提交Spark程序时,资源调优是必须的,否则会默认运行2个executor,每个executor内存1G。这里主要针对资源利用做个总结。
原
提交Spark程序时,资源调优是必须的,否则会默认运行2个executor,每个executor内存1G。这里主要针对资源利用做个总结。
主要涉及
-
--num-executors
-
--executor-memory
-
--executor-cores
-
--conf spark.default.parallelism
服务器节点YARN可用资源
| 服务器 | 单节点cores | 总cores | 单节点内存 | 总内存 |
| 3台 | 29 | 87 | 18G | 54G |
提交任务时遇到的一个小问题
提交Spark时,发现无论怎么设置executor数都是2个,排查后才发现,CDH上设置了yarn.scheduler.minimum-allocation-mb的值为8G,也就是YARN的作业最小调度资源。节点上YARN可用内存为18G,所以最多只能开启2个Container,也就是2个executor,剩下的内存足够开启一个AM的Container,所以最后Container为3个,executor只有2个。
1. Spark的executor申请资源需要加上堆外内存
-
# 堆外内存5
g以下都是取384
m
-
spark
.executor
.memoryOverhead
max(384,
executorMemory * 0
.07)
-
-
spark
.executor
.memory 默认1
g
如果默认情况下,真正申请的资源应该是 1g+384m,但是设置了增量为512m,最后申请资源为 1.5g。
driver的内存设置也是同样。
2. 一个Container开启一个executor
3. dirver会占用一个Container,默认1个core,1G内存
也就是有一个节点会开启一个Container来运行driver,cluster模式AM运行在driver中,默认占用1个core,1G内存。这个节点的资源减少了,所以应该减掉一个executor。
4. 并行度为executor总cores的2-3倍
因为内存比较少,所以先从内存来分配。
单节点18G可用内存,设置每个executor内存2G,那么实际申请资源为2.5G,可以开启 7.2个,也就是7个,总21个。
总87个core,每个executor分配4.14个core,也就是4个core。
考虑AM需要一个Container,这里可以减掉一个executor。
并行度设置为executor总core的2-3倍,即80的2-3倍,160。
-
--num-executors 20
-
--executor-memory 2g
-
--executor-cores 4
-
--conf spark.default.parallelism=160 \
运行spark-shell测试
-
spark-shell \
-
--master yarn \
-
--deploy-mode client \
-
--num-executors 20 \
-
--executor-cores 4 \
-
--executor-memory 2g
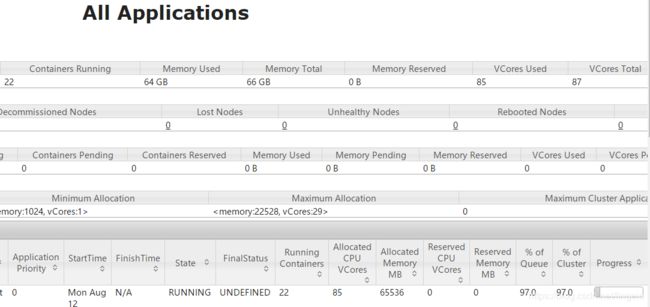
Container为21个,是20个executor和1个driver。
cores为81个,20个executor * 4为80,driver默认1个core。
内存52224,20个executor * 2.5 * 1024为51200,driver默认1G(1024m)。

这样CPU和内存使用率达到94.4%。 当然,还可以根据情况继续优化,尽量不要有闲置资源造成浪费。
例如Cluster模式时可以设置driver资源来分配给AM。
-
--master yarn
-
--deploy-mode clster
-
--driver-memory 2g
-
--driver-cores 4
这样基本达到完全使用。
或者开启对外内存,这是需要另外的分配空闲内存的。executors共享堆外内存,executor中的task共享executor的堆内内存。
-
--conf spark.memory.offHeap.enabled=true \
-
--conf spark.memory.offHeap.size=3072m \
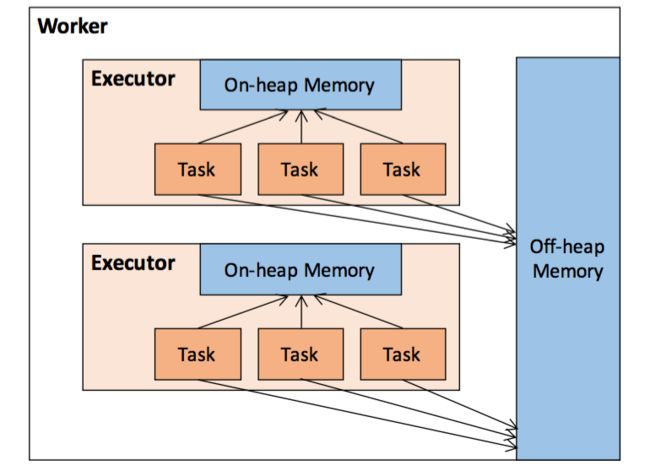
这里的Storage Memory是存储内存,根据官网说明。
-
spark
.memory
.fraction 0
.6
-
#
Fraction
of (
heap
space
- 300
MB)
used
for
execution
and
storage.
