回归算法 逻辑斯谛回归(LR算法)
回归算法 LR算法
二分类(Logistic Regression 逻辑斯谛回归 简称LR):model -> 0/1
多分类(Softmax):model -> 0/1/2…
一、Sigmoid函数——逻辑回归的实现
1.
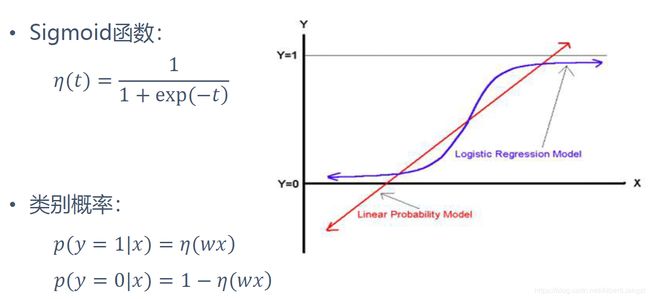
2.用sigmoid原因:
- 简单来讲,可以将(-∞, +∞)的输入变量映射到(0,1),作为后验概率
- 在某个临界点左右两端变化较大,比较容易进行分类
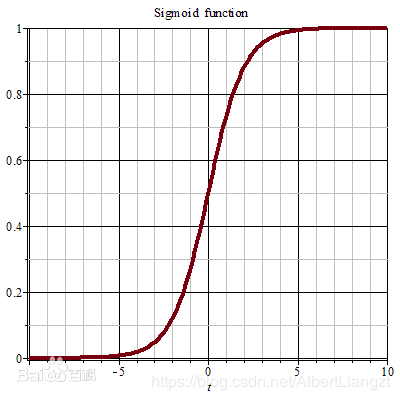
二、基本公式推导
1.对sigmoid求w偏导:
η ( t ) = 1 1 + e − t \eta(t)=\frac{1}{1+e^{-t}} η(t)=1+e−t1 转换为 η ( w x ) = 1 1 + e − w x \eta(wx)=\frac{1}{1+e^{-wx}} η(wx)=1+e−wx1
偏导为 ∂ ( η ) ∂ ( w ) \frac{\partial(\eta)}{\partial(w)} ∂(w)∂(η) $=\frac{(-1)}{(1+e{-wx}){2}} (-x)(e^{-wx}) $
= 1 1 + e − w x ∗ e − w x 1 + e − w x ∗ x =\frac{1}{1+e^{-wx}} * \frac{e^{-wx}}{1+e^{-wx}} * x =1+e−wx1∗1+e−wxe−wx∗x
= 1 1 + e − w x ∗ 1 + e − w x − 1 1 + e − w x ∗ x =\frac{1}{1+e^{-wx}} * \frac{1+e^{-wx}-1}{1+e^{-wx}} * x =1+e−wx1∗1+e−wx1+e−wx−1∗x
= 1 1 + e − w x ∗ ( 1 − 1 1 + e − w x ) ∗ x =\frac{1}{1+e^{-wx}} * (1 - \frac{1}{1+e^{-wx}}) * x =1+e−wx1∗(1−1+e−wx1)∗x
= η ∗ ( 1 − η ) ∗ x =\eta * (1-\eta) * x =η∗(1−η)∗x
2.对损失函数 L ( w ) L(w) L(w)求导(梯度):
2.1类别概率
p ( y i = 1 ∣ x ) = η p(y_{i}=1|x)=\eta p(yi=1∣x)=η
p ( y i = 0 ∣ x ) = 1 − η p(y_{i}=0|x)=1-\eta p(yi=0∣x)=1−η
2.2似然函数
L ( w ) = ∏ i p ( y i ) L(w)=\prod\limits_{i}p(y_{i}) L(w)=i∏p(yi)
= ∏ i ( I ( y i = 1 ) p ( y i = 1 ∣ x i , w ) ) ∗ I ( y i = 0 ) p ( ( y i = 0 ) ∣ x i , w ) ) =\prod\limits_{i}(I(y_{i}=1)p(y_{i}=1|x_{i},w)) * I(y_{i}=0)p((y_{i}=0)|x_{i},w)) =i∏(I(yi=1)p(yi=1∣xi,w))∗I(yi=0)p((yi=0)∣xi,w))
= ∏ i y i η ∗ ( 1 − y i ) ( 1 − η ) =\prod\limits_{i}y_{i}\eta * (1-y_{i})(1-\eta) =i∏yiη∗(1−yi)(1−η)
2.3负对数似然
l o g ( L ( w ) ) = − l o g ( ∏ i y i η ∗ ( 1 − y i ) ( 1 − η ) ) log(L(w))=-log(\prod\limits_{i}y_{i}\eta * (1-y_{i})(1-\eta)) log(L(w))=−log(i∏yiη∗(1−yi)(1−η))
l o g ( L ( w ) ) = − ∑ i ( y i l o g ( η ) + ( 1 − y i ) l o g ( ( 1 − η ) ) log(L(w))=-\sum\limits_{i}(y_{i}log(\eta)+(1-y_{i})log((1-\eta)) log(L(w))=−i∑(yilog(η)+(1−yi)log((1−η))
