编译hbase-sink
文章目录
- 准备环境
- 安装git
- 安装maven
- 修改代码
- fork到自己的github下
- 使用git push到本地
- 修改代码
- maven 编译
- 启动hbase-sink
- 上传jar包到服务器
- sink properties
- 启动sink
- 用 avro console测试
- 数据库查询
- 实践中遇到的问题
- 启动sink报错
- 排查问题
- avro console发送消息报错
- 排查问题
- hbase-sink处理消息报错
- kafka-avro-console-producer VALUE_NULL
- 参考资料
准备环境
- linux系统CentOS 7
安装git
su - root
yum install git-core
git clone https://github.com/thbzh/kafka-connect-hbase.git
安装maven
- 如果没有安装wget,安装wget
yum -y install wget
- 用wget下载maven(其它方式下载也行)
wget http://mirror.bit.edu.cn/apache/maven/maven-3/3.6.0/binaries/apache-maven-3.6.0-bin.tar.gz
- 安装
tar -xvzf apache-maven-3.6.0-bin.tar.gz
mkdir /usr/local/maven
mv apache-maven-3.6.0 /usr/local/maven
- 配置环境变量
vi /etc/profile
添加如下
## MAVEN CONFIG ##
export MAVEN_HOME=/usr/local/maven/apache-maven-3.6.0
export PATH=$MAVEN_HOME/bin:$PATH
- 验证
$mvn -v
Apache Maven 3.6.0 (1edded0938998edf8bf061f1ceb3cfdeccf443fe; 2018-06-18T02:33:14+08:00)
Maven home: /home/crm_core_account/.apache-maven-3.5.4
Java version: 1.8.0_121, vendor: Oracle Corporation, runtime: /software/servers/jdk1.8.0_121/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-327.28.3.el7.x86_64", arch: "amd64", family: "unix"
修改代码
fork到自己的github下
hbase-sink github地址:https://github.com/nishutayal/kafka-connect-hbase
注: 如果不想管理代码,可以不用fork
使用git push到本地
git clone https://github.com/nishutayal/kafka-connect-hbase.git
修改代码
可以fork代码到自己properties中,git clone到windows系统,用idea编译,在git pull的项目中。编译时,从自己的repositories中git clone。
修改代码AvroEventParser如下:
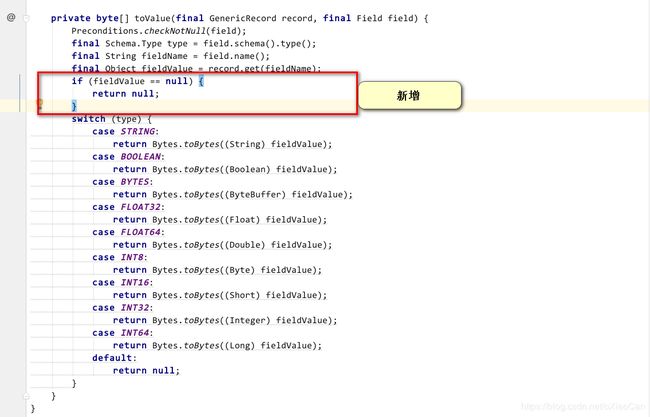
maven 编译
mvn package -Dmaven.test.skip=true
注:hbase-sink如果package不通过,可以跳过测试部分。
编译完后,target下会有两个jar包,如下:
kafka-connect-hbase-1.0.1.jar // 带依赖
hbase-sink.jar // 不带依赖
启动hbase-sink
上传jar包到服务器
- 将kafka-connect-hbase-1.0.1.jar上传到服务器上
目录为/home/kafka/confluent-5.1.2/share/java/kafka-connect-hbase - 将hbase-site.xml打到jar包中
jar -uvf kafka-connect-hbase-1.0.1.jar hbase-site.xml
sink properties
$CONFLUENT_HOME/etc/kafka-connect-hbase/hbase-sink.properties
connector.class=io.svectors.hbase.sink.HBaseSinkConnector
tasks.max=1
topics=test
zookeeper.quorum=bigdata1:2181
event.parser.class=io.svectors.hbase.parser.AvroEventParser
hbase.table.name=kafka_test
hbase.kafka_test.rowkey.columns=a
hbase.kafka_test.rowkey.delimiter=|
hbase.kafka_test.family=cf
启动sink
$CONFLUENT_HOME/bin/connect-standalone $CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties $CONFLUENT_HOME/etc/kafka-connect-hbase/hbase-sink.properties
用 avro console测试
bin/kafka-avro-console-producer --broker-list appserver5:9092 --topic test --property value.schema='{"type":"record","name":"record","fields":[{"name":"id","type":"int"}, {"name":"name", "type": "string"}]}'
#insert at prompt
{"id": 10, "name": "foo"}
{"id": 20, "name": "bar"}
{"id": 30, "name": "xiaocan"}
数据库查询
hbase shell
list
scan ‘kafka_test’
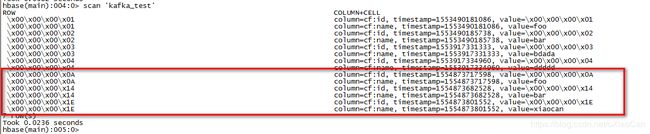
实践中遇到的问题
启动sink报错
$CONFLUENT_HOME/bin/connect-standalone $CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties $CONFLUENT_HOME/etc/kafka-connect-hbase/hbase-sink.properties
报错如下:
[2019-04-06 17:29:37,164] INFO Kafka Connect standalone worker initialization took 3796ms (org.apache.kafka.connect.cli.ConnectStandalone:96)
[2019-04-06 17:29:37,164] INFO Kafka Connect starting (org.apache.kafka.connect.runtime.Connect:50)
[2019-04-06 17:29:37,164] INFO Herder starting (org.apache.kafka.connect.runtime.standalone.StandaloneHerder:87)
[2019-04-06 17:29:37,164] INFO Worker starting (org.apache.kafka.connect.runtime.Worker:172)
[2019-04-06 17:29:37,164] INFO Starting FileOffsetBackingStore with file /tmp/connect.offsets (org.apache.kafka.connect.storage.FileOffsetBackingStore:58)
