何以高可用?
我们以前用Mysql的时候,经常是一台服务器走天下,如果只是用于学习,是没有问题的,但是在生产环境中,这样的风险是很大的,如果服务器因为网络原因或者崩溃了,就会导致数据库一段时间了不可用,这样的体验很不好。
那么应该怎么办呢?既然一台机器不行,我就多上几台机器总可以了吧,比如我上个两台,让他们互为主备,相互同步数据。想到这里我就只想说一个字,稳。
其实redis,mongodb,kafka等分布式应用基本上都是这样的思想
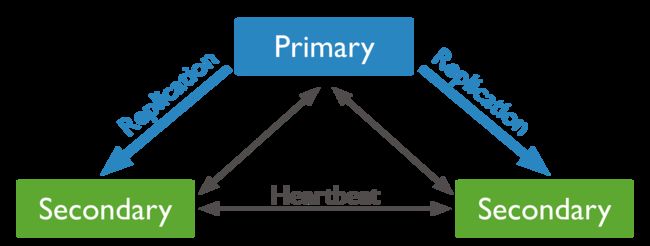
MongoDB也差不多是这样的思想。它通过复制集来解决这个问题,MongoDB复制集由一组Mongod进程组成,包含一个Primary节点和多个Secondary节点,Mongodb Driver(客户端)的所有数据都写入Primary,Secondary从Primary同步写入的数据,以保持复制集内所有成员存储相同的数据集,提供数据的高可用。
要想成为primary节点,你必须保证大多数节点都同意才行,大多数的节点就是副本中一半以上的成员。
| 成员总数 | 大多数 | 容忍失败数 |
|---|---|---|
| 1 | 1 | 0 |
| 2 | 2 | 0 |
| 3 | 2 | 1 |
| 4 | 3 | 1 |
| 5 | 3 | 2 |
| 6 | 4 | 2 |
| 7 | 4 | 3 |
为什么要要求大多数呢?其实是为了避免出现两个primary节点。比如一个五个节点的复制集,其中3个成员不可用,剩下的2个仍然正常工作。这两个工作的节点由于不能满足复制集大多数的要求(这个例子中要求要有3个节点才是大多数),所以他们无法选择主节点,即使其中有一个节点是primary节点,当它注意到它无法获取大多数节点的支持时,它就会退位,成为备份节点。
如果让这两个节点可以选出primary节点,问题是另外3个节点可能不是真正挂了,而只是网络不可达而已。另外3个节点就一定可以选择出primary节点,这样就存在了两个primary节点了。
所以要求大多数就可以避免产生两个primary节点的问题。
如果MongoDB副本集可以拥有多个primary节点,那么就会面临写入冲突的问题,在支持多线程写入的系统中解决冲突的方式有手动解决和让操作系统任选一个这两种方式,但是这两种方式都不易实现,无法保证写入的数据不被其他节点修改,因此mongodb只支持单一的primary节点,这样使得开发更容易。
当一个备份节点无法与主节点连通时,它会联系并请求其他副本集成员将自己选举为主节点,其他成员会做几项理性的检查:自身是否能够与主节点连通?希望被选举为主节点的备份节点的数据是否最新?有没有其他更高优先级的成员可以被选举为主节点?
