网址:http://www.52ml.net/tags/计算机视觉/page/3
【计算机视觉】Canny Edge边缘检测器
2013年10月13日
机器学习
计算机视觉
smallroof
引言
Canny提出一种新的边缘检测方法[1][2],它对受白噪声影响的阶跃型边缘是最优的。整个Canny边缘检测器算法分成四步.
Canny边缘检测算子
Canny边缘分成四步:
-
噪声去除。因为这个检测器用到了微分算子,所以对于局部的不连续是敏感的,某区域的噪声点很容易造成边缘的模糊。在我做的这个应用里,因为要检测的是文本的边缘,而文本的背景是比较规则的变形后的正方形方格,所以如果用wiki里建议的高斯滤波器,会造成整个图像都变成一种颜色,即全黑或者全白。因此如果换一种观点,把这些变形后的方格也看成图的一部分,因为字体的纹理和方格的纹理不同,所以可以看作是两种区域组合成的图像。由此我改用一般的镜子,增强图像边缘。
-
计算图像的边缘梯度。这个是常规运算,用了Sobel算子,分别计算图像的x和y方向的梯度值,最后计算出图像各点的梯度值以及梯度角。计算得到梯度角需要进行近似,近似四个值{-45(或135), 0, 45,90}。
-
非最大梯度值点抑制第2步计算后得到两组值,第一组是各点的梯度值,第二组是各点梯度角的近似值。这一个非最大梯度值点抑制是比较不好理解的一步。遍历各点,做如下操作。(1)如果该点(x, y)的梯度角是0,如果其梯度值比北(x – 1, y)和南(x + 1, y)的梯度值大,则认为(x,y)点是一个边缘点,否则抑制其值,该其梯度值为设定的背景值(0或255);(2)如果该点(x, y)的梯度角是90,如果其梯度值比西(x, y – 1)和东(x, y +1)的梯度值大,则认为(x, y)点是一个边缘点,否则抑制其值,该其梯度值为设定的背景值(0或255); (3)如果该点(x,y)的梯度角是135(或-45),如果其梯度值比东北(x – 1, y + 1)和西南(x + 1, y -1)的梯度值大,则认为(x, y)点是一个边缘点,否则抑制其值,该其梯度值为设定的背景值(0或255); (4)如果该点(x,y)的梯度角是45,如果其梯度值比西北(x – 1, y – 1)和东南(x + 1, y + 1)的梯度值大,则认为(x,y)点是一个边缘点,否则抑制其值,该其梯度值为设定的背景值(0或255)。
-
产生边缘. 在第3步里直接用边缘值和背景值对两种图像区域进行了划分。这么做对于图像不同区域像素值区别较大的场合比较方便,计算也快,但是对于图像不同区域像
Canny边缘检测代码和Main程序
// Canny edge detection #include "stdio.h"#include "cv.h"#include "highgui.h"#define PI 3.1415926535#define ORI_SCALE 40.0#define MAG_SCALE 20.0#define MAX_MASK_SIZE 20float ratio = 0.1f;int WIDTH = 0;long seed = 132531;typedef struct image * IMAGE;int range (IMAGE im, int i, int j);void print_se (IMAGE p);IMAGE Input_PBM (char *fn);IMAGE Output_PBM (IMAGE image, char *filename);void get_num_pbm (FILE *f, char *b, int *bi, int *res);void pbm_getln (FILE *f, char *b);void pbm_param (char *s);struct image *newimage (int nr, int nc);void freeimage (struct image *z);void sys_abort (int val, char *mess);void CopyVarImage (IMAGE *a, IMAGE *b);void Display (IMAGE x);float ** f2d (int nr, int nc);void srand32 (long k);double drand32 ();void copy (IMAGE *a, IMAGE b);int trace (int i, int j, int low, IMAGE im,IMAGE mag, IMAGE ori);float gauss(float x, float sigma);float dGauss (float x, float sigma);float meanGauss (float x, float sigma);void hysteresis (int high, int low, IMAGE im, IMAGE mag, IMAGE oriim);void canny (float s, IMAGE im, IMAGE mag, IMAGE ori);void seperable_convolution (IMAGE im, float *gau, int width,float **smx, float **smy);void dxy_seperable_convolution (float** im, int nr, int nc, float *gau, int width, float **sm, int which);void nonmax_suppress (float **dx, float **dy, int nr, int nc,IMAGE mag, IMAGE ori);void estimate_thresh (IMAGE mag, int *low, int *hi);void canny (float s, IMAGE im, IMAGE mag, IMAGE ori){ int width; float **smx,**smy; float **dx,**dy; int i,j,n; float gau[MAX_MASK_SIZE], dgau[MAX_MASK_SIZE], z; // Create a Gaussian and a derivative of Gaussian filter mask for(i=0; iinfo->nr, im->info->nc); smy = f2d (im->info->nr, im->info->nc); //Convolution of source image with a Gaussian in X and Y directions seperable_convolution (im, gau, width, smx, smy); //Now convolve smoothed data with a derivative printf ("Convolution with the derivative of a Gaussian...\n"); dx = f2d (im->info->nr, im->info->nc); dxy_seperable_convolution (smx, im->info->nr, im->info->nc,dgau, width, dx, 1); free(smx[0]); free(smx); dy = f2d (im->info->nr, im->info->nc); dxy_seperable_convolution (smy, im->info->nr, im->info->nc, dgau, width, dy, 0); free(smy[0]); free(smy); // Create an image of the norm of dx,dy for (i=0; iinfo->nr; i++) for (j=0; jinfo->nc; j++) { z = norm (dx[i][j], dy[i][j]); mag->data[i][j] = (unsigned char)(z*MAG_SCALE); } //Non-maximum suppression - edge pixels should be a local max nonmax_suppress (dx, dy, (int)im->info->nr, (int)im->info->nc, mag, ori); free(dx[0]); free(dx); free(dy[0]); free(dy);}int main ( ){ int i,j; float s=1.0; int low= 0,high=-1; FILE *params; IMAGE im, magim, oriim; char name[128]; // Try to read an image printf ("Enter path to the image file to be processed: "); scanf ("%s", name); printf ("Opening file '%s'\n", name); //Read parameters from the file canny.par params = fopen ("canny.par", "r"); if (params){ fscanf (params, "%d", &low); // Lower threshold fscanf (params, "%d", &high); // High threshold fscanf (params, "%f", &s); // Gaussian standard deviation printf ("Parameters from canny.par: HIGH: %d LOW %d Sigma %f\n", high, low, s); fclose (params); } else printf ("Parameter file 'canny.par' does not exist.\n"); im = get_image(name); display_image (im); // Create local image space magim = newimage (im->info->nr, im->info->nc); if (magim == NULL){ printf ("Out of storage: Magnitude\n"); exit (1); } oriim = newimage (im->info->nr, im->info->nc); if (oriim == NULL){ printf ("Out of storage: Orientation\n"); exit (1); } canny (s, im, magim, oriim); // Apply the filter hysteresis (high, low, im, magim, oriim); //Hysteresis thresholding of edge pixels for (i=0; iinfo->nc; j++) im->data[i][j] = 255; for (i=im->info->nr-1; i>im->info->nr-1-WIDTH; i--) for (j=0; jinfo->nc; j++) im->data[i][j] = 255; for (i=0; iinfo->nr; i++) for (j=0; jdata[i][j] = 255; for (i=0; iinfo->nr; i++) for (j=im->info->nc-WIDTH-1; jinfo->nc; j++) im->data[i][j] = 255; display_image (im); save_image (im, "canny.jpg"); return 0;}
参考文献
[1] Canny J. F. "Finding edges and lines in images" Technical Report AI-TR-720,MIT,Artifical Inteligence Labortay,Cambridg,MA,1983.