[2019-04-06 17:29:37,166] INFO Worker started (org.apache.kafka.connect.runtime.Worker:177)
[2019-04-06 17:29:37,166] INFO Herder started (org.apache.kafka.connect.runtime.standalone.StandaloneHerder:89)
[2019-04-06 17:29:37,166] INFO Kafka Connect started (org.apache.kafka.connect.runtime.Connect:55)
[2019-04-06 17:29:37,168] ERROR Failed to create job for /home/kafka/confluent-5.1.2/etc/kafka-connect-hbase/hbase-sink.properties (org.apache.kafka.connect.cli.ConnectStandalone:108)
[2019-04-06 17:29:37,168] ERROR Stopping after connector error (org.apache.kafka.connect.cli.ConnectStandalone:119)
java.util.concurrent.ExecutionException: org.apache.kafka.connect.errors.ConnectException: Failed to find any class that implements Connector and which name matches io.svectors.hbase.sink.HBaseSinkConnector, available connectors are: PluginDesc{klass=class org.apache.kafka.connect.file.FileStreamSinkConnector, name='org.apache.kafka.connect.file.FileStreamSinkConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=sink, typeName='sink', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.file.FileStreamSourceConnector, name='org.apache.kafka.connect.file.FileStreamSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.MockConnector, name='org.apache.kafka.connect.tools.MockConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=connector, typeName='connector', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.MockSinkConnector, name='org.apache.kafka.connect.tools.MockSinkConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=sink, typeName='sink', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.MockSourceConnector, name='org.apache.kafka.connect.tools.MockSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.SchemaSourceConnector, name='org.apache.kafka.connect.tools.SchemaSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.VerifiableSinkConnector, name='org.apache.kafka.connect.tools.VerifiableSinkConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.VerifiableSourceConnector, name='org.apache.kafka.connect.tools.VerifiableSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}
at org.apache.kafka.connect.util.ConvertingFutureCallback.result(ConvertingFutureCallback.java:79)
at org.apache.kafka.connect.util.ConvertingFutureCallback.get(ConvertingFutureCallback.java:66)
at org.apache.kafka.connect.cli.ConnectStandalone.main(ConnectStandalone.java:116)
Caused by: org.apache.kafka.connect.errors.ConnectException: Failed to find any class that implements Connector and which name matches io.svectors.hbase.sink.HBaseSinkConnector, available connectors are: PluginDesc{klass=class org.apache.kafka.connect.file.FileStreamSinkConnector, name='org.apache.kafka.connect.file.FileStreamSinkConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=sink, typeName='sink', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.file.FileStreamSourceConnector, name='org.apache.kafka.connect.file.FileStreamSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.MockConnector, name='org.apache.kafka.connect.tools.MockConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=connector, typeName='connector', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.MockSinkConnector, name='org.apache.kafka.connect.tools.MockSinkConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=sink, typeName='sink', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.MockSourceConnector, name='org.apache.kafka.connect.tools.MockSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.SchemaSourceConnector, name='org.apache.kafka.connect.tools.SchemaSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.VerifiableSinkConnector, name='org.apache.kafka.connect.tools.VerifiableSinkConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}, PluginDesc{klass=class org.apache.kafka.connect.tools.VerifiableSourceConnector, name='org.apache.kafka.connect.tools.VerifiableSourceConnector', version='2.1.1-cp1', encodedVersion=2.1.1-cp1, type=source, typeName='source', location='classpath'}
