Redis教程
NoSQL
Nosql(NoSQL=Not Only SQL),意即不仅仅是SQL,是一项全新的数据库,泛指非关系数据库
作用:
传统关系数据库在因对,超大规模和高并发SNS类型的web2.0存动态网络暴露很多难以克服的问题。
1.对数据库高并发读写的需求(高并发,双11之内的)
2.对海量数据高效存储和访问的需求(类似Facebook,twitter这样的SNS网站,每天用户产生海量的动态,就FB为例,一个月就到达2.5亿条用户动态,对于关系数据库,在一张2.5亿条记录的表里面进行sql查询,效率极其低下不可忍受)
3.对数据库高扩展性和高可用的需求(基于web的架构中,数据库是最难进行横向扩展的,当一个应用系统的用户量和访问量与日俱增的时候,你的数据库却没用办法项web server和app server 简单的通过添加更多的硬件和服务节点来扩展性能和负载能力,对于数据库的升级和扩展是非常痛苦的,往往需要停机维护和数据迁移,为什么数据库不能通过不断的添加服务器节点来实现扩展?)
NoSQL数据库就是为了解决以上难题。
主流NoSQL产品
Redis(键值对类型数据库)
MongoDB(文档类型数据库)
HBASE(列存类型据库,hadoop生态圈的数据库)
NOSQL优点
易扩展)NoSQL数据库种类繁多,有个共同点,去掉关系数据库的关系特性(数据没关联,表和表之间没联系),内存数据库,内存读写快,而且也能持久化,但是大部分都是在内存中,除非是停机断电情况下持久化,而。
高性能)NoSQL数据库高性能读写特性,尤其大数据量的时候,得利于无关系性,数据库结构简单。
灵活数据模型)NoSQL随时存储自定义数据格式,而在关系数据库,增删字段是一件非常麻烦的事情,如果是非常大数据量表,增加字段简直是一个噩梦。
高可用)NoSQL在不太影响性能的情况,就可以方便实现报可用的架构,如HBase模型,通过复制模型也能实现高可用。
什么是Redis
c语言开发开源高性能键值对(key-value)数据库,提供多种数据类型来适应不同场景下的存储需求,目前为止Redis支持类型有:
1.字符串类型
2.散列类型(相当于set)
3.列表类型(list)
4.集合类型(set)
5.有序集合类型(相当于java的TreeSet,有序集合)
以上主要指value类型
官方提供测试数据,50个并发执行100000个请求,读的速度110000次/s,写的速度是81000次/s。
Redis应用场景
缓存(数据查询,短链接,新闻内容,商品内容等),用的最多的
聊天室的在线好友列表
任务队列。(秒杀,抢购,12306等)
应用排行榜
网站访问统计
数据过期处理(可以精确到毫秒)
分布式集群架构中的session分离
Redis安装与启动
redis建议安装在linux服务器上运行测试,window版本的也可以,但是性能就不好说了。
Redis在linux上安装
1)安装redis编译的c环境,yuminstall gcc-c++
2)将redis-2.6.16.tar.gz上传到Linux系统中
3)解压到/usr/local下 tar -xvf redis-2.6.16.tar.gz -C /usr/local
4)进入redis-2.6.16目录 使用make命令编译redis
5)在redis-2.6.16目录中 使用make PREFIX=/usr/local/redis install命令安装 redis到/usr/local/redis中(这时候生成的redis/bin/redis-server可以直接访问,属于前端访问)
6)拷贝redis-2.6.16中的redis.conf到安装目录redis中,并且修改配置文件的daemonize no变为yes
7)启动redis 在bin下执行命令redis-server redis.conf(必需加上redis.conf否则还是前台启动)
关闭redis服务器两种方式
1.ps -ef|grep redis查看进程的pid然后使用kill -9 pid给关掉
2../redis-cli shutdown
8)如需远程连接redis,需配置redis端口6379在linux防火墙中开放
/sbin/iptables -I INPUT -p tcp --dport 6379 -j ACCEPT
/etc/rc.d/init.d/iptables save

Jedis对redis操作
public void test(){//如果连接不成功,说明linux上防火墙拦截了,需要开发6379端口
Jedis jedis=new Jedis("192.168.209.134",6379);
String name = jedis.get("userName");
System.out.println(name);
}Jedis的连接池使用
@Test
public void test2(){
JedisPoolConfig poolConfig=new JedisPoolConfig();
poolConfig.setMaxIdle(30);//最大闲置个数
poolConfig.setMinIdle(10);//最小现闲置个数