也写作
L ( w ) = − ∑ i ( I ( y i = 1 ) l o g ( p ( y i = 1 ∣ x i , w ) ) ) + I ( y i = 0 ) l o g ( p ( ( y i = 0 ) ∣ x i , w ) ) ) L(w)=-\sum\limits_{i}(I(y_{i}=1)log(p(y_{i}=1|x_{i},w))) + I(y_{i}=0)log(p((y_{i}=0)|x_{i},w))) L(w)=−i∑(I(yi=1)log(p(yi=1∣xi,w)))+I(yi=0)log(p((yi=0)∣xi,w)))
= − ∑ i ( I ( y i = 1 ) l o g ( η ( w x i ) ) + I ( y i = 0 ) l o g ( 1 − η ( w x i ) ) ) =-\sum\limits_{i}(I(y_{i}=1)log(\eta(wx_{i})) + I(y_{i}=0)log(1-\eta(wx_{i}))) =−i∑(I(yi=1)log(η(wxi))+I(yi=0)log(1−η(wxi)))
2.4所以负对数似然求偏导
δ ( L ( w ) ) = − ∑ ( y i η η ( 1 − η ) x i − 1 − y i 1 − η η ( 1 − η ) x i ) \delta(L(w))=-\sum(\frac{y_{i}}{\eta}\eta(1-\eta)x_{i} - \frac{1-y_{i}}{1-\eta}\eta(1-\eta)x_{i}) δ(L(w))=−∑(ηyiη(1−η)xi−1−η1−yiη(1−η)xi)
= − ∑ ( y i ( 1 − η ) x i + ( 1 − y i ) η x i ) =-\sum(y_{i}(1-\eta)x_{i}+(1-y_{i})\eta x_{i}) =−∑(yi(1−η)xi+(1−yi)ηxi)
= − ∑ ( y i x i − y i η x i − η x i + y i η x i ) =-\sum(y_{i}x_{i}-y_{i}\eta x_{i}-\eta x_{i}+y_{i}\eta x_{i}) =−∑(yixi−yiηxi−ηxi+yiηxi)
= − ∑ ( y i − η ) x i =-\sum(y_{i}-\eta) x_{i} =−∑(yi−η)xi
所以梯度为: ∇ ( L ( w ) ) = − ∑ ( y i − η ) x i \nabla(L(w))=-\sum(y_{i}-\eta) x_{i} ∇(L(w))=−∑(yi−η)xi
三、举例:到达谷底的最佳路线
梯度
梯度方向——让f(x,y)函数快速变大的方向
反梯度方向——让f(x,y)函数快速变小的方向
方法:梯度下降法——最小化F(w)
- 1.设置初始w,计算出F(w)
- 2.计算梯度 ∇ \nabla ∇:下降方向dir=(- ∇ \nabla ∇F(w))
- 3.尝试梯度更新: w n e w = w + 步 长 ∗ d i r w^{new} = w + 步长*dir wnew=w+步长∗dir
得到下降后的 w n e w w^{new} wnew和F( w n e w w^{new} wnew) - 4.如果F( w n e w w^{new} wnew)-F(w)较小:说明基本处于底部,模型稳定,可以停止
否则w= w n e w w^{new} wnew, F( w n e w w^{new} wnew)=F(w)
实现
误差=真实值-预测值=(yi - η ( w x i ) \eta(wx_{i}) η(wxi))
errors = target - prediction
prediction = sigmoid(wx)=(wx)
wx = weight * x + b
w 1 w_{1} w1:随机初始化 => f(x):预测值
python实现
git地址