【Hadoop】HDFS分布式文件系统
HDFS分布式文件系统
- HDFS基本知识
- 前言
- 目标
- 局限性
- HDFS相关概念
- 块(Block)
- HDFS架构
- 名称节点(NameNode)
- 数据节点(DataNode)
- 第二名称节点(Secondary NameNode)
- 体系结构图示
- HDFS核心设计
- Block大小设置
- HDFS存储原理
- 数据复制(流水线)
- HDFS 数据读写(使用Java API)
- 读文件
- 1.调用java.net.URL(简单粗暴法)
- 2.调用FileSystem类
- 3.代码实战练习(读文件)
- 写文件
- 代码实战练习(写文件)
HDFS基本知识
前言
1. 分布式文件系统是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。HDFS是Google的GFS的开源实现。
2. HDFS具有很好的容错能力,并且兼容廉价的硬件设备,因此可以以较低的成本利用现有机器实现大流量和大数据量的读写。
3. 分布式文件系统在物理结构上由计算机集群中多个节点构成。节点分为两部分:
- “主节点”:Master Node 或 “名称节点”:NameNode;
- ”从节点”:Slave Node 或 “数据节点”:DataNode;
4. NameNode和DataNode之间的交互是通过RPC进行的。RPC(Remote Procedure Call Protocol)是远程调用协议,其对底层网络协议是透明的,跨越了传输层和应用层,是Hadoop是最重要的底层核心协议之一。
目标
HDFS在设计上要实现以下目标:
-
1)兼容廉价的硬件设备
-
2)流数据读写:为了提高数据吞吐率,以流式方式来访问文件系统数据
-
3)大数据集
-
4)简单的文件模型:采用“一次写入,多次读取”模型,文件一旦完成写入,关闭后就无法再次写入,只能被读取。
-
5)强大的跨平台兼容性
局限性
-
1)不适合低延迟数据访问:对于低延时要求的应用,HBase更好
-
2)无法高效存储大量小文件:名称节点来管理文件系统元数据时,元数据会被保存在内存中使客户端可以快速获取,访问大量小文件时影响性能
-
3)不支持多用户写入及任意修改文件。
HDFS相关概念
块(Block)
- 默认一个块大小是64MB,在HDFS中的文件会被拆分成多个块,每个块作为独立的单元进行存储。HDFS在文件块大小设置上要远远大于普通文件系统,以期在处理大规模文件时能得到更好的性能。但是,通常MapReduce中的Map任务一次只处理一个块中的数据,如果启动的任务太少会降低作业并行处理速度,所以块的大小设置也不易过大。
HDFS架构
名称节点(NameNode)
-
名称节点主要负责文件和目录的创建,删除和重命名等,同时管理着数据节点和文件块的映射关系。因此客户端只有访问名称节点才能找到请求的文件块所在的位置,进而到相应位置读取所需文件块。
-
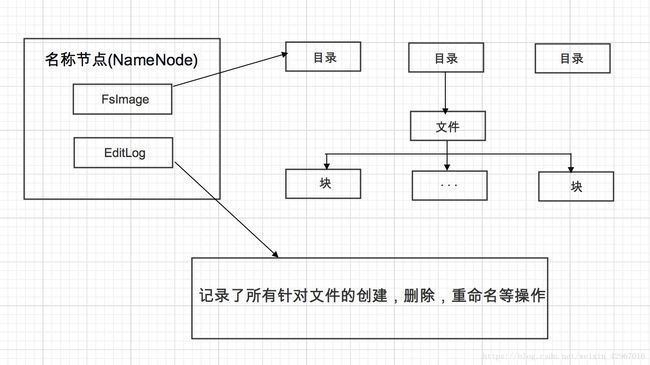
同时,名称节点还负责管理分布式文件系统的命名空间,保存了两个核心的数据结构,即FsImage(元数据镜像文件)和EditLog(日志文件)。FsImage用于维护文件系统树以及文件树中所有文件和文件夹的元数据(文件的名称,位置,副本数,拥有者,组,权限,存储块,各块在哪些节点上)。操作日志文件EditLog中记录了所有针对文件的创建,删除,重命名等操作。
名称节点启动时,会将FsImage的内容加载到内存中,然后执行EditLog中的各项操作,使得内存中的元数据保持最新,操作完成后,会创建新的FsImage文件和一个空的EditLog。
数据节点(DataNode)
-
数据节点负责数据的存储和读取。在存储时,由名称节点分配存储位置,然后由客户端把数据直接写入相应数据节点;在读取时,客户端从名称节点获得数据节点和文件块的映射关系,从而找到相应位置访问文件块。数据节点还要根据名称节点的命令创建,删除数据块和冗余复制。
-
每个数据节点会周期性向名称节点发送"心跳"信息,报告自己的状态,没有按时发送心跳信息的节点会被标记为"宕机",不会给他分配任何I/O请求。
第二名称节点(Secondary NameNode)
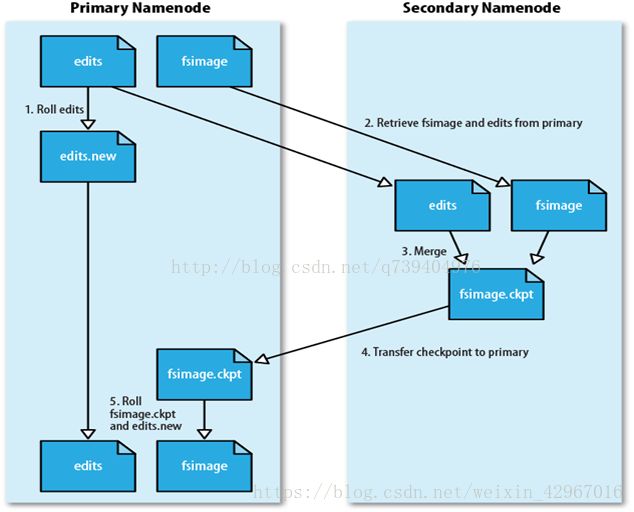
- 在设计中,HDFS采用第二名称节点"Secondary NameNode",以解决实际操作中EditLog逐渐变大的问题。
功能:
- 首先,可完成EditLog和FsImage的合并操作,减小EditLog文件大小,缩短名称节点重启时间;
- 其次,作为名称节点的"检查点",保存名称节点的元数据信息,起到"冷备份"的作用。
体系结构图示

HDFS核心设计
Block大小设置
前文我们有提到,在这里不进行过分的赘述。
HDFS存储原理
-
1.数据的冗余存储
HDFS采用了多副本方式对数据进行冗余存储,通常一个数据块的多个副本会被分布到不同数据节点上。可加快数据传输速度,容易检查数据错误,保证数据可靠性。 -
2.数据副本存取策略(机架感知:就近写入,就近读取)
