ConcurrentHashMap 1.8 源码分析
ConcurrentHashMap 1.8 源码分析
- 基本结构
- 基本概念
- sizeCtl
- 实例构造方法
- initTable方法
- put()操作
- 链表转红黑树
- treeifyBin:链表转红黑树
- TreeBin(TreeNode b) : 构建红黑树
- balanceInsertion :
- tryPresize : 数组长度为64以下时触发的扩容
- 将数据放到红黑树
- putTreeVal : 放入红黑树
- findTreeNode :查找treeNode
- 扩容
- 什么时候触发扩容?
- addCount : 扩容检查
- helpTransfer :
- 扩容过程:
- transfer : 扩容
- get()操作
基本结构
ConcurrentHashMap在1.8中的实现,相比于1.7的版本基本上全部都变掉了。首先,取消了Segment分段锁的数据结构,取而代之的是数组+链表(红黑树)的结构。而对于锁的粒度,调整为对每个数组元素加锁(Node)。然后是定位节点的hash算法被简化了,这样带来的弊端是Hash冲突会加剧。因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。这样一来,查询的时间复杂度就会由原先的O(n)变为O(logN)。下面是其基本结构:
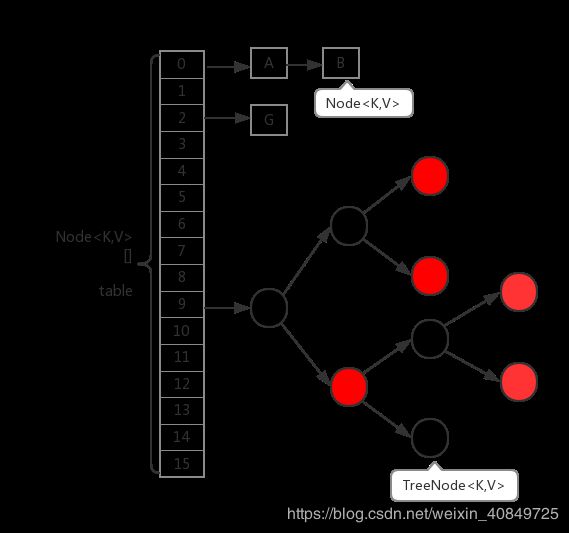
1、ConcurrentHashMap内部是一个Node节点的数组table,数组的每一个位置table[i]代表一个桶。根据键的hash值映射到不同的桶内。
transient volatile Node<K,V>[] table;
2、Node节点一共有5种类型
1、Node节点,是所有节点的父类,可以单独放入桶内,也可以作为链表的头放入桶内。
2、TreeNode节点,继承自Node,是红黑树的节点,此节点不能直接放入桶内,只能是作为红黑树的节点。
3、TreeBin节点,TreeNode的代理节点,可以放入桶内,这个节点下面可以连接红黑树的根节点,所以叫做TreeNode的代理节点。
4、ForwardingNode节点,扩容节点,只是在扩容阶段使用的节点,当前桶扩容完毕后,桶内会放入这个节点,此时查询会跳转到查询扩容后的table,不存储实际数据
5、ReservationNode节点,内部方法使用,暂时可以忽略。
TreeNode就是红黑树的结点,TreeNode不会直接链接到table[i]——桶上面,而是由TreeBin链接,TreeBin会指向红黑树的根结点。当扩容时,桶中存的是ForwardingNode,ForwardingNode指向链表或指针的头结点。
关于各种节点的介绍可参考:多线程(十四、ConcurrentHashMap原理(1)节点)
基本概念
sizeCtl
/**
* Table initialization and resizing control. When negative, the
* table is being initialized or resized: -1 for initialization,
* else -(1 + the number of active resizing threads). Otherwise,
* when table is null, holds the initial table size to use upon
* creation, or 0 for default. After initialization, holds the
* next element count value upon which to resize the table.
*/
private transient volatile int sizeCtl;
/*
* Encodings for Node hash fields. See above for explanation.
