yolov4论文解读和训练自己数据集
前天YOLOv4终于问世——
YOLO v4 论文:https://arxiv.org/abs/2004.10934
YOLO v4 开源代码:https://github.com/AlexeyAB/darknet
效果相比YOLOv3和去年的EfficientDet系列提升明显。这里使用tensorflow model的测试图片对官方给出的COCO数据集训练的模型测试对比:

 分别是YOLOv3和YOLOv4的测试结果,可以看到提升还是很明显的,特别是小目标的识别效果,不枉论文吹B的:
分别是YOLOv3和YOLOv4的测试结果,可以看到提升还是很明显的,特别是小目标的识别效果,不枉论文吹B的:
Improves YOLOv3’s AP and FPS by 10% and 12%, respectively
论文细节还在研究中,后面有空更新。我也第一时间使用YOLOv4训练了自己数据集。
具体的步骤和YOLOv3一模一样,需要下载backbone的权重:https://github.com/AlexeyAB/darknet#how-to-compile-on-linux-using-make中for yolov4.cfg, yolov4-custom.cfg (162 MB)。
因为我没有梯子,能下载的兄弟请传个百度网盘分享交流。这里在网上只能找到别人分享的yolov4.weights文件,于是提取了yolov4.weights模型的backbone参数作为backbone部分的预训练模型。
训练自己数据集只需要修改yolov4-custom.cfg中三处的:
[convolutional]
size=1
stride=1
pad=1
filters=${3×(自己数据集类别+5)} #例如COCO是3×(80+5)=255
activation=linear
[yolo]
mask = 3,4,5
anchors = 12, 16, 19, 36, 40, 28, 36, 75, 76, 55, 72, 146, 142, 110, 192, 243, 459, 401
classes=${自己数据集类别} #例如COCO是80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
scale_x_y = 1.1
iou_thresh=0.213
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
nms_kind=greedynms
beta_nms=0.6
