linux-shell编程
环境变量
配置环境变量
#vim /etc/profile export EDITOR=vim //设置默认的编辑器为vim
#source /etc/profile
#crontab -e //有颜色
一些环境变量:(系统定义的) :
/etc/profile
/etc/bashrc
~/.bashrc
~/.bash_profile
帮助
系统的4种帮助方法 (以ls为列)
ls --help
info ls
type ls
man ls
(man 1 用户命令 * man 2 系统调用 man 3 库调用 man 4 特殊文件 man 5 配置文件 * man 6 游戏 man 7 杂项 man 8 系统命令 * makewhatis 维护man
man -f passwd 索引,查看在哪个章节 man -k passwd | grep --color passwd )
SHELL
- 命令和文件自动补全
- 通配符

- 快捷键
^c 终止前台运行的程序
^d 退出 等价exit
reset 屏幕乱码,重置屏幕
^a 光标移到命令行的最前端 //编辑命令
^e 光标移到命令行的后端 //编辑命令
^u 删除光标前所有字符 //编辑命令
^k 删除光标后所有字符 //编辑命令
- 其他

- 转义字符
\ 反斜线 \a 报警符(BEL) \b 退格符 \c 禁止尾随的换行符 \f 换页符 \n 换行符 \r 回车符 \t 水平制表符 \v 纵向制表符
shell脚本的写法
脚本的名字: .sh为结尾
作用:使用对应的后缀名,为了不给他人造成麻烦
脚本内容第一行:#!/bin/bash
作用:声明命令解释器,如果当前环境和脚本的环境一致,可以不用声明
脚本内容的第二行:说明脚本的内容,以及版本信息
执行脚本:

注意:最后两种方法执行脚本时,对于管理员来说只需要由x权限,但是对于普通用户来说需要 r 和 x 的权限
调试脚本:
#sh -n 02.sh #仅调试 syntax error
#sh -vx 01.sh #以调试的方式执行
#cat 01.sh #仅调试脚本的某一部分
变量
1. 自定义变量
定义变量: 变量名=变量值 变量名必须以字母或下划线开头,区分大小写 ip1=192.168.2.115
引用变量: $变量名 或 ${变量名}
查看变量: echo $变量名 set(所有变量:包括自定义变量和环境变量)
取消变量: unset 变量名
作用范围: 仅在当前shell中有效
2. 环境变量
定义环境变量: 方法一 export back_dir2=/home/backup
方法二 export back_dir1 将自定义变量转换成环境变量
引用环境变量: $变量名 或 ${变量名}
查看环境变量: echo $变量名 env 例如env |grep back_dir2
取消环境变量: unset 变量名
变量作用范围: 在当前shell和子shell有效
set 查看所有变量(包括自定变量和环境变量)
env(environment) 查看环境变量
# vim /etc/profile
export EDITOR=vim //设置默认的编辑器为vim
# source /etc/profile
# crontab -e //有颜色
系统环境变量:
留意的一些环境变量:(系统定义的) /etc/profile /etc/bashrc ~/.bashrc ~/.bash_profile
# echo $PS1 //当前shell提示符
# echo $HOSTNAME //当前主机名
# echo $USER //当前用户
# echo $UID //当前用户的UID
# echo $SHELL //当前使用的shell
# echo $HISTSIZE //历史命令保存条数
# echo $MAIL //当前用户邮件路径
# echo $PATH //会影响命令搜索路径
# echo $RANDOM //产生0-32767的随机值
# echo $(($RANDOM%100+1)) //产生1-100的随机数99/100+1
# echo $(($RANDOM%10)) //产生0-9的随机数
# echo $LANG
# date

3. 位置变量
$1 $2 $3 $4 $5 $6 $7 $8 $9 ${10}
4. 预定义变量
$0 脚本名
$* 所有的参数
$@ 所有的参数
$# 参数的个数
$$ 当前进程的PID
$! 上一个进程的PID
$? 上一个命令的返回值
参考:影响bash shell的其它文件
bash登录和欢迎信息
/etc/issue 登录前显示的信息(本地登录) Ctrl+Alt+F2
/etc/issue.net 登录前显示的信息(网络登录)
/etc/motd 登录后显示的信息