*/
// hash值是-1,表示这是一个forwardNode节点,表示在扩容阶段,该桶已扩容完成,查询时会被转到新table中查询
static final int MOVED = -1;
// hash值是-2 表示这时一个TreeBin节点,代表是红黑树,在TreeBin构建红黑树时设置
static final int TREEBIN = -2;
sizeCtl用于table[]的初始化和扩容操作,不同值的代表状态如下:
- -1:table[]正在初始化。
- -N:表示有N-1个线程正在进行扩容操作。
- 非负情况:
- 如果table[]未初始化,则表示table需要初始化的大小。
- 如果初始化完成,则表示table[]扩容的阀值,默认是table[]容量的0.75 倍。
扩容时sizeCtl变化
//第一条扩容线程设置的某个特定基数
U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
//后续线程加入扩容大军时每次加 1
U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)
//线程扩容完毕退出扩容操作时每次减 1
U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)
作用:sizeCtl 用于记录当前扩容的并发线程数情况,此时 sizeCtl 的值为:((rs << RESIZE_STAMP_SHIFT) + 2) + (正在扩容的线程数) ,并且该状态下 sizeCtl < 0 。
实例构造方法
// 1\. 构造一个空的map,即table数组还未初始化,初始化放在第一次插入数据时,默认大小为16
ConcurrentHashMap()
// 2\. 给定map的大小
ConcurrentHashMap(int initialCapacity)
// 3\. 给定一个map
ConcurrentHashMap(Map<? extends K, ? extends V> m)
// 4\. 给定map的大小以及加载因子
ConcurrentHashMap(int initialCapacity, float loadFactor)
// 5\. 给定map大小,加载因子以及并发度(预计同时操作数据的线程)
ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel)
ConcurrentHashMap一共给我们提供了5中构造器方法,具体使用请看注释,我们来看看第2种构造器,传入指定大小时的情况,该构造器源码为:
public ConcurrentHashMap(int initialCapacity) {
//1\. 小于0直接抛异常
if (initialCapacity < 0)
throw new IllegalArgumentException();
//2\. 判断是否超过了允许的最大值,超过了话则取最大值,否则再对该值进一步处理
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
//3\. 赋值给sizeCtl,此时table[]还未初始化,所以sizeCtl保存的是要初始化的大小
this.sizeCtl = cap;
}
调用构造器方法的时候并未构造出table数组(可以理解为ConcurrentHashMap的数据容器),只是算出table数组的长度,当第一次向ConcurrentHashMap插入数据的时候才真正的完成初始化创建table数组的工作。
initTable方法
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
// 1\. 保证只有一个线程正在进行初始化操作
Thread.yield(); // lost initialization race; just spin
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { //sizeCtl为-1时,表示正在初始化
try {
if ((tab = table) == null || tab.length == 0) {
// 2\. 得出数组的大小
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
// 3\. 这里才真正的初始化数组
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// 4\. 计算数组中可用的大小:实际大小n*0.75(加载因子),n-(1/4)n=(3/4)n
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc; //初始化完成时,sizeCtl表示table[]扩容阈值
}
break;
}
}
return tab;
}
put()操作
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
// onlyIfAbsent 用于区分 当key存在时,是否覆盖旧值
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//1\. 计算key的hash值
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//2\. 如果当前table还没有初始化先调用initTable方法将tab进行初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//3\. tab中索引为i的位置的元素为null,则直接使用CAS将值插入即可
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//4\. 当前正在扩容
else if ((fh = f.hash) == MOVED) //MOVED = -1;
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { //锁的粒度为table[i],即链表或者红黑树的第一个节点
if (tabAt(tab, i) == f) {
//5\. 当前为链表,在链表中插入新的键值对,当为红黑树时fh是小于0的
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent) // 覆盖旧值
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 6.当前为红黑树,将新的键值对插入到红黑树中
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 7.插入完键值对后再根据实际大小看是否需要转换成红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD) // TREEIFY_THRESHOLD = 8;
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//8.对当前容量大小进行检查,如果超过了临界值(实际大小*加载因子)就需要扩容
addCount(1L, binCount);
return null;
}
从上面代码可以看出,put的步骤大致如下:
- 参数校验。
- 若table[]未创建,则初始化。
- 当table[i]后面无节点时,直接创建Node(无锁操作)。
- 如果当前正在扩容,则帮助扩容并返回最新table[]。
- 然后在链表或者红黑树中追加节点。
- 最后还回去判断是否到达阀值,如到达变为红黑树结构
why:
if (tabAt(tab, i) == f) {
//5. 当前为链表,在链表中插入新的键值对
spread()
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
链表转红黑树
treeifyBin:链表转红黑树
/**
* Replaces all linked nodes in bin at given index unless table is
* too small, in which case resizes instead.