详细准备工作参考https://pjreddie.com/darknet/yolo/中Training YOLO on VOC章节。
准备好后既可以开始训练: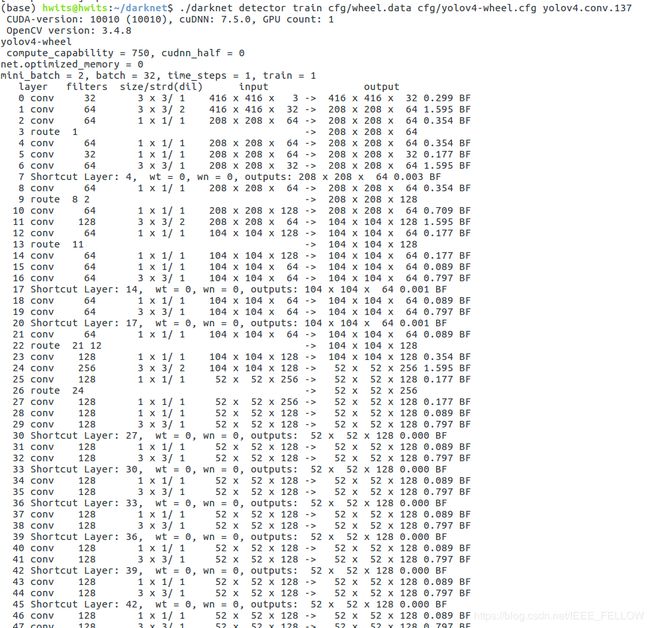
训练过程:
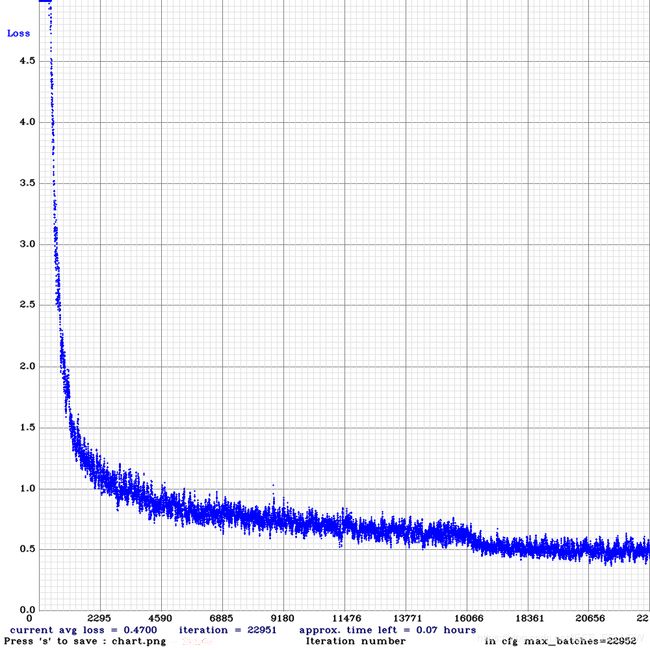
这里使用车轮识别数据集对比YOLOv3和YOLOv4:
| Model | AP for Body | AP for Wheel | mAP | time |
|---|---|---|---|---|
| YOLOv3 | 0.999322235707 | 0.88200726583 | 0.940664750768 | 12.47s/532images |
| YOLOv4 | 0.998358289307 | 0.948024870726 | 0.973191580016 | 12.00s/532images |
| YOLOv3 with Mosaic | 0.99807091697 | 0.888338772271 | 0.943204844621 | 13.00s /532 imags |
可以看到,在完全相同的训练数据和测试数据集上,YOLOv4提升效果非常明显!更短的时间,到达好的识别效果,特别是小目标识别效果。对YOLOv3使用YOLOv4中的马赛克增强处理,对识别也有0.3%的提升,特别是小目标的识别上。
对恶劣条件下的车轮测试对比:

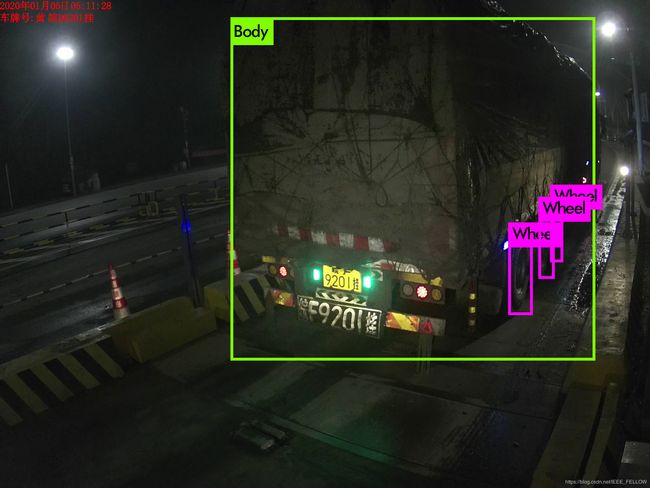
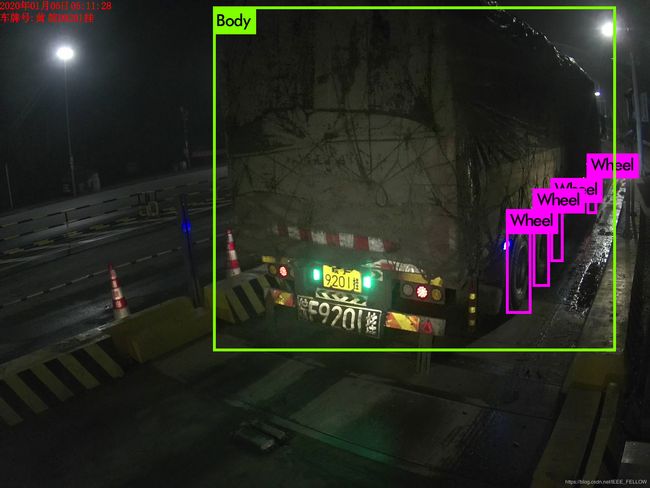
可以看到,YOLOv4相比YOLOv3提升非常明显,特别是小目标的识别效果。
YOLOv4网络结构
TensorRT模型对比
这里对比YOLOv3和YOLOv4在darknet和tensorrt模型下的实验:
| model | framework | time | GPU Mem |
|---|---|---|---|
| YOLOv3 | darknet | 27.575 | 1809MiB |
| YOLOv3 - pruned 99% | darknet | 6.446 | 685MiB |
| YOLOv4 | darknet | 27.572000 ms | 1333MiB |
| YOLOv4 | tensorrt-fp32 | 25 ms | 1145MiB |
| YOLOv4 | tensorrt-fp16 | 10 ms | 721MiB |
可以看到YOLOv4和YOLOv3的推理速度相差不大,实际显存消耗降低明显,tensorrt可以有效降低显存消耗和推理时间。