变量的定义方式:
1. 显式赋值
变量名=变量值
2. read 从键盘读入变量值
read -p "提示信息: " -t 5 -n 6 变量名
-t:时间
-n:输入的字符数
stty -echo //隐藏显示,不显示输入的密码
stty echo //恢复正常
shift命令用于对参数的移动(左移) eg:shift 2 移动2个
变量的运算:
1.整数运算

2. 小数运算
echo "2*4" |bc
echo "2^4" |bc
echo "scale=2;6/4" |bc
awk 'BEGIN{print 1/2}'
3.开方运算
echo "sqrt(100)" | bc
echo "sqrt(10000)" | bc
4.进制之间的转换
# echo "ibase=2;11111111" |bc //将二进制转换成十进制
# echo "ibase=10;obase=16;11" |bc //将十进制转换成16进制
# echo "ibase=10;obase=2;255" |bc //将十进制转换成二进制
变量"内容"的删除和替换:
==="内容"的删除===
# url=www.sina.com.cn
# echo ${#url} 获取变量值的长度
15
# echo ${url} 标准查看
www.sina.com.cn
# echo ${url#*.} 从前往后,最短匹配
sina.com.cn
# echo ${url##*.} 从前往后,最长匹配 贪婪匹配(找到最靠后的一个 . )
cn
# url=www.sina.com.cn
# echo ${url}
www.sina.com.cn
# echo ${url%.*} 从后往前,最短匹配
www.sina.com
# echo ${url%%.*} 从后往前,最长匹配 贪婪匹配(找到靠前的一个 . )
www
# echo ${url#*sina.}
com.cn
# echo $HOSTNAME
xiaochen.uplooking.com
# echo ${HOSTNAME%%.*}
xiaochen
# echo ${url:0:5}
www.s
# echo ${url:5:5}
ina.c
==="内容"的替换===
# url=www.sina.com.cn
#
# echo ${url/sina/baidu}
www.baidu.com.cn
# url=www.sina.com.cn
#
# echo ${url/n/N}
www.siNa.com.cn
# echo ${url//n/N} 贪婪匹配
www.siNa.com.cN
===变量的替代===
${变量名-新的变量值}
变量没有被赋值:会使用“新的变量值“ 替代
变量有被赋值(包括空值): 不会被替代
# unset var1
#
# echo ${var1}
# echo ${var1-aaaaa}
aaaaa
# var2=111
# echo ${var2}
# echo ${var2-bbbbb}
111
#
# var3=
# echo $var3
# echo ${var3-ccccc}
${变量名:-新的变量值}
变量没有被赋值(包括空值):都会使用“新的变量值“ 替代
变量有被赋值: 不会被替代
# unset var1 var1不给他赋值
# unset var2 var2赋空值
# unset var3 var3赋值为111
#
# var2=
# var3=111
# echo ${var1:-aaaa}
aaaa
# echo ${var2:-aaaa}
aaaa
# echo ${var3:-aaaa}
111
条件测试
Shell 条件测试
格式1: test 条件表达式
格式2: [ 条件表达式 ]
格式3: [[ 条件表达式 ]]
===文件测试 [ 操作符 文件或目录 ]
根据文件类型判断
-d 文件存在必须是个目录
-e 有文件名存在就行不管类型
-f 文件存在而且是个标准普通文件
-h 文件存在并且为符号链接文件
-L 文件是软链接文件
-r 判断文件权限是否有r权限(针对于root用户不生效)
-w 写权限
-x 执行权限
===数值比较 [ 整数1 操作符 整数2 ]
[ 1 -gt 10 ] 大于
[ 1 -lt 10 ] 小于
[ 1 -eq 10 ] 等于
[ 1 -ne 10 ] 不等于
[ 1 -ge 10 ] 大于等于
[ 1 -le 10 ] 小于等于
-a -o && ||

===字符串比较
# [ -z "$BBB" ] 字符长度是为0
# [ -n "$BBB" ] 字符长度不为0
*变量为空 或 未定义: 长度都为0
# [[ "$USER" =~ ^r ]];echo $? //使用正则
判断变量是不是数字:
# [[ "$num10" =~ ^[0-9]+$ ]];echo $?
() 子shell中执行
(()) 数值比较,运算 C语言
$() 命令替换 等同于 ``
$(()) 整数运算等同于$[]
[] 条件测试
[[]] 条件测试,支持正则 =~ ,支持&& ||
$[] 整数运算
& 后台运行
&> 混合输出重定向
&& 逻辑判断


数组
普通数组:只能使用整数作为数组索引
关联数组:可以使用字符串作为数组索引
一、普通数组
定义数组:
方法一: 一次赋一个值
数组名[下标]=变量值
# array1[0]=pear
# array1[1]=apple
# array1[2]=orange
# array1[3]=peach
方法二: 一次赋多个值
# array2=(tom jack alice)
# array3=(tom jack alice "bash shell")
查看数组:
# declare -a
declare -a array1='([0]="pear" [1]="apple" [2]="orange" [3]="peach")'
declare -a array2='([0]="tom" [1]="jack" [2]="alice")'
访问数组元数:
# echo ${array1[0]} 访问数组中的第一个元数
# echo ${array1[@]} 访问数组中所有元数 等同于 echo ${array1[*]}
# echo ${#array1[@]} 统计数组元数的个数
# echo ${!array2[@]} 获取数组元数的索引
# echo ${array1[@]:1} 从数组下标1开始
# echo ${array1[@]:1:2} 从数组下标1开始,访问两个元素
遍历数组:
方法一: 通过数组元数的个数进行遍历
方法二: 通过数组元数的索引进行遍历
二、关联数组
定义/申明关联数组:
# declare -A ass_array1
# declare -A ass_array2
方法一: 一次赋一个值
数组名[索引]=变量值
# ass_array1[index1]=pear
# ass_array1[index2]=apple
# ass_array1[index3]=orange
# ass_array1[index4]=peach
方法二: 一次赋多个值
# ass_array2=([index1]=tom [index2]=jack [index3]=alice [index4]='bash shell')
查看数组:
# declare -A
declare -A
ass_array1='([index4]="peach" [index1]="pear" [index2]="apple" [index3]="orange" )'
declear -A ass_array2='([index4]="bash shell" [index1]="tom" [index2]="jack" [index3]="alice" )'
访问数组元数:
# echo ${ass_array2[index2]} 访问数组中的第二个元数
# echo ${ass_array2[@]} 访问数组中所有元数 等同于 echo ${array1[*]}
# echo ${#ass_array2[@]} 获得数组元数的个数
# echo ${!ass_array2[@]} 获得数组元数的索引
函数
local i =1 ;//定义局部变量 只能在函数内部用
方法一:
函数名() {
函数要实现的功能代码
}
方法二:
function 函数名 {
函数要实现的功能代码
}
二、调用函数
函数名
函数名 参数1 参数2
函数也可以让我们死机 如下:
:(){ :|:& };:
文件锁
防止进程被重复运行
========================================================
每一个进程在运行的时候都有一个pid,这个pid会存放在对应的文件中,同时在/proc/目录下生成一个以pid号命名的目录,如果有这样一个目录,说明进程正在运行,就不能重复运行,如果没有,就可以再次运行了。这就叫文件锁
[root@xiaochen scripts]# cat lock.sh
#!/bin/bash
if [ -f /tmp/lock.pid ]
then
pid=`cat /tmp/lock.pid`
if [ -d /proc/$pid ]
then
echo "脚本已运行!!!!!"
exit
fi
fi
echo $$ > /tmp/lock.pid
sleep 100000
测试:
终端一:
# sh lock.sh
终端二:
# sh lock.sh
脚本已运行!!!!!
expect
安装命令: yum install expect
#!/bin/expect
set timeout 30
spawn ssh [email protected]
expect "(yes/no)?"
send "yes\r"
expect "password:"
send "123456\r"
interact
注释:
1、#!/usr/bin/expect
声明命令解释器
2、set timeout 30
设置超时时间,单位时间是s,默认是10s
3、spawn ssh [email protected]
spawn 是进入expect环境后才可以执行的expect内部命令,在shell命令行上找不到此命令
他主要的功能是给ssh运行进程加个壳,用来传递交互指令
4、expect "(yes/no)?"