*/
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
if ((n = tab.length) < MIN_TREEIFY_CAPACITY) // MIN_TREEIFY_CAPACITY = 64
tryPresize(n << 1);
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
在这段代码中我们知道,先对传进来的桶长度进行判断,如果桶的长度小于64,则会调用tryPresize()方法,这个方法的作用就是将容量翻倍,也就是当桶的长度大于8的时候,第一时间不是树化,而是扩大当前桶的长度,如果桶的长度大于等于64,则进行树化操作。看代码块中,同步锁锁的依旧是桶的首节点,然后使用一个for循环,遍历当前桶,注意两个语句:
1、if ((p.prev = tl) == null)
2、tl.next = p
在tl不等于null的情况下,也就是从桶的第二个节点开始,前一个节点的next指向后一个节点,后一个节点的prev指向前一个节点,通俗点说就是遍历这个链表,使它成为一个双端链表,然后再把这个双端链表的头结点作为参数传到TreeBin
TreeBin(TreeNode b) : 构建红黑树
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null); //将TreeBin的hash置为-2,表示是红黑树
this.first = b;
TreeNode<K,V> r = null;
for (TreeNode<K,V> x = b, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
//将根节点设置为黑色,并且赋值给r
if (r == null) {
x.parent = null;
x.red = false;
r = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
//开始遍历
for (TreeNode<K,V> p = r;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h) // 小于,存于左子树中
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) //注意if后面没跟{, 所以满足条件只会执行一条语句
dir = tieBreakOrder(k, pk); // 对于没有实现Comparable的key,使用默认的hashCode()方法进行比较
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) { // 遍历到叶子节点
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
r = balanceInsertion(r, x); // 将红黑树重新保持平衡
break;
}
}
}
}
this.root = r;
assert checkInvariants(root);
}
super(TREEBIN, null, null, null);表示创建一个hash值为-2的TreeBin,所以回过头去看上边的代码,你会发现,链表和红黑树的区别在于链表首节点的hash大于0,而红黑树的首节点hash等于-2.
TreeNode就是红黑树的结点,TreeNode不会直接链接到table[i]——桶上面,而是由TreeBin链接,TreeBin会指向红黑树的根结点。
balanceInsertion :
tryPresize : 数组长度为64以下时触发的扩容
/**
* Tries to presize table to accommodate the given number of elements.
*
* @param size number of elements (doesn't need to be perfectly accurate)
*/
//putAll批量插入或者插入节点后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容会调用到这个方法
private final void tryPresize(int size) {
// MAXIMUM_CAPACITY = 1 << 30
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY : tableSizeFor(size + (size >>> 1) + 1);
int sc;
//如果不满足条件,也就是 sizeCtl < 0 ,说明有其他线程正在扩容当中,这里也就不需要自己去扩容了,结束该方法
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
//如果数组初始化则进行初始化,这个选项主要是为批量插入操作方法 putAll 提供的
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
//初始化时将 sizeCtl 设置为 -1 ,保证单线程初始化
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
//初始化完成后 sizeCtl 用于记录当前集合的负载容量值,也就是触发集合扩容的阈值
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
//插入节点后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容会进入到下面这个 else if 分支
else if (tab == table) {
int rs = resizeStamp(n);
//下面的内容基本跟上面 addCount 方法的 while 循环内部一致,可以参考上面的注释
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
将数据放到红黑树
putTreeVal : 放入红黑树
/**
* Finds or adds a node.