poolConfig.setMaxTotal(50);//最大连接数
//创建一个redis的连接池
JedisPool jedisPool=new JedisPool(poolConfig,"192.168.209.134",6379);
//从池中获取redis的连接资源
Jedis jedis = jedisPool.getResource();
jedis.set("userName","小明");
String name = jedis.get("userName");
System.out.println(name); //关闭资源 jedis.close(); jedisPool.close(); }封装成工具类
redis.propertors
redis.maxIdle=30
redis.minIdle=10
redis.maxTotal=100
redis.url=192.168.186.131
redis.port=6379JedisPoolUtils.javas
public class JedisPoolUtils {
private static JedisPool pool = null;
static{
//加载配置文件
InputStream in = JedisPoolUtils.class.getClassLoader().getResourceAsStream("redis.properties");
Properties pro = new Properties();
try {
pro.load(in);
} catch (IOException e) {
e.printStackTrace();
}
//获得池子对象
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxIdle(Integer.parseInt(pro.get("redis.maxIdle").toString()));//最大闲置个数
poolConfig.setMinIdle(Integer.parseInt(pro.get("redis.minIdle").toString()));//最小闲置个数
poolConfig.setMaxTotal(Integer.parseInt(pro.get("redis.maxTotal").toString()));//最大连接数
pool = new JedisPool(poolConfig,pro.getProperty("redis.url") , Integer.parseInt(pro.get("redis.port").toString()));
}
//获得jedis资源的方法
public static Jedis getJedis(){
return pool.getResource();
}
} Redis常用命令
redis是一种高级的key-value的存储系统其中的key是字符串类型,尽可能满足如下几点:1)key不要太长,最好不要操作1024个字节,这不仅会消耗内存还会降低查找 效率2)key不要太短,如果太短会降低key的可读性3)在项目中,key最好有一个统一的命名规范(根据企业的需求)其中value 支持五种数据类型:1)字符串型 string2)字符串列表 lists3)字符串集合 sets4)有序字符串集合 sorted sets5)哈希类型 hashs 字符串类型string
get key 获取值set key value 设置值getset key value 先获取值后修改值del key 删除值nil 表示不存的元素incr key 递增,如果key的value是数值就加一,不是数值就报错(ERR value is not an integer or out of range),如果key不存在,则创建key,并且value初始为0+1decr key 递减,同上面一样incrby key increment (相当于java的i+=5),如果key不存在,器初始化值为0,然后+=increment,如果该值不是数值,则报错。decrby key decrement 累减,同上特性一样append key 字符串链接,返回的是字符串长度(如果不存在,则创建字符串) 存储类型hash
每个Hash可以存储4294967295个键值对hgetkey fieldKey 获取一个Hash类型中的一个fieldKey的valuehget key fieldKey key fieldKey 可以获取多个值 hset key fieldKey value 设置一个Hash类型,并且存入fieldKey和value,返回插入结果行数hset key fieldKey value fieldKey value 可以设置多个值hdel key fieldKey 删除多个keyhdel key fieldKey fieldKey 可以删除多个值hdel key 同下del key 删除整个大的keyhmset key fieldKey value fieldKey value.....