摘要
我们介绍了一种新的对象检测方法名为YOLO。在进行目标检测前,要进行分类来进行检测。相反,我们将对象检测框架变为空间分离的边界框和相关类别概率的回归问题。单个神经网络在一次评估中可以直接从完整的图像中预测边框和所属类别的概率。由于整个检测管道是单个神经网络,所以可以直接对检测性能进行端到端的优化。
我们的这种统一框架非常快。我们的基础YOLO模型以每秒45帧的速度处理实时图像。该网络的一个小版本,名为Fast YOLO,每秒处理的速度达到惊人的155帧,同时还能达到其它实时探测器的两倍。在和最先进的检测系统对比时,YOLO出现了较多的定位错误,但在背景上预测正像时出现的错误较少。最终,YOLO学习到了目标非常一般化的表示方法。当从自然图像推广到其他领域时它比其它检测方法表现更好。
引言
人类看一眼图像就知道图像中有什么,它们在图像中的什么位置,以及它们是如何相互联系的。当前的检测系统将分类器重新应用于目标检测。为了检测对象,这些检测系统在目标上使用了一个分类器,并在测试图像的不同位置和不同尺度上进行评估。诸如DPM(deformable parts models)这样的系统使用了一个滑动窗口,使得分类器等间隔地应用在了整个图像上。
最近的一些方法,例如R-CNN,使用区域建议法首先在图像上生成潜在的边界框,然后在这些建议的框上运行分类器。在分类结束后,使用后处理重新优化边界框,消除重复的检测,并根据场景中的其它目标对这些边界框进行二次评分。由于这些组件必须分开单独进行训练,导致这些复杂的结构速度慢并且难以优化。
我们将对象检测问题定义为一个单一的回归问题,直接从图像像素到边界框坐标和类别的概率。使用我们的系统,一次就可预测出图像中的目标是什么,它们在哪里。
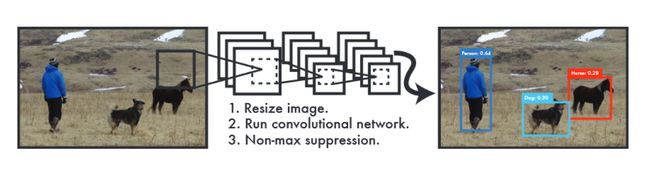
YOLO很简单,如图1,一个单一的卷积网络同时预测多个边界框和这些边界框所属类的概率。YOLO可以在整张图像上训练,并直接优化检测性能。这个统一的模型相比传统的目标检测方法有以下一个优点:
- 首先,YOLO非常快。我们将检测任务作为一个回归问题,不需要复杂的管道连接。我们在测试时在一个新图像上运行我们的神经网络来预测检测的结果。
- YOLO的预测结果是针对全局图像的。不像滑动窗口和基于区域的建议技术,YOLO 在训练和测试时使用的是整张图像,所以它的检测结果隐含地编码了类的上下文信息和外表信息。Fast R-CNN,一种顶级的检测方法,因为无法看到更大的上下文信息,所以分割的目标在背景中容易出现补丁式的错误。与Fast R-CNN相比,YOLO的背景错误数量不足一半。
- YOLO学习到了目标对象的一般化表示。当对自然图像进行训练,并在艺术品上进行测试时,YOLO比DPM和R-CNN等顶级检测方法更加有效。当将其应用到别的领域或输入异常时,YOLO不太容易发生崩溃。
YOLO在精度方面仍然落后于最先进的检测系统。虽然它能快速识别图像中的物体,但它很难将精确定位某些物体,尤其是当物体较小时。
统一检测(Unified Detection)
我们将目标检测的独立组件整合到一个单一的神经网络中。我们的网络使用整张图像的特征预测每个边界框,同时它还可以同时预测所有类的所有边界框。这意味着我们的网络在整个图像和图像的所有目标的检测依据是全局的。
YOLO的设计使得在保持较高的平局精度的同时可以进行端到端的训练和实时的加速。
我们的系统将输入图像分为SxS的方格。如果物体的中心落入单元格中,那么该网格单元就负责检测该对象。
如果网格单元中没有目标对象存在,那么置信度就为0。否侧,我们希望置信度得分等于预测框和实际标签的交集(IOU)。
每个边界框包括5个预测值:x、y、w、h和可信度。坐标(x, y)表示框的中心相对于网格单元的边界。高度和宽度的预测是相对于整张图像而言的。可信度代表了预测框和任何真实框之间的IOU。
每个网格单元还会预测条件类概率c,
这些概率取决于包含目标的网格单元。我们只预测每个网格单元中的一组概率值,不关心网格单元中的边界框B的数量。

