JUC集合类 ConcurrentLinkedDueue源码解析 JDK8
文章目录
- 前言
- 概述
- linkFirst 入队
- pollFirst 获取并出队
- first()
- succ()
- unlink()
- unlinkFirst
- skipDeletedPredecessors
- updateHead
- updateTail
- gc-unlinking
- 松弛阈值
- unlink的Unlink interior node逻辑
- peekFirst 仅获取
- remove 删除操作
- size
- 迭代器
- 总结
前言
ConcurrentLinkedDueue是一个无界的双端队列,底层是双向链表,它的并发操作是基于CAS的无锁实现,所以不会产生阻塞。
要想理解ConcurrentLinkedDueue,先去理解了ConcurrentLinkedQueue才是快捷方式,因为它们二者使用的概念和函数实现的套路实际上都很类似。
JUC框架 系列文章目录
概述
- 一个node的item不为null,被认为是live node。因为一个node的item为null说明它已经是逻辑上被删除了,不过注意,初始化时队列中只有一个dummy node,它的item为null。
- 任何时刻,队列中只有一个first node,因为只有它的prev指针为null;只有一个last node,因为只有它的next指针为null。
- first node和last node可能不是live的(比如初始化时),它们之间可以通过prev和next链相互到达。
- 当一个新node被附在first node的prev上,或者附在last node的next上时,它就成功入队了。
- head或tail并不一定指向first node或last node。但通过head肯定能找到first node,tail同理。
- active node指处于队列上的节点,它们之间通过prev和next链能相互到达,当然active node的item可以是null。所以active node包括live node。
- 对节点的删除有三个步骤:
- “logical deletion”。将node的item置为null,它在逻辑上已经被认为是删除了的。
- “unlinking”。使得从active node出发不能到达这些逻辑删除节点(反之,从逻辑删除节点节点出发还是可以到达active node的),这样,GC最终会发现这些逻辑删除节点。
- “gc-unlinking”。使得从逻辑删除节点也不能到达active node了,这样,会使得GC更快发现它们。当然,第三步只是一种优化,没有第三步节点也会被回收。这只是为了保持GC健壮性。
- 在这一步中,会使得node self-links(即指针指向自己),另一个指针指向end终止符(end指first端或last端)。
- head和tail可能被unlinking,但不可以被gc-unlinking。
- 通过两种方法最小化volatile写的次数:
- 允许head或tail偏离first node或last node。
- 对同一块内存区域使用 volatile写 和 非volatile写 两种方式结合使用。比如
lazySetNext和casNext结合使用、UNSAFE.putObject(this, itemOffset, item)和casItem的结合使用。
- 一般认为队首在左边,队尾在右边。所以往prev链方向前进称为左移,往next链方向前进称为右移。
linkFirst 入队
offer(E)、add(E)、push(E)、addFirst(E)、addLast(E)、offerFirst(E)、offerLast(E)都是属于入队动作,它们的实现都依赖于linkFirst和linkLast。这些方法如果没有没有标注first或者last,那么默认都是从last端入队(这符合常识,从队尾入队)。但除了push方法(它是在first端操作),因为push和pop属于一对栈的方法,所以把last当作栈底,first当作栈顶,所以push和pop都是在操作first端了。
由于linkFirst、linkLast二者的实现完全对称,所以在此只会讲解linkFirst的入队,这个你看懂了,那么linkLast你也触类旁通了。
此函数的目的就是找到first node,并把新节点串在first node的左边。但是此函数不会在于first node的item是否为null。
private void linkFirst(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
restartFromHead:
for (;;)
for (Node<E> h = head, p = h, q;;) {
if ((q = p.prev) != null &&
(q = (p = q).prev) != null)
//该分支自动左移p,左移后如果p左边还有节点,则进入此分支。
p = (h != (h = head)) ? h : q;//判断p的更新动作是左移,还是变成新head
else if (p.next == p) // 如果已经脱离队列了,继续外循环,重新读取head
continue restartFromHead;
//执行到这里,说明p已经是first node了。
else {
newNode.lazySetNext(p); // 这里不需要volatile写动作
if (p.casPrev(null, newNode)) {
// CAS成功说明p已经成功从first端入队
if (p != h) // p和h的距离至少为1,现在p左边还加了个新节点,所以head需要更新了
casHead(h, newNode); // CAS失败是允许的
return;
}
// CAS失败就是入队失败,需要继续循环直到成功
}
}
}
if ((q = p.prev) != null && (q = (p = q).prev) != null)分支的理解很关键,让我们来拆分一下逻辑:
| 条件1 | 附带效果 | 条件2 | 附带效果 | 结果 |
|---|---|---|---|---|
p.prev ≠null |
获得了p的前驱q | q.prev≠null |