-
-
spark
.memory
.storageFraction 0
.5
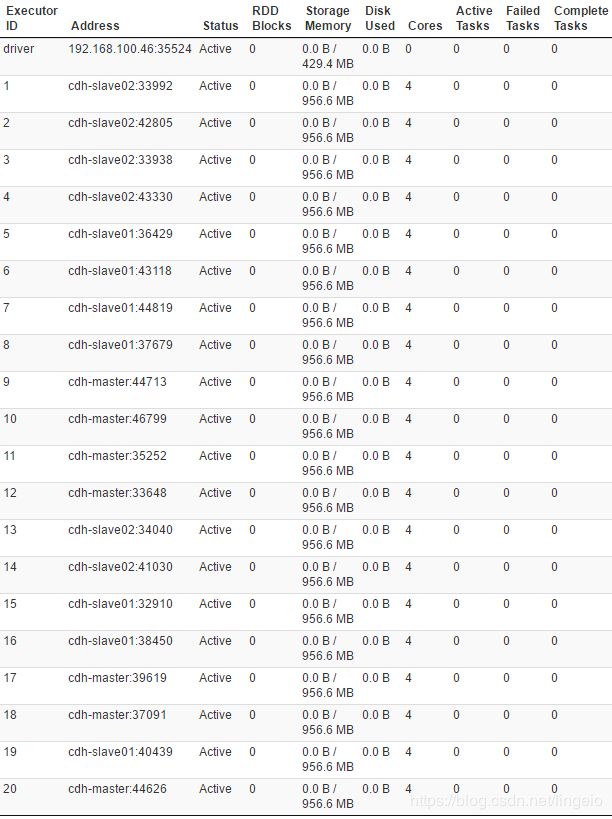
例如
当把Yarn节点内存调整到22G,总内存为66G,87cores
-
spark-shell \
-
--master yarn \
-
--deploy-mode client \
-
--num-executors 21 \
-
--executor-cores 4 \
-
--executor-memory 2560m
07-27 阅读数 522
SparkSQL特性之:代码量少,可读性高。计算平均数的功能,左是hadoop写MapReduce的代码量,太繁琐。右是用SparkCoreRDDAPI写,代码量少但可读性不好。同样是计算平均数,用S... 博文 来自: Sid小杰的博客
05-26 阅读数 578
在spark开发过程中,会遇到给中各样的问题。主要原因是对spark机制误解导致的。 学习spark之初,走了很多很多弯路。甚至一度对spark官方文档产生了怀疑,最终又回到s... 博文 来自: u010990043的博客
04-29 阅读数 77
前言在大数据计算领域,Spark已经成为了越来越流行、越来越受欢迎的计算平台之一。Spark的功能涵盖了大数据领域的离线批处理、SQL类处理、流式/实时计算、机器学习、图计算等各种不同类型的计算操作,... 博文 来自: MeituanTech的博客
04-28 阅读数 3085
1启动方式执行命令./spark-shell--masteryarn默认运行的是client模式。执行./spark-shell--masteryarn-client或者./spark-shell--... 博文
11-15 阅读数 467
文章目录资源调度结论:1、默认情况下,每一个Worker会为当前的Application启动一个Executor进程,并且这个Executor会使用1G内存和当前Worker所能管理的所有core。2... 博文 来自: 滴水穿石的博客
01-23 阅读数 1395
打开微信扫一扫,关注微信公众号【数据与算法联盟】转载请注明出处:http://blog.csdn.net/gamer_gyt博主微博:http://weibo.com/234654758Github:... 博文 来自: Thinkgamer博客
01-12 阅读数 7427
阅读本篇博文时,请先理解RDD的描述及作业调度:[《深入理解Spark2.1Core(一):RDD的原理与源码分析》](http://blog.csdn.net/u011239443/article/... 博文 来自: Soul Joy Hub
10-15 阅读数 2270
算子优化MapPartitionsspark中,最基本的原则,就是每个task处理一个RDD的partition。MapPartitions操作的优点:如果是普通的map,比如一个partition中... 博文
07-13 阅读数 5741