判断上面输出结果中是否包含什么字符串,如果包含则返回,否则超时继续
5、send "yes\r"
这里就是执行交互动作,与手工输入密码的动作等效,\r相当于是回车
6、interact
执行完成后保持交互状态,把控制权交给控制台,这个时候可以手工操作了,如果没有这一句登录完成后退出,而不是留在远程终端上。如果只是登录过去执行一段命令就退出,可改为expect eof
先使用这个脚本将密钥都传输到其他主机上,然后就可以实现非交互式的操作了
正则表达式
--基本正则表达式元字符
^ 行首定位符 ^love
$ 行尾定位符 love$
. 匹配单个字符 l..e
* 匹配前导符0到多次 ab*love
[] 匹配指定范围内的一个字符 [lL]ove
[ - ] 匹配指定范围内的一个字符 [a-z0-9]ove
[^] 匹配不在指定组内的字符 [^a-Z0-9]ove
\ 用来转义元字符 love\.
\< 词首定位符 \ 词尾定位符 love\>
\(..\) 匹配稍后将要使用的字符的标签
x\{m\} 字符x重复出现m次
x\{m,\} 字符x重复出现m次以上
x\{m,n\} 字符x重复出现m到n次
=扩展正则表达式元字符
+ 匹配一个或多个前导字符 [a-z]+ove
? 匹配零个或一个前导字符 lo?ve
a|b 匹配a或b love|hate
() 组字符 love(able|rs) (ov)+
(..)(..)\1\2 标签匹配字符 /(love)able/\1er/
x{m} 字符x重复m次 o{5}
x{m,} 字符x重复至少m次 o{5,}
x{m,n} 字符x重复m到n次 o{5,10}
grep
grep: 在文件中全局查找指定的正则表达式,并打印所有包含该表达式的行
egrep: 扩展的egrep,支持更多的正则表达式元字符
fgrep: 固定grep(fixed grep),有时也被称作快速(fast grep),它按字面解释所有的字符
找到: grep返回的退出状态为0
没找到: grep返回的退出状态为1
找不到指定文件: grep返回的退出状态为2
grep: 使用基本元字符集 ^, $, ., *, [], [^], \< \>,\(\),\{\}
egrep(或grep -E): 使用扩展元字符集 ?, +, { }, |, ( )
-i, --ignore-case 忽略大小写
-l, --files-with-matches 只列出匹配行所在的文件名
-n, --line-number 显示匹配行在文件中的行号
-c, --count 显示成功匹配的行的总行数
-s, --no-messages 禁止显示文件不存在或文件不可读的错误信息(不报错)
-q, --quiet, --silent 静默,什么也不显示,可以使用$?判断是否执行成功
-v, --invert-match 反向查找,只显示不匹配的行
-R, -r, --recursive 递归,在目录下递归查找文件中的内容
--color 颜色
-o, --only-matching 只显示匹配的内容,不显示整行
-B, --before-context=NUM 从找到的行开始再向上显示指定的行数
-A, --after-context=NUM 从找到的行开始再向下显示指定的行数
-C, --context=NUM 从找到的行开始再向上和向下显示指定的行数
-x, --line-regexp 显示完全匹配的行,相当于行首行尾定位符
-a, --text 过滤二进制文件
grep可以将一个不小心删掉的文件找回来,但是需要具备以下三个条件
1.删除的文件在磁盘上占用连续的块
2.知道删除文件的一部分内容
3.文件所占用的磁盘没有连续的读写
sed
sed 是一种在线的、非交互式的编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。Sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;编写转换程序等。