[2] Canny J. F. "a Computational Approach to Edge Detection", IEEE Trancsctions on Pattern Analysis and Machine Intelligence, 8(6):679-698,1996.
======================================================
转载请注明出处 : http://blog.csdn.net/utimes/article/details/8827781
======================================================
本文转载自:CSDN博客
计算机视觉领域的一些牛人博客,超有实力的研究机构等的网站链接—个人整理 – 射手炎魂
2013年10月11日
机器学习
计算机视觉
smallroof
由 carson2005 » 2011-05-06 20:46
提示:本文为笔者原创,转载请注明出处:blog.csdn.net/carson2005
以下链接是本人整理的关于计算机视觉(ComputerVision, CV)相关领域的网站链接,其中有CV牛人的主页,CV研究小组的主页,CV领域的paper,代码,CV领域的最新动态,国内的应用情况等等。打算从事这个行业或者刚入门的朋友可以多关注这些网站,多了解一些CV的具体应用。搞研究的朋友也可以从中了解到很多牛人的研究动态、招生情况等。总之,我认为,知识只有分享才能产生更大的价值,真诚希望下面的链接能对朋友们有所帮助。
(1)googleResearch; http://research.google.com/index.html
(2)MIT博士,汤晓欧学生林达华; http://people.csail.mit.edu/dhlin/index.html
(3)MIT博士后Douglas Lanman; http://web.media.mit.edu/~dlanman/
(4)opencv中文网站; http://www.opencv.org.cn/index.php/%E9%A6%96%E9%A1%B5
(5)Stanford大学vision实验室; http://vision.stanford.edu/research.html
(6)Stanford大学博士崔靖宇; http://www.stanford.edu/~jycui/
(7)UCLA教授朱松纯; http://www.stat.ucla.edu/~sczhu/
(8)中国人工智能网; http://www.chinaai.org/
(9)中国视觉网; http://www.china-vision.net/
(10)中科院自动化所; http://www.ia.cas.cn/
(11)中科院自动化所李子青研究员; http://www.cbsr.ia.ac.cn/users/szli/
(12)中科院计算所山世光研究员; http://www.jdl.ac.cn/user/sgshan/
(13)人脸识别主页; http://www.face-rec.org/
(14)加州大学伯克利分校CV小组; http://www.eecs.berkeley.edu/Research/P … CS/vision/
(15)南加州大学CV实验室; http://iris.usc.edu/USC-Computer-Vision.html
(16)卡内基梅隆大学CV主页; http://www.cs.cmu.edu/afs/cs/project/ci … ision.html
(17)微软CV研究员Richard Szeliski;http://research.microsoft.com/en-us/um/people/szeliski/
(18)微软亚洲研究院计算机视觉研究组; http://research.microsoft.com/en-us/groups/vc/
(19)微软剑桥研究院ML与CV研究组; http://research.microsoft.com/en-us/gro … fault.aspx
(20)研学论坛; http://bbs.matwav.com/
(21)美国Rutgers大学助理教授刘青山; http://www.research.rutgers.edu/~qsliu/
(22)计算机视觉最新资讯网; http://www.cvchina.info/
(23)运动检测、阴影、跟踪的测试视频下载; http://apps.hi.baidu.com/share/detail/18903287
(24)香港中文大学助理教授王晓刚; http://www.ee.cuhk.edu.hk/~xgwang/
(25)香港中文大学多媒体实验室(汤晓鸥); http://mmlab.ie.cuhk.edu.hk/
(26)U.C. San Diego. computer vision; http://vision.ucsd.edu/content/home
(27)CVonline; http://homepages.inf.ed.ac.uk/rbf/CVonline/
(28)computer vision software; http://peipa.essex.ac.uk/info/software.html
(29)Computer Vision Resource; http://www.cvpapers.com/
(30)computer vision research groups; http://peipa.essex.ac.uk/info/groups.html
(31)computer vision center; http://computervisioncentral.com/cvcnews
(32)浙江大学图像技术研究与应用(ITRA)团队:http://www.dvzju.com/
(33)自动识别网:http://www.autoid-china.com.cn/
(34)清华大学章毓晋教授:http://www.tsinghua.edu.cn/publish/ee/4157/2010/20101217173552339241557/20101217173552339241557_.html
(35)顶级民用机器人研究小组Porf.Gary领导的Willow Garage:http://www.willowgarage.com/
(36)上海交通大学图像处理与模式识别研究所:http://www.pami.sjtu.edu.cn/
(37)上海交通大学计算机视觉实验室刘允才教授:http://www.visionlab.sjtu.edu.cn/
(38)德克萨斯州大学奥斯汀分校助理教授Kristen Grauman :http://www.cs.utexas.edu/~grauman/
(39)清华大学电子工程系智能图文信息处理实验室(丁晓青教授):http://ocrserv.ee.tsinghua.edu.cn/auto/index.asp
(40)北京大学高文教授:http://www.jdl.ac.cn/htm-gaowen/
(41)清华大学艾海舟教授:http://media.cs.tsinghua.edu.cn/cn/aihz
(42)中科院生物识别与安全技术研究中心:http://www.cbsr.ia.ac.cn/china/index%20CH.asp
(43)瑞士巴塞尔大学 Thomas Vetter教授:http://informatik.unibas.ch/personen/vetter_t.html
(44)俄勒冈州立大学 Rob Hess博士:http://blogs.oregonstate.edu/hess/
(45)深圳大学 于仕祺副教授:http://yushiqi.cn/
(46)西安交通大学人工智能与机器人研究所:http://www.aiar.xjtu.edu.cn/
(47)卡内基梅隆大学研究员Robert T. Collins:http://www.cs.cmu.edu/~rcollins/home.html#Background
(48)MIT博士Chris Stauffer:http://people.csail.mit.edu/stauffer/Home/index.php
(49)美国密歇根州立大学生物识别研究组(Anil K. Jain教授):http://www.cse.msu.edu/rgroups/biometrics/
(50)美国伊利诺伊州立大学Thomas S. Huang:http://www.beckman.illinois.edu/directory/t-huang1
(51)武汉大学数字摄影测量与计算机视觉研究中心:http://www.whudpcv.cn/index.asp
(52)瑞士巴塞尔大学Sami Romdhani助理研究员:http://informatik.unibas.ch/personen/romdhani_sami/
(53)CMU大学研究员Yang Wang:http://www.cs.cmu.edu/~wangy/home.html
(54)英国曼彻斯特大学Tim Cootes教授:http://personalpages.manchester.ac.uk/staff/timothy.f.cootes/
(55)美国罗彻斯特大学教授Jiebo Luo:http://www.cs.rochester.edu/u/jluo/
(56)美国普渡大学机器人视觉实验室:https://engineering.purdue.edu/RVL/Welcome.html
(57)美国宾利州立大学感知、运动与认识实验室:http://vision.cse.psu.edu/home/home.shtml
