聚类之K-Means算法
文章目录
- 前言
- 1. 相似性的度量
- 1.1 闵可夫斯基距离
- 1.2 曼哈顿距离
- 1.3 欧氏距离
- 2. K-Means算法原理
- 2.1 基本原理
- 2.2 计算过程
- 2.3 代码实现
- 结束语
前言
K-Means算法,也被称为K-平均或K-均值算法,是一种广泛使用的聚类算法。K-Means算法是基于相似性的无监督算法,通过比较样本之间的相似性,将较为相似的样本划分到同一个类别中。
1. 相似性的度量
在K-Means算法中,通过某种相似性度量的方法,将较为相似的个体划分到同一个类别中。对于不同的应用场景,有着不同的相似性度量方法,一般定义一个距离函数 d ( X , Y ) d(X,Y) d(X,Y)来表示样本 X X X和样本 Y Y Y之间的相似性。在机器学习中使用到的距离函数主要有以下三种:
- 闵可夫斯基距离
- 曼哈顿距离
- 欧氏距离
1.1 闵可夫斯基距离
假设有两个点,分别为点 P P P和点 Q Q Q(即两个样本),其对应的坐标分别为:
P = ( x 1 , x 2 , … , x n ) ∈ R n P=(x_1,x_2,\dots,x_n)\in\mathbb R^n P=(x1,x2,…,xn)∈Rn Q = ( y 1 , y 2 , … , y n ) ∈ R n Q=(y_1,y_2,\dots,y_n)\in\mathbb R^n Q=(y1,y2,…,yn)∈Rn 那么,点 P P P和点 Q Q Q之间的闵可夫斯基距离可以定义为:
d ( P , Q ) = ( ∑ i = 1 n ( x i − y i ) p ) 1 / p d(P,Q)=\biggl(\sum_{i=1}^n (x_i-y_i)^p\biggl)^{1/p} d(P,Q)=(i=1∑n(xi−yi)p)1/p
1.2 曼哈顿距离
上述两点的曼哈顿距离可以定义为:
d ( P , Q ) = ∑ i = 1 n ∣ x i − y i ∣ d(P,Q)=\sum_{i=1}^n |x_i-y_i| d(P,Q)=i=1∑n∣xi−yi∣
1.3 欧氏距离
上述两点的欧氏距离可以定义为:
d ( P , Q ) = ∑ i = 1 n ( x i − y i ) 2 d(P,Q)=\sqrt{\sum_{i=1}^n (x_i-y_i)^2} d(P,Q)=i=1∑n(xi−yi)2
注:从上面也可以看出,曼哈顿距离和欧氏距离是闵可夫斯基距离的具体表现形式(p=1和p=2)。下面用到的是欧氏距离的平方。
2. K-Means算法原理
2.1 基本原理
K-Means算法可大致分为三个步骤:
- 首先,定义常数 k k k(即最终的聚类的类别数),随机初始化 k k k个类的聚类中心;
- 然后,重复计算以下过程,直到聚类中心不再改变;
- 计算每个样本与每个聚类中心之间的相似度,将样本划分到最相似的类别中;
- 计算划分到每个类别中的所有样本特征的平均值,并将该均值作为每个类新的聚类中心。
- 最后,输出最终的聚类中心以及每个样本所属的类别。
注:
初始化聚类中心的方法:找到每一维数据上的最小值和最大值,生成此区间范围内的随机值,即 c = m i n + r a n d ( 0 , 1 ) × ( m a x − m i n ) c=min+rand(0,1)\times(max-min) c=min+rand(0,1)×(max−min)
2.2 计算过程
假设训练集数据 X X X中有 m m m个样本 { X ( 1 ) , X ( 2 ) , … , X ( m ) } \{X^{(1)},X^{(2)},\dots,X^{(m)}\} {X(1),X(2),…,X(m)},其中,每一个样本 X ( i ) X^{(i)} X(i)为 n n n维的向量,就像上面的点 P P P和点 Q Q Q。此时样本可以表示为一个 m × n m\times n m×n的矩阵:
X m × n = ( X ( 1 ) , X ( 2 ) , … , X ( m ) ) T = ( x 1 ( 1 ) x 2 ( 1 ) … x n ( 1 ) x 1 ( 2 ) x 2 ( 2 ) … x n ( 2 ) ⋮ ⋮ ⋮ x 1 ( m ) x 2 ( m ) … x n ( m ) ) m × n X_{m\times n}=\Big(X^{(1)},X^{(2)},\dots,X^{(m)}\Big)^T= \begin{pmatrix} x_1^{(1)} & x_2^{(1)} & \dots & x_n^{(1)} \\ \\ x_1^{(2)} & x_2^{(2)} & \dots & x_n^{(2)} \\ \\ \vdots & \vdots & & \vdots \\ \\ x_1^{(m)} & x_2^{(m)} & \dots & x_n^{(m)} \end{pmatrix}_{m\times n} Xm×n=(X(1),X(2),…,X(m))T=⎝⎜⎜⎜⎜⎜⎜⎜⎜⎜⎜⎛x1(1)x1(2)⋮x1(m)x2(1)x2(2)⋮x2(m)………xn(1)xn(2)⋮xn(m)⎠⎟⎟⎟⎟⎟⎟⎟⎟⎟⎟⎞m×n 假设有 k k k个类,分别为: { C 1 , C 2 , … , C k } \{C_1, C_2, \dots,C_k\} {C1,C2,…,Ck},根据上述原理,可以计算得到新的聚类中心 C k ′ C_k^{'} Ck′:
