
- HTML解析器是核心模块。当解析到HTML的开始位置、结束为止或注释时,都会触发钩子函数,将相关信息通过参数传递给煮东西拿,生成AST
优化器
优化器会遍历AST,检测所有静态子树,并打上标记。在重新渲染时,就不需要为打上标记的静态节点创建虚拟节点,而是直接克隆已存在的虚拟jiedian
代码生成器
代码生成器会生成一个代码字符串,然后通过new Function这种形式,将字符串转换为可以执行的代码
解析器
解析器的功能就是将模板转换为AST,AST是用JavaScript中的对象来描述一个节点,一个对象表示一个节点
解析器内部运行原理
解析器内部最主要的就是HTML解析器,它的作用是解析HTML,在解析过程中会不断触发各种钩子函数
function createASTElement(tag, attrs, parent) {
return {
type: 1,
tag,
attrList: attrs,
parent,
children: []
}
}
parseHtml(template, {
start(tag, attrs, unary) {
// 解析到标签的开始位置时,触发该函数
let element = createASTElement(tag, attrs, currentParent)
},
end() {
// 解析到标签的结束位置时,触发该函数
},
chars(text) {
// 解析到文本时,触发该函数
let element = {type: 3, text};
},
comment(text)
// 解析到注释时,触发该函数
let element = {type: 3, text, isComment: true};
},
})
在钩子函数中构建AST,在start中构建元素类型的节点,在chars中构建文本类型的节点,在comment中构建注释类型节点
构建出来的AST应该是有层级关系的,但是如果直接按照上面的方式去解析模板,得到的AST节点都是被拉平的。为了构建AST的层级关系,需要维护一个栈(stack),用栈来记录层级关系,这个层级关系可以理解为DOM的深度。
在解析HTML时,遇到开始标签就会触发start函数,这是把构建的节点推入栈中,遇到结束标签会触发end函数,就会从栈中弹出一个节点。这样就可以保证,每当触发函数start时,栈的最后一个节点就是当前正在构建的节点的父节点。
HTML解析器
解析HTML模板就是循环的过程,每轮循环都从HTML模板中截取一小段字符串,然后重复以上过程,直到HTML模板被截取为一个空字符串时结束循环。
每一轮截取字符串时,都是在整个模板的开始位置截取,根据模板开始位置的片段类型,进行不同的截取操作。
截取开始标签
判断是否是开始摆多钱,首先判断模板是否以<开头,如果不是,那么一定不是开始标签,如果是的话,还需要借助正则表达式来分辨是否为开始标签
开始标签会被拆成是哪个部分,分别是标签名、属性和结尾:

这个部分的正则表达式我看起来很费劲,跳过具体的匹配规则,只看原理。
截取属性也要分成多个小部分,一块一块的去解析与截取
截取结束标签
截取结束标签也是通过正则表达式来判断,通过正则判断剩余模板是否是结束标签,如果是的话,对模板进行截取的同时触发钩子函数
截取注释
原理与截取开始和结束标签原理相同,也会触发钩子函数(可以通过选项配置是否触发)
截取条件注释
条件注释会被直接接去掉,也不会触发钩子函数,所以在Vue中写条件注释没用
截取文本
不需要使用正则表达式,如果模板的第一个字符不是<,那么一定是文本,文本的结束位置是下一个<的所在位置,如果模板中找不到<那么说明整个模板全是文本,截取后出发钩子函数
有一种特殊情况,如果<是文本的一部分,例如1,会遗漏文本,解决思路是,如果将前端面的<截取完后,剩余的模板不符合任何被解析的片段类型,那么这个<就是文本的一部分
当判断出<是属于文本的一部分后,需要做的事情就是找到下一个<,并将前面的文本截取出来加到再前面截取了一半的文本后面
如果剩余的模板仍然不符合被解析的类型,那么重复这个过程
纯文本内容元素的处理
script、style和textarea三种元素叫做纯文本内容元素。上面的处理都默认当前截取的父元素不是纯文本元素,纯文本元素的处理逻辑完全不同。
如果截取内容的父元素是纯文本内容元素,那么在本轮循环中会一次性将这个父标签给处理完毕
整体逻辑
export function parseHtml(html, options) {
while (html) {
// lastTag 是从维护的栈中取出的最后一个元素,是当前元素的父元素
// 判断当前元素的父元素是否是纯文本内容元素
if (!lastTag || !isPlainTextElement(lastTag)) {
// 非纯文本内容元素
let textEnd = html.indexOf('<');
// 首先处理当做非文本内容进行解析
if (textEnd === 0) {
// 注释
if (comment.test(html)) {
// 注释的处理逻辑
continue;
}
// 条件注释
if (conditionalComment.test(html)) {
// 条件注释的处理逻辑
continue;
}
// DOCTYPE
const doctypeMatch = html.match(docType);
if (doctypeMatch) {
// DOCTYPE 的处理逻辑
continue;
}
// 结束标签
const endTagMatch = html.match(endTag);
if (endTagMatch) {
// 结束标签的处理逻辑
continue;
}
// 开始标签
const startTagMatch = parseStartTag(html);
if (startTagMatch) {
// 开始标签的处理逻辑
continue;
}
}
let text, rest, next;
// 非文本内容解析后,文本中仍然含有 <,那么需要解析文本
if (textEnd >= 0) {
rest = html.slice(textEnd);
while (!endTag.test(rest) && !startTagOpen.test(rest) && !comment.test(rest) && conditionalComment.test(rest)) {
// 如果 < 在纯文本中,那么将它视为纯文本对待
next = rest.indexOf('<', 1);
if (next < 0) break;
textEnd += next;
rest = html.slice(textEnd);
}
text = html.substring(0, textEnd);
html = html.substring(textEnd)
}
// 如果模板中不再包含 < 了,那么剩余内容都是文本内容了
if (textEnd < 0) {
text = html;
html = '';
}
// 触发文本解析的钩子函数
if (options.chars && text) {
options.chars(text);
}
} else {
// 父元素是纯文本内容元素(script、style 或 textarea)
}
}
}
文本解析器
文本解析器是对HTML解析器解析出来的文本进行二次加工,因为HTML解析器在解析文本时并不会区分文本是否带有变量
在构建文本类型的AST时,纯文本和带有变量的文本是两种不同的处理方式,如果是带有变量的文本,会将表达式带入最终结果:
"hello" + _s(name)
AST会转换成为代码字符串在witch中执行,将name替换为值
文本解析器中第一步要做的事情就是使用正则表达式判断文本是否带有变量,如果是纯文本就会返回undefined,如果带有变量,那么解决思路是,使用正则表达式匹配出文本中的变量,先把变量左边的文本添加到数组,然后把变量改成_s(x)的形式也添加到数组,如果变量后面还有变量,那么重复以上动作
这时候就可以得到一个数组,数组元素的顺序与文本顺序一致,将这个数组用join('+')方法连接起来变成字符串,就可以得到带有变量表达式的AST
export function parseText(text) {
const tagRE = /\{\{((?:.|\n)+?)\}\}/g;
if (!tagRE.test(text)) {
return;
}
const tokens = [];
let lastIndex = (tagRE.lastIndex = 0);
let match, index;
while ((match = tagRE.exec(text))) {e
index = match.index;
// 先把 {{ 左边的文本添加到 tokens 中
if (index > lastIndex) {
tokens.push(JSON.stringify(text.slice(lastIndex, index)));
}
// 把变量改为 _s(x) 的形式也添加到数组中
tokens.push(`_s(${match[1].trim()})`);
// 设置 lastIndex 来保证下一轮循环时,不会将已经添加过的文本重复添加到数组中
lastIndex = index + match[0].length;
}
// 所有变量处理完毕后,如果最后一个变量右边还有文本,就将文本添加到数组中
if (lastIndex > text.length) {
tokens.push(JSON.stringify(text.slice(lastIndex)));
}
return tokens.join('+')
}
第十章 优化器
解析器的作用是将HTML模板解析为AST,优化器的作用就是在AST中找出静态子树并打上标记,好处是:
- 重新渲染时,不需要为静态子树创建新节点
- 在虚拟DOM中打补丁的过程可以跳过
在AST中,静态节点指的是static属性为true的节点,静态根节点指的是staticRoot属性为true的节点
先标记静态节点,然后标记静态根节点
找出静态节点并标记
先判断根节点是否是静态根节点,再用相同的方式处理子节点,进行反复递归
function markStatic(node) {
node.static = isStatic(node);