(58)美国宾夕法尼亚大学GRASP实验室:https://www.grasp.upenn.edu/
(59)美国内达华大学里诺校区CV实验室:http://www.cse.unr.edu/CVL/index.php
(60)美国密西根大学vision实验室:http://www.eecs.umich.edu/vision/index.html
(61)University of Massachusetts(麻省大学),视觉实验室:http://vis-www.cs.umass.edu/index.html
(62)华盛顿大学博士后Iva Kemelmacher:http://www.cs.washington.edu/homes/kemelmi
(63)以色列魏茨曼科技大学Ronen Basri:http://www.wisdom.weizmann.ac.il/~ronen/index.html
(64)瑞士ETH-Zurich大学CV实验室:http://www.vision.ee.ethz.ch/boostingTrackers/index.htm
(65)微软CV研究员张正友:http://research.microsoft.com/en-us/um/people/zhang/
(66)中科院自动化所医学影像研究室:http://www.3dmed.net/
(67)中科院田捷研究员:http://www.3dmed.net/tian/
(68)微软Redmond研究院研究员Simon Baker:http://research.microsoft.com/en-us/people/sbaker/
(69)普林斯顿大学教授李凯:http://www.cs.princeton.edu/~li/
(70)普林斯顿大学博士贾登:http://www.cs.princeton.edu/~jiadeng/
(71)牛津大学教授Andrew Zisserman: http://www.robots.ox.ac.uk/~az/
(72)英国leeds大学研究员Mark Everingham:http://www.comp.leeds.ac.uk/me/
(73)英国爱丁堡大学教授Chris William: http://homepages.inf.ed.ac.uk/ckiw/
(74)微软剑桥研究院研究员John Winn: http://johnwinn.org/
(75)佐治亚理工学院教授Monson H.Hayes:http://savannah.gatech.edu/people/mhayes/index.html
(76)微软亚洲研究院研究员孙剑:http://research.microsoft.com/en-us/people/jiansun/
(77)微软亚洲研究院研究员马毅:http://research.microsoft.com/en-us/people/mayi/
(78)英国哥伦比亚大学教授David Lowe: http://www.cs.ubc.ca/~lowe/
(79)英国爱丁堡大学教授Bob Fisher: http://homepages.inf.ed.ac.uk/rbf/
(80)加州大学圣地亚哥分校教授Serge J.Belongie:http://cseweb.ucsd.edu/~sjb/
(81)威斯康星大学教授Charles R.Dyer: http://pages.cs.wisc.edu/~dyer/
(82)多伦多大学教授Allan.Jepson: http://www.cs.toronto.edu/~jepson/
(83)伦斯勒理工学院教授Qiang Ji: http://www.ecse.rpi.edu/~qji/
(84)CMU研究员Daniel Huber: http://www.ri.cmu.edu/person.html?person_id=123
(85)多伦多大学教授:David J.Fleet: http://www.cs.toronto.edu/~fleet/
(86)伦敦大学玛丽女王学院教授Andrea Cavallaro:http://www.eecs.qmul.ac.uk/~andrea/
(87)多伦多大学教授Kyros Kutulakos: http://www.cs.toronto.edu/~kyros/
(88)杜克大学教授Carlo Tomasi: http://www.cs.duke.edu/~tomasi/
(89)CMU教授Martial Hebert: http://www.cs.cmu.edu/~hebert/
(90)MIT助理教授Antonio Torralba: http://web.mit.edu/torralba/www/
(91)马里兰大学研究员Yasel Yacoob: http://www.umiacs.umd.edu/users/yaser/
(92)康奈尔大学教授Ramin Zabih: http://www.cs.cornell.edu/~rdz/
(93)CMU博士田渊栋: http://www.cs.cmu.edu/~yuandong/
(94)CMU副教授Srinivasa Narasimhan: http://www.cs.cmu.edu/~srinivas/
(95)CMU大学ILIM实验室:http://www.cs.cmu.edu/~ILIM/
(96)哥伦比亚大学教授Sheer K.Nayar: http://www.cs.columbia.edu/~nayar/
(97)三菱电子研究院研究员Fatih Porikli :http://www.porikli.com/
(98)康奈尔大学教授Daniel Huttenlocher:http://www.cs.cornell.edu/~dph/
(99)南京大学教授周志华:http://cs.nju.edu.cn/zhouzh/index.htm
(100)芝加哥丰田技术研究所助理教授Devi Parikh: http://ttic.uchicago.edu/~dparikh/index.html
(101)瑞士联邦理工学院博士后Helmut Grabner: http://www.vision.ee.ethz.ch/~hegrabne/#Short_CV
(102)香港中文大学教授贾佳亚:http://www.cse.cuhk.edu.hk/~leojia/index.html
(103)南洋理工大学副教授吴建鑫:http://c2inet.sce.ntu.edu.sg/Jianxin/index.html
(104)GE研究院研究员李关:http://www.cs.unc.edu/~lguan/
(105)佐治亚理工学院教授Monson Hayes:http://savannah.gatech.edu/people/mhayes/
(106)图片检索国际会议VOC(微软剑桥研究院组织): http://pascallin.ecs.soton.ac.uk/challenges/VOC/
(107)机器视觉开源处理库汇总:http://archive.cnblogs.com/a/2217609/
(108)布朗大学教授Benjamin Kimia: http://www.lems.brown.edu/kimia.html
(109)数据堂-图像处理相关的样本数据:http://www.datatang.com/data/list/602026/p1
(110)东软基于CV的汽车辅助驾驶系统:http://www.neusoft.com/cn/solutions/1047/
(111)马里兰大学教授Rema Chellappa:http://www.cfar.umd.edu/~rama/
(112)芝加哥丰田研究中心助理教授Devi Parikh:http://ttic.uchicago.edu/~dparikh/index.html
(113)宾夕法尼亚大学助理教授石建波:http://www.cis.upenn.edu/~jshi/
(114)比利时鲁汶大学教授Luc Van Gool:http://www.vision.ee.ethz.ch/members/get_member.cgi?id=1,http://www.vision.ee.ethz.ch/~vangool/
(115)行人检测主页:http://www.pedestrian-detection.com/
(116)法国学习算法与系统实验室Basilio Noris博士:http://lasa.epfl.ch/people/member.php?SCIPER=129576 http://mldemos.epfl.ch/
(117)美国马里兰大学LARRY S.DAVIS教授:http://www.umiacs.umd.edu/~lsd/
(118)计算机视觉论文分类导航:http://www.visionbib.com/bibliography/contents.html
(119)计算机视觉分类信息导航:http://www.visionbib.com/
(120)西班牙马德里理工大学博士Marcos Nieto:http://marcosnieto.net/
(121)香港理工大学副教授张磊:http://www4.comp.polyu.edu.hk/~cslzhang/
(122)以色列技术学院教授Michael Elad:http://www.cs.technion.ac.il/~elad/
(123)韩国启明大学计算机视觉与模式识别实验室:http://cvpr.kmu.ac.kr/
(124)英国诺丁汉大学Michel Valstar博士:http://www.cs.nott.ac.uk/~mfv/