设置一个Hash类型,并且可以存入多个fieldKey 和value,返回插入结果行数(如果存在fieldKey,返回0)hmget 类型名 fieldKey ,key......... 获取一个Hash类型,并且可以获取多个fieldKey 的value,返回LIst类型。del 类型名 删除整个hashhincrby key fieldKey value 和基本类型一样,+=一个意思,如果想-=写负数hexists key fieldKey 判断某个key中的fieldKey是否存在,存在返回1,否则0(Jedis中是返回boolean类型)hlen key 获取key的长度hgetall key 获取全部的keyhkeys key 获取key下的所有fieldKey的名称hvals key 获取key下的所有fieldKey的值 存储类型List
此List类型是链表类型,一般可以使用到消息队列和连接池中 lpush key value value .... 左边的方式压入值rpush key value value .... 右边的方式插入值lrange key X到Y之间 (全部1 -1,-1代表最后一个元素)lpop key 弹出并且返回第一个元素,并且list中没有这个元素rpop key 弹出并且返回尾部元素,并且list中没有这个元素 lrem key count value 从左开始删除匹配到的value,删除个数为count(count参数为负数时是从左开始删除)lset key index value 设置链表中index的脚标的元素值,如果当前的元素存在则替换,0代表链表的头元素,-1代表链表的尾元素,如果无效的下标,则异常()llen key 返回指定key关联的链表中的元素数量linsert key 之前(之后) 元素1,元素2 将元素2插入第一个元素1之前(之后)lpushx key value 仅当key存在时,向头部插入value,不存在将不进行插入rpushx key value同上,只不过是尾部插入linsert key after |before pivot value 在pivot元素后或者前插入value这个元素rpoplpush 将链表中的尾部元素弹出并添加到头部(循环操作) 存储类型Set类型
set的元素不可重复,和List相比,set类型在功能上还存在一个非常重要的特性,即在服务器端完成多个Sets之间的聚合计算,如unions(并集),intersections(交际)和differences(差级)。由于这些操作均在服务端完成,因此效率极高,而且也节省了大量的网络io开销sadd key value,value.... 添加集合元素srem key value 删除set指定的value元素smember key 返回集合的所有元素(整个set)sdiff key key2... 返回多个集合的差级(返回不相同的)sinter key key2... 返回多个集合的交级(返回相同的)sunion key key2... 返回多个集合的并级(融合,重复的集合会被覆盖)sdiffstore destination key1 key2... 将key1和key2差集的成员存储在destination上sinterstore destination key1 key2... 将key1和key2交集的成员存储在destination上 sunionstore destination key1 key2... 将key1和key2并集的成员存储在destination上 scard key 获取set集合的数量srandmember key 返回一个随机的元素 存储类型sortedSet类型
SortedSet和Set类型极为相似,它们都是字符串的集合,并且不可重复,差别在于SortedSet中每个成员都会有一个分数(score)与之关联,正是通过分数来为集合中的成员进行从小到大的排序。尽管SortedSet成员是唯一的,但是分数(score)却可以重复。zadd key score value score value.... 添加多个带有排序功能的valuezscore key value 查看元素对应的score(分数)zcard key 返回key的个数zrem key value 删除key中的valuezrang key start stop[withscores] 返回范围start 到stop之间的value,带参数显示分数zrevrange key start stop[withscores] 返回范围start到stop之间所有元素,从大到小zrangebyscore 类型名 范围0 100 0到100之间的元素withscores参数 (带分数) limit参数(只显示多少个)zremrangebyrank key start stop 按照排名范围删除元素(默认从小到大删除)zremrangebyscore key min max 按照分数范围删除元素zrangebyscore key min max[withscores][limit offset count] 可以分页查询zincrby key 分数 value 设置value的分数zcount key min max 获取分数在min到max之间的成员zrank key member 返回成员在集合中的排名(从小到大) Keys通用的操作