if (node.type === 1) {
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i];
markStatic(child)
}
}
}
这里的问题是,递归是从上向下进行的,如果父节点被标记为静态节点后,子节点有可能被标记为动态节点,这就矛盾了。因此需要在子节点被打上标记后,重新校对当前标记的节点是否准确
function markStatic(node) {
node.static = isStatic(node);
if (node.type === 1) {
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i];
markStatic(child);
}
// 校对当前节点
if (!child.static) {
node.static = false;
}
}
}
找出静态根节点并标记
找出静态根节点的过程与找出静态节点的过程类似,都是从根节点开始向下一层一层用递归方式去找,不一样的是,如果一个节点被判定为静态根节点,那么将不会继续向它的子级继续寻找
根据上一节中寻找静态节点的逻辑,静态节点的所有子节点都是静态节点,那么从上向下找时,找到的第一个静态节点一定是静态根节点
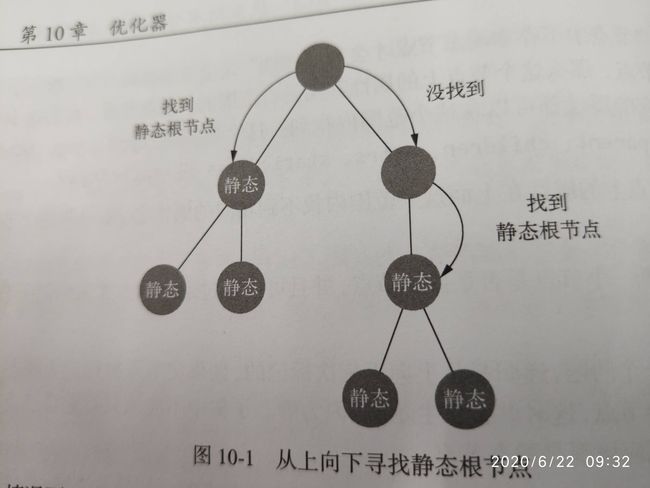
有一种情况,即使符合上面的规则的静态根节点,也不会标记为静态根节点,因为其优化成本大于收益,这种情况是一个元素节点只有一个文本节点:
hello
function markStaticRoot(node) {
if (node.type === 1) {
// 要使节点符合静态根节点的要求,它必须有子节点
// 并且这个子节点不能使只有一个静态文本的子节点,否则优化成本将超过收益
if (node.static && node.children.length &&!(node.children.length !==1 && node.children[0].tyle === 3)) {
node.staticRoot = true;
return;
} else {
node.staticRoot = false
}
if(node.children) {
for (let i = 0, l = node.children.length; i < l; i++) {
const child = node.children[i];
markStaticRoot(child);
}
}
}
如果当前节点时静态节点,就说明该节点的子节点也是静态节点。这就要求先要判断静态节点,才能判断静态根节点
第十一章 代码生成器
代码生成器是模板编译的最后一步,作用是将AST转换为渲染函数中的内容(即代码字符串),代码字符串可以被包装在渲染函数执行,渲染函数调用了createElement,生成VNode
通过AST生成代码字符串
生成代码字符串是一个递归的过程,从顶向下处理每一个AST节点,节点三种类型,对应三种创建方法:
| 类型 | 创建方法 | 别名 |
|---|---|---|
| 元素节点 | createElement |
_c |
| 文本节点 | createTextVNode |
v |
| 注释节点 | createEmptyVNode |
_e |
递归处理节点时,每处理一个AST节点,就会生成与节点类型对应的代码字符串,元素节点对应的代码字符串形如:
_c(, , )
元素节点的子节点创建出来的代码字符串会放在上面例子中的
Hello {{name}}
使用AST生成代码字符串后是:
const code = _c('div', {attrs: {id: 'el'}, [_c('div', [_c('p', [_v('Hello' + _s(name])])])
生成的代码字符串会被包裹在witch中
`witch(this) { return ${code}}`
代码生成器的原理
不同节点的生成方式不同,会分别调用三个函数:
export function genNode(node, state) {
if (node.type === 1) {
return genElement(node, state);
}
if (node.type === 3 && node.isComment) {
return genComment(node);
} else {
return genText(node);
}
}
生成元素节点
export function genData(el, state) {
let data = '{';
if (el.key) {
data += `key:${el.key}`;
}
if (el.ref) {
data += `ref:${el.ref}`;
}
if (el.pre) {
data += `pre:${el.pre}`;
}
// 还有很多类似的逻辑
// ...
data = data.replace(/.$/, '') + '}';
return data;
}
export function genChildren(el, state) {
const children = el.children;
if (children.length) {
return `[${children.map((c) => genNode(c, state)).join(',')}]`;
}
}
export function genElement(el, state) {
// plain 属性是在编译时发现的,如果节点没有属性 plain 为 true
const data = el.plain ? undefined : genData(el, state);
const children = genChildren(el, state);
return `_c('${el.tag}'${data ? `,${data}` : ''}${children ? `,${children}` : ''})`;
}
生成文本节点
export function genText(text) {
// 如果是动态文本使用 expression,否则使用 JSON.stringify 为字符串额外包一层""
return `_v(${type.type === 2 ? text.expression : JSON.stringify(text.text)})`;
}
生成注释节点
export function genComment(comment) {
return `_e(${JSON.stringify(comment.text)})`;
}
第十二章 架构设计
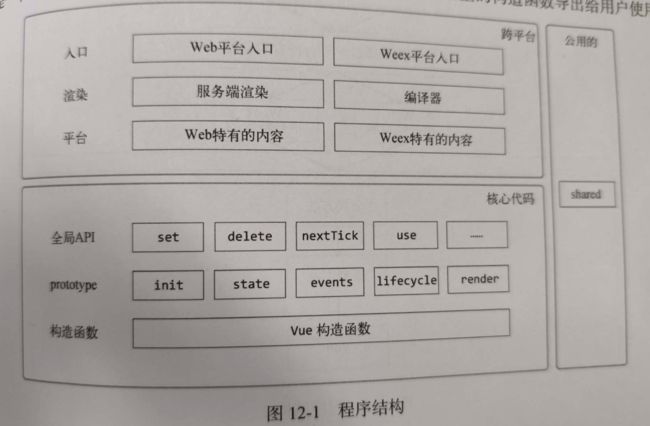
第十三章 实例方法与全局API
在定义Vue构造函数时,会将Vue构造函数当做参数传递给initMixin、stateMixin、eventsMixin、lifeCycleMixin、renderMixin五个函数,它们会将Vue的原型挂载方法
实例方法
$on方法
$on方法向实例上添加自定义事件,由$emit触发。实际上这就是一个订阅器:
Vue.prototype.$on = function (event, fn) {
const vm = this;
if (Array.isArray(event)) {
for (let i = 0, l = event.length; i < l; i++) {
this.$on(event[i], fn);
}
} else {
(vm._events[event] || (vm._events[event] = [])).push(fn);
}
return vm;
};
vm._events是在Vue的初始化时添加的一个对象:
vm._events = Object.create(null)
$off方法
用来移除自定义的事件监听,它分为几种情况:
- 如果没有提供参数,则移除所有的事件监听器
- 如果只提供了事件,则移除该事件的所有监听器
- 如果提供了事件和回调,则只移除这个回调的监听器
Vue.prototype.$off = function (event, fn) {
const vm = this;
if (arguments.length === 0) {
vm._events = Object.create(null);
return null;
}
if (Array.isArray(event)) {
for (let i = 0, l = event.length; i < l; i++) {
this.$off(event[i], fn);
}
return vm;
}
const cbs = vm._events[event];
if (!cbs) {
return vm;
}
if (arguments.length === 1) {
vm._events[event] = null;
return vm;
}
if(fn) {
let cb;
let i = cbs.length;
// 注意,遍历时从后向前进行的
while(i--) {
if(cb === fn || cb.fn === fn) {
cbs.splice(i, 1);
break;
}
}
}
return vm;
};
$once方法
监听一个自定义事件,只触发一次,在第一次触发后移除监听器
Vue.prototype.$once = function (event, fn) {
const vm = this;
function on() {
vm.$off(event, on);
fn.apply(vm, arguments);
}
on.fn = fn;
vm.$on(event, on);
return vm;
};
为了让事件在触发一次后被$off移除,传给$on的是内部的on函数,在on里面进行$off移除操作
但是由于$off时传入的on函数,与用户传入的移除的监听的fn不一致,如果用户手动触发$off来移除监听器时会失败,所以会将用户传入的函数保存到on.fn上,这也就是$off移除时也会比较cb.fn属性的原因
$emit方法
$emit的作用是触发事件:
/**
* Convert an Array-like object to a real Array.