(125)卡内基梅隆大学Takeo Kanade教授:http://www.ri.cmu.edu/people/kanade_takeo.html
(126)微软学术搜索:http://libra.msra.cn/
(127)比利时天主教鲁汶大学Radu Timofte博士:http://homes.esat.kuleuven.be/~rtimofte/,交通标志检测,定位,3D跟踪
(128)迪斯尼匹兹堡研究院研究员:Iain Matthews:http://www.iainm.com/iainm/Home.html
http://www.ri.cmu.edu/person.html?type= … son_id=741 AAM,三维重建
(129)康奈尔大学视觉与图像分析组:http://www.via.cornell.edu/ 医学图像处理
(130)密西根州立大学生物识别研究组:http://www.cse.msu.edu/biometrics/ 人脸识别、指纹识别、图像检索
(131)柏林科技大学计算机视觉与遥感实验室:http://www.cv.tu-berlin.de/menue/computer_vision_remote_sensing/parameter/en/ 图像分析、物体重建、基于图像的表面测量、医学图像处理
(132)英国布里斯托大学数字多媒体研究组:http://www.cs.bris.ac.uk/Research/Digitalmedia/ 运动检测与跟踪、视频压缩、3D重建、字符定位
(133)英国萨利大学视觉、语音与信号处理中心: http://www.surrey.ac.uk/cvssp/ 人脸识别、监控、3D、视频检索、
(134)北卡莱罗纳大学教堂山分校Marc Pollefeys教授:http://www.cs.unc.edu/~marc/ 基于视频的3D模型生成、相机标定、运动检测与分析、3D重建
(135)澳大利亚国立大学Richard Hartley教授:http://users.cecs.anu.edu.au/~hartley/ 运动估计、稀疏子空间、跟踪、
(136)百度技术副总监于凯:http://www.dbs.ifi.lmu.de/~yu_k/ 深度学习,稀疏表示,图像分类
(137)西安电子科技大学高新波教授:http://web.xidian.edu.cn/xbgao/index.html 质量评判、水印、稀疏表示、超分辨率
(138)加州大学伯克利分校Michael I.Jordan教授:http://www.cs.berkeley.edu/~jordan/ 机器学习
(139)加州理工行人检测相关资料:http://www.vision.caltech.edu/Image_Datasets/CaltechPedestrians/
(140)微软Redmond研究院研究员Piotr Dollar: http://vision.ucsd.edu/~pdollar/ 行人检测、特征提取、
(141)视觉计算研究论坛:http://www.sigvc.org/bbs/ 中科院视觉计算研究小组的论坛
(142)美国坦桑尼亚州立大学稀疏学习软件包:http://www.public.asu.edu/~jye02/Software/SLEP/index.htm 稀疏学习
(143)美国加州大学圣地亚哥分校Jacob Whitehill博士:http://mplab.ucsd.edu/~jake/ 机器学习
(144)美国布朗大学Michael J.Black教授:http://cs.brown.edu/~black/ 人的姿态估计和跟踪
(145)美国加州大学圣地亚哥分校David Kriegman教授:http://cseweb.ucsd.edu/~kriegman/ 人脸识别
(146)南加州大学Paul Debevec教授:http://ict.debevec.org/~debevec/ 或 http://www.pauldebevec.com/ 将CV和CG结合研究 人脸捕捉重建技术
(147)伊利诺伊大学D.A.Forsyth教授:http://luthuli.cs.uiuc.edu/~daf/ 三维重建
(148)英国牛津大学Ian Reid教授:http://www.robots.ox.ac.uk/~ian/ 跟踪和机器人导航
(149)CMU大学Alyosha Efros 教授: https://www.cs.cmu.edu/~efros/ 图像纹理合成
(150)加州大学伯克利分校Jitendra Malik教授:http://www.cs.berkeley.edu/~malik/ 轮廓检测、图像/视频分割、图形匹配、目标识别
(151)MIT教授William Freeman: http://people.csail.mit.edu/billf/ 应用于CV的ML、可视化感知的贝叶斯模型、计算摄影学;最有影响力的研究成果:图像纹理合成
(152)CMU博士Henry Schneiderman: http://www.cs.cmu.edu/~hws/ 目标检测和识别;最有影响力的研究成果:目标检测;2000年CVPR上发表了”A statistical method for 3D object detection applied to faces and cars”。该算法采用多视角训练样本,可用于检测不同视角下的物体,如人脸和车,是第一个能够检测侧脸的算法。他创建了PittPatt公司,后被Google收购
(153)微软研究员Paul Viola: http://research.microsoft.com/en-us/um/people/viola/ AdaBoost算法
(154)微软研究员Antonio Criminisi: http://research.microsoft.com/en-us/people/antcrim/ 图像修补,三维重建,目标检测与跟踪;
(155)魏茨曼科学研究所教授Michal Irani: http://www.wisdom.weizmann.ac.il/~irani/ 超分辨率
(156)瑞士洛桑理工学院Pascal Fua教授:http://people.epfl.ch/pascal.fua/bio?lang=en 立体视觉,增强现实
(157)佐治亚理工学院Irfan Essa教授:http://www.ic.gatech.edu/people/irfan-essa 人脸表情识别
整理的内容不见得完善,也不见得能满足所有朋友的需要。如果您有更好的网站资源,欢迎推荐给我。另外,如果你不想记录所有这些链接,也可以去我的博客,所有这些网址在我的博客都有链接。而且,以后我还会不断更新!我的博客是:http://blog.csdn.net/carson2005
最后由 carson2005 编辑于 2013-03-02 9:44,总共编辑了 20 次
my blog: http://blog.csdn.net/carson2005 QQ:1079185264
carson2005
OpenCV博士
帖子: 577
注册: 2008-10-01 19:22
本文转载自:博客园-原创精华区

图像检索和视频检索领域的会议和杂志
2013年10月4日
机器学习
信息检索, 模式识别, 计算机视觉
smallroof
下面介绍一些图像检索(Image Retrieval)和视频检索(Video Retrieval)领域相关的国际会议和杂志。
Conferences
[1] ACM international conference on Multimedia
[2] IEEE International Conference on Multimedia and Expo (ICME)
[3] ACM International Conference on Multimedia Information Retrieval (MIR)
[4] International Conference on Image and Video Retrieval (CIVR)
[5] IEEE Pacific-Rim Conference On Multimedia (PCM)
[6] IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)
[7] International Conference on Computer Vision (ICCV)
[8] European Conference on Computer Vision (ECCV)
[9] International Conference on Acoustics, Speech, and Signal Processing (ICASSP)
[10] IEEE International Conference on Image Processing (ICIP)
[11] International Conference on Pattern Recognition (ICPR)
Journals
[1] IEEE Transactions on Pattern Analysis and Machine Intelligence
[2] IEEE Transaction on Multimedia
[3] IEEE Trans. on Circuits Systems for Video Technology (T-CSVT)
[4] Pattern Recognition
[5] IEEE Image Processing
[6] Multimedia Systems
[7] Image and Vision Computing
[8] Multimedia Analysis for Security Application