q和p整体左移 | 左移后,p离first node距离至少为1,进入分支,分支内逻辑为再次移动p |
p.prev ≠null |
获得了p的前驱q | q.prev=null |
q和p整体左移(q为null) | p刚移动到first node了,不进入分支 |
p.prev =null |
获得了p的前驱q(q为null) | 短路不执行 | - | p就是first node时,不进入分支 |
很巧妙的是,只要p到达了first node,就不会进入这个分支了。
p = (h != (h = head)) ? h : q;的逻辑就是,如果检测到head相比之前取的局部变量h发生了变化,p就赋值为新head(锚点需要更新,所以p也需要归位)。否则,p就是左移一下即可。
newNode.lazySetNext(p)不需要volatile写动作,之后的casPrev如果成功,便会自动使得这个newNode.lazySetNext(p)普通写动作对所有线程可见。

if (p != h)说明head距离新入队的节点的距离至少为2,所以此时需要更新head。这说明每隔一次入队动作,head或tail才会更新一次,这个和ConcurrentLinkedQueue一样(这一句就不画图表现了)。
![]()
一个初始化的ConcurrentLinkedDueue(初始化只有一个dummy node,它的item为null),只进行两端的入队操作的话,它的样子可能是上图这样的。
pollFirst 获取并出队
poll、pop、remove、pollFirst、pollLast、removeFirst、removeLast都是属于出队并移除的动作,它们的实现都依赖于pollFirst、pollLast,由于pollFirst、pollLast二者的实现完全对称,所以在此只会讲解pollFirst的出队,这个你看懂了,那么pollLast你也触类旁通了。
有意思的是,如果某个方法没有标注first或者last,那么它一定调用的first版本的函数。因为一般认为出队就是从first端出队的。
pollFirst()获得并移除队首节点。它寻找的是第一个live node,并返回它的item域。
public E pollFirst() {
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null && p.casItem(item, null)) {//删除的第一步,逻辑删除
unlink(p);
return item;
}
}
return null;
}
first()
pollFirst()首先调用first()获得first node。first()中,局部变量h作为锚点,h每次都从head中取出,p从锚点处向左移动,目的是为了找到first node。
Node<E> first() {
restartFromHead:
for (;;)
for (Node<E> h = head, p = h, q;;) {
//该分支自动左移p,左移后如果p左边还有节点,则进入此分支。
if ((q = p.prev) != null &&
(q = (p = q).prev) != null)
//判断p是左移,还是变成新head
p = (h != (h = head)) ? h : q;
//执行到这里,说明p已经是first node了。
else if (p == h
// 需要保证返回节点在返回时,是队列的head
|| casHead(h, p))
return p;
//casHead失败,进入此分支。
else
continue restartFromHead;
}
}
if ((q = p.prev) != null && (q = (p = q).prev) != null)分支。
| 条件1 | 附带效果 | 条件2 | 附带效果 | 结果 |
|---|---|---|---|---|
p.prev ≠null |
获得了p的前驱q | q.prev≠null |
q和p整体左移 | 左移后,p离first node距离至少为1,进入分支,分支内逻辑为再次移动p |
p.prev ≠null |
获得了p的前驱q | q.prev=null |
q和p整体左移(q为null) | p刚移动到first node了,不进入分支 |
p.prev =null |
获得了p的前驱q(q为null) | 短路不执行 | - | p就是first node时,不进入分支 |
p = (h != (h = head)) ? h : q;的逻辑就是,如果检测到head相比之前取的局部变量h发生了变化,p就赋值为新head(锚点需要更新,所以p也需要归位)。否则,p就是左移一下即可。
-
else if (p == h || casHead(h, p))分支
执行到这里,说明p就是first node了,但此函数需要返回的就是head节点。但此时还要判断是否需要更新head。- 如果p此时等于h,而h就是之前从head取得的,所以不需要更新了,直接返回即可,短路后者条件。
- 如果p此时不等于h,说明p是从锚点h移动过来的,说明之前的head需要更新了,因为它之前取得的时候都不在first node上。此时只有CAS成功了才会返回。
- 也有可能p是个PREV_TERMINATOR,这种情况p已经脱离队列了,而此时的h肯定已经过时不是当前的head了,所以casHead肯定会失败。
-
else分支
进了这个分支,说明p就是first node了,但执行casHead失败了,所以continue外循环,直接重新读取head即可。
简单的说,first()会返回first node,并且保证返回的节点是head(最起码在刚返回时是这样)。
succ()
这个函数方向是右移,自然使用next指针。后继为null都无所谓,但如果发现p是一个PREV_TERMINATOR时,需要重新first()读取first node,然后再从左到右遍历。
PREV_TERMINATOR的next指向自身,succ()遇到这种节点时,不管调用多少次都只能返回它本身了。但实际上不可能有哪个节点的next指向PREV_TERMINATOR,除非这个参数p传进来就是PREV_TERMINATOR。
final Node<E> succ(Node<E> p) {
// TODO: should we skip deleted nodes here?