*/
function toArray(list, start) {
start = start || 0;
let i = list.length - start;
let ret = new Array(i);
while (i--) {
ret[i] = list[i + start];
}
return ret;
}
Vue.prototype.$emit = function (event) {
const vm = this;
const cbs = vm._events[event];
if (cbs) {
const args = toArray(arguments, 1);
for (let i = 0, l = cbs.length; i < l; i++) {
try {
cbs[i].apply(vm, args);
} catch (e) {
console.error(e);
}
}
}
return vm;
};
生命周期方法
$forceUpdate
vm.$forceUpdate的作用是迫使Vue实例重新渲染,它仅仅影响实例本身以及插入插槽内容的子组件,而不是所有子组件。它实际上调用的组件的watcher的update方法:
export function lifecycleMixin(Vue) {
Vue.prototype.$forceUpdate = function () {
const vm = this;
if (vm._watcher) {
vm._watcher.update();
}
};
}
$destory
vm.$destory的作用是完全销毁一个实例,它会清理该实例与其他实例的连接,并解绑其全部指令与监听器,同时出发beforeDestory与destroyed钩子函数
Vue.prototype.$destroy = function () {
const vm = this;
// 防止反复执行,销毁只需要执行一次
if (vm._isBeginDestroyed) {
return;
}
// 触发钩子函数
callHook(vm, 'beforeDestroyed');
// 清理当前组件与父组件的关联
const parent = vm.parent;
if (parent && !parent._isBeingDestroyed && !vm.$option.abstract) {
remove(parent.$children, vm);
}
// 移除 watcher 监听的所有状态
if (vm._watcher) {
vm._watcher.teardown();
}
// 当创建 watcher 实例时,都将 watcher 实例添加到 vm._watchers 中
// 清除用户收到创建的 watcher 就需要将 _watchers 中的实例移除
let i = vm._watchers.length;
while (i--) {
vm._watchers[i].teardown();
}
// 表明 Vue 实例有被销毁
vm._isDestroyed = true;
// 解绑模板中的指令
vm.__patch__(vm._vnode, null);
// 触发 destroyed 钩子函数
callHook(vm, 'destroyed');
// 移除事件监听器
vm.$off();
};
$nextTick()
vm.$nextTick()的作用是将接收到的回调函数延迟到下次DOM更新周期后执行。下次DOM更新的意思是,下次微任务执行时更新DOM,vm.$nextTick()就是将回调添加到微任务,只有在特殊情况下会降级为宏任务。
更新DOM的回调函数也是使用vm.$nextTick注册到微任务中。
我理解,更新DOM与实际上浏览器渲染即UI的更新不是同一个事件,浏览器的渲染可以认为是一个宏任务。
(1)Vue异步更新
Vue中状态变化时,Watcher会得到通知,然后触发虚拟DOM的渲染流程,Watcher触发渲染这个流程不是同步的,而是异步的。Vue中有一个队列,每当需要渲染时,会将Watcher推送到这个队列中,在下一次事件循环再让Watcher触发渲染的流程
Vue使用异步更新的原因是,变化的侦测只发送到组件,在同一轮事件循环中,组件内可能会有多个数据发生变化,那么组件的Watcher就会收到多次通知、进行多次渲染。而实际上虚拟DOM会对整个组件进行重新渲染,为了避免多次渲染,需要等到所有状态修改完毕后,一次将整个组件的DOM渲染到最新即可。
为了达到上面的目的,Vue的实现是将受到通知的watcher实例添加到队列中缓存起来,并且每次添加时都会检查是否存在相同的Watcher。在下一次事件循环中,Vue会让队列中的Watcher触发渲染流程并清空队列。
(2)$nextTick()默认使用微任务
一轮事件循环中flashCallbacks只会被执行一次
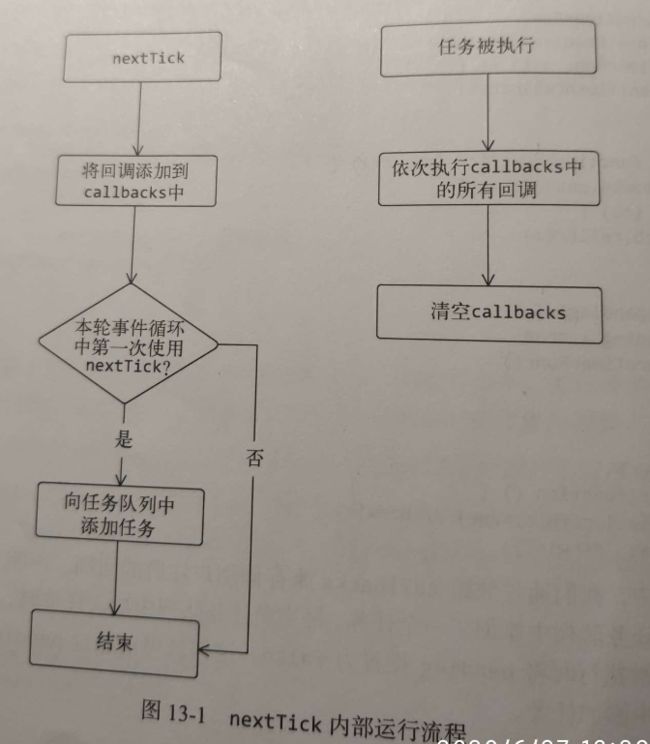
nextTick默认使用Promise.then来将任务添加到微任务中
const callbacks = [];
let pending = false;
function flushCallbacks() {
pending = false;
const copies = callbacks.slice(0);
callbacks.length = 0;
for (let i = 0, l = copies.length; i < l; i++) {
copies[i]();
}
}
// 利用 Promise.resolve 来将更新添加到微任务
const p = Promise.resolve;
let microTimerFunc = () => {
p.then(flushCallbacks);
};
export function nextTick(cb, ctx) {
callbacks.push(() => {
if (cb) {
cb.call(ctx);
}
});
// 利用 pending 来标记是否已经向任务队列添加了一个任务
// 如果已经开始使用 flushCallbacks 执行任务,那么将 pending 设为 false
if (!pending) {
pending = true;
microTimerFunc();
}
}
Vue.prototype.$nextTick = function (fn) {
return nextTick(fn, this);
};
(3)宏任务是可选方案
在Vue2.4版本之前,nextTick在任何地方都使用微任务,但是微任务的优先级太高,在某些场景下会导致问题。所以Vue提供了在特殊场合下可以强制使用宏任务的方法。
“微任务优先级太高导致的问题”可以参考这篇文章的说明。
const callbacks = [];
let pending = false;
function flushCallbacks() {
pending = false;
const copies = callbacks.slice(0);
callbacks.length = 0;
for (let i = 0, l = copies.length; i < l; i++) {
copies[i]();
}
}
// 利用 Promise.resolve 来将更新添加到微任务
const p = Promise.resolve;
let microTimerFunc = () => {
p.then(flushCallbacks);
};
let macroTimerFunc = function () {};
let useMacroTask = false;
export function witchMacroTask(fn) {
return (
fn._withTask ||
(fn._withTask = function () {
useMacroTask = true;
const res = fn.apply(null, arguments);
useMacroTask = false;
return res;
})
);
}
export function nextTick(cb, ctx) {
callbacks.push(() => {
if (cb) {
cb.call(ctx);
}
});
// 利用 pending 来标记是否已经向任务队列添加了一个任务
// 如果已经开始使用 flushCallbacks 执行任务,那么将 pending 设为 false
if (!pending) {
pending = true;
if (useMacroTask) {
macroTimerFunc();
} else {
microTimerFunc();
}
}
}
Vue.prototype.$nextTick = function (fn) {
return nextTick(fn, this);
};