keys * 查询匹配的key(my? 查询所有开头开my的元素) del key key.... 删除指定的多个指定的key
exists key 判断该key是否存在,1代表存在,0代表不存在
rename key newkey 重命名
expire key 设置过期时间(单位:秒)
ttl key 获取该key所剩的超时时间,如果没有设置超时时间返回-1,如果返回-2表示超时不存在type key 查询key的类型
Redis特性
多数据库,默认为0号数据库,使用客户端软件Redis Desktop Manager
命令
select 1 连接1号数据库(默认是在0库)
move newkey 1 将当前库的key剪切到1号库中
flushdb 删除当前选择数据库中的所有key
flushall 删除所有数据库中所有key
Redis的消息订阅与发布
subscribe channel 订阅频道,例:subscribe mychat,订阅mychat频道
psubscribe channel* 批量订阅频道,例:psubscribe s* ,订阅以s开头的频道
publish channel content 在指定的频道中发布消息,如 publish mychat 'today is a newday'
例:
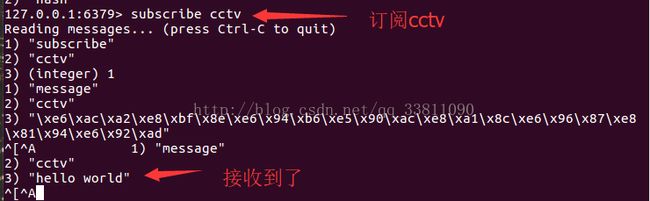
@Test
public void test4(){
Jedis jedis=new Jedis("192.168.209.134",6379);
jedis.publish("cctv","hello world");//发布后,上面图片接受到了
}缺点:
所有pub/sub很有用,但是redis的实现有这么几个问题:
1.如果一个客户订阅了频道,但自己读取消息速度却不够快,那么不断积压的消息会使redis输出缓冲区的体积变得越来越大,可能使得redis的速度变慢,甚至直接崩溃。
2.这和数据传输可靠性有关,如果在订阅方断线,那么他将会丢失所有在断线期间发布者发布的消息。
Redis事务
multi 开启事务用于标记事务开始,其后执行的命令都将被存入命令队列,直到执行exec时,这些命令才会被原子的执行,
exec 提交事务
discard 事务回滚
Redis的持久化(重要)
1.RDB方式(默认支持,无需配置)
该机制是指在指定的时间间隔内将内存中的数据集快照以二进制的方式写入磁盘。
默认是在bin目录里面生成dump.rdb文件
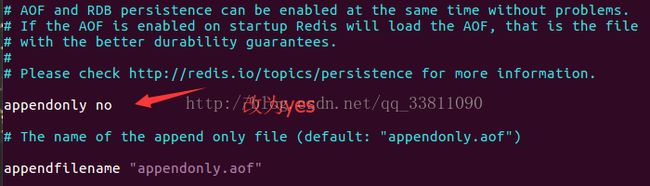
2.AOF方式
该机制将以日志的形式记录服务器所处理的每一个写操作,在Redis服务器启动之初会读取该文件来重新构建数据库,以保证启动后数据库中的数据是完整的。
(以文本的方式,将所有对数据库进行过写入的命令,记录到AOF文件中,以此达到记录数据库状态的目的)
牺牲一些性能,换取更高的缓存一致性(aof)
RDB
优势
1.一旦采用该方式,那么你的整个reids数据库将只包含一个文件,这对于文件备份而言是非常完美的。比如,你可能打算每个小时归档一次最近24小时的数据,同时还要每天归档一次最近30天的数据。通过这样的备份策略,一旦系统出现灾难性故障,我们可以非常容易进行恢复。
2.对于灾难恢复而言,RDB是非常不错的选择,因为我们可以非常轻松的将一个单独的文件压缩后再转移到其它存储介质上。
3.性能最大化。对Redis的服务进程而言,在开始持久化时,它唯一需要做的只是fork(分叉)出子进程,之后再由子进程完成这些持久化工作,这样就可以极大的避免服务进程执行io操作。
4.相比于AOF机制,如果数据集很大,RDB的启动效率会更高。
劣势
1.如果你想保证塑聚的高可用性,即最大限度避免数据丢失,那么RDB将不是一个很好的选择。因为系统一旦在定时持久化之前出现问题,此前没有来得及写入磁盘的数据都将丢失。
2.由于RDB是通过fork子进程来协助完成数据持久化工作,因此,如果当数据集较大时,可能会导致整个服务器停止服务器停止几百毫秒,甚至1秒钟。
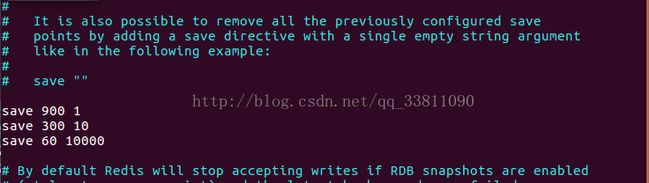
配置说明Snapshotting
快照参数设置
save 900 1 每900秒(15分钟)至少有1个key发生变化,则dump内存快照。
save 300 10 每300秒(5分钟)至少有10个key发生变化,则dump内存快照。
save 60 10000 每60秒(1分钟)至少有10000个key发生变化,则dump内存快照。
使用vi打开redis.config 在命令模式下输入/save 找到以下位置(如果改目录地址可以找dir属性(默认是bin目录),改名字找dbfileame)
AOF

Redis主从复制
Redis主从配置
从机配置
模拟主从复制
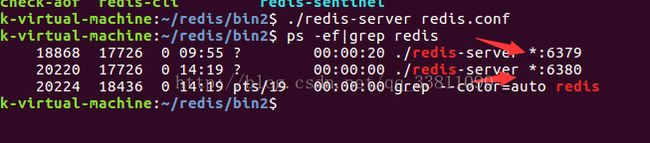
 在主机中设置一个key111
在主机中设置一个key111