at org.apache.kafka.connect.runtime.isolation.Plugins.newConnector(Plugins.java:179)
at org.apache.kafka.connect.runtime.AbstractHerder.getConnector(AbstractHerder.java:382)
at org.apache.kafka.connect.runtime.AbstractHerder.validateConnectorConfig(AbstractHerder.java:261)
at org.apache.kafka.connect.runtime.standalone.StandaloneHerder.putConnectorConfig(StandaloneHerder.java:188)
at org.apache.kafka.connect.cli.ConnectStandalone.main(ConnectStandalone.java:113)
[2019-04-06 17:29:37,170] INFO Kafka Connect stopping (org.apache.kafka.connect.runtime.Connect:65)
[2019-04-06 17:29:37,170] INFO Stopping REST server (org.apache.kafka.connect.runtime.rest.RestServer:226)
[2019-04-06 17:29:37,175] INFO Stopped http_9083@3506d826{HTTP/1.1,[http/1.1]}{0.0.0.0:9083} (org.eclipse.jetty.server.AbstractConnector:341)
[2019-04-06 17:29:37,176] INFO node0 Stopped scavenging (org.eclipse.jetty.server.session:167)
[2019-04-06 17:29:37,183] INFO Stopped o.e.j.s.ServletContextHandler@6de0f580{/,null,UNAVAILABLE} (org.eclipse.jetty.server.handler.ContextHandler:1040)
[2019-04-06 17:29:37,184] INFO REST server stopped (org.apache.kafka.connect.runtime.rest.RestServer:244)
[2019-04-06 17:29:37,184] INFO Herder stopping (org.apache.kafka.connect.runtime.standalone.StandaloneHerder:94)
[2019-04-06 17:29:37,184] INFO Worker stopping (org.apache.kafka.connect.runtime.Worker:184)
[2019-04-06 17:29:37,185] INFO Stopped FileOffsetBackingStore (org.apache.kafka.connect.storage.FileOffsetBackingStore:66)
[2019-04-06 17:29:37,185] INFO Worker stopped (org.apache.kafka.connect.runtime.Worker:205)
[2019-04-06 17:29:37,186] INFO Herder stopped (org.apache.kafka.connect.runtime.standalone.StandaloneHerder:111)
[2019-04-06 17:29:37,186] INFO Kafka Connect stopped (org.apache.kafka.connect.runtime.Connect:70)
排查问题
-
参考资料
https://stackoverflow.com/questions/53412622/kafka-connect-cant-find-connector
https://github.com/DataReply/kafka-connect-mongodb/issues/23 -
查看配置
etc/schema-registry/connect-avro-standalone.properties

【分析】:share/java为相对路径,当不在CONFLUENT_HOME启动时,是读不到此文件夹的
- 修改配置
plugin.path=/home/kafka/confluent-5.1.2/share/java
- 再次启动成功
命令见上面
avro console发送消息报错
bin/kafka-avro-console-producer --broker-list appserver5:9092 --topic test --property value.schema='{"type":"record","name":"record","fields":[{"name":"id","type":"int"}, {"name":"name", "type": "string"}]}'
#insert at prompt
{"id": 10, "name": "foo"}
{"id": 30, "name": "xiaocan"}
报错如下
org.apache.kafka.common.errors.SerializationException: Error serializing Avro message
Caused by: com.fasterxml.jackson.core.JsonParseException: Unexpected character ('<' (code 60)): expected a valid value (number, String, array, object, 'true', 'false' or 'null')
at [Source: (sun.net.www.protocol.http.HttpURLConnection$HttpInputStream); line: 1, column: 2]
at com.fasterxml.jackson.core.JsonParser._constructError(JsonParser.java:1804)
at com.fasterxml.jackson.core.base.ParserMinimalBase._reportError(ParserMinimalBase.java:669)
at com.fasterxml.jackson.core.base.ParserMinimalBase._reportUnexpectedChar(ParserMinimalBase.java:567)
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser._handleUnexpectedValue(UTF8StreamJsonParser.java:2624)
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser._nextTokenNotInObject(UTF8StreamJsonParser.java:826)