代码中新增了withMacroTask函数,给回调函数添加封装,保证在回调函数执行过程中,如果更新了数据,更新DOM的操作会被推到宏任务队列中。也就是说,更新DOM的执行时间晚于回调函数的执行时间(这是因为更新DOM的回调也是通过nextTick添加到任务队列中的)
被withMacroTask包裹的函数使用的vm.$nextTick方法都会将回调添加到宏任务队列中,其中包括状态被修改后触发的更新DOM的回调和用户自己使用vm.$nextTick注册的回调等
Vue使用macroTimerFunc来将回调函数添加到宏任务队列,优先使用setImmediate,MessageChannel和setTimeout依次作为备选方案
微任务的实现原理使用了Promise,当浏览器不支持时,就会降级为使用macroTimerFunc
let microTimerFunc;
let macroTimerFunc = function () {};
if (typeof Promise !== 'undefined' && isNative(Promise)) {
// 利用 Promise.resolve 来将更新添加到微任务
const p = Promise.resolve;
microTimerFunc = () => {
p.then(flushCallbacks);
};
} else {
microTimerFunc = macroTimerFunc;
}
(4)返回Promise
如果没有提供回调,并且在支持Promise的环境中,nextTick会返回一个Promise。实现这个功能,需要在nextTick中判断符合上述条件,会返回一个Promise,并且在callbacks中添加一个函数,将返回的Promise的reolsve传给这个新添加的函数并且让其执行
export function nextTick(cb, ctx) {
let _resolve;
callbacks.push(() => {
if (cb) {
cb.call(ctx);
} else if (_resolve) {
_resolve(ctx);
}
});
// 利用 pending 来标记是否已经向任务队列添加了一个任务
// 如果已经开始使用 flushCallbacks 执行任务,那么将 pending 设为 false
if (!pending) {
pending = true;
if (useMacroTask) {
macroTimerFunc();
} else {
microTimerFunc();
}
}
if (!cb && typeof Promise !== 'undefined') {
return new Promise((resolve) => {
_resolve = resolve;
});
}
}
(5)2.6+的更新
这本书对应的Vue版本是2.5.16+,在这之后Vue的2.6版本对nextTick又进行了更新。这之后的Vue仍然是以微任务为默认的任务队列,但是降级方案与书中介绍的不同:
// Here we have async deferring wrappers using microtasks.
// In 2.5 we used (macro) tasks (in combination with microtasks).
// However, it has subtle problems when state is changed right before repaint
// (e.g. #6813, out-in transitions).
// Also, using (macro) tasks in event handler would cause some weird behaviors
// that cannot be circumvented (e.g. #7109, #7153, #7546, #7834, #8109).
// So we now use microtasks everywhere, again.
// A major drawback of this tradeoff is that there are some scenarios
// where microtasks have too high a priority and fire in between supposedly
// sequential events (e.g. #4521, #6690, which have workarounds)
// or even between bubbling of the same event (#6566).
var timerFunc;
// The nextTick behavior leverages the microtask queue, which can be accessed
// via either native Promise.then or MutationObserver.
// MutationObserver has wider support, however it is seriously bugged in
// UIWebView in iOS >= 9.3.3 when triggered in touch event handlers. It
// completely stops working after triggering a few times... so, if native
// Promise is available, we will use it:
/* istanbul ignore next, $flow-disable-line */
if (typeof Promise !== 'undefined' && isNative(Promise)) {
var p = Promise.resolve();
timerFunc = function () {
p.then(flushCallbacks);
// In problematic UIWebViews, Promise.then doesn't completely break, but
// it can get stuck in a weird state where callbacks are pushed into the
// microtask queue but the queue isn't being flushed, until the browser
// needs to do some other work, e.g. handle a timer. Therefore we can
// "force" the microtask queue to be flushed by adding an empty timer.
if (isIOS) {
setTimeout(noop);
}
};
isUsingMicroTask = true;
} else if (
!isIE &&
typeof MutationObserver !== 'undefined' &&
(isNative(MutationObserver) ||
// PhantomJS and iOS 7.x
MutationObserver.toString() === '[object MutationObserverConstructor]')
) {
// Use MutationObserver where native Promise is not available,
// e.g. PhantomJS, iOS7, Android 4.4
// (#6466 MutationObserver is unreliable in IE11)
var counter = 1;
var observer = new MutationObserver(flushCallbacks);
var textNode = document.createTextNode(String(counter));
observer.observe(textNode, {
characterData: true
});
timerFunc = function () {
counter = (counter + 1) % 2;
textNode.data = String(counter);
};
isUsingMicroTask = true;
} else if (typeof setImmediate !== 'undefined' && isNative(setImmediate)) {
// Fallback to setImmediate.
// Technically it leverages the (macro) task queue,
// but it is still a better choice than setTimeout.
timerFunc = function () {
setImmediate(flushCallbacks);
};
} else {
// Fallback to setTimeout.