Node<E> q = p.next;
return (p == q) ? first() : q;
}
unlink()
unlink函数有三种逻辑,我们先看删除队首和队尾的逻辑。这两个逻辑,在经过简单的判断以后,直接调用另外的函数。
void unlink(Node<E> x) {
// assert x != null;
// assert x.item == null;
// assert x != PREV_TERMINATOR;
// assert x != NEXT_TERMINATOR;
final Node<E> prev = x.prev;
final Node<E> next = x.next;
if (prev == null) {
unlinkFirst(x, next);
} else if (next == null) {
unlinkLast(x, prev);
} else {
unlinkFirst
该函数已知first是一个逻辑删除的节点了,但next的情况不知道,所以需要从next开始右移,找到一个没有被删除的节点(live node)或者直到last node。
找到右移遇到的第一个live node后(或者last node):
- 如果发现这个节点不是first参数的直接后继,则需要执行删除步骤的unlinking和gc-unlinking。
- 如果是直接后继,那么不需要后续操作了。
private void unlinkFirst(Node<E> first, Node<E> next) {
// assert first != null;
// assert next != null;
// assert first.item == null;
for (Node<E> o = null, p = next, q;;) {
//1. p的item不为null,是个live node
//2. p的item为null,但p的后继没有。说明p是一个last node了(就是那个dummy node)
//上面两种情况进入分支,说明找到了first参数的新后继了
//
//3. p的item为null,且p的后继q不为null。需要继续寻找
if (p.item != null || (q = p.next) == null) {
//1. 如果o不为null,说明p相对next参数肯定右移过了。否则不需要修改first参数的后继。
//2. 如果p不是一个NEXT_TERMINATOR(通过next链遍历需要判断这个)。否则不需要修改first参数的后继。
//3. 如果CAS修改first参数的后继成功。失败说明,有人代替执行了这步
if (o != null && p.prev != p && first.casNext(next, p)) {
skipDeletedPredecessors(p);//这步是删除的第二步unlinking
if (first.prev == null &&//如果first还是first node
(p.next == null || p.item != null) &&//如果p还是last node,或者还是个live node
p.prev == first) {//如果p的前驱还是first
//进入这个分支,说明first和p都保持着之前的性质,且p和first之间的前驱关系还维持着
updateHead(); // 保证从head出发不可能找到 o,或者第二步unlinking跳过的节点
updateTail(); // 保证从tail出发不可能找到 o,或者第二步unlinking跳过的节点
// 最后,执行删除的第三步gc-unlinking
o.lazySetNext(o);
o.lazySetPrev(prevTerminator());
}
}
return;
}
else if (p == q)//如果p是一个PREV_TERMINATOR
return;
else {
//右移p,并且用o来保存旧p
o = p;
p = q;
}
}
}
skipDeletedPredecessors
该函数的内循环负责找到x左移遇到的第一个live node,或者找到item为null的first node,总之找到的是p局部变量。
该函数的目的是为了跳过x与p之间的逻辑删除节点,如果它俩之间有删除节点,那么将x的前驱改为p,从而跳过中间的删除节点;如果没有的话,就不需要动作了。
需要说的一点是,continue whileActive用来继续外循环(do while)时,会先执行外循环的检查(x.item != null || x.next == null),再执行循环体。
private void skipDeletedPredecessors(Node<E> x) {//传入的x肯定是一个live node
whileActive:
do {
Node<E> prev = x.prev;
// assert prev != null;
// assert x != NEXT_TERMINATOR;
// assert x != PREV_TERMINATOR;
Node<E> p = prev;//左移p
findActive:
for (;;) {
if (p.item != null)//遇到了live node,不需要左移了,把之前遇到的删除节点给unlink了就行
break findActive;//退出内循环
//执行到这里,说明p的item为null,为删除节点
Node<E> q = p.prev;//获得p的前驱
if (q == null) {//如果p的前驱为null
if (p.next == p)//p是一个PREV_TERMINATOR,继续外循环
continue whileActive;