HDFS默认的冗余复制因子是3,每一个文件块会被同时保存到3个地方。其中,两份副本在同一机架的不同机器上,第三个副本放在不同机架的机器上面。

数据复制(流水线)
- 当客户端向HDFS文件写数据的时候,一开始是写入本地的临时文件,假设该文件的复制因子是3,那么客户端会从NameNode获取一张DataNode列表来存放副本。然后客户端再向第一个DataNode传输数据,第一个DadaNode会一小部分一小部分(4KB)地接受数据,将每个部分写入本地仓库,同时传输给第二个DataNode。其他节点也是这样,边接受边传输,直到最后一个副本节点,只接受并存储。
HDFS 数据读写(使用Java API)
读文件
1.调用java.net.URL(简单粗暴法)
- (1)调用java.net.URL类获得输入流
- (2)通过IOUtils操作输入流对文件读取
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
//识别URL路径
}
InputStream in = new URL("hdfs://bigdata-hadoop.wbc.com/user/wbc/datas/").openStream();
//do something for in
IOUtils.closeStream(in);
2.调用FileSystem类
- (1)实例化FileSystem对象
在FileSystem类中有两种静态方法可以获得FileSystem类对象
1. public static FileSystem get(Configuration conf)
//默认加载core-site.xml,并返回默认文件系统。
2. public static FileSystem get(URI uri, Configuration conf)
//根据传入的完整的URI来确定返回的文件系统类型。根据传入的完整的URI来确定返回的文件系统类型。
- (2)通过.open()方法打开文件,DistributedFileSystem会创建输入流FSDataInputStream对象(两种)。
对于HDFS而言,具体的输入流就是DFSInputStream。1. public FSDataInputStream open (path f) //默认使用4KB的缓冲大小 2. public abstract FSDataInputStream open (Path f, int bufferSize) //自定义缓存大小
为了深入了解FSDataInputStream,可以看一下它的源码
//截取部分源码
1.public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable,
ByteBufferReadable, HasFileDescriptor, CanSetDropBehind, CanSetReadahead,
HasEnhancedByteBufferAccess, CanUnbuffer, StreamCapabilities {
//可以看到FSDataInputStream实现了Seekable和PositionedReadable接口,因此实现了随机查找和读取的方法
2. public long getPos() throws IOException {
return ((Seekable)in).getPos();
}
//用于查询当前位置相对于文件开始处的偏移量
3.public int read(long position, byte[] buffer, int offset, int length)
throws IOException {
return ((PositionedReadable)in).read(position, buffer, offset, length);
}
//从文件给定位置开始读取length长度的字节数到buffer中,并返回读取到字节数目,(且是安全函数)
4.public void readFully(long position, byte[] buffer)
throws IOException {
((PositionedReadable)in).readFully(position, buffer, 0, buffer.length);
}
//从文件给定位置开始读取buffer长度的字节数到buffer中,并返回读取到字节数目,(且是安全函数)
4.public void readFully(long position, byte[] buffer, int offset, int length)
throws IOException {
((PositionedReadable)in).readFully(position, buffer, offset, length);
}
//readFully重载方法。读取length长度的字节数组到buffer中。(安全)
5.public void seek(long desired) throws IOException {
((Seekable)in).seek(desired);