timerFunc = function () {
setTimeout(flushCallbacks, 0);
};
}
function nextTick(cb, ctx) {
var _resolve;
callbacks.push(function () {
if (cb) {
try {
cb.call(ctx);
} catch (e) {
handleError(e, ctx, 'nextTick');
}
} else if (_resolve) {
_resolve(ctx);
}
});
if (!pending) {
pending = true;
timerFunc();
}
// $flow-disable-line
if (!cb && typeof Promise !== 'undefined') {
return new Promise(function (resolve) {
_resolve = resolve;
});
}
}
优先使用Promise,降级方案依次为MutationObserver、setImmediate、setTimeout
实际上在出版、2.5.2和2.6+之间,nextTick经历了多次变更,比较大的几次改动内容有:
(1)曾经将微任务全部去除(在2.5.2版本恢复),timerFunc检测顺序变为了setImmediate、MessageChannel、setTimeout。这是因为微任务的优先级太高,会导致一些问题
(2)在2.5.2版本,重新引入了微任务(就是这本书介绍的内容),这是因为当状态恰好在重绘之前改变时,任何地方都使用宏任务会导致一些很subtle的问题,因为宏任务的执行时间节点太靠后
(3)2.6版本又改回了使用微任务,这是权衡后的结果,源码中的注释也说明了,由于微任务的高优先级,在事件连续被触发或者同一事件的冒泡过程中仍然会有意外情况出现
$mount()
vm.$mount的目的是让Vue实例具有关联的DOM元素
Vue的构建版本分为完整版(vue.js)和只包含运行时的版本(vue.runtime.js),二者的差异在于是否带有编译器,是否有编译器的差异主要在于vm.$mount方法的表现形式。
完整版本功能
完整的构建版本vm.$mount会检查template或者el选项提供的模板是否已经转换成为渲染函数,如果没有会进入编译过程,将模板编译为渲染函数,之后在进入挂载和渲染的流程。
只包含运行时版本的vm.$mount没有编译步骤,默认实例上有渲染函数,没有花的会设置一个返回空的VNode渲染函数。
首先对Vue原型上的$mount方法进行了函数劫持:
const mount = Vue.prototype.$mount;
Vue.prototype.$mount = function (el) {
return mount.call(this, el)
}
通过函数劫持可以在原始功能之上新增一些其他功能
Vue.prototype.$mount = function (el) {
// query 方法用来获取 DOM 元素
el = el && query(el);
const options = this.$options;
// 当 render 选项不存在时才会将模板编译为渲染函数传递给 $options.render
if (!options.render) {
let template = options.template;
if (template) {
if (typeof template === 'string') {
// 如果 template 为 # 开头的字符串,会被当做选择符,如果不是以 # 开头,说明 template 是用户设置的模板,不需要处理,直接使用
if(template.charAt(0) === '#') {
template = idToTemplate(template);
}
} else if(template.nodeType) {
// 如果 template 不是字符串,根据 nodeType 判断是否是一个DOM元素,
template = template.innerHTML;
} else {
// 非生产环境下提示模板无效
}
} else if (el) {
// 如果没有设置 template 选项的话,会返回参数中提供的 DOM 元素的 HTML 字符串
template = getOuterHTML(el);
}
// 将模板编译为渲染函数
if(template) {
const {render} = compileToFunctions(template, options, this)
// 将通过模板编译得到的渲染函数挂载到 option 上
options.render = render;
}
}
return mount.call(this, el);
};
其中compileToFunctions用来将代码字符串转换成渲染函数(字符串→函数)
function createFunction(code) {
return new Function(code)
}
function compileToFunctions(template, options, vm) {
// 混合参数
options = extend({}, options);
// 检查缓存职工是否已经存在已经编译的模板
const key = options.delimiters ? String(options.delimiters) + template : template;
if (cache[key]) {
return cache[key];
}
// 将模板字符串转换为AST再转换为代码字符串
const compiled = compile(template, options);
// 将代码字符串转换为渲染函数
const res = {};
res.render = createFunction(compiled.render);
return (cache[key] = res);
}
将代码字符串转换为渲染函数利用了new Function,其中设置了缓存,保证编译过的渲染函数重复使用,提高性能
运行时版本功能
只包含运行时版本的vm.$mount包含了核心功能,完整版本函数劫持的功能就是先挂载到Vue原型上的核心功能:
Vue.prototype.$mount = function (el) {
el = el && inBrowser ? query(el) : undefined
return mountComponent(this, el)
}
$mount方法将ID转换为DOM元素后,使用mountComponent将Vue实例挂载到DOM元素上,也就是将模板渲染到指定的DOM元素上,而且是持续性的,后续当数据状态发生变化是,依然可以渲染到指定的DOM元素中
实现这个功能需要开启Watcher,Watcher会持续观察模板中绑定的数据,数据修改时它将得到通知,从而进行渲染操作。这个过程会一直持续到实例销毁。
function mountComponent(vm, el) {
// 如果实例上没有渲染函数,设置默认的渲染函数,这个渲染函数会创建一个注释节点,并且在开发环境中给出警告
if (!vm.$options.render) {
vm.$options.render = createEmptyVNode;
if (process.env.NODE_ENV !== 'production') {
// 警告
}
}
// 触发生命周期钩子
callHook(vm, 'beforeMount')
// 执行挂载操作,观察数据状态,状态改变持续进行渲染
vm._watcher = new Watcher(vm, () => {
vm._update(vm._render())
}, noop)
}
这里面,vm._update用来调用虚拟DOM的patch方法执行节点的比对与渲染操作,_vrender的作用是执行渲染函数,得到一份最新的VNode节点树,noop函数是一个空函数,为了满足Flow的类型检查需要
vm._update(vm._render())的作用是先调用渲染函数得到最新的VNode节点树,然后通过_update方法对最新的VNode和旧的VNode进行比对并更新DOM节点,进行渲染操作。
Watcher的第二个参数是一个函数,它会观察函数中读取的所有Vue实例上的响应式数据。当数据任何一个发生变化时,Watcher都会得到通知。
全局API的原理
Vue.extend
Vue.extend的作用是使用Vue构造器创建一个子类,参数所是一个包含组件选项的对象。
Vue.extend本质上实现的是对Vue的继承,继承方法使用了Object.create
Vue.extend = function (extendOptions) {
extendOptions = extendOptions || {};
const Super = this;
const SuperId = Super.cid;
const cachedCtors = extendOptions._Ctor || (extendOptions._Ctor = {});
if (cachedCtors[SuperId]) {
return cachedCtors[SuperId];
}
const name = extendOptions.name || Super.options.name;
if (process.env.NODE_ENV !== 'production') {
// 对组件名字进行校验,在开发模式下进行警告
}
const Sub = function VueComponent(options) {
this._init(options);
};
Sub.prototype = Object.create(Super.prototype);
Sub.prototype.constructor = Sub;
Sub.cid = cid++;
Sub.options = mergeOptions(Super.options, extendOptions);
Sub['super'] = Super;
// 处理 props、computed 等属性
// 缓存构造函数
cachedCtors[SuperId] = Sub;
return Sub;
};
为什么使用父元素的ID作为缓存的Key?首先要搞明白,这个缓存对象cachedCtors不是全局对象或是Vue上的属性,而是Vue.extend(extendOptions)方法中的参数extendOptions的属性,所以也就是说,当传入的参数相同、且父元素相同,才会使用缓存。