[9] Foundations and Trends® in Information Retrieval
[10] International Journal of Image and Graphics (IJIG )
Copyright: icvpr
本文转载自:Tech2Vision
AppSeed:用计算机视觉和手机加速UI设计
2013年10月3日
机器学习
用户界面设计, 计算机视觉
smallroof
数字设计师们,把你们的眼睛放到 Kickstarter项目AppSeed 上,它利用计算机视觉技术来加速设计过程的早期阶段。AppSeed的想法是让设计师们能快速将纸上的草图变成可操作的UI原型,以便测试工作流,获取早期设计观点的反馈。
要怎么才能做到这一点呢?活动发起人的计划是制作一款名为AppSeed的应用,设计师可以用手机拍摄设计草图,AppSeed的计算机视觉算法会区分并识别出草图上的不同UI元素,并且给元素以应有的功能。比如,一个文本框的草图会变成可以输入文本的框。
AppSeed的制作者们使用开源计算机视觉库 OpenCV 和自行设计的算法来区分并识别UI元素。该应用会通过分析元素的形状或相对位置,来猜测元素是什么。如果应用不能立即判断出元素所属的种类,它会向用户弹出UI元素列表,要求用户选取元素的功能。
AppSeed的格雷格·格拉斯基(Greg Goralski)解释道:“AppSeed使用OpenCV库来识别封闭形状,然后根据元素位置、大小和形状来判定元素所属分类。因此,左上方的箭头很有可能就是返回键,而同一位置画上三条水平短线就可能是菜单按钮。50px高、非常宽的空长方形可以被认为是文本输入框。”
“AppSeed默认将元素变成按钮。当然,设计师可以直接设置元素类型(这也是搞定事情的主要做法)。它使用了发现轮廓和匹配模板这两项技术来识别形状和特定元素。”
AppSeed的重心就放在UI设计的早期阶段——“最初的头脑风暴和回炉重做阶段”。“你在项目之初的想法越多,最终产品就越好。我们想让最初阶段的UI设计变得更容易、更快、更自然。”
有趣的是,这款面向数字设计师们的应用认为纸会继续在这一过程中扮演关键角色,即便有很多电子方法可以直接在计算机(平板电脑、智能笔、设计软件等)上画草图。但在头脑风暴早期设计上,格拉斯基认为很难打败纸笔。
“我们当然能直接引入数字文件,但感觉用纸和笔来画草图还会陪伴我们很长时间”,他说道:“笔和纸(以及白板和标记笔)如此快、如此自然,开始项目时自然会选择它们。数字工具很棒,也出现很长时间了,但笔和纸让人感觉很对,也很容易进行协作,且能常伴左右。”
从纸上转移到AppSeed中的设计将会作为UI原型在应用内运行,也可以以HTML5原型的形式分享给其他人,无需安装AppSeed就可以测试工作流。
目前还没有最终应用的完整UI元素列表(假设其融资成功的话),该团队计划从支持者获得反馈,了解他们想要的元素种类。格拉斯基表示,可能加入的元素包括:地图、街景、滑块、弹窗、边栏目录、开关、列表、返回键、社交媒体连接、打开相机(和其他按钮),还包括扫动、捏放和轻点等手势。
在AppSeed的原型阶段完成后,设计就可以移交至下一阶段的设计,用Photoshop制作分层文件(比如每个按钮或元素都有单独的层,以便于操控)。
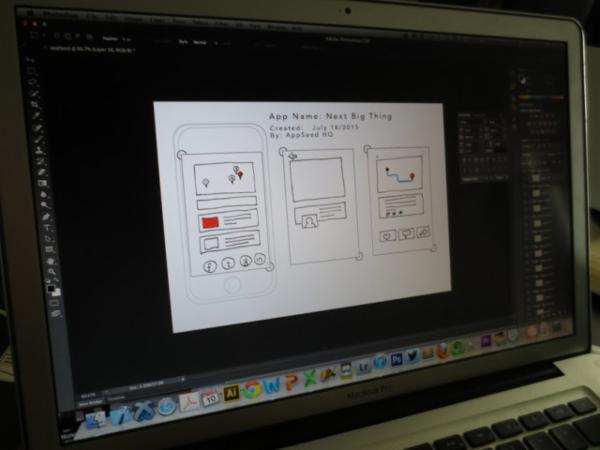
格拉斯基称,AppSeed概念的主要竞争对手是 POP 和 Protosketch ,但通过在应用中加入计算机视觉技术,AppSeed要更好。“两款[竞争应用]都是拍摄草图照片并在应用中显示。区别在于我们会用计算机视觉来区分元素。正是这一阶段让我们把图形变成UI元素。这一区别差异巨大。”
目前,AppSeed团队已经制作出了可运作的应用原型,但在寻求资金将它变成完整的iOS应用(众筹活动中也将推出Android应用列入了计划之中)。
他们正在寻求筹资3万加元来制作iOS应用,目前已接近筹款目标的一半,而30天的筹款活动还剩下大概10天。Kickstarter活动版应用的价格起价为8加元和30加元(30加元可以得到应用和速写薄)。他们计划在1月发布应用。
本文转载自:TechCrunch中国

模式识别,计算机视觉,计算机图形学,智能控制,信号处理,语音识别,知识处理,机器学习,数据挖掘领域区别
2013年9月22日
机器学习
模式识别, 计算机视觉, 语音识别
smallroof
1.人工智能:给机器赋予人类的智能,让机器能够像人类那样独立思考。当然,目前的人工智能没有发展到很高级的程度,这种智能与人类的大脑相比还是处于非常幼稚的阶段,但目前我们可以让计算机掌握一定的知识,更加智能化的帮助我们实现简单或复杂的活动。2.机器学习。通俗的说就是让机器自己去学习,然后通过学习到的知识来指导进一步的判断。举个最简单的例子,我们训练小狗狗接飞碟时,当小狗狗接到并送到主人手中时,主人会给一定的奖励,否则会有惩罚。于是狗狗就渐渐学会了接飞碟。同样的道理,我们用一堆的样本数据来让计算机进行运算,样本数据可以是有类标签的,并设计惩罚函数,通过不断的迭代,机器就学会了怎样进行分类,使得惩罚最小。然后用学习到的分类规则进行预测等活动。3.数据挖掘。数据挖掘是一门交叉性很强的学科,可以用到机器学习算法以及传统统计的方法,最终的目的是要从数据中挖掘到为我所用的知识,从而指导人们的活动。所以我认为数据挖掘的重点在于应用,用何种算法并不是很重要,关键是能够满足实际应用背景。而机器学习则偏重于算法本身的设计。
数据挖掘与知识发现(第二版)中说道,数据挖掘任务分类:包括分类或预测模型知识发现,数据总结,数据聚类,关联规则发现,时序模式发现,依赖关系或依赖模型发现,异常和趋势发现等。
数据挖掘对象分类:包括数据库,面向对象数据库,空间数据库,时态数据库,文本数据库,多媒体数据库,异构数据库,数据仓库,演绎数据库和Web数据库等。
数据挖掘方法分类:包括统计方法,机器学习方法,神经网络方法和数据库方法。4.模式识别。我觉得模式识别偏重于对信号、图像、语音、文字、指纹等非直观数据方面的处理,如语音识别,人脸识别等,通过提取出相关的特征,利用这些特征来进行搜寻我们想要找的目标。
数据挖掘是数据库知识发现(KDD)过程中应用数据分析和发现算法的一个步骤,在可接受的计算效率的局限性之内,在数据上产生一种特殊的列举模式(或模型)。要注意模式空间通常是无限的而且模式的列举包括对那个空间某种形式的搜索。
5.计算机视觉
计算机视觉是一门关于如何运用照相机和计算机来获取我们所需的,被拍摄对象的数据与信息的学问。形象地说,就是给计算机安装上眼睛(照相机)和大脑(算法),让计算机能够感知环境。我们中国人的成语"眼见为实"和西方人常说的"One picture is worth ten thousand words"表达了视觉对人类的重要性。不难想象,具有视觉的机器的应用前景能有多么地宽广。
计算机视觉既是工程领域,也是科学领域中的一个富有挑战性重要研究领域。计算机视觉是一门综合性的学科,它已经吸引了来自各个学科的研究者参加到对它的研究之中。其中包括 计算机科学 和工程、 信号处理 、 物理学 、应用数学和统计学,神经生理学和认知科学 等。
6.智能控制
智能控制的定义一: 智能控制是由智能机器自主地实现其目标的过程。而 智能机器 则定义为,在结构化或非结构化的,熟悉的或陌生的环境中,自主地或与人交互地执行人类规定的任务的一种机器。
定义二: K.J.奥斯托罗姆则认为,把人类具有的直觉推理和试凑法等智能加以形式化或机器模拟,并用于控制系统的分析与设计中,以期在一定程度上实现控制系统的智能化,这就是智能控制。他还认为自调节控制,自适应控制就是智能控制的低级体现。
定义三: 智能控制是一类无需人的干预就能够自主地驱动智能机器实现其目标的自动控制,也是用计算机模拟人类智能的一个重要领域。
定义四: 智能控制实际只是研究与模拟人类智能活动及其控制与信息传递过程的规律,研制具有仿人智能的工程控制与信息处理系统的一个新兴分支学科。
从20世纪60年代起,计算机技术和人工智能技术迅速发展,为了提高控制系统的自学习能力,控制界学者开始将 人工智能技术应用于控制系统 。
人工智能 是
计算机科学
的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、 语言识别 、
图像识别
、
自然语言处理
和
专家系统
等。
研究范畴:
自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法。
7.信号处理,语音识别,知识处理都是人工智能所要研究的内容。
区别:以上内容都包括在人工智能的范围之内。
对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。由于统计学往往醉心于理论的优美而忽视实际的效用,因此,统计学界提供的很多技术通常都要在机器学习界进一步研究,变成有效的机器学习算法之后才能再进入数据挖掘领域。从这个意义上说,统计学主要是通过机器学习来对数据挖掘发挥影响,而机器学习和数据库则是数据挖掘的两大支撑技术。从数据分析的角度来看,绝大多数数据挖掘技术都来自机器学习领域,但机器学习研究往往并不把海量数据作为处理对象,因此,数据挖掘要对算法进行改造,使得算法性能和空间占用达到实用的地步。同时,数据挖掘还有自身独特的内容,即关联分析。
而模式识别和机器学习的关系是什么呢,传统的模式识别的方法一般分为两种:统计方法和句法分析方法。句法分析一般是不可学习的,而统计分析则是发展了不少机器学习的方法。也就是说,机器学习同样是给模式识别提供了数据分析技术。
至于,数据挖掘和模式识别,那么从其概念上来区分吧,数据挖掘重在 发现知识 ,模式识别重在 认识事物 。
机器学习的目的是建模隐藏的数据结构,然后做识别、预测、分类等。
因此,机器学习是方法,模式识别是目的。
智能控制包括机器学习这个方面 。智能控制与数据挖掘的区别,智能控制也包括数据挖掘。 计算机视觉也包括数据挖掘 ???