at com.fasterxml.jackson.core.json.UTF8StreamJsonParser.nextToken(UTF8StreamJsonParser.java:723)
at com.fasterxml.jackson.databind.ObjectMapper._initForReading(ObjectMapper.java:4141)
at com.fasterxml.jackson.databind.ObjectMapper._readMapAndClose(ObjectMapper.java:4000)
at com.fasterxml.jackson.databind.ObjectMapper.readValue(ObjectMapper.java:3077)
at io.confluent.kafka.schemaregistry.client.rest.RestService.sendHttpRequest(RestService.java:194)
at io.confluent.kafka.schemaregistry.client.rest.RestService.httpRequest(RestService.java:235)
at io.confluent.kafka.schemaregistry.client.rest.RestService.registerSchema(RestService.java:326)
at io.confluent.kafka.schemaregistry.client.rest.RestService.registerSchema(RestService.java:318)
at io.confluent.kafka.schemaregistry.client.rest.RestService.registerSchema(RestService.java:313)
at io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient.registerAndGetId(CachedSchemaRegistryClient.java:118)
at io.confluent.kafka.schemaregistry.client.CachedSchemaRegistryClient.register(CachedSchemaRegistryClient.java:155)
at io.confluent.kafka.serializers.AbstractKafkaAvroSerializer.serializeImpl(AbstractKafkaAvroSerializer.java:79)
at io.confluent.kafka.formatter.AvroMessageReader.readMessage(AvroMessageReader.java:181)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:54)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
排查问题
https://github.com/Landoop/stream-reactor/issues/148
初步断定是之前修改端口号,导致连接不到服务
- 之前9021和8081对换过端口号
修改配置$CONFLUENT_HOME/etc/schema-registry/connect-avro-standalone.properties
key.converter.schema.registry.url=http://appserver5:8081 => key.converter.schema.registry.url=http://appserver5:9021
value.converter.schema.registry.url=http://appserver5:8081 => value.converter.schema.registry.url=http://appserver5:9021
【结论】问题没有解决
- 验证schema-registry
curl http://appserver5:9021
【注】schema-registry默认端口号为8081,和端口9021对调
【结论】服务正常
- 显示指定chema.registry.url
bin/kafka-avro-console-producer --broker-list appserver5:9092 --topic test --property value.schema='{"type":"record","name":"record","fields":[{"name":"id","type":"int"}, {"name":"name", "type": "string"}]}' --property schema.registry.url=http://appserver5:9021
【结论】发送消息正常,问题解决
hbase-sink处理消息报错
java.lang.NullPointerException
at org.apache.hadoop.hbase.client.Put.(Put.java:68)
at org.apache.hadoop.hbase.client.Put.(Put.java:58)
at io.svectors.hbase.util.ToPutFunction.apply(ToPutFunction.java:73)
at io.svectors.hbase.sink.HBaseSinkTask.lambda$null$0(HBaseSinkTask.java:76)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at io.svectors.hbase.sink.HBaseSinkTask.lambda$put$1(HBaseSinkTask.java:76)
at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1321)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.HashMap$EntrySpliterator.forEachRemaining(HashMap.java:1699)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at io.svectors.hbase.sink.HBaseSinkTask.put(HBaseSinkTask.java:75)
at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:565)
at org.apache.kafka.connect.runtime.WorkerSinkTask.poll(WorkerSinkTask.java:323)
at org.apache.kafka.connect.runtime.WorkerSinkTask.iteration(WorkerSinkTask.java:226)
at org.apache.kafka.connect.runtime.WorkerSinkTask.execute(WorkerSinkTask.java:194)
at org.apache.kafka.connect.runtime.WorkerTask.doRun(WorkerTask.java:175)
at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:219)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
[2019-04-10 12:59:41,799] ERROR WorkerSinkTask{id=kafka-cdc-hbase-0} Task threw an uncaught and unrecoverable exception (org.apache.kafka.connect.runtime.WorkerTask:177)
org.apache.kafka.connect.errors.ConnectException: Exiting WorkerSinkTask due to unrecoverable exception.