//p是first node,已经找到头了,退出内循环
break findActive;
}
//如果p的前驱不为null,但p的前驱指向自身,说明p是个NEXT_TERMINATOR,继续外循环
else if (p == q)
continue whileActive;
//左移p
else
p = q;
}
//内循环找到了x左移遇到的第一个live node,或者找到item为null的first node,总之找到的是p
//1. 如果p就是x的直接前驱,那就没必要更新x的前驱,直接返回。
//2. 如果不是直接前驱,就需要CAS设置x的前驱为找到的这个first node,如果成功则返回
//
//3. 如果不是直接前驱,且CAS失败,继续外循环
if (prev == p || x.casPrev(prev, p))
return;
} while (x.item != null || x.next == null);//检查x,两种情况继续外循环
//1. x的item不为null 2. x的item虽然为null,但x是last node(这种情况也要使x的前驱跳跃)
//3. x的item为null,且x的后继不为null,此时退出循环。因为会有别的线程来处理。
}
回到unlinkFirst的逻辑,可以发现first.casNext(next, p)和skipDeletedPredecessors(p)相当于一对操作。
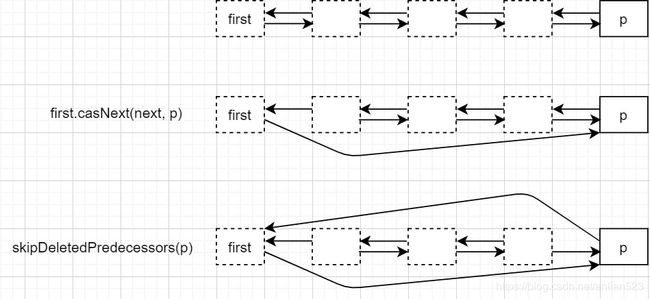
如上图所示,虚线框就代表item为null的逻辑删除节点,执行完上面两步后,从队列上就无法访问到这些中间这些逻辑删除节点了,但这些逻辑删除节点还能通过指针到达队列上来。
注意,图中first也是一个逻辑删除节点(pollFirst()里的p.casItem(item, null)),但它这里是作为dummy node来使用了,它现在被认为是active node的。
这就是删除步骤的第二步unlinking。
updateHead
除非head已经指向first node了,否则该函数就会一直尝试直到head变成first node。
private final void updateHead() {
// 除非head已经指向first node了,否则就会一直尝试直到head变成first node
Node<E> h, p, q;
restartFromHead:
//如果head不是live node,而且head不是first node
while ((h = head).item == null && (p = h.prev) != null) {
for (;;) {
if ((q = p.prev) == null ||//如果p的前驱为null
(q = (p = q).prev) == null) {//如果p左移后前驱为null
//总之进入分支说明p为first node
if (casHead(h, p))//更新head为first node
return;
else//CAS失败说明head被更新,重新读取head
continue restartFromHead;
}
else if (h != head)//发现head更新,重新读取head
continue restartFromHead;
else//左移p
p = q;
}
}
}

执行完此函数后,就不可能再从head出发通过prev链遍历到中间这些删除节点了。
updateTail
实现与updateHead完全对称,不赘述。
gc-unlinking
最终unlinkLast里可能执行这两句:
o.lazySetNext(o);
o.lazySetPrev(prevTerminator());

考虑到unlinkLast的逻辑中,first和p之间可能越过多个逻辑删除节点,所以gc-unlinking后的效果图可能如上图所示。即并不能完全达到这种效果:从中间这些删除节点不能到达队列的active node。
松弛阈值
要想进行unlinking操作,前提是o != null,这意味着局部变量p相对于next参数肯定右移了。next参数就是first参数的后继。
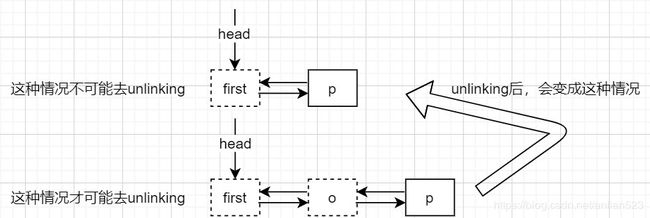
从上图第二行可以看出,当first和p之间的距离至少为2时,unlinkFirst函数才可能去执行unlinking步骤。
即使first端的第一个节点是个live node,但是在连续的pollFirst的执行下,只有第一个pollFirst动作是执行的unlinkFirst(x, next),之后的pollFirst动作由于first端总是存在一个非live node,所以它们在unlink里执行的其实是common case(删除内部节点)。
unlink的Unlink interior node逻辑
else分支才是通常的case。进入这个分支说明x既有前驱也有后继的。
- 首先找到x的live前驱(如果没有live前驱,那么找到非live的端节点也行),作为activePred;activeSucc同理。
- 在一定情况下执行activePred与activeSucc之间的unlinking操作。一定情况是指:
- x原本是一个内部的live node(即x前后都有live node)
- x原本不是一个内部的live node,但找到activePred或activeSucc的途中遇到了过多的逻辑删除节点。
- 执行unlinking操作后,还可能执行gc-unlink操作。当x不是一个内部的live node时。
void unlink(Node<E> x) {
// assert x != null;
// assert x.item == null;
// assert x != PREV_TERMINATOR;