有不少学科的研究目标与 计算机视觉 相近或与此有关。这些 学科 中包括图像处理、 模式识别 或 图像识别 、景物分析、图象理解等。计算机视觉包括图像处理和模式识别,除此之外,它还包括空间形状的描述,几何建模以及认识过程。实现图像理解是计算机视觉的终极目标。
图像处理 技术把输入图像转换成具有所希望特性的另一幅图像。例如,可通过处理使输出图象有较高的信-噪比,或通过增强处理突出图象的细节,以便于操作员的检验。在计算机视觉研究中经常利用图象处理技术进行预处理和 特征抽取 。
模式识别 技术 根据从图象抽取的统计特性或结构信息,把图像分成予定的类别。例如,文字识别或 指纹识别 。在计算机视觉中模式识别技术经常用于对图象中的某些部分,例如分割区域的识别和分类。
根据我的研究体会,三者之间既有区别,又有联系。计算机图形学是给定关于景象结构、表面反射特性、光源配置及相机模型的信息,生成图像。而计算机视觉是给定图象,推断景象特性实现的是从模型到图像的变换,也就是说从图象数据提取信息,包括景象的三维结构,运动检测,识别物体等。模式识别则是从特征空间到类别空间的变换。研究内容包括特征提取(PCA,LDA,LFA,Kernel,Mean Shift,SIFT,ISOMAP,LLE);特征选择;分类器设计(SVM,AdaBoost)等。
本文转载自:CSDN博客
Some good resources: – Leo Han
2013年9月14日
机器学习
计算机视觉
smallroof
对一个方向的深入研究,必须建立在广泛且有质量的阅读、领悟之上。
研一的一年时间里,感觉虽然黄老师给我的任务并不重,课程压力也不大,但思想负担不轻。想在计算机视觉领域做出点东西,这一年是打基础、搞研究最重要的一年。
抓得住现在,才抓得住未来。
今天也找了一些计算机视觉领域的前沿阵地,有时间一定多看看。多学知识、多总结。
资源分为三类,第一类是一些注明的计算机视觉研究中心:
- 谷歌研究院: http://research.google.com/index.html
- 斯坦福视觉研究中心: http://vision.stanford.edu/research.html
- 中国视觉网: http://www.china-vision.net/
- 微软亚洲计算机视觉: http://research.microsoft.com/en-us/groups/vc/
- 微软剑桥研究院ML与CV研究组: http://research.microsoft.com/en-us/groups/mlp/default.aspx
- 香港中文大学多媒体实验室(汤晓鸥): http://mmlab.ie.cuhk.edu.hk/
第二类是不少的技术博客,关于做研究的一些心得和不少新鲜资讯,也可以研究一下。
偶尔能看到一篇挺好的文章,可惜都没有整理下来记住来源,看过就错过了,以后有发现再补上吧。
第三类是 顶级会议、大牛期刊的录取paper,可以多看看学习学习。
应该定期从PAMI上精读一两篇文章。
主要的有:
三大顶级会议:BMVC ICCV CVPR
巅峰期刊: PAMI
本文转载自:博客园-所有随笔区
49 款人脸检测/识别的API、库和软件
2013年8月31日
机器学习
人脸识别, 计算机视觉
smallroof
| 自从谷歌眼镜被推出以来,围绕人脸识别,出现了很多争议。我们相信,不管是不是通过智能眼镜,人脸识别将在人与人交往甚至人与物交互中开辟无数种可能性。 为了帮助研究过程中探索人脸识别,我们列出以下人脸检测和识别API。希望有所帮助! 
- Face Recognition – 拉姆达实验室斯蒂芬弄的。示例代码和图形演示点击http://api.lambdal.com/docs, 我们的API提供了面部识别,面部检测,眼睛定位,鼻子定位,嘴巴定位,和性别分类。如果您有任何疑问,只需发一封邮件到[email protected] 。
- Face (Detection) – 计算机视觉面部识别和面部检测。这是一个完美的face.com替代品。目前,我们有一个免费的API进行人脸检测。
- Animetrics Face Recognition – Animetrics的人脸识别API可用于图片中的人脸检测。面部特征或“地标”的信息被返回作为图象上的坐标。 Animetrics人脸识别也会在三维坐标轴上侦测并返回脸部位置信息。
- Skybiometry Face Detection and Recognition 一个易于使用的人脸检测与识别的API。必须在您的SkyBiometry帐户中创建应用程序来使用它。(如果你还没有帐户,请先注册)。
- ImageVision Face Detection – 测试版发布更好的人脸检测服务!ImageVision是一个计算机视觉公司改进技术,确定在任意的(数字)的图像中的人脸的位置和大小。
- Face and scene recognition by Rekognition.com – Face.com的替代品!快速,强大和可扩展的rekognition引擎可以做面部检测,采集,识别,场景理解!它可以自动训练使用Facebook上的图像和标签!