如果竞选节点成员能够得到大多数投票,就会成为主节点。但是一旦大多数成员中只有一个否决了本次选举,选举就会取消。
在日志中可以看到得票数为比较大的负数的情况,因为一张否决票相当于10000张赞成票。如果有2张赞成票,2张否决票,那么选举结果就是-19998,依此类推。
配置选项
我们一般在部署的时候,副本集节点个数至少是3个(因为它允许1个失败),这也就意味着数据要被复制三份。
仲裁者(arbiter)
很多人的应用程序使用量比较小,不想保存三份数据,只想要保存两份就行了,保存第三份纯粹是浪费。对于这种部署MongoDB也是支持的。它有一种特殊的成员叫做仲裁者(arbiter),它唯一的作用就是参与选举,它既不保存数据也不为客户端提供服务,只是为了帮助只有两个成员的副本集满足大多数这个条件而已。
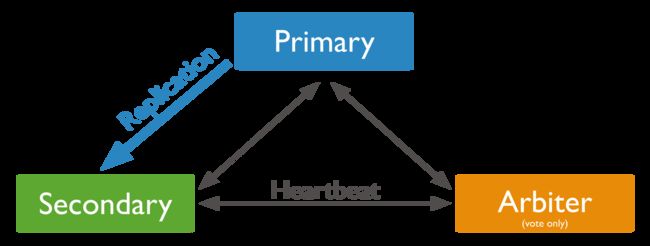
仲裁者其实也是有缺点的。如果真有一个节点挂了(数据无法恢复),另一个成员称为主节点。为了数据安全,就需要一个新的备份节点,并且将主节点的数据备份到备份节点。复制数据会对服务器造成很大的压力,会拖慢应用程序。相反如果有三个数据成员即使其中一个挂了,仍有一个主节点和一个备份节点,不影响正常运作。这个时候还可以用剩下的那个备份节点来初始化一个新的备份节点服务器,而不依赖于主节点。所以如果可能尽可能在副本集中使用奇数个数据成员,而不要使用仲裁者。
优先级(priority)
如果想让一个节点有更大的机会成为primary的话这需要设置优先级,比如我添加一个优先级为2的成员(默认为1)
rs.add({"_id":4, "host": "10.17.28.190:27017", "priority" : 2});
假设其他都是默认优先级,只要10.17.28.190拥有最新数据,那么当前primary节点就会自动退位,10.17.28.190会被选举为新的主节点。如果它的数据不够新,那么当前主节点就会保持不变。
如果设置priority为0,表示不会被选为primary节点。
投票权(vote)
由于复制集成员最多50个,而参与Primary成员投票的最多7个,所以其他成员的vote必须设置为0(priority也必须为0)。
尽管无投票权的成员不会在选举中投票,但这些成员拥有副本集数据的副本,并且可以接受来自客户端应用程序的读取操作。
隐藏成员(hidden)
客户端不会像隐藏成员发送请求,隐藏成员也不会作为复制源(尽管当其他复制源不可用时隐藏成员)。因此很多人将不够强大的服务器或者备份服务器隐藏起来。通过设置hidden:true可以设置隐藏,只有优先级为0的才能被隐藏。
可使用Hidden节点做一些数据备份、离线计算的任务,不会影响复制集的服务
延迟备份节点(slaveDelay)
数据可能会因为人为错误而遭到毁灭性的破坏,为了防止这类问题,可以使用slaveDelay设置一个延迟的备份节点。
延迟备份节点的数据回比主节点延迟指定的时间(单位是秒),slaveDelay要求优先级是0,如果应用会将读请求路由到备份节点,应该将延迟备份节点隐藏掉,以免读请求被路由到延迟备份节点。
因Delayed节点的数据比Primary落后一段时间,当错误或者无效的数据写入Primary时,可通过Delayed节点的数据来恢复到之前的时间点。
修改副本集配置
比如我有个副本集叫做rs0,我想修改增加或者删除成员,修改成员的配置(vote,hidden,priority等)可以通过reconfig命令
https://docs.mongodb.com/manual/reference/method/rs.reconfig/
cfg = rs.conf();
cfg.members[1].priority = 2;
rs.reconfig(cfg);
同步
Primary与Secondary之间通过oplog来同步数据,Primary上的写操作完成后,会向特殊的local.oplog.rs特殊集合写入一条oplog,Secondary不断的从Primary取新的oplog并应用。
因oplog的数据会不断增加,local.oplog.rs被设置成为一个capped集合,当容量达到配置上限时,会将最旧的数据删除掉。由于复制操作的过程是先复制数据在写入oplog,oplog必须具有幂等性,即重复应用也会得到相同的结果。
我向test库的coll集合插入了一条数据之后(db.coll.insert({count:1})),调用db.isMaster()命令可以看到当前节点的最后一次写入时间戳
> db.isMaster()
{
"ismaster" : true,
"secondary" : false,
"lastWrite" : {
"opTime" : {
"ts" : Timestamp(1572509087, 2),
"t" : NumberLong(1)