at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:587)
at org.apache.kafka.connect.runtime.WorkerSinkTask.poll(WorkerSinkTask.java:323)
at org.apache.kafka.connect.runtime.WorkerSinkTask.iteration(WorkerSinkTask.java:226)
at org.apache.kafka.connect.runtime.WorkerSinkTask.execute(WorkerSinkTask.java:194)
at org.apache.kafka.connect.runtime.WorkerTask.doRun(WorkerTask.java:175)
at org.apache.kafka.connect.runtime.WorkerTask.run(WorkerTask.java:219)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NullPointerException
at org.apache.hadoop.hbase.client.Put.(Put.java:68)
at org.apache.hadoop.hbase.client.Put.(Put.java:58)
at io.svectors.hbase.util.ToPutFunction.apply(ToPutFunction.java:73)
at io.svectors.hbase.sink.HBaseSinkTask.lambda$null$0(HBaseSinkTask.java:76)
at java.util.stream.ReferencePipeline$3$1.accept(ReferencePipeline.java:193)
at java.util.ArrayList$ArrayListSpliterator.forEachRemaining(ArrayList.java:1382)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at io.svectors.hbase.sink.HBaseSinkTask.lambda$put$1(HBaseSinkTask.java:76)
at java.util.stream.Collectors.lambda$toMap$58(Collectors.java:1321)
at java.util.stream.ReduceOps$3ReducingSink.accept(ReduceOps.java:169)
at java.util.HashMap$EntrySpliterator.forEachRemaining(HashMap.java:1699)
at java.util.stream.AbstractPipeline.copyInto(AbstractPipeline.java:481)
at java.util.stream.AbstractPipeline.wrapAndCopyInto(AbstractPipeline.java:471)
at java.util.stream.ReduceOps$ReduceOp.evaluateSequential(ReduceOps.java:708)
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:234)
at java.util.stream.ReferencePipeline.collect(ReferencePipeline.java:499)
at io.svectors.hbase.sink.HBaseSinkTask.put(HBaseSinkTask.java:75)
at org.apache.kafka.connect.runtime.WorkerSinkTask.deliverMessages(WorkerSinkTask.java:565)
... 10 more
- 根据exception查看源码,发现rowkey是null

- 查看配置文件

【结论】配置文件rowkey字段配置错误
kafka-avro-console-producer VALUE_NULL
bin/kafka-avro-console-producer --broker-list appserver5:9092 --topic test --property value.schema='{"type":"record","name":"record","fields":[{"name":"id","type":"int"}, {"name":"name", "type": "string"}]}'
{"id": 40, "name": null}
报错如下:
org.apache.kafka.common.errors.SerializationException: Error deserializing json {"id": 40, "name": null} to Avro of schema {"type":"record","name":"record","fields":[{"name":"id","type":"int"},{"name":"name","type":"string"}]}
Caused by: org.apache.avro.AvroTypeException: Expected string. Got VALUE_NULL
at org.apache.avro.io.JsonDecoder.error(JsonDecoder.java:698)
at org.apache.avro.io.JsonDecoder.readString(JsonDecoder.java:227)
at org.apache.avro.io.JsonDecoder.readString(JsonDecoder.java:214)
at org.apache.avro.io.ResolvingDecoder.readString(ResolvingDecoder.java:201)
at org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:430)
at org.apache.avro.generic.GenericDatumReader.readString(GenericDatumReader.java:422)
at org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:180)
at org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:152)
at org.apache.avro.generic.GenericDatumReader.readField(GenericDatumReader.java:240)
at org.apache.avro.generic.GenericDatumReader.readRecord(GenericDatumReader.java:230)
at org.apache.avro.generic.GenericDatumReader.readWithoutConversion(GenericDatumReader.java:174)
at org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:152)
at org.apache.avro.generic.GenericDatumReader.read(GenericDatumReader.java:144)
at io.confluent.kafka.formatter.AvroMessageReader.jsonToAvro(AvroMessageReader.java:213)
at io.confluent.kafka.formatter.AvroMessageReader.readMessage(AvroMessageReader.java:180)
at kafka.tools.ConsoleProducer$.main(ConsoleProducer.scala:54)
at kafka.tools.ConsoleProducer.main(ConsoleProducer.scala)
【结论】通过mysql binlog测试null值效果
参考资料
- Linux 环境下安装Maven https://www.cnblogs.com/jimmy-muyuan/p/7895933.html
- Maven常用命令 https://www.cnblogs.com/wkrbky/p/6352188.html
- Git 提交代码和更新代码 https://blog.csdn.net/Snow_loveLife/article/details/80519998
- kafka avro producer console exceptions https://github.com/Landoop/stream-reactor/issues/148
- Kafka Connect can’t find connector https://stackoverflow.com/questions/53412622/kafka-connect-cant-find-connector
- Failed to find any class that implements Connector https://github.com/DataReply/kafka-connect-mongodb/issues/23