sed命令告诉sed对指定行进行何种操作,包括打印、删除、修改等。
命令 功能
p 打印行
d 删除行
a 在当前行的下一行添加一行或多行
i 在当前行的上一行插入文本
c 用新文本修改当前行中的文本(即覆盖掉当前行)
= 显示行号;在做行处理之前先打印行号
l 列出非打印字符
n 对找到匹配的行的下一行进行处理(最好是匹配唯一行)
q 结束或退出sed
! 对所选行以外的所有行应用命令
s 用一个字符串替换另一个
s 替换标志
g 在行内进行全局替换
i 忽略大小写
r 从文件中读
w 将行写入文件
y 将匹配字符替换为另一字符(不支持正则表达式)
h 把模式空间里的内容复制到暂存缓冲区(覆盖)
H 把模式空间里的内容追加到暂存缓冲区(追加)
g 取出暂存缓冲区的内容,将其复制到模式空间,覆盖该处原有内容
G 取出暂存缓冲区的内容,将其复制到模式空间,追加在原有内容后面
x 交换暂存缓冲区与模式空间的内容
awk
awk有3个不同版本: awk、nawk和gawk,未作特别说明,一般指gawk,gawk 是 AWK 的 GNU 版本。工作流程如下:

开始块(BEGIN block)
开始块的语法格式如下所示:
BEGIN {awk-commands}
顾名思义,开始块就是在程序启动的时候执行的代码部分,并且它在整个过程中只执行一次。 一般情况下,我们在开始块中初始化一些变量。BEGIN 是 AWK 的关键字,因此它必须是大写的。 不过,请注意,开始块部分是可选的,你的程序可以没有开始块部分。
主体块(Body Block)
主体部分的语法要求如下:
/pattern/ {awk-commands}
对于每一个输入的行都会执行一次主体部分的命令。默认情况下,对于输入的每一行,AWK 都会很执行命令。但是,我们可以将其限定在指定的模式中。 注意,在主体块部分没有关键字存在。
结束块(END Block)
下面是结束块的语法格式:
END {awk-commands}
结束块是在程序结束时执行的代码。 END 也是 AWK 的关键字,它也必须大写。 与开始块相似,结束块也是可选的。
awk命令
awk [options] file ...
[root@liuli file]# awk '{print}' marks.txt
1) Amit Physics 80
2) Rahul Maths 90
3) Shyam Biology 87
4) Kedar English 85
5) Hari History 89
AWK 标准选项
在命令行环境下,AWK 支持如下的标准选项
-f scripfile or --file scriptfile
从脚本文件中读取awk命令。
-F fs or --field-separator fs
指定输入文件折分隔符,fs是一个字符串或者是一个正则表达式,如-F:。
-v 选项
这个选项可以为变量赋值。它允许在程序执行之前为变量赋值
[root@liuli file]# awk -v name=liuli 'BEGIN{printf "name=%s\n",name}'
name=liuli
–dump-variables[=file] 选项
此选项会将全局变量及相应值按序输出到指定文件中。默认的输出文件名是 awkvars.out。
–help 选项
此选项将帮助消息转出到标准输出中。
–lint[=fatal] 选项
这个选项用于检查程序的可移植情况以及代码中的可疑部分。如果提供了参数 fatal,AWK 会将所有的警告信息当作错误信息处理
[root@liuli file]# awk --lint '' command.awk
awk: cmd. line:1: warning: empty program text on command line
awk: cmd. line:1: warning: source file does not end in newline
awk: warning: no program text at all!