},
"lastWriteDate" : ISODate("2019-10-31T08:04:47Z"),
"majorityOpTime" : {
"ts" : Timestamp(1572509087, 2),
"t" : NumberLong(1)
},
"majorityWriteDate" : ISODate("2019-10-31T08:04:47Z")
}
}
命令会返回很多数据,这里我只列出了小部分,可以看到我们当前所在节点是master节点(primary),如果当前节点不是primary,也会通过primary属性告诉你当前primary节点是哪个,同时最后一次写入的时间戳是1572509087。
此时我们登录另一台secondary节点,切换到local数据库,执行命令db.oplog.rs.find()命令,会返回很多条数据,这里我们查看最后一条即可
{
"ts" : Timestamp(1572509087, 2),
"t" : NumberLong(1),
"h" : NumberLong("6139682004250579847"),
"v" : 2,
"op" : "i",
"ns" : "test.coll",
"ui" : UUID("1be7f8d0-fde2-4d68-89ea-808f14b326da"),
"wall" : ISODate("2019-10-31T08:04:47.925Z"),
"o" : {
"_id" : ObjectId("5dba959fcf287dfd8727a1bf"),
"count" : 1
}
}
可以看到oplog的ts和isMater()命令返回的lastTime.opTime.ts的值是一致的,证明我们的数据是最新的,如果你这个时候访问其他节点查看oplog.rs的数据,会发现数据是一模一样的。
在来解释下字段含义
- ts : 操作时间,当前timestamp + 计数器,计数器每秒都被重置
- h:操作的全局唯一标识
- v:oplog版本信息
- op:操作类型
- i:插入操作
- u:更新操作
- d:删除操作
- c:执行命令(如createDatabase,dropDatabase)
- n:空操作,特殊用途
- ns:操作针对的集合
- o:操作内容,可以看到我这里插入的字段是count,值是1
- o2:操作查询条件,仅update操作包含该字段
初始化同步
副本集中的成员启动之后,就会检查自身状态,确定是否可以从某个成员那里进行同步。如果不行的话,它会尝试从副本的另一个成员那里进行完整的数据复制。这个过程就是初始化同步(initial syncing)。
init sync过程包含如下步骤
- 准备工作删除所有已存在的数据库,以一个全新的状态开始同步
- 将同步源的所有记录全部复制到本地(除了local)
- oplog同步第一步,克隆过程中的所有操作都会被记录到oplog中,如果有文档在克隆过程中被移动了,就有可能会被遗漏,导致没有被克隆,对于这样的文档,可能需要重新克隆
- oplog同步过程第二步,将第一个oplog同步中的操作记录下来
- 创建索引
- 如果当前节点的数据仍然远远落后于同步源,那么oplog同步过程的最后一步就是将创建索引期间的所有操作全部同步过来,防止该成员成为备份节点。
- 完成初始化同步之后,切换到普通同步状态,这时当前成员就可以称为备份节点了。
总结起来就是从其他节点同步全量数据,然后不过从Primary的local.oplog.rs集合里查询最新的oplog并应用到自身。
查询固定集合使用的tailable cursor(https://docs.mongodb.com/manual/core/tailable-cursors/)
Primary选举
Primary选举除了在复制集初始化时发生,还有如下场景
- 复制集reconfig
- Secondary节点检测到Primary宕机时,会触发新Primary的选举
- 当有Primary节点主动stepDown(主动降级为Secondary)时,也会触发新的Primary选举
Primary的选举受节点间心跳、优先级、最新的oplog时间等多种因素影响。
节点间心跳
复制集成员间默认每2s会发送一次心跳信息,如果10s未收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点为Primary,Secondary(前提是可被选为Primary)会发起新的Primary选举。
心跳是为了知道其他成员状态,哪个是主节点,哪个可以作为同步源,哪个挂掉了等等信息
成员状态:
- STARTUP : 刚启动时处于这个状态,加载副本集成功后就进入STARTUP2状态
- STARTUP2 : 整个初始化同步都处于这个状态,这个状态下,MongDB会创建几个线程,用于处理复制和选举,然后就会切换到RECOVERING状态