- FaceRect - FaceRect是一个功能强大且免费的API进行人脸检测,能够发现网页中的或者上传文件中特定图片上的脸部(包括正面和侧面),并能够在一张图片中找到多张人脸,生成的 JSON输出每个脸部的边界框。
- Infatics Face Detection -简单的 人脸检测 API。
- OpenCV Face Recognizer -基于 OpenCV (开源计算机视觉库: http://opencv.org )是一个开源的BSD授权的库,其中包括数百个计算机视觉算法。
- Libface – Libface库旨在使人脸识别技术应用于开源社区。这是用 C++ 编写的,托管在 Sourceforge上 。这个库使用 OpenCV 2.0 ,目标是成为一个中间件,在人脸识别和检测时,开发人员不必包括任何OpenCV的代码。
- Automatic naming of characters in video 用来是标记电视或电影每个帧中出现的人名。
- CCV -现代计算机视觉库。
- OpenBR -开源的生物特征识别。
- Flandmark -开源实现面部地标探测器。
- 计算机表情识别工具箱(CERT) -一个终端到终端的完全自动化的实时面部表情识别系统。
- Nviso 3D facial imaging technology -从面部表情分析人类的情感。比任何其他方法更直接和自动化。
- FaceReader – FaceReader是世界上第一个能够自动分析面部表情的工具,使用户能够客观的评估一个人的情绪。
- Affdex – – 通过摄像头,Affdex从面部表情读取的人们的情绪状态,比如喜好和兴趣,使营销人员更快,更准确地洞察到消费者对品牌和媒体的回应。
- Faceware – 分析仪从视频中抓取一个演员的面部表现,生成用于在 Retargeter™ 的IMPD文件 。它通过将用户在前端的简单输入和在后端的复杂的计算机视觉算法组合起来实现这一功能。
- 20. Face detection in iOS – 在iOS中的人脸检测 。
- Face-Recognition-SDK -在您的应用程序添加面部识别。
- Oddcast face detection API -这个人脸跟踪API允许Flash开发人员利用以前只在高端视频游戏中使用的高级技术。
- BioID -世界上第一个基于摄像头的个人识别。
- Betaface API -人脸检测和识别。
- Discrete Area Filters Face Detector —可检测脸部15个点,4个部分,多张脸,或遮住的脸。
- Face detection using Support Vector Machine -该程序是克隆MATLAB中的“人脸检测系统”,可以代替神经网络算法的 人脸检测 ,它是基于 SVG。
- fdlib – 是一个 C / C + + 和 MATLAB的人脸检测库,可检测图像中的正脸。
- Visage -一个人机接口,旨在用脸部取代传统的鼠标。用一个摄像头,将脸部面相的运动变成鼠标指针的运动。如左/右眼睛闪烁产生左/右鼠标点击事件。
- Face tracking Project (卡耐基梅隆大学)–结合可变形模板和颜色匹配来跟踪脸部。
- Real-time face detection program ( 实时人脸检测程序 )-来自德国弗劳恩霍夫研究所IIS的演示。展示了用边缘定位匹配的面部跟踪和检测。
- Evaluation of Face Recognition Algorithms -来自科罗拉多州立大学研究人员开发的人脸识别算法,它提供了一套标准的众所周知的算法,并建立实验 协议 。
- Computer Vision Source Code -实用的图像处理代码集合。
- Acsys biometrics SDK ( ACSYS生物识别SDK )-允许第三方开发者用先进的面部生物识别技术来实现自己应用。
- Cognitec SDK -为世界各地的企业和政府客户开发领先的人脸识别技术和应用。
- KeyLemonFaceSDK -为主要的操作系统提供集成识别技术。
- FaceIT SDK
- FaceSDK – 人脸识别和基于面部的生物识别功能,易整合。
- Verilook SDK -–使用了VeriLook算法,该算法确保快速和可靠的面部识别。
- Beyond Reality Face SDK -在视频流中的一张简单图片上,计算面部位置和3D角度。这些信息可以被用来将三维对象放置到图像上,或通过头部运动控制一个应用程序。
- InSight SDK -通过测量面部肌肉的运动,对人脸进行完全自动化分析,并将这些面部肌肉运动转化为七个普遍的面部表情。
- Visage FaceDetect SDK -以C++软件开发工具包的形式,包含了很多在静止图像中发现脸和五官的有用技术。
- Microsoft Research Face SDK Beta – 集成了微软研究团队最新的面部识别技术。
- How To: Kinect for Windows SDK Face Recognition
- Bayometric FaceIt Face Recognition SDK -结合了传统的面部皮肤生物识别技术。
- FacePhi FaceRecognition SDK –包含了一组.NET和Silverlight库
- 360Biometrics Face SDK -非常先进的脸部识别系统,用来将人脸图像嵌入或链接到已有的数据库中。
- Hunter TrueID
- IMRSV -现实世界中的实时感知计算软件,用一个基本的摄像头,就可以测量25英尺外,多达25人的性别,年龄,关注点,目光等信息。它也有一个REST API(应用编程接口)
- Bob -一个信号处理和机器学习工具箱,最初是由IDIAP研究所的生物识别技术团队在瑞士开发的 。
还有哪些是这个名单上缺少的吗?如果有,请在评论中添加。 原文链接: mashape 翻译: 伯乐在线 – 伯乐在线读者
译文链接: http://blog.jobbole.com/45936/ (mashape) |
本文转载自:流媒体家园 – 罗索工作室

《用Python构建机器学习》——第十章:计算机视觉-模式识别 读后小结
2013年8月28日
机器学习
Python, 模式识别, 计算机视觉
smallroof
本文是《Building Machine Learning Systems with Python》第十章的笔记。 亚马逊英文版链接 (话说亚马逊现在图书的介绍图像做得很赞啊!)
这本书和图灵出版的《机器学习实战》一书有点类似。《机器学习实战》那本书是非常建议购买一本的,如果这本书出版了,也建议购买一本。这里将阅读第十章的一些心得记录下来。
首先,关于第十章《Computer Vision: Pattern Recognition》。这一章有点名不符实,本章一半篇幅在介绍图像的基本处理,这一部分有点充数的感觉。
另外,本章使用了我以前没听过的 Mahotas 图像处理库。关于这个库的介绍可参见: 介绍 、 Github 、 官网 、 文档 。
我其实不清楚为什么作者使用这个库而不用OpenCV。比如,Mahotas远没有OpenCV功能强大,从 目前已有的信息 来看,Mahotas已有的优点,OpenCV都具有。另外,更重要的一点,根据国外友人的测试,OpenCV的速度远远快于其他常见的Python上的图像处理库,OpenCV比Mahotas快20-30倍,地址 在这 (自备梯子)。当然,不排除我对OpenCV先入为主的一些看法。
其实,上面一段是调侃的。。。因为后来我发现Mahotas软件包的作者就是本书的作者之一——Luis Pedro Coelho,这就不难理解为什么本书使用这个以前我没听过的库了。(仰天长笑,我还以为我out了。。。)
言归正传。本章的布局为:
10.1 Introducing image processing
10.2 Loading and displaying images
10.3 Basic image processing
Thresholding
Gaussian blurring
Filtering for different effects
Adding salt and pepper noise
Putting the center in focus
10.4 Pattern recognition
10.5 Computing features from images
10.6 Writing your own features
10.7 Classifying a harder dataset
10.8 Local feature representations
标题号是我自己加上去的,为了方便下文的说明。10.4之前的内容,除了Putting the center in focus的内容没有介绍外,其他都能在我的《 OpenCV-Python教程 》中找到。
10.4是模式识别,但这里有些误导。他用Tip来提示作者:“模式识别就是图像分类。由于历史原因,曾经将图像分类称为图像分类。但有关模式识别的应用和方法不只局限于图像方面。”根据机械工业出版社的《模式识别》一书,模式识别是将对象进行分类,这些对象包括图像、信号波形或者任何可测量且需要分类的对象。所以建议读者在记住知识点时,不要只看Tip的标题,还要看其说明。^_^。
10.5和10.6介绍计算特征图像以及如何自己编写特征。 Sobel算子 、 Laplacian算子 和Canny算子 都是计算图像特征的。图像特征并没有统一的定义,但可以看一下 维基百科的词条 ,这个词条是介绍特征提取,可以作为参考。
10.7是对10.8的铺垫,而10.8这介绍用Mahotas包中的函数应用SURF算法,并用K均值对不同结果进行了精度评价。有空我写一篇OpenCV-Python关于SURF的文章。
个人观点,这一章对计算机视觉的机器学习方面做了初步的介绍,并且宣传了作者自己的Mahotas函数包。读者要想在计算机视觉充分利用机器学习,还需要进一步的学习。
友情提示:尊重版权,请勿索要电子版,谢谢。
本文转载自:sunny2038的专栏

[收藏]40多个关于人脸检测/识别的API、库和软件
2013年8月19日
机器学习
人脸识别, 计算机视觉
smallroof
补充:
50:Face++: http://cn.faceplusplus.com/
—-
收藏原因:忒多了。。
原文链接: mashape 翻译: 伯乐在线 – 伯乐在线读者
译文链接: http://blog.jobbole.com/45936/
————————————
自从谷歌眼镜被推出以来,围绕人脸识别,出现了很多争议。我们相信,不管是不是通过智能眼镜,人脸识别将在人与人交往甚至人与物交互中开辟无数种可能性。
为了帮助研究过程中探索人脸识别,我们列出以下人脸检测和识别 API。希望有所帮助!