// assert x != NEXT_TERMINATOR;
final Node<E> prev = x.prev;
final Node<E> next = x.next;
if (prev == null) {
unlinkFirst(x, next);
} else if (next == null) {
unlinkLast(x, prev);
} else {
Node<E> activePred, activeSucc;//优先寻找live node,或者直到两端节点
boolean isFirst, isLast;//代表x原本是左起第一个live node;代表x原本是右起第一个live node
int hops = 1;
// Find active predecessor
for (Node<E> p = prev; ; ++hops) {
if (p.item != null) {//找到了live的前驱
activePred = p;
isFirst = false;//那么x原来不是第一个live node,所以为false
break;
}
//执行到这里,说明p的item为null
Node<E> q = p.prev;
if (q == null) {//如果p是first node
if (p.next == p)
return;
activePred = p;
isFirst = true;//那么x原来是第一个live node了,所以为true
break;
}
else if (p == q)//如果在prev链上遇到了一个NEXT_TERMINATOR,这其实不可能
return;
else//左移p
p = q;
}
// Find active successor
for (Node<E> p = next; ; ++hops) {
if (p.item != null) {
activeSucc = p;
isLast = false;
break;
}
Node<E> q = p.next;
if (q == null) {
if (p.prev == p)
return;
activeSucc = p;
isLast = true;
break;
}
else if (p == q)
return;
else
p = q;
}
// 1.hops变量小于,且x原来是第一个或最后一个live node
if (hops < HOPS// HOPS是一种启发式的检测
// 总是会弹出内部删除节点
&& (isFirst | isLast))
return;
// 2.如果x原来既不是第一个也不是最后一个live node,那么总是会执行到这里
// 3.如果x原来是第一个或最后一个live node,但x与activePred或activeSucc之间的逻辑删除节点太多,
// 也会执行到这里
// 总是会执行activePred和activeSucc之间的unlinking操作
skipDeletedSuccessors(activePred);
skipDeletedPredecessors(activeSucc);
// 只有当x是第一个或最后一个live node(这说明x与activePred或activeSucc之间的逻辑删除节点太多)
if ((isFirst | isLast) &&
// 重新检查前驱和后继之间的关系
(activePred.next == activeSucc) &&
(activeSucc.prev == activePred) &&
(isFirst ? activePred.prev == null : activePred.item != null) &&
(isLast ? activeSucc.next == null : activeSucc.item != null)) {
updateHead(); // Ensure x is not reachable from head
updateTail(); // Ensure x is not reachable from tail
// Finally, actually gc-unlink
x.lazySetPrev(isFirst ? prevTerminator() : x);
x.lazySetNext(isLast ? nextTerminator() : x);
}
}
}
- x参数的原本是live node的,但是调用此函数之前将其item设置为了null,所以x原来是live node。
isFirst变量为true代表x原本是左起第一个live node;为false,则代表x原本不是左起第一个live node。isLast同理。 - 两个for循环用来找到activePred和activeSucc,并设置isFirst和isLast。
if (hops < HOPS && (isFirst | isLast)) return;则是一种松弛阈值的表现,但如果x原本是一个内部的live node节点,则一定不会return,进而去执行unlinking操作。因为内部的逻辑删除节点需要及时被删除掉。
peekFirst 仅获取
peek、peekFirst 、peekLast、getFirst、getLast方法都是依赖于peekFirst 、peekLast的。peek也是默认调用的first版本。
public E peekFirst() {
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null)
return item;
}
return null;
}
public E peekLast() {
for (Node<E> p = last(); p != null; p = pred(p)) {