这给了我们每个边界框阶段特有的可信度得分。这些得分编码了出现在边界框中的那个类的概率,以及预测框与对象的匹配程度。

网络设计
我们通过一个卷积神经网络来实现这个模型,并在PASCAL VOC检测数据集上进行评价。网络的初始卷积层从图像中抽取特征,然而全连接层预测输出的概率和坐标。
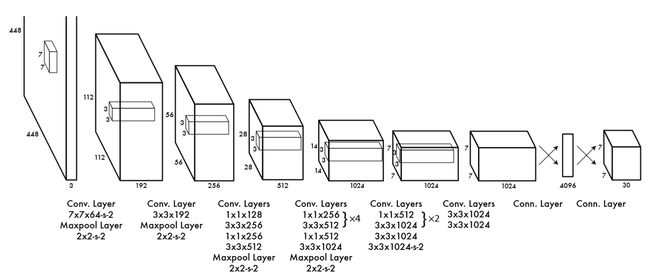
网络的最终输出为7x7x30的预测张量。
训练
我们在ImageNet 1000-class数据集上对卷积层进行预训练。对于预训练,我们使用图3中的前20个卷积层,然后是一个平局池化层和一个全连接层。
然后,我们将模型转化后用于目标检测。Ren等人表示将卷积层和全连接层加到预训练网络中可以提高网络性能。根据他们的例子,我们添加了四个卷积层和两个全连接层,并对权重进行随机初始化。目标检测通常需要更细粒度的视觉信息,所以我们将网络的输入从224x224增到了448x448。
网络中的最后一层负责预测类概率和边界框坐标。我们使用图像的高和宽对边界框的高和宽进行归一化,使其值介于0和1之间。我们将边界框的x和y坐标参数化为特定网格单元位置的偏移量,因此它们也在0和1之间有界。
我们在网络的最后一层使用了一个线性激活函数,在其它层使用了如下的leaky整流线性激活:

我们在网络的输出中优化了求和平方误差函数。我们使用求和平方误差函数是因为它容易优化,但是它与我们最大化平均精度的目标并不相符。它的权重定位错误和分类错误几乎相等,这并不是我们期望的。此外,在每张图像中,许多网格中是不包含任何目标对象的。这就导致这些网格单元中的可信度得分为0,而且还会压迫那些包含目标对象的网格单元的梯度。最终导致模型不稳定,在训练早期就发生了偏离。
为了解决这个问题,我们增加了边框坐标的预测损失,并减少了那些不包含目标对象的框中置信度预测的损失。我们使用了两个参数,λcoord和λnoobj完成这个工作,设置λcoord=5,λnoobj=.5。
在大框和小框中,求和平方误差叶近似与权重误差。误差指标从大框中反映出小的误差比从小框中反映出小的偏差更加重要。为了部分解决这个问题,我们预测了边界框的宽和高的平方根,而不是直接预测宽和高。
YOLO在每个网格单元中预测出多个边界框。在训练时,我们只想让一个边界框预测器去负责每个对象。如果一个预测器和真实目标具有最高的IOU,那么我们就指定这个预测器负责预测这个目标对象。这导致了边界框预测器之间的专业化。每个预测器都能更好地预测特定的大小、纵横比或者对象的类别,从而提高了整体的召回率。
在训练过程中,我们进行了以下优化:
损失函数:
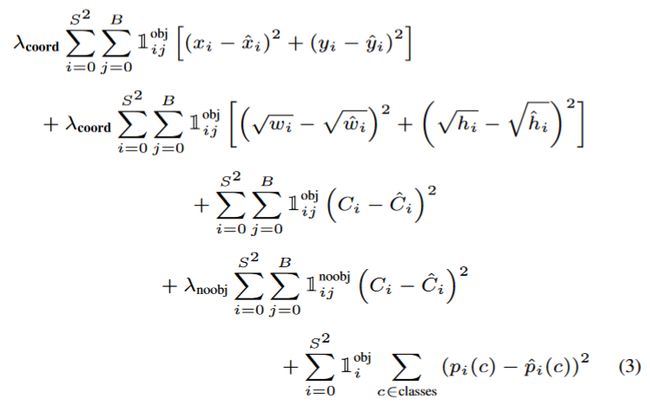
特别强调,当一个对象存在于该网格单元中时,损失函数只会惩罚分类错误。当预测器负责预测该目标对象时,惩罚函数也只会惩罚边界框坐标错误。
我们在PASCAL VOC2007和2012数据集上进行了135回合的训练,同时进行了验证和测试。在使用2012数据集测试时,我们还使用了VOC2007测试数据进行了训练。整个训练过程个中,我们使用的batch size=64,动量为0.9,衰减为0.0005。
我们的学习率如下:在第一回合的训练中,我们将学习率从10 -3缓慢增长到了10-2。由于不稳定的梯度,在一开始就使用一个较高的学习率可能会使得模型会出现偏离。接下来使用10 -2的学习率进行了75回合的训练,接下来使用10-3进行了30回合的训练,最终使用10^-4的学习率进行了30回合的训练。
为了避免过拟合,我们使用了Dropout和广泛的数据增强。在第一个连接层之后使用了droout_rate=0.5的Drouout层,可以阻止层之间的相互适应性。对于数据增强,我们在原图上使用了随机缩放和高达20%的图像反转。我们还在HSV颜色空间中随机调整图像的曝光率和饱和度,达到1.5倍。
YOLO的局限性
YOLO在边界框的预测上是加了很强的空间约束,导致每一个网格单元只能预测两个边界框并且只能有一个类。这种空间约束限制了模型在一个目标对象附近所能预测的目标数量。我们的模型与群体中出现的小物体进行斗争(比如鸟群)。
由于模型学会了从数据中预测边界框,所以它很难推广到新的或着不同寻常的长宽比的对象中。同时,由于网络对原始输入图像使用了多个下采样层,导致模型只能使用相对粗糙的特征预测边界框。
当我们在一个近似检测性能的损失函数上进行训练时,我们的损失函数在小的边界框和大的边界框中处理时出现相同的错误。一个大框中的小错误通常是可接受的,但小框中的小错误却对IOU的影像非常大。模型的主要错误来源于目标的不正确的定位。
来一张图总结一下