}
//从文件的开始搜索到给定的偏移量,下一个read()函数将从该位置偏移开始读取
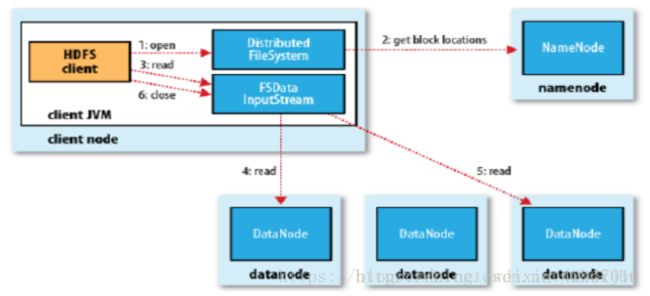
- (3)在DFSInputStream的构造函数中,输入流通过ClientProtocal.getBlockLocations()远程调用名称节点,获得文件开始部分数据块存放位置。
对于该数据块,名称节点返回保存该数据块的所有数据节点的地址,同时根据距离客户端的远近对数据节点进行排序,然后,DistributedFileSystem会利用DFSInputStream来实例化FSDataInputStream,返回给客户端,同时返回了数据块的数据节点地址。 - (4)获得输入流FSDataInputStream后,客户端调用read()函数开始读取数据。输入流根据排序结果,选择距离客户端最近的数据节点建立连接并读取数据。
- (5)数据从该数据节点读到客户端。当该数据块读取完毕后,FSDataInputStream关闭与该数据节点的连接。
- (6)输入流通过getBlockLocations()方法查找下一个数据块(如果客户端缓存中已包含该数据块的位置信息,就不需要调用该方法)
- (7)找到该数据块的最佳数据节点,读取信息。
- (8)当客户端读取完毕数据时,调用FSDataInputStream的close()函数,关闭数据流。
3.代码实战练习(读文件)
下面通过一个简单的测试例子来说明如何读取文本文件。
package com.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.net.URI;
public class HdfsRead {
public static void main(String[] args) throws Exception{
String uri = args[0];
//读取args数组的第一个元素
Configuration conf = new Configuration();
//读取配置文件
FileSystem hdfs = FileSystem.get(URI.create(uri),conf);
//实例化FileSystem对象
FSDataInputStream in = null;
try{
in = hdfs.open(new Path(uri));
//相当于 Path path = new Path(uri)-> hdfs.open(path)
//调用open()方法获得输入流名为in的FSDataInputStream对象
byte buffer[] = new byte[256];
int bytesRead = 0;
while ((bytesRead = in.read(buffer)) > 0){
//读取文件
System.out.write(buffer, 0, bytesRead);
//打印输出
}
}finally {
IOUtils.closeStream(in);
//读取完毕关闭流
}
}
}
将程序打包并提交到hdfs上运行
hadoop jar HdfsRead.jar com.hadoop.hdfs.HdfsRead /user/datas/hdfs_read.txt
//hadoop + jar + jar名 + class名 + 文件路径
- 当然,文件目录和URI参数也可以由用户在程序中定义。
写文件
-
(1)通过FileSystem类获得HDFS文件系统对象。
-
(2)客户端通过FileSystem.create()创建文件,相应地,DistributedFileSystem具体实现了FileSystem,因此,调用create()方法后,DistributedFileSystem会创建输出流FSDataOutputStream。
对于HDFS而言,具体的输出流就是DFSOutputStream。
-
这里介绍FileSystem中两个与写文件相关的重要方法:create()和append(),通过使用这两个函数可以得到文件输出流FSDataOutputStream的对象。
-
FSDataOutputStream继承了java.io.DataOutputStream,实现了Syncable()接口,通过write()函数就可以对HDFS上的文件进行写入操作
(1)create ()方法
public FSDataOutputStream create (Path f) throws IOException
//如果文件存在则默认覆盖
public FSDataOutputStream create (Path f, boolean overwrite) throw IOException
//可以指定是否覆盖
(2)如果用户要写入一个大文件,通常需要程序反馈写入进度,这时可以调用以下接口:
public FSDataOutputStream create (Path f, Progressable progress) throw IOException