* @return null if added
*/
final TreeNode<K,V> putTreeVal(int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
if (p == null) {
first = root = new TreeNode<K,V>(h, k, v, null, null);
break;
}
else if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
if (((ch = p.left) != null &&
(q = ch.findTreeNode(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.findTreeNode(h, k, kc)) != null))
return q;
}
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
TreeNode<K,V> x, f = first;
first = x = new TreeNode<K,V>(h, k, v, f, xp);
if (f != null)
f.prev = x;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
if (!xp.red)
x.red = true;
else {
lockRoot();
try {
root = balanceInsertion(root, x);
} finally {
unlockRoot();
}
}
break;
}
}
assert checkInvariants(root);
return null;
}
findTreeNode :查找treeNode
/**
* Returns the TreeNode (or null if not found) for the given key
* starting at given root.
*/
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0) //利用比较器kc,比较k pk
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null) // 去右子树查找,针对key没有实现Comparable的场景
return q;
else
p = pl; // 去左子树查找,跟上面去右子树查找效果一样;(因为findTreeNode方法内部就只有一个循环,所以可以这样写)
} while (p != null);
}
return null;
}
扩容
ConcurrentHashMap1.8 - 扩容详解,这篇博文讲的超级棒
什么时候触发扩容?
总的来说
-
在调用 addCount 方法增加集合元素计数后发现当前集合元素个数到达扩容阈值时就会触发扩容 。(putval() --> addCount() --> transfer())
-
扩容状态下其他线程对集合进行插入、修改、删除、合并、compute 等操作时遇到 ForwardingNode 节点会触发扩容 。(putval() -> helpTransfer() --> transfer())
-
putAll 批量插入或者插入节点后发现存在链表长度达到 8 个或以上,但数组长度为 64 以下时会触发扩容 。(tryPresize() --> transfer())
注意:桶上链表长度达到 8 个或者以上,并且数组长度为 64 以下时只会触发扩容而不会将链表转为红黑树 。
addCount : 扩容检查
//新增元素时,也就是在调用 putVal 方法后,为了通用,增加了个 check 入参,用于指定是否可能会出现扩容的情况
//check >= 0 即为可能出现扩容的情况,例如 putVal方法中的调用
private final void addCount(long x, int check) {
ConcurrentHashMap.CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
ConcurrentHashMap.CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//检查当前集合元素个数 s 是否达到扩容阈值 sizeCtl ,扩容时 sizeCtl 为负数,依旧成立,同时还得满足数组非空且数组长度不能大于允许的数组最大长度这两个条件才能继续
//这个 while 循环除了判断是否达到阈值从而进行扩容操作之外还有一个作用就是当一条线程完成自己的迁移任务后,如果集合还在扩容,则会继续循环,继续加入扩容大军,申请后面的迁移任务
while (s >= (long)(sc = sizeCtl) && (tab = table) != null && (n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
// sc < 0 说明集合正在扩容当中
if (sc < 0) {
//判断扩容是否结束或者并发扩容线程数是否已达最大值,如果是的话直接结束while循环
// 如果 sc 的低 16 位不等于 标识符(校验异常 sizeCtl 变化了)
// 如果 sc == 标识符 + 1 (扩容结束了,不再有线程进行扩容)(默认第一个线程设置 sc ==rs 左移 16 位 + 2,
//当第一个线程结束扩容了,就会将 sc 减一。这个时候,sc 就等于 rs + 1)
// 如果 sc == 标识符 + 65535(帮助线程数已经达到最大)
// 如果 nextTable == null(结束扩容了)
// 如果 transferIndex <= 0 (桶的迁移任务都已分配)
// 结束循环
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1
|| sc == rs + MAX_RESIZERS || (nt = nextTable) == null || transferIndex <= 0)
break;
//扩容还未结束,并且允许扩容线程加入,此时加入扩容大军中
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
//如果集合还未处于扩容状态中,则进入扩容方法,并首先初始化 nextTab 数组,也就是新数组
//(rs << RESIZE_STAMP_SHIFT) + 2 为首个扩容线程所设置的特定值,后面扩容时会根据线程是否为这个值来确定是否为最后一个线程