- RECOVERING : 表示运行正常,当暂时不能处理读取请求。如果有成员处于这个状态,可能会造成轻微系统过载
- ARBITER : 仲裁者处于这个状态
- DOWN : 一个正常运行的成员不可达,就处于DOWN状态。这个状态有可能是网络问题
- UNKNOWN : 成员无法到达其他任何成员,其他成员就知道无法它处于什么状态,就会处于UNKNOWN。表明这个未知状态的成员挂掉了。或者两个成员间存在网络访问问题。
- REMOVED : 被移除副本集时处于的状态,添加回来后,就会回到正常状态
- ROLLBACK : 处于数据回滚时就处于ROLLBACK状态。回滚结束后,会换为RECOVERING状态,然后成为备份节点。
- FATAL : 发生不可挽回错误,也不再尝试恢复,就处于这个状态。这个时候通常应该重启服务器
节点优先级
- 每个节点都倾向于投票给优先级最高的节点
- 优先级为0的节点不会主动发起Primary选举
- 当Primary发现有优先级更高Secondary,并且该Secondary的数据落后在10s内,则Primary会主动降级,让优先级更高的Secondary有成为Primary的机会。
OpTime
最新optime(最近一条oplog的时间戳)的节点才能被选为主,请看上面对oplog.rs的分析。
网络分区
只有大多数投票节点间保持网络连通,才有机会被选Primary;如果Primary与大多数的节点断开连接,Primary会主动降级为Secondary。当发生网络分区时,可能在短时间内出现多个Primary,故Driver在写入时,最好设置大多数成功的策略,这样即使出现多个Primary,也只有一个Primary能成功写入大多数。
复制集的读写设置
Read Preference
默认情况下,复制集的所有读请求都发到Primary,Driver可通过设置Read Preference来将读请求路由到其他的节点。
- primary: 默认规则,所有读请求发到Primary
- primaryPreferred: Primary优先,如果Primary不可达,请求Secondary
- secondary: 所有的读请求都发到secondary
- secondaryPreferred:Secondary优先,当所有Secondary不可达时,请求Primary
- nearest:读请求发送到最近的可达节点上(通过ping探测得出最近的节点)
Write Concern
默认情况下,Primary完成写操作即返回,Driver可通过设置Write Concern来设置写成功的规则。
如下的write concern规则设置写必须在大多数节点上成功,超时时间为5s。
db.products.insert(
{ item: "envelopes", qty : 100, type: "Clasp" },
{ writeConcern: { w: majority, wtimeout: 5000 } }
)
上面的设置方式是针对单个请求的,也可以修改副本集默认的write concern,这样就不用每个请求单独设置。
cfg = rs.conf()
cfg.settings = {}
cfg.settings.getLastErrorDefaults = { w: "majority", wtimeout: 5000 }
rs.reconfig(cfg)
回滚(rollback)
Primary执行了一个写请求之后挂了,但是备份节点还没有来得及复制这次操作。新选举出来的主节点结就会漏掉这次写操作。当旧Primary恢复之后,就要回滚部分操作。
比如一个复制集存在两个数据中心,DC1中存在A(primary),B两个节点,DC2中存在C,D,E这三个节点。
如果DC1出现了故障。其中DC1这个数据中心的最后的操作是126,但是126没有被复制到另外的数据中心。所以DC2中服务器最新的操作是125
DC2的数据中心仍然满足副本集大多数的要求(5台,DC2有3台),因此其中一个会被选举成为新的主节点,这个节点会继续处理后续的写入操作。
当网络恢复之后,DC1中心的服务器就会从其他服务器同步126之后的操作,但是无法找到。这种时候DC1中的A,B就会进入回滚过程。
回滚回将失败之前未复制的操作撤销。拥有126操作的服务器会在DC2的服务器的oplog寻找共同的操作点。这里会定位125,这是两个数据中心相匹配的最后一个操作。
这时,服务器会查看这些没有被复制的操作,将受这些操作影响的文档写入一个.bson文件,保存在数据目录下的rollback目录中。
如果126是一个更新操作,服务器回将126更新的文档写入collectionName.bson文件。如果想要恢复被回滚的操作,可以使用mongorestore命令。