public void progress () { System.out.print ("."); }
//该方法也会覆盖已存在文件,需要用户实现progress()函数。每写入64KB打印一个点号。
(3)append()方法
1.public abstract FSDataOutputStream append(Path f, int bufferSize, Progressable progress) throws IOException
//bufferSize:写入时使用的缓冲buffer大小
//progress:进度报告
2.public FSDataOutputStream append (Path f) throws IOException
//相当于调用append(f, getConf().getInt("io.file.buffer.size",4096),null)函数
3.public FSDataOutputStream append (Path f, int bufferSize) throws IOException
//相当于调用append(f,bufferSize,null)函数
-
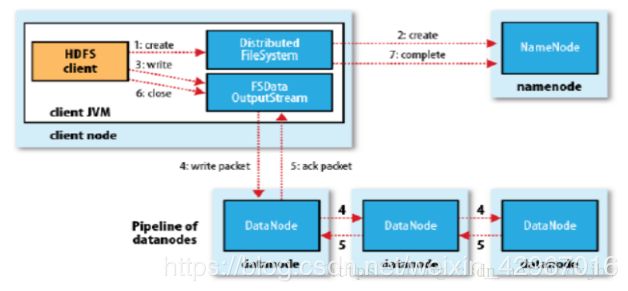
(3)DistributedFileSystem通过RPC远程调用名称节点,在文件系统的命名空间中创建新文件。远程方法调用结束后,DistributedFileSystem会利用DFSOutputStream来实例化FSDataOutputStream,返回给客户端,客户端使用这个输出流写入数据。
-
(4)获得输出流FSDataOutputStream以后,客户端调用输出流的write()方法向HDFS中对应的文件写入数据。
-
(5)客户端向输出流FSDataOutputStream中写入数据会首先被分成一个个分包,放入DFSOutputStream对象的内部队列。输出流FSDataOutputStream会向名称节点申请保存文件和副本数据块的若干个数据节点,这些数据节点形成一个数据流管道,队列中的分包被打包成数据包,进行流水线复制传输。
-
(6)接收到数据的数据节点向发送者发送“确认包”(ACK Packet)。确认包随数据流管道逆流而上,最终发往客户端,当客户端收到应答时,将对应分包从内部队列移除。不断执行(3)~(5)步,知道数据全部写完。
-
(7)客户端调用close()方法关闭输出流。当DFSOutputStream对象内部队列中的分包都收到应答以后,可使用ClientProtocol.complete()方法通知名称节点关闭文件,完成一次写文件过程。
代码实战练习(写文件)
下面通过一个简单的测试例子来说明如何写入文本文件。
package com.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.util.Progressable;
import java.io.IOException;
public class HdfsWrite {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//加载配置文件
FileSystem local = FileSystem.getLocal(conf);
//获取本地文件系统对象
FileSystem hdfs = FileSystem.get(conf);
//获取hdfs文件系统对象
Path localdir = new Path(args[0]);
//获取本地目录
Path hdfsFile = new Path(args[1]);
//获取hdfs文件夹目录
try{
FileStatus[] inputFiles = local.listStatus(localdir);
//得到本地文件系统目录下所有文件信息
FSDataOutputStream out = hdfs.create(hdfsFile, new Progressable() {
public void progress() {
System.out.print(".");
}
//调用反馈进度函数
});
//调用create()函数,获得输出流
for(int i = 0;i < inputFiles.length; i++){
System.out.println(inputFiles[i].getPath().getName());
//输出文件名
FSDataInputStream in = local.open(inputFiles[i].getPath());
//得到FSDataInputStream对象
byte buffer[] = new byte[512];
int bytesRead = 0;
while ((bytesRead = in.read(buffer)) > 0){
out.write(buffer,0,bytesRead);
//写入文件
}
in.close();
}
out.close();
}catch (IOException e){
e.printStackTrace();
}
}
}
提交运行方法与读文件相同