我原来理解的是cachedCtors是一个全局变量,应该使用子类的ID作为缓存。这样做的话,每次调用Vue.extend时,要判断全局缓存中是否存在子类的ID,但是这个时候子类还没产生,这个ID只能通过传进去的extendOptions得到,也就是说每个extendOptions要转换为一个唯一的key。这样做的本质还是将缓存的key与extendOptions关联,莫不如直接将缓存作为extendOptions的属性进行保存。
Vue.directive
Vue.directive(id, [definition])用来注册或者获取全局指令,如果definition不存在,直接在全局指令中获取key为id的指令并返回,如果definition是函数则默认监听bind的update事件,如果definition是对象,则这是用户自定义的指令对象,保存在options['directives']桑即可
Vue.filter和Vue.component是类似的,只是Vue.component返回的实际上是一个构造函数,是使用Vue.extend生成的子类,它的第二个参数definition可以是构造器也可以是选项对象,需要将其都处理为构造器,方法就是调用Vue.extend
这三个方法在是在一起实现的
Vue.options = Object.create(null);
// ASSET_TYPES = ['component', 'directive', 'filter']
ASSET_TYPES。forEach(type => {
Vue.option[type + 's'] = Object.create(null);
})
ASSET_TYPES。forEach(type => {
Vue[type] = function(id, definition) {
if (!definition) {
return this.options[type + 's'][id];
} else {
if (type === 'component' && isPlainObject(definition) {}
definition.name = definition.name || id;
definition = Vue.extend(definition);
if (type === 'directive' && typeof definition === 'function') {
definition = {bind: definition, update: definition};
}
this.options[type + 's'][id] = definition;
return definition;
}
}
})
Vue.use
Vue.use(plugin)用来安装插件,有三点要注意:
- 如果
plugin是对象,则必须包含install方法 - 如果
plugin是函数,那么会被视为install方法 - 同一个插件只能注册一次
Vue.use = function (plugin) {
const installedPlugins = (this._installedPlugins ||| (this._installedPlugins = []);
if (installedPlugins.indexOf(plugin) > -1) {
return;
}
// 其他参数
const args = toArray(arguments, 1);
args.unshift(this);
if (typeof plgugin.install === 'function') {
plugin.install.apply(plugin, args);
} else if (typeof plugin === 'function') {
plugin.apply(plugin, args);
}
installedPlugins.push(plugin);
return this;
}
Vue.mixin
Vue.mixin(mixin)用来注册全局的混入,插件作用可以用来向组件注册自定义行为,不推荐在应用代码中使用。
原理是将用户传入的mixin与Vue自身的options合并
Vue.mixin = function (mixin) {
this.options = mergeOptions(this.options, mixin);
return this;
}
它修改了Vue.options属性,会影响到之后创建的每个Vue实例
生命周期
4个阶段
分为以下几个阶段:
- 初始化阶段,在Vue实例上添加属性、事件和响应式数据
- 模板编译阶段,将模板编译为渲染函数
- 挂载阶段,将Vue实例挂载到Dom元素上,并持续追踪状态变化
- 卸载阶段,将自身从父组件中删除,取消实例依赖并移除事件监听器
new Vue()发生了什么
会首先进行一些初始化操作,然后进入模板编译阶段,最后进入挂载阶段。
初始化操作是通过this._init()方法完成的,_init是通过initMixin挂载到Vue构造函数的原型上,在_init内部完成了一系列的初始化流程
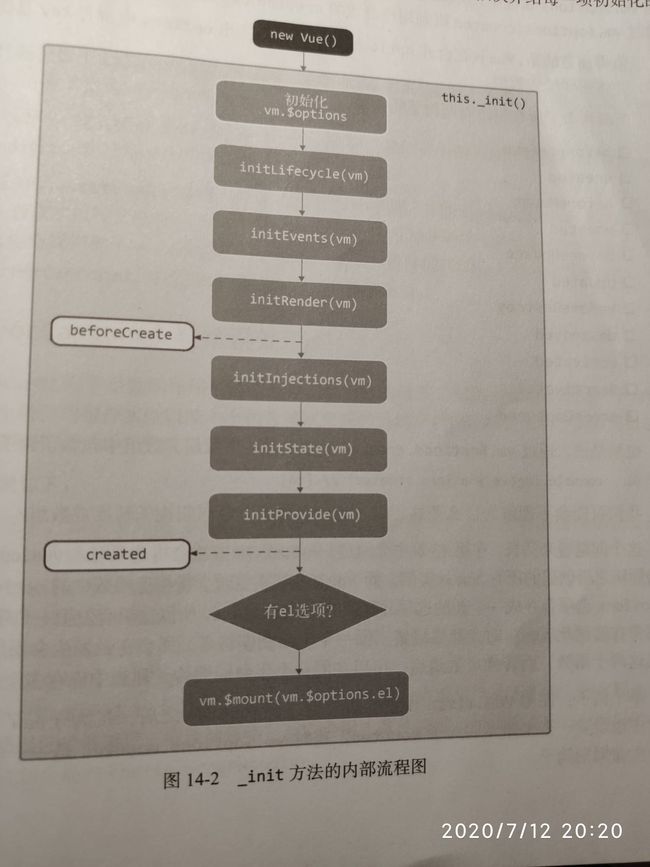
callHook函数
所有生命周期都会挂载到$options上,例如created会挂载到vm.$options.created,它是一个数组,数组中包含各个钩子函数,主要是因为全局的Mixin中,对应的生命周期会被触发多次
callHook函数通过传入生命周期的名称在vm.$options的对应生命周期的数组中,遍历执行每一个钩子函数。
每个钩子函数都会被用try...catch包括起来,利用handleError处理错误,他会一次执行父组件和全局的errorCaptured函数
export function callHook(vm, hook) {
const handlers = vm.$options[hook];
if (handlers) {
for (let i = 0, j = handlers.length; i < j; i++) {
try {
handlers[i].call(vm);
} catch (e) {
handlerError(e,j vm, `${hook} hook`)
}
}
}
}
错误处理
错误处理的钩子函数是errorCaptured,它可以捕获来自子孙组件的错误。它会从子组件逐渐向上传播,知道全局的config.errorHandler,可以通过返回false来阻止继续传播
function globalHandleError(err, vm, info) {
// 全局的错误处理的钩子,Vue.config.errorHandler
if (config.errorHanlder) {
try {
return config.errorHanlder.call(null, err, vm, infgo)
} catch (e) {
console.error(e)
}
console.log(error)
}
}
export function handlerError(err, vm, info) {
if (vm) {
let cur = vm;
// 通过遍历父组件的 errorCapture 钩子函数列表来讲错误向上传递
while ((cur = cur.$parent)) {
const hooks = cur.$options.errorCaptured;
if (hooks) {
for (let i = 0; i < hooks.length; i++) {
try {
const captured = hooks[i].call(cur, err, vm, info) === false;
// 如果返回 false,则终止向上传递
if (captured) {
return;
}
} catch (e) {
globalHandleError(e, cur, 'errorCaptured hook')
}
}
}
}
}
globalHandleError(err, vm, info)
}
初始化实例属性
初始化实例属性是生命周期第一步,以$开头的是给用户使用的外部属性,以_开头的内部使用
这一步是在initLifecycle完成的,它的参数vm是Vue实例,为vm添加对应的实例属性即可
初始化事件
初始化事件是将父组件在模板使用v-on注册的事件添加到子组件的事件系统中,子组件使用$emit触发
v-on如果写在组件标签上,这个事件就会注册到Vue事件系统中,如果写在平台标签上(例如div)那么就会注册到浏览器事件中
父组件模板中注册的事件,会保存在子组件的vm.$options._parentListeners中
初始化Inject
Inject在Props和Data后初始化,Provide在Props和Data之后初始化,这样在Data和Props中就可以使用注入的数据了。
Inject使用配置的key从当前租金啊读取内容,读不到就读取父组件,这是一个自底向上获取内容的过程,最终将找到的内容保存到实例this上
在获取到key值之前会对Inject传递的内容进行规格化,成为统一的对象(Vue的API大多支持多种形式,所以一般都会有这样类似的一个步骤来进行规格化)
Inject和Proivde支持Symbol作为key,在读取key的过程中,使用Reflect.ownKeys读取所有key(需要使用getOwnPropertyDescriptor提出不可枚举的),如果不支持Symbol时使用Object.keys获取key值
获取到用户设置Inject的所有属性名之后,可以循环属性名,自底向上搜索值,是通过while循环来递归实现的
for (let i = 0; i < keys.length; i++) {
const key = keys[i];
const provideKey = inject[key].from;
let srouce = vm;
while (source) {
if (source._provided && provideKey in source._provided) {
result[key] = source._provided[providedKey];
break;
}
source = source.$parent;
}
}
初始化状态
初始化状态包括Props、Methods、Data、Computed和Watch,这些都是在initState中完成的,初始化顺序也是精心安排的:
graph LR
Props-->Methods
Methods-->Data
Data-->Computed
Computed-->Watch
Data在Props后,可以再Data使用Props的数据,Watch在最后,就可以观察Props和Data了
初始化Props
Props的实现原理:父组件提供数据,子组件通过props字段选择自己需要哪些内容,Vue通过子组件的props选项将需要的数据筛选出来后添加到子组件的上下文中
(1)规格化Props