- Face Recognition - 拉姆达实验室斯蒂芬弄的。示例代码和图形演示点击http://api.lambdal.com/docs, 我们的 API 提供了面部识别,面部检测,眼睛定位,鼻子定位,嘴巴定位,和性别分类。如果您有任何疑问,只需发一封邮件到[email protected] 。
- Face (Detection) – 计算机视觉面部识别和面部检测。这是一个完美的 face.com 替代品。目前,我们有一个免费的 API 进行人脸检测。
- Animetrics Face Recognition – Animetrics 的人脸识别 API 可用于图片中的人脸检测。面部特征或“地标”的信息被返回作为图象上的坐标。 Animetrics 人脸识别也会在三维坐标轴上侦测并返回脸部位置信息。
- Skybiometry Face Detection and Recognition 一个易于使用的人脸检测与识别的 API。必须在您的 SkyBiometry 帐户中创建应用程序来使用它。(如果你还没有帐户,请先注册)。
- ImageVision Face Detection – 测试版发布更好的人脸检测服务!ImageVision 是一个计算机视觉公司改进技术,确定在任意的(数字)的图像中的人脸的位置和大小。
- Face and scene recognition by Rekognition.com - Face.com 的替代品!快速,强大和可扩展的 rekognition 引擎可以做面部检测,采集,识别,场景理解!它可以自动训练使用 Facebook 上的图像和标签!
- FaceRect - FaceRect 是一个功能强大且免费的 API 进行人脸检测,能够发现网页中的或者上传文件中特定图片上的脸部(包括正面和侧面),并能够在一张图片中找到多张人脸,生成的 JSON 输出每个脸部的边界框。
- Infatics Face Detection -简单的 人脸检测 API。
- OpenCV Face Recognizer -基于 OpenCV(开源计算机视觉库: http://opencv.org )是一个开源的 BSD 授权的库,其中包括数百个计算机视觉算法。
- Libface - Libface 库旨在使人脸识别技术应用于开源社区。这是用 C++ 编写的,托管在 Sourceforge 上 。这个库使用 OpenCV 2. 0 ,目标是成为一个中间件,在人脸识别和检测时,开发人员不必包括任何 OpenCV 的代码。
- Automatic naming of characters in video 用来是标记电视或电影每个帧中出现的人名。
- CCV -现代计算机视觉库。
- OpenBR -开源的生物特征识别。
- Flandmark -开源实现面部地标探测器。
- 计算机表情识别工具箱(CERT) -一个终端到终端的完全自动化的实时面部表情识别系统。
- Nviso 3D facial imaging technology -从面部表情分析人类的情感。比任何其他方法更直接和自动化。
- FaceReader - FaceReader 是世界上第一个能够自动分析面部表情的工具,使用户能够客观的评估一个人的情绪。
- Affdex - – 通过摄像头,Affdex 从面部表情读取的人们的情绪状态,比如喜好和兴趣,使营销人员更快,更准确地洞察到消费者对品牌和媒体的回应。
- Faceware – 分析仪从视频中抓取一个演员的面部表现,生成用于在 Retargeter™ 的 IMPD 文件 。它通过将用户在前端的简单输入和在后端的复杂的计算机视觉算法组合起来实现这一功能。
- 20. Face detection in iOS - 在 iOS 中的人脸检测 。
- Face-Recognition-SDK -在您的应用程序添加面部识别。
- Oddcast face detection API -这个人脸跟踪 API 允许 Flash 开发人员利用以前只在高端视频游戏中使用的高级技术。
- BioID -世界上第一个基于摄像头的个人识别。
- Betaface API -人脸检测和识别。
- Discrete Area Filters Face Detector —可检测脸部 15 个点,4 个部分,多张脸,或遮住的脸。
- Face detection using Support Vector Machine -该程序是克隆 MATLAB 中的“人脸检测系统”,可以代替神经网络算法的 人脸检测 ,它是基于 SVG。
- fdlib – 是一个 C / C + + 和 MATLAB 的人脸检测库,可检测图像中的正脸。
- Visage -一个人机接口,旨在用脸部取代传统的鼠标。用一个摄像头,将脸部面相的运动变成鼠标指针的运动。如左/右眼睛闪烁产生左/右鼠标点击事件。
- Face tracking Project (卡耐基梅隆大学)–结合可变形模板和颜色匹配来跟踪脸部。
- Real-time face detection program ( 实时人脸检测程序 )-来自德国弗劳恩霍夫研究所 IIS 的演示。展示了用边缘定位匹配的面部跟踪和检测。
- Evaluation of Face Recognition Algorithms -来自科罗拉多州立大学研究人员开发的人脸识别算法,它提供了一套标准的众所周知的算法,并建立实验协议。
- Computer Vision Source Code -实用的图像处理代码集合。
- Acsys biometrics SDK ( ACSYS 生物识别 SDK )-允许第三方开发者用先进的面部生物识别技术来实现自己应用。
- Cognitec SDK -为世界各地的企业和政府客户开发领先的人脸识别技术和应用。
- KeyLemonFaceSDK -为主要的操作系统提供集成识别技术。
- FaceIT SDK
- FaceSDK - 人脸识别和基于面部的生物识别功能,易整合。
- Verilook SDK -–使用了 VeriLook 算法,该算法确保快速和可靠的面部识别。
- Beyond Reality Face SDK -在视频流中的一张简单图片上,计算面部位置和 3D 角度。这些信息可以被用来将三维对象放置到图像上,或通过头部运动控制一个应用程序。
- InSight SDK -通过测量面部肌肉的运动,对人脸进行完全自动化分析,并将这些面部肌肉运动转化为七个普遍的面部表情。
- Visage FaceDetect SDK -以 C++ 软件开发工具包的形式,包含了很多在静止图像中发现脸和五官的有用技术。
- Microsoft Research Face SDK Beta - 集成了微软研究团队最新的面部识别技术。
- How To: Kinect for Windows SDK Face Recognition
- Bayometric FaceIt Face Recognition SDK -结合了传统的面部皮肤生物识别技术。
- FacePhi FaceRecognition SDK –包含了一组 .NET 和 Silverlight 库
- 360Biometrics Face SDK -非常先进的脸部识别系统,用来将人脸图像嵌入或链接到已有的数据库中。
- Hunter TrueID
- IMRSV -现实世界中的实时感知计算软件,用一个基本的摄像头,就可以测量 25 英尺外,多达 25 人的性别,年龄,关注点,目光等信息。它也有一个 REST API(应用编程接口)
- Bob -一个信号处理和机器学习工具箱,最初是由 IDIAP 研究所的生物识别技术团队在瑞士开发的 。
还有哪些是这个名单上缺少的吗?如果有,请在评论中添加。
本文转载自:丕子

几个模式识别和计算机视觉相关的Matlab工具箱 – Hanson-jun
2013年7月2日
机器学习
MATLAB, 模式识别, 计算机视觉
smallroof
模式识别、计算机视觉、图像处理等领域大部分是对一些图像等数据的处理,比较常用的语言是C++和Matlab,相应也对应很多库,象opencv等,都是很好用功能也很强大,但是对于数据处理更方便的应该还是Matlab了,其强大的矩阵处理能力真是解决了很多问题,提高了编码效率。
这里我搜集了一些关于模式识别、视觉相关的Matlab工具箱(Toolbox),其中涵盖的东西就很多了,像是一些分类聚类的模型和算法,一些数据的表示和绘制等,应该会有所帮助,但是一般都是英文的,还是那句话,用到的话肯定英文也不是问题了,对吧。自己解决就行。
第一个,这个很全面但是很杂,直接涵盖了各行各业的,物理化学都有,不过还是以咱们的方向为主:
Matlab Toolboxes
下面介绍的几个在上面这个已经包含进去了,也相当于一个全面的链接库。
Statistical Pattern Recognition Toolbox ,这算是一个相当好用的了,也比较全面,看几个图:
再一个:
DCPR (Data Clustering & Pattern Recognition) Toolbox ,也看几个图:
- gmmGrowDemo : Animation of GMM (Gaussian mixture models) growing with center splitting
再来一个: David M.J. Tax — Data description toolbox (dd_tools)
当然,网上还有很多很多,还有很多很多牛人作者页面上的很多很多源码,在做研究的时候有机缘碰到选择一下就一般能用。
本文转载自:Hanson-jun Blog