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
并发编程——ConcurrentHashMap#addCount() 分析
helpTransfer :
//扩容状态下其他线程对集合进行插入、修改、删除、合并、compute等操作时遇到 ForwardingNode 节点会调用该帮助扩容方法 (ForwardingNode 后面介绍)
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) {
Node<K,V>[] nextTab; int sc;
if (tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) {
int rs = resizeStamp(tab.length);
//此处的 while 循环是上面 addCount 方法的简版,可以参考上面的注释
while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
扩容过程:
transfer : 扩容
//调用该扩容方法的地方有:
//java.util.concurrent.ConcurrentHashMap#addCount 向集合中插入新数据后更新容量计数时发现到达扩容阈值而触发的扩容
//java.util.concurrent.ConcurrentHashMap#helpTransfer 扩容状态下其他线程对集合进行插入、修改、删除、合并、compute 等操作时遇到 ForwardingNode 节点时触发的扩容
//java.util.concurrent.ConcurrentHashMap#tryPresize putAll批量插入或者插入后发现链表长度达到8个或以上,但数组长度为64以下时触发的扩容
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
//计算每条线程处理的桶个数,每条线程处理的桶数量一样,如果CPU为单核,则使用一条线程处理所有桶,否则将 length / 8 然后除以 CPU核心数
//每条线程至少处理16个桶,如果计算出来的结果少于16,则一条线程处理16个桶
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // 初始化新数组(原数组长度的2倍)
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
//将 transferIndex 指向最右边的桶,也就是数组索引下标最大的位置
transferIndex = n;
}
int nextn = nextTab.length;
//新建一个占位对象,该占位对象的 hash 值为 -1 该占位对象存在时表示集合正在扩容状态,key、value、next 属性均为 null ,nextTable 属性指向扩容后的数组
//该占位对象主要有两个用途:
// 1、占位作用,用于标识数组该位置的桶已经迁移完毕,处于扩容中的状态。
// 2、作为一个转发的作用,扩容期间如果遇到查询操作,遇到转发节点,会把该查询操作转发到新的数组上去,不会阻塞查询操作。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
//该标识用于控制是否继续处理下一个桶,为 true 则表示已经处理完当前桶,可以继续迁移下一个桶的数据
boolean advance = true;
//该标识用于控制扩容何时结束,该标识还有一个用途是最后一个扩容线程会负责重新检查一遍数组查看是否有遗漏的桶
boolean finishing = false; // to ensure sweep before committing nextTab
//这个循环用于处理一个 stride 长度的任务,i 后面会被赋值为该 stride 内最大的下标,而 bound 后面会被赋值为该 stride 内最小的下标
//通过循环不断减小 i 的值,从右往左依次迁移桶上面的数据,直到 i 小于 bound 时结束该次长度为 stride 的迁移任务
//结束这次的任务后会通过外层 addCount、helpTransfer、tryPresize 方法的 while 循环达到继续领取其他任务的效果
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
//每处理完一个hash桶就将 bound 进行减 1 操作
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
//transferIndex <= 0 说明数组的hash桶已被线程分配完毕,没有了待分配的hash桶,将 i 设置为 -1 ,后面的代码根据这个数值退出当前线的扩容操作
i = -1;
advance = false;
}
//只有首次进入for循环才会进入这个判断里面去,设置 bound 和 i 的值,也就是领取到的迁移任务的数组区间
else if (U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
//扩容结束后做后续工作,将 nextTable 设置为 null,表示扩容已结束,将 table 指向新数组,sizeCtl 设置为扩容阈值
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
//每当一条线程扩容结束就会更新一次 sizeCtl 的值,进行减 1 操作
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
//(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT 成立,说明该线程不是扩容大军里面的最后一条线程,直接return回到上层while循环
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
//(sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT 说明这条线程是最后一条扩容线程
//之所以能用这个来判断是否是最后一条线程,因为第一条扩容线程进行了如下操作:
// U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2)
//除了修改结束标识之外,还得设置 i = n; 以便重新检查一遍数组,防止有遗漏未成功迁移的桶