环境信息:hive1.2.1spark1.6.1hadoop2.6.0-cdh5.4.2memory:1918752,vCores:506表结构:表名称表容量主键hive存储类型temp_01_pc_... 博文 来自: yijichangkong的专栏
03-26 阅读数 3352
文章地址:http://www.haha174.top/article/details/259354举个例子valcounts=pairs.reduceByKey(_+_)valcounts=pair... 博文 来自: u012957549的博客
12-22 阅读数 969
因为默认的distinct算子操作效率太低,自己改写一下。defmydistinct(iter:Iterator[(String,Int)]):Iterator[String]={iter.foldL... 博文 来自: willyan2007的博客
06-09 阅读数 6835
数据量:1~2G左右的表与3~4T的大表进行Join拆分将任务数据分为多个结果RDD,将各个RDD的数据写入临时的hdfs目录,最后合并调整并行度和shuffle参数spark-submit参数#提高... 博文 来自: program哲学
腾讯大王卡怎么申请|腾讯大王卡官方申请办理入口流程 酷猴游戏
大观
经验|如何设置Spark资源
08-20 阅读数 2251
经常有人在微信群里问浪尖,到底应该如何配置yarn集群的资源,如何配置sparkexecutor数目,内存及cpu。今天浪尖在这里大致聊聊这几个问题。资源调优Spark...... 博文 来自: Spark高级玩法
Spark on YARN占用资源分析 - Spark 内存模型
04-17 阅读数 782
Spark的Excutor的Container内存有两大部分组成:堆外内存和Excutor内存A) 堆外内存(spark.yarn.executor.memoryOverhead) 主要用于JVM自... 博文 来自: wjl7813的博客
Spark离线计算优化——leftOuterJoin优化
06-06 阅读数 1264
两个k-v格式的RDD进行leftOuterJoin操作如果数据量较大复杂度较高的话计算可能会消耗大量时间。可以通过两种方式进行优化:1、leftOuterJoin操作前,两个RDD自身进行reduc... 博文 来自: zxlove
利用shell配置spark资源
05-30 阅读数 442
利用shell配置spark资源run.sh#!/bin/bashCUR=$(cd`dirname$0`;pwd)day=201801main(){localmonth=$1localprov_id=... 博文 来自: yiluohan0307的专栏
第145课: Spark面试经典系列之Yarn生产环境下资源不足问题、JVM和网络的经典问题详解
07-15 阅读数 1642
第145课:Spark面试经典系列之Yarn生产环境下资源不足问题、JVM和网络的经典问题详解 1Yarn生产环境下资源不足无法提交spark2yarn-client网络流量的问题 spar... 博文 来自: 段智华的博客

没有更多推荐了,返回首页