C k ′ = ∑ X ( i ) ∈ C k X ( i ) N X ( i ) ∈ C k C_k^{'}=\frac {\sum_{X^{(i)}\in C_k} X^{(i)}} {N_{X^{(i)}\in C_k}} Ck′=NX(i)∈Ck∑X(i)∈CkX(i) 其中,分子表示属于 C k C_k Ck类别中的所有样本的特征向量的和,分母表示属于 C k C_k Ck类别的样本个数。
算法的停止条件是聚类中心不再发生改变,此时,所有样本被划分到了最近的聚类中心所属的类别中,即:
m i n ∑ i = 1 m ∑ j = 1 k z i j ∥ X ( i ) − C j ∥ 2 min\sum_{i=1}^m \sum_{j=1}^k z_{ij} \Big\|X^{(i)}-C_j\Big\|^2 mini=1∑mj=1∑kzij∥∥∥X(i)−Cj∥∥∥2 其中,样本 X ( i ) X^{(i)} X(i)是数据集 X m × n X_{m\times n} Xm×n的第 i i i行,也就是第 i i i个样本; C j C_j Cj是第 j j j个类别的聚类中心。假设 M k × n M_{k\times n} Mk×n为 k k k个聚类中心构成的矩阵,矩阵 Z m × k Z_{m\times k} Zm×k是由 z i j z_{ij} zij构成的0-1矩阵, z i j z_{ij} zij为:
z i j = { 1 , i f X ( i ) ∈ C j 0 , o t h e r w i s e z_{ij}=\begin{cases} 1, & ifX^{(i)}\in C_j\\ 0, & otherwise \end{cases} zij={1,0,ifX(i)∈Cjotherwise 对于上述的理解:矩阵 Z m × k Z_{m\times k} Zm×k表示 m m m个样本(行),每个样本的所属类别 k k k(列),如果属于这个类别,则其对应的系数为1,其他为0,其实就是one-hot。
根据上式可知, C j = Z M C_j=ZM Cj=ZM,所以上述的目标函数可以写成如下的等价形式(求和的过程可以用矩阵来代替):
m i n ∥ X − Z M ∥ 2 min\|X-ZM\|^2 min∥X−ZM∥2
注:如果n维向量不好理解,可以把它当成二维的
2.3 代码实现
代码实现如下:
import numpy as np
import matplotlib.pyplot as plt
def o2_distance(vecA, vecB):
"""
计算向量vecA和向量vecB之间的欧氏距离的平方
:param vecA: 向量vecA的坐标
:param vecB: 向量vecB的坐标
:return:
"""
# .T 对一个矩阵转置
distance = np.dot((vecA - vecB), (vecA - vecB).T)
return distance
def load_data(file_path):
"""
将txt里面的数据转换成矩阵
:param file_path:
:return:
"""
data_list = []
with open(file_path, 'r') as f:
lines = f.readlines()
for line in lines:
data_row = []
line = line.strip().split('\t')
for x in line:
data_row.append(float(x))
data_list.append(data_row)
data_arr = np.array(data_list)
return data_arr
def random_center(data_arr, k):
"""
随机初始化聚类中心
:param data:
:param k:
:return:
"""
# 每个样本的维度, 即n
dim_n = np.shape(data_arr)[1]
# 初始化k个聚类中心
centroids = np.array(np.zeros(shape=(k, dim_n)))
# 初始化聚类中心的坐标
for x in range(dim_n):
# 0 坐标x 1 坐标y
min_x = np.min(data_arr[:, x])
max_x = np.max(data_arr[:, x])
temp = min_x * np.array(np.ones(shape=(k, 1))) + np.random.rand(k, 1) * (max_x - min_x)
centroids[:, x] = temp.flatten()
return centroids
def kmeans(data_mat, k, centroids):