–posix 选项
这个选项会打开严格 POSIX 兼容性审查。 如此,所有共同的以及 GAWK 特定的扩展将被设置为无效。
–profile[=file] 选项
这个选项会将程序文件以一种很优美的方式输出(译注:用于格式化 awk 脚本文件)。默认输出文件是 awkprof.out

–traditional 选项
此选项用于禁止 GAWK 相关的扩展。
–version 选项
此选项显示 AWK 程序的版本信息。
内置变量
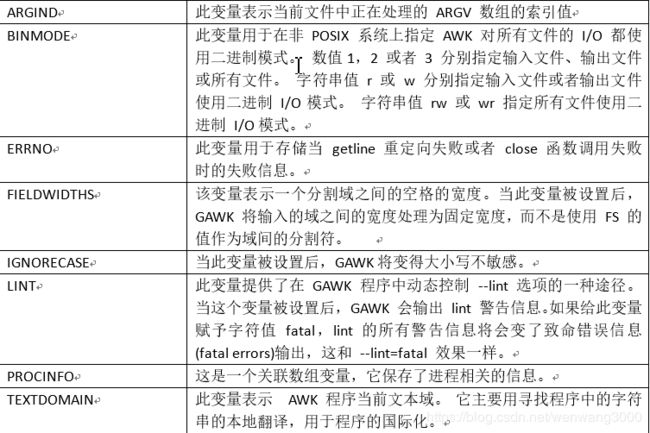
awk有许多内置变量用来设置环境信息,这些变量可以被改变,下面给出了最常用的一些变量。


操作符
算术运算符
AWK 支持如下的算术运算符:
+ - * / % ++ -- = += -= /= %= ^=(指数) == !=
< <= > >= && || ! ? : (三元) in 访问数组
[root@liuli file]# awk 'BEGIN { arr[0] = 1; arr[1] = 2; arr[2] = 3; for (i in arr) printf "arr[%d] = %d\n", i, arr[i] }'
arr[0] = 1
arr[1] = 2
arr[2] = 3
正则表达式
匹配运算符为 ~
不匹配操作符为 !~
点字符(.)可以匹配除了行结束字符的所有字符
行开始符(^)匹配一行的开始
行结束符($)匹配一行的结束
匹配字符集用于匹配集合(由方括号表示)中的一个字符
正则匹配时会排除集合中的字符[^]
该符号( ?)前面的字符不出现或者出现一次
该符号(*) 允许其前的字符出现多次或者不出现
该符号(+)使得其前的字符出现一次或者多次
括号用于分组而字符 | 用于提供多种选择。
数组
AWK 有关联数组这种数据结构,而这种数据结构最好的一个特点就是它的索引值不需要是连续的整数值。我们既可以使用数字也可以使用字符串作为数组的索引。除此之外,关联数组也不需要提前声明其大小,因为它在运行时可以自动的增大或减小
如下为数组使用的语法格式:
array_name[index]=value
其中 array_name 是数组的名称,index 是数组索引,value 为数组中元素所赋予的值。
创建数组
[root@liuli file]# awk 'BEGIN {
> fruits["mango"]="yellow";
> fruits["orange"]="orange"
> print fruits["orange"] "\n" fruits["mango"]
> }'
orange
yellow
删除数组 delete array_name[index]
[root@liuli file]# awk 'BEGIN {
> fruits["mango"]="yellow";
> fruits["orange"]="orange";
> delete fruits["orange"];
> print fruits["orange"]
> }'
多维数组
[root@liuli file]# awk 'BEGIN {
> array["0,0"] = 100;
> array["0,1"] = 200;
> array["0,2"] = 300;
> array["1,0"] = 400;
> array["1,1"] = 500;
> array["1,2"] = 600;
> # print array elements
> print "array[0,0] = " array["0,0"];
> print "array[0,1] = " array["0,1"];
> print "array[0,2] = " array["0,2"];
> print "array[1,0] = " array["1,0"];
> print "array[1,1] = " array["1,1"];
> print "array[1,2] = " array["1,2"];
> }'
array[0,0] = 100
array[0,1] = 200
array[0,2] = 300
array[1,0] = 400
array[1,1] = 500
array[1,2] = 600
控制流
IF 语句
条件语句测试条件然后根据条件选择执行相应的动作。下面是条件语句的语法:
if (condition)
action
也可以使用花括号来执行一组操作:
if (condition)
{
action-1
action-1
.