Props支持数组和对象,并且会将Props的名称驼峰化,将a-b这样的名称转换为aB
(2)初始化Props
初始化时会将Props对象的key值缓存起来,目的是为了更新Props时只需要遍历缓存的数组即可
根组件的Props会被转换为响应式,这是通过toggleObserving完成的,它是一个闭包函数,通过调用它并传入一个参数来控制objserve/index.js中的变量shouldObserve,来确定是否需要将数据转换为响应式的
Props的内容是通过validateProp完成的,除了布尔值之外的数据,在prop的value有数据时不需要特殊处理,没数据时检查默认值即可。而布尔类型的Prop有两种情况需要特殊注意:一种是key不存在,也就是父组件没有提供这个数据,并且也没有设置默认值,这是需要将value设置为false,另一种是key存在,但是value是空字符串或者value与key相等,这时value都会被设置为true,例如下面的情况:
在validateProp最后会通过asserProp来断言Prop是否有效并且在非生产环境下进行提示,要注意的是,判断值是否存在时使用了value == null,在使用==的情况下,null和undefined是相当的
null == undefined
// true
null == 0
// false
null == false
// false
null == ''
// false
undefined == 0
// false
undefined == false
// false
undefined == ''
// false
初始化Methods
初始化Methods时,只需要循环选项中的methods对象,并将每个属性依次挂载到vm上即可
初始化Data
Data中的数据会最终保存到vm._data中,然后在vm上设置一个代理,使得通过vm.x可以访问到vm._data.x属性,最后将data转换为响应式数据。
在保存之前,会对Data进行校验,是否与Props/Methods重复,是否使用了_或$开头命名
代理功能是通过proxy函数完成的:
const sharedPropertyDefinition = {
enumerable: true,
configurable: true,
get: noop;
set: noop;
}
export function proxy(target, sourceKey, key) {
sharedPropertyDefinition.get = function proxyGetter() {
return this[sourceKey][key];
}
ssharedPropertyDefinition.set = function proxySetter(val) {
this[sourceKey][key] = val
}
Object.defineProperty(target, key, sharedPropertyDefinition);
}
通过这个函数时,当我们访问target[key]时,实际上访问的就是target[sourceKey][key],也可以使用ES6的Proxy实现:
let a = {
x: {
y: 123
}
};
const proxy = (target, sourceKey) => {
return new Proxy(target, {
get(obj, key) {
return obj[sourceKey][key];
}
});
};
const proxyA = proxy(a, 'x');
console.log(proxyA.y); // 123
初始化Computed
计算属性会通过Watcher来观察它用到的所有属性的变化,当这些属性变化时,计算属性会将自身的Wathcer的dirty设置为true,说明自身的返回值变化了
计算属性实际上就是Vue实例vm上的一个getter属性,在定义计算属性时,会根据是否是服务端渲染判断是否shouldCache,如果是是服务端渲染,那么计算属性就是一个普通的getter,不具备缓存也不会观察其依赖数据的变化等响应式功能
如果shouldCache为true,也就是非服务端渲染时,会使用createComputedGetter函数创建一个具备缓存和响应式功能的getter:
function createComputedGetter(key) {
return function computedGetter() {
const watcher = this._computedWatchers &&^ this._cokmputedWatchers[key];
if (watcher) {
if (watcher.dirty) {
watcher.evalutate();
}
if (Dep.target) {
watcher.depend();
}
return watcher.value
}
}
}
这个函数是一个高阶函数,最终被设置到getter中的函数是高阶函数返回的computedGetter函数,在非服务端渲染环境下,每当计算属性被读取时,computedGetter函数都会被执行。
这个函数中根据wather.dirty属性判断计算属性依赖是否发生变化,计算属性的缓存就是通过这个判断来是实现的。
watcher.depend用于将读取计算属性的Watcher添加到计算属性所依赖的所有状态的依赖列表中,也就是说让读取计算属性的Watcher持续观察计算属性所依赖的状态的变化。
在Watcher的evaluate和depend方法专门用于实现计算属性相关功能
export default class Watcher {
constructor (vm, expOrFn, cb, options) {
// 隐藏无关代码
if (options) {
this.lazy = !!options.lazy;
} else {
this.lazy = false;
}
this.dirty = this.lazy;
this.value = this.lazy ? undefined : this.get();
}
evaluate () {
this.value = this.get();
this.dirty = false;
}
depend () {
let i = this.deps.length;
while (i--) {
this.deps[i].depend();
}
}
}
depend方法会遍历this.deps属性,这个属性中保存了计算属性用到的所有dep实例,保存了watcher所有依赖。遍历过程中执行了dep实例的depend方法,会将组件的Watcher实例添加到dep实例的依赖列表中。
换句话再说,this.deps是计算属性中用到的所有状态的dep实例,而依次执行了dep实例的depend方法就将组件的Watcher一次加入到这些dep实例的依赖列表中。这就实现了让组件的Watcher观察计算属性用到的所有状态变化。当这些状态变化时,组件的Watcher会受到通知,重新计算渲染操作。
新版本计算属性的实现
上面的原理是Vue2.5.2版本的是吸纳,在2.5.17中有了改动。因为原来的计算属性存在一个问题,当计算属性用到的状态发生了变化,但是最终计算属性返回值没有变化,按照上面的实现,组件Watcher仍然会触发渲染流程,因为Watcher观察的实际上时计算属性的依赖,而非计算属性的返回值
改动后的逻辑是,组件的Watcher不再观察计算属性用到的数据变化,而是让计算属性的Watcher得到通知后,计算一次计算属性的值,如果发现值与上一次计算出来的值不同,再去主动通知组件的Watcher进行重新渲染操作。
这时当计算属性的getter被触发时:
- 使用组件的Watcher观察计算属性的Watcher,也就是把组件的Watcher添加到计算属性的Watcher的依赖中,让计算属性的Watcher向组件的Watcher发送通知
- 使用计算属性的Watcher观察计算属性中用到的数据,当数据发生变化时,通知计算属性的Watcher
具体来看,createComputedGetter函数发生了变化:
function createComputedGetter(key) {
return function computedGetter() {
const watcher = this._computedWatchers &&^ this._cokmputedWatchers[key];
if (watcher) {
watcher.depend();
return watcher.evalutate();
}
}
}
depend方法执行后,会将读取计算属性的Watcher添加到计算属性的Watcher的依赖列表中,Watcher的代码也有很大改动:
export default class Watcher {
constructor(vm, expOrFn, cb, options) {
// 隐藏无关代码
if (options) {
this.computed = !! options.computed
} else {
this.computed = false;
}
this.dirty = this.computed;
if (this.computed) {
this.value = undefined;
this.dep = new Dep;
} else {
this.value = this.get();
}
}
update() {
if (this.computed) {
if (this.deps.subs.length === 0) {
this.dirty = true
} else {
this.getAndInvoke(() = > {
this.dep.notify();
})
}
}
}
getAndInvoke(cb) {
const value = this.get();
if (value !== this.value || isObject(value) || this.deep) {
const oldValue = this.value;
this.value = value;
this.dirty = false '
if(this.user) {
try {
cb.call(this.vm, value, oldValue);
} catch(e) {
handleError(e, this.vm, `callback for watcher "${this.expression}"`)
}
}
} else {
cb.call(this.vm, value, oldValue);
}
}
evaluate () {
if (this.dirty) {
this.value = this.get();
this.dirty = false;