"""
聚类计算
:param data_mat:
:param k:
:param centroids:
:return: sub_centroids [类别, 最小距离]
"""
# (样本个数, 特征维度)
dim_m, dim_n = np.shape(data_mat)
# 初始化每一个样本所属的类别
sub_center = np.array(np.zeros(shape=(dim_m, 2)))
# 更新标志
flag = True
while flag:
flag = False
for i in range(dim_m):
# 设置样本与聚类中心之间的初始最小距离, 初始值为无穷
min_distance = np.inf
# 设置所属的初始类别
min_index = 0
for j in range(k):
# 计算样本i和每个聚类中心之间的距离
distance = o2_distance(data_mat[i], centroids[j])
if distance < min_distance:
min_distance = distance
min_index = j
if sub_center[i, 0] != min_index:
flag = True
sub_center[i] = np.array([min_index, min_distance])
# 重新计算聚类中心
for j in range(k):
sum_all = np.array(np.zeros(shape=(1, dim_n)))
# 每个类别中的样本个数
counter = 0
for i in range(dim_m):
# 计算第j个类别
if sub_center[i, 0] == j:
sum_all += data_mat[i]
counter += 1
for t in range(dim_n):
try:
centroids[j, t] = sum_all[0, t] / counter
except Exception as err:
print('样本数为0')
return sub_center
def draw_picture(data_mat, sub_center, centroids):
x = sub_center[:, 0]
dots1 = data_mat[x == 0.0]
dots2 = data_mat[x == 1.0]
dots3 = data_mat[x == 2.0]
dots4 = data_mat[x == 3.0]
plt.figure()
plt.scatter(dots1[:, 0], dots1[:, 1], marker='o',
color='blue', alpha=0.7, label='dots1 samples')
plt.scatter(dots2[:, 0], dots2[:, 1], marker='o',
color='green', alpha=0.7, label='dots2 samples')
plt.scatter(dots3[:, 0], dots3[:, 1], marker='o',
color='red', alpha=0.7, label='dots3 samples')
plt.scatter(dots4[:, 0], dots4[:, 1], marker='o',
color='purple', alpha=0.7, label='dots4 samples')
plt.scatter(centroids[:, 0], centroids[:, 1], marker='x',
color='black', alpha=0.7, label='centroids')
plt.savefig('./result.png')
plt.show()
if __name__ == '__main__':
k = 4
file_path = './data.txt'
data_arr = load_data(file_path)
centroids = random_center(data_arr, k)
sub_center = kmeans(data_arr, k, centroids)
draw_picture(data_arr, sub_center, centroids)
运行结果如下:
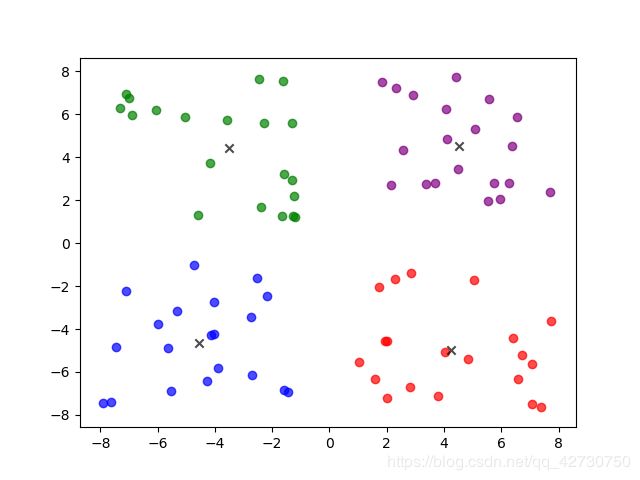
上图中黑色的叉表示四个聚类中心,每一个圆点表示一个样本,可以看出结果还是蛮好的。
结束语
入CSDN将近三年了,其实很早就有写博客的想法,磨磨唧唧,今天终于写了第一篇博客,花了好大会儿时间,哈哈哈哈!身为一名理(kao)工(yan)男(gou),学业繁重,平时学的这些比较零碎,都写在了笔记本上,以后也会不定期把这些分享在博客上,希望能在学习的过程中坚持写博客,哈哈哈哈哈,加油ヾ(◍°∇°◍)ノ゙
注:本篇文章主要参考赵志勇老师的《Python机器学习算法》和李航老师的《统计学习方法》,另外加入了一点个人见解。能力有限,如有错误或更好的见解,记得交流哦,嘿嘿嘿。