.
action-n
}
IF - ELSE 语句
if-else语句中允许在条件为假时执行另外一组的动作。下面为 if-else 的语法格式:
if (condition)
action-1
else
action-2
循环
For
for (initialisation; condition; increment/decrement)
action
While
while (condition)
action
内置函数
int(expr) 此函数返回数值 expr 的整数部分
rand() rand 函数返回一个大于等于 0 小于 1 的随机数 N(0<= N < 1)
srand([expr]) 此函数使用种子值生成随机数,数值 expr 作为随机数生成器的种子值。如果没有指定 expr 的值则函数默认使用当前系统时间作为种子值。
asort(arr,[, d [,how] ]) asort 函数使用 GAWK 值比较的一般规则排序 arr 中的内容,然后用以 1 开始的有序整数替换排序内容的索引。
asorti(arr,[, d [,how] ]) asorti 函数的行为与 asort 函数的行为很相似,二者的差别在于 aosrt 对数组的值排序,而 asorti 对数组的索引排序。
gsub(regx,sub, string) gsub 是全局替换( global substitution )的缩写。它将出现的子串(sub)替换为 regx。第三个参数 string 是可选的,默认值为 $0,表示在整个输入记录中搜索子串。
index(str,sub) index 函数用于检测字符串 sub 是否是 str 的子串。如果 sub 是 str 的子串,则返回子串 sub 在字符串 str 的开始位置;若不是其子串,则返回 0。str 的字符位置索引从 1 开始计数。
length(str) length 函数返回字符串的长度。
match(str, regex) match 返回正则表达式在字符串 str 中第一个最长匹配的位置。如果匹配失败则返回0。
split(str, arr,regex) split 函数使用正则表达式 regex 分割字符串 str。分割后的所有结果存储在数组 arr 中。如果没有指定 regex 则使用 FS 切分。
sprintf(format,expr-list) sprintf 函数按指定的格式( format )将参数列表 expr-list 构造成字符串然后返回。
strtonum(str) strtonum 将字符串 str 转换为数值。 如果字符串以 0 开始,则将其当作十进制数;如果字符串以 0x 或 0X 开始,则将其当作十六进制数;否则,将其当作浮点数。
sub(regex,sub,string) sub 函数执行一次子串替换。它将第一次出现的子串用 regex 替换。第三个参数是可选的,默认为 $0。
substr(str, start, l) substr 函数返回 str 字符串中从第 start 个字符开始长度为 l 的子串。如果没有指定 l 的值,返回 str 从第 start 个字符开始的后缀子串。
tolower(str) 此函数将字符串 str 中所有大写字母转换为小写字母然后返回。注意,字符串 str 本身并不被改变。
toupper(str) 此函数将字符串 str 中所有小写字母转换为大写字母然后返回。注意,字符串 str 本身不被改变。
systime 此函数返回从 Epoch 以来到当前时间的秒数(在 POSIX 系统上,Epoch 为1970-01-01 00:00:00 UTC)。
mktime(dataspec) 此函数将字符串 dataspec 转换为与 systime 返回值相似的时间戳。 dataspec 字符串的格式为 YYYY MM DD HH MM SS。
strftime([format [, timestamp[, utc-flag]]]) 此函数根据 format 指定的格式将时间戳 timestamp 格式化。
SN 描述
%a 星期缩写(Mon-Sun)。
%A 星期全称(Monday-Sunday)。
%b 月份缩写(Jan)。
%B 月份全称(January)。
%c 本地日期与时间。
%C 年份中的世纪部分,其值为年份整除100。
%d 十进制日期(01-31)
%D 等价于 %m/%d/%y.
%e 日期,如果只有一位数字则用空格补齐
%F 等价于 %Y-%m-%d,这也是 ISO 8601 标准日期格式。
%g ISO8610 标准周所在的年份模除 100(00-99)。比如,1993 年 1 月 1 日属于 1992 年的第 53 周。所以,虽然它是 1993 年第 1 天,但是其 ISO8601 标准周所在年份却是 1992。同样,尽管 1973 年 12 月 31 日属于 1973 年但是它却属于 1994 年的第一周。所以 1973 年 12 月 31 日的 ISO8610 标准周所在的年是 1974 而不是 1973。
%G ISO 标准周所在年份的全称。
%h 等价于 %b.