E item = p.item;
if (item != null)
return item;
}
return null;
}
代码和pollFirst几乎一模一样,只是除去了删除的三个步骤,所以简单了很多。
remove 删除操作
remove是默认从first端进行删除的。
public boolean remove(Object o) {
return removeFirstOccurrence(o);
}
removeFirstOccurrence的实现跟pollFirst差不多,只是置item域为null的前提条件不同罢了。
public boolean removeFirstOccurrence(Object o) {
checkNotNull(o);
for (Node<E> p = first(); p != null; p = succ(p)) {
E item = p.item;
if (item != null && o.equals(item) && p.casItem(item, null)) {
unlink(p);
return true;
}
}
return false;
}
size
- 该函数返回的大小可能不准确,只有弱一致性。
- 该函数需要遍历一遍队列,效率低下。
public int size() {
int count = 0;
for (Node<E> p = first(); p != null; p = succ(p))
if (p.item != null)
// Collection.size() spec says to max out
if (++count == Integer.MAX_VALUE)
break;
return count;
}
迭代器
分为正向迭代器和反向迭代器,毕竟咱们是一个双端队列。
同样,这个迭代器也是弱一致性的,因为放到nextNode的节点,即使之后从队列中被删除(节点的item会变成null),nextItem也会继续维持引用,然后调用next()依旧能返回这个item。
private abstract class AbstractItr implements Iterator<E> {
//下一个返回的节点。即使节点放到nextNode后马上被删除,也会返回这个节点
private Node<E> nextNode;
//nextNode的item域
private E nextItem;
//上一个返回过的节点,用来支持删除操作
private Node<E> lastRet;
abstract Node<E> startNode();//获得first或last
abstract Node<E> nextNode(Node<E> p);//前进方向为prev或next
AbstractItr() {
advance();
}
private void advance() {
lastRet = nextNode;//nextNode的item即将返回,所以把nextNode放到lastRet
//迭代器初始化时才会调用startNode()
Node<E> p = (nextNode == null) ? startNode() : nextNode(nextNode);
for (;; p = nextNode(p)) {
if (p == null) {//前进方向已经到头了
// p might be active end or TERMINATOR node; both are OK
nextNode = null;
nextItem = null;
//这个迭代器之后不能再前进了,已经废了
break;
}
E item = p.item;
if (item != null) {//找到了下一个,先存起来
nextNode = p;
nextItem = item;
break;
}
}
}
public boolean hasNext() {
return nextItem != null;
}
public E next() {
E item = nextItem;
if (item == null) throw new NoSuchElementException();
advance();
return item;
}
public void remove() {
Node<E> l = lastRet;
if (l == null) throw new IllegalStateException();
l.item = null;
unlink(l);
lastRet = null;
}
}
/** Forward iterator */
private class Itr extends AbstractItr {
Node<E> startNode() { return first(); }
Node<E> nextNode(Node<E> p) { return succ(p); }
}
总结
- 队列的两端都可以进行插入和删除操作,另外ConcurrentLinkedDueue还可以作为栈使用。
- 完全的非阻塞算法(lock free),大量使用了CAS和自旋。
- 通过两种方法最小化volatile写的次数:
- 允许head或tail偏离first node或last node。
- 对同一块内存区域使用 volatile写 和 非volatile写 两种方式结合使用。比如
lazySetNext和casNext结合使用、UNSAFE.putObject(this, itemOffset, item)和casItem的结合使用。
- 对节点的删除有三个步骤:logical deletion、unlinking、gc-unlinking。第三步可以不做,只是为了GC健壮性的保证。