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
//遇到数组上空的位置直接放置一个占位对象,以便查询操作的转发和标识当前处于扩容状态
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
//数组上遇到hash值为MOVED,也就是 -1 的位置,说明该位置已经被其他线程迁移过了,将 advance 设置为 true ,以便继续往下一个桶检查并进行迁移操作
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
//该节点为链表结构
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
//遍历整条链表,找出 lastRun 节点
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
//根据 lastRun 节点的高位标识(0 或 1),首先将 lastRun设置为 ln 或者 hn 链的末尾部分节点,后续的节点使用头插法拼接
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
//使用高位和低位两条链表进行迁移,使用头插法拼接链表
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
//setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法
//使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果
//使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上
setTabAt(nextTab, i, ln);
//使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上
setTabAt(nextTab, i + n, hn);
//迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用
setTabAt(tab, i, fwd);
//advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶
advance = true;
}
//该节点为红黑树结构
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
//lo 为低位链表头结点,loTail 为低位链表尾结点,hi 和 hiTail 为高位链表头尾结点
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
//同样也是使用高位和低位两条链表进行迁移
//使用for循环以链表方式遍历整棵红黑树,使用尾插法拼接 ln 和 hn 链表
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
//这里面形成的是以 TreeNode 为节点的链表
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
//形成中间链表后会先判断是否需要转换为红黑树:
//1、如果符合条件则直接将 TreeNode 链表转为红黑树,再设置到新数组中去
//2、如果不符合条件则将 TreeNode 转换为普通的 Node 节点,再将该普通链表设置到新数组中去
//(hc != 0) ? new TreeBin(lo) : t 这行代码的用意在于,如果原来的红黑树没有被拆分成两份,那么迁移后它依旧是红黑树,可以直接使用原来的 TreeBin 对象
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
//setTabAt方法调用的是 Unsafe 类的 putObjectVolatile 方法
//使用 volatile 方式的 putObjectVolatile 方法,能够将数据直接更新回主内存,并使得其他线程工作内存的对应变量失效,达到各线程数据及时同步的效果
//使用 volatile 的方式将 ln 链设置到新数组下标为 i 的位置上
setTabAt(nextTab, i, ln);
//使用 volatile 的方式将 hn 链设置到新数组下标为 i + n(n为原数组长度) 的位置上
setTabAt(nextTab, i + n, hn);
//迁移完成后使用 volatile 的方式将占位对象设置到该 hash 桶上,该占位对象的用途是标识该hash桶已被处理过,以及查询请求的转发作用
setTabAt(tab, i, fwd);
//advance 设置为 true 表示当前 hash 桶已处理完,可以继续处理下一个 hash 桶
advance = true;
}
}
}
}
}
}
get()操作
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// 1\. 重hash
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 2\. table[i]桶节点的key与查找的key相同,则直接返回
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// 3\. 当前节点hash小于0说明为树节点,在红黑树中查找即可
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
//4\. 从链表中查找,查找到则返回该节点的value,否则就返回null即可
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
参考:
关于ConcurrentHashMap方面红黑树的讲解
ConcurrentHashMap1.8 - 扩容详解
ConcurrentHashMap的JDK1.8实现
多线程(十四、ConcurrentHashMap原理(1)节点)
并发编程——ConcurrentHashMap#addCount() 分析
ConcurrentHashMap源码阅读补充3——TreeBin需要额外的读写锁机制
并发编程——ConcurrentHashMap#transfer() 扩容逐行分析
ConcurrentHashMap的红黑树实现分析