%H 用十进制表示的 24 小时格式的小时(00-23)
%I 用十进制表示的 12 小时格式的小时(00-12)
%j 一年中的第几天(001-366)
%m 月份(01-12)
%M 分钟数(00-59)
%n 换行符 (ASCII LF)
%p 十二进制表示法(AM/PM)
%r 十二进制表示法的时间(等价于 %I:%M:%S %p)。
%R 等价于 %H:%M。
%S 时间的秒数值(00-60)
%t 制表符 (tab)
%T 等价于 %H:%M:%S。
%u 以数字表示的星期(1-7),1 表示星期一。
%U 一年中的第几个星期(第一个星期天作为第一周的开始),00-53
%V 一年中的第几个星期(第一个星期一作为第一周的开始),01-53。
%w 以数字表示的星期(0-6),0表示星期日 。
%W 十进制表示的一年中的第几个星期(第一个星期一作为第一周的开始),00-53。
%x 本地日期表示
%X 本地时间表示
%y 年份模除 100。
%Y 十进制表示的完整年份。
%z 时区,表示格式为+HHMM(例如,格式要求生成的 RFC 822或者 RFC 1036 时间头)
%Z 时区名称或缩写,如果时区待定则无输出。
and 执行位与操作。
compl 按位求补。
lshift 左移位操作。
rshift 向右移位操作。
or 按位或操作
xor 按位异或操作
close(expr) 关闭管道的文件。
delete delete 被用于从数组中删除元素
exit 该函数终止脚本执行。它可以接受可选的参数 expr 传递 AWK 返回状态
flush flush 函数用于刷新打开文件或管道的缓冲区
getline getline 函数读入下一行
next 停止处理当前记录,并且进入到下一条记录的处理过程
nextfile nextfile 停止处理当前文件,从下一个文件第一个记录开始处理。
return return 用于从用户自定义的函数中返回值
system 可以执行特定的命令然后返回其退出状态。返回值为 0 表示命令执行成功;非 0 表示命令执行失败
自定义函数
函数是程序的基本构造部分。AWK 允许我们自定义函数。事实上,大部分的程序功能都可以被切分成多个函数,这样每个函数可以独立的编写与测试。函数不仅提高了代码的复用度也提高代码的鲁棒性。
下面是用户自定义函数的一般形式:
function function_name(argument1, argument2, ...)
{
function body
}
输出重定向
到目前为止我们输出的数据都是输出到标准输出流中。不过我们也可以将数据输出重定向到文件中。重定向操作往往出现在 print 或者 printf 语句中。 AWK 中的重定向方法与 shell 重定向十分相似,除了 AWK 重定向只用于 AWK 程序中外。
重定向操作符的使用方法如下:
print DATA > output-file
追加重定向操作符的语法如下:
print DATA >> output-file
管道
除了使用文件在程序之间传递数据之外,AWK 还提供使用管道将一个程序的输出传递给另一个程序。这种重定向方式会打开一个管道,将对象的值通过管道传递给管道另一端的进程,然后管道另一端的进程执行命令。
下面是管道的使用方法:
print items | command
双向通信通道
AWK 允许使用 |& 与一个外部进程通信,并且可以双向通信
实例

awk工作流程是这样的:读入有’\n’换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,$0则表示所有域, 1 表 示 第 一 个 域 , 1表示第一个域, 1表示第一个域,n表示第n个域 $NF 表示最后一列。默认域分隔符是"空白键" 或 “[tab]键”

这种是awk+action的示例,每行都会执行action{print $1}。
-F指定域分隔符为’:’。

而账户与shell之间以tab键分割

awk工作流程是这样的:先执行BEGING,然后读取文件,读入有/n换行符分割的一条记录······直到所有的记录都读完,最后执行END操作。
1. 查看TCP连接状态
# netstat -nat |awk '{print $6}' | sort | uniq -c | sort -rn
2. 查找请求数前20个IP(常用于查找攻来源)
# netstat -anlp |grep 80 | grep tcp | awk '{print $5}'| awk -F':' '{print $1}' |sort | uniq -c | sort -nr | head -20
3. 根据端口列出进程
# netstat -ntlp | grep 80 | awk '{print $7}' | cut -d/ -f1