}
return this.value();
}
depend () {
if (this.dep && Dep.target) {
this.dep.depend;
}
}
depend的改动比较大,这一次不再是将Dep.target添加到计算属性用到的所有数据的依赖列表中,而是就像Dep.target添加到计算属性的依赖列表中。this.dep用于在实例化Watcher时进行判断,如果为计算属性用的Watcher,则实例化一个dep实例并将其放在this.dep属性上
update中根据依赖数量分为了主动模式(Activated)和被动模式(Lazy),主动模式下会主动通知组件的Watcher,发送通知的代码是在getAndInvoke中执行,这个函数用来对比计算属性的返回值,只有计算属性的返回值发生了变化才会执行回调,通知组件进行重新渲染逻辑
初始化Watcher
初始化的思路是,循环watcher选项,对支持的各种Watcher的类型进行适配(createWatcher),然后在createWatcher中调用vm.$watch方法生成Watcher
初始化Provide
初始化Provide时只需要将provide选项添加到vm._provided即可
指令的秘密
指令的原理
在模板解析阶段,会将节点上的指令解析出来并添加到AST的directives属性中,随后directives属性会传递到VNode中,然后可以通过vnode.dasta.directives获取一个节点绑定的指令
当虚拟DOM更新时,会根据节点的对比结果触发指令的钩子函数(bind/inserted/update/componentUpdated/unbind)
v-if的原理
v-if的原理与自定义指令不同,v-if是在模板编译阶段实现的,生成代码时会生成一个特殊的代码字符串实现指令的功能
if
else
生成的代码字符串:
(has) ? _c('li', [_v("if")]) : _c('li', [_v("else"])
v-for的原理
v-for也是在模板编译阶段实现的
v-for {{index}}
编译后的代码字符串是:
_l((list), function (item, index) {
return _c('li', [_c("v-for ") + _s(index)])
})
_l是函数renderList的别名,_l函数会循环变量list并调用第二个参数所传递的函数,同时传递两个参数
v-on指令
v-on用在普通元素可以监听原生DOM事件,用在自定义元素组件时可以监听子组件触发的自定义事件。
当v-on绑定原生DOM事件时,使用了addEventListener事件。绑定的事件并不是原始的事件,而是使用withMacroTask包了一层,当事件触发时,如果回调中修改了数据而触发更新DOM的操作,那么该更新操作会被推送到宏任务的任务队列中。具体的细节可以参考$nextTick的实现原理
如果v-on绑定的事件使用了once修饰符,那么会在withMacroTask外面再使用createOnceHandler外面再包一层,createOnceHandler是一个高阶函数,返回的函数内部根据绑定的事件的返回值进行判断,返回值不为null的时候就会使用remove函数来解绑函数
remove调用的是removeEventListener方法,此时解绑的监听器有一个判断,如果handler._withTask存在,则解绑它,因为绑定的事件经过了withMacroTask的处理,绑定的事件并不是原始的事件,而是handler._withTask了
自定义指令的实现
自定义指令的处理逻辑监听了create、update、destroy钩子函数,在钩子函数触发时执行相关处理逻辑,都会执行的updateDirectives函数
在自定义指令的_update方法中,会根据oldDir与dir的对比判断要实现的逻辑。
如果oldDir不存在,那么这个指令是首次绑定到元素,此时调用callHook触发指令中的bind函数。如果该指令在注册时设置了inserted方法,会将该指令添加到dirsWithInsert,这样做可以保证在执行完所有指令的bind方法后再执行指令的inserted方法
oldDir存在时,说明指令之前绑定过了,应该更新指令,调用callHook函数触发指令的update函数,然后判断注册自定义指令时是否设置了componentUpdated方法,如果设置了,将该指令添加到dirsWithPostpatch列表中,这样让指令所在组件VNode和子VNode全部更新后在调用componentUpdateed方法
然后判断dirsWithInsert是否有元素,有的话循环dirsWithInsert并以此调用callHook执行每一个指令的inserted钩子函数。如果是新创建的节点,会使用mergeVNodeHook方法,将钩子函数(inserted)与虚拟节点现有的钩子函数(insert)合并在一起,在元素被插入到父节点后再执行指令的inserted方法
随后执行componentedUpdated的钩子函数,逻辑与上面相同,它需要使用mergeVNodeHook方法将调用事件推迟到postpatch钩子函数后执行
最后执行解绑unbind钩子,如果不是新增节点,并且指令在旧的指令中存在、在新的指令不存在,就可以使用callHook触发unbind钩子函数
虚拟DOM钩子函数
虚拟DOM在渲染时会触发的钩子函数如下:

过滤器的奥秘
过滤器的用法
过滤器可以在组件的选项中定义本地过滤器,也可以在创建Vue实例前定义全局过滤器
{{ message | filterA | filterB }}
使用的时候,过滤器函数会收到表达式的值作为参数,过滤器可以串联,后一个过滤器会收到前一个过滤器的返回值作为参数
过滤器是函数,所以可以接受参数
{{ message | filterA('a') }}
这时候,message是第一个参数,a是第二个参数
过滤器原理
{{ message | capitalize }}
上面的这个过滤器在模板编译阶段会编译为:
_s(_f('capitalize')(message))
_f是resolveFilter的别名,作用是从this.$options.filters找出注册的过滤器并返回
_s是toString的别名,执行的结果会保存到VNode的text属性中,用于渲染视图
如果是串联的过滤器,比如:
{{ message | capitalize | suffix }}
会被编译为:
_s(_f('suffix')(_f('capitalize')(message)))
前一个过滤器的返回值会作为参数传递给后一个过滤器
接受参数的过滤器的会加在过滤器的第二个参数中
resolveFilter的原理
resolveFilter用来查找过滤器:
const identity = _ => _;
export function resolveFilter (id) {
return resolveAsset(this.$options, 'filters', id, true) || identity
}
它调用resolveAsset查找过滤器,如果查找不到返回identity,identity的作用是原样返回参数
reoslveAsset查找过滤器,会在this.$options.filters中,首先查找本地是否有对应的id为key的过滤器,如果查不到会对id进行驼峰化、首字母大写的变化后,再在本地查找,如果还是找不到会到原型上上查找全局过滤器,如果还是找不到在非生产环境下会给出警告
解析过滤器
解析过滤器的过程就是一个对字符串进行处理,然后转换为上文编译后的字符串的过程
export function parseFilters (exp) {
let filters = exp.split('|');
let expression = filters.shift().trim();
let i;
if (filters) {
for (i = 0; i < filters.length; i++) {
expression = wrapFilter(expression, filters[i].trim());
}
}
return expression;
}
function wrapFilter (exp, filter) {
// 判断是否存在参数
const i = filter.indexOf('(');
if (i < 0) {
return `_f('${filter}'')(${exp})`;
} else {
const name = filter.slice(0, i);
const args = filter.slice(i + 1);
// 注意,返回值最后没有 ),是因为 args 的最后一位一定是 )
return `_f('${name}')(${exp}, ${args}`
}
}
首先使用split方法根据|将模板字符串切割为过滤器列表,并将列表中的第一个元素作为初始表达式,后续的元素进行遍历,不断拼接表达式
最佳实践
添加key
为列表添加key就不用多说了,建议如果在使用v-if/v-else/v-if-else时,如果元素类型相同最好也添加key
因为Vue在虚拟节点对比时,如果发现切换的元素类型相同,它会修补已存在的元素,而不是将旧的元素移除,为了避免修补过程中出现意料之外的副作用,可以添加key,那么会直接将旧的元素移除,并且在相同的位置添加新的元素
路由切换组件不变的情况
从/detail/:id路由切换id跳转时,组件不会发生变化,因为VueRouter进行了组件复用,解决方法有:
- 使用路由导航守卫
beforeRouteUpdate - 观察
$route对象的变化 - 为
key
区分Vuex与Props的使用边界
在业务组件使用Vuex维护状态,不同组件统一操作Vuex中的状态
通用组件使用Props和事件进行父子组件通信,通用组件不需要兄弟组件通信,与业务解耦
避免v-for与v-if同时使用
不要将v-for与v-if放在同一个元素上,在下面两种情况有不同的处理:
列表中的某些元素不需要展示
{{ user.name }}
不建议这样去做,因为v-for比v-if优先级更高,因为即使只渲染列表的一小部分元素,每次重新渲染时都会遍历整个列表。
推荐的做法是,将循环的列表渲染替换为一个根据v-if的逻辑确定的计算属性,这样做可以充分利用计算属性的缓存,并且减少遍历的范围
{{ user.name }}
声明计算属性:
computed: {
activeUsers () {
return this.users.filter(v => v.isActive)
}
}
隐藏整个列表
- {{ user.name }}
如果需要在某些情况下将整个列表异常,那么将v-if移动到容器元素上:
>
- {{ user.name }}
如果需