学习Hadoop第十四课(自定义分区Partitioner)
上一节课我们一起学习了Hadoop的远程调试,这节课我们一起学习Hadoop的Partitioner(分区),首先说一下为什么要用到分区的功能,这里我们举个例子,
中国移动公司想要查看北京用户的打电话情况,手机信号来自附近的基站,要查看北京用户的信息得从全国所有的基站获取信息并一一筛选,假如我们不把用户按
省市进行分别存放的话,每次我们想查看某个省市的信息时便需要从全国所有的基站信息中去一一查询,这样做,无疑效率是非常低的。假如我们把数据都分省市
进行存放了,以后我们再想查看北京市的打电话信息便非常方便了,直接到存放北京市打电话信息的文件中查找就可以了。
我们学习Partitioner不用举那么复杂的例子,就举一个简单的例子就好了,在第十二节课学习了一个DataCount的小例子,地址:http://blog.csdn.net/u012453843/article/details/52600313我们就在这个程序的基础上加上我们自定义的分区功能。我们先来看看DataCount这个程序最终的执行结果是什么样子的,在查看之前我们需要先启动hdfs和yarn,如果你是看完上节远程debug之后并且在hadoop-env.sh文件中配置了namenode和datanode的debug信息的话,我们需要先把那两句配置语句给注释掉,否则我们启动namenode和datanode时程序会被阻塞住。操作步骤如下图所示,可以看到我们只需在两句配置前面加上"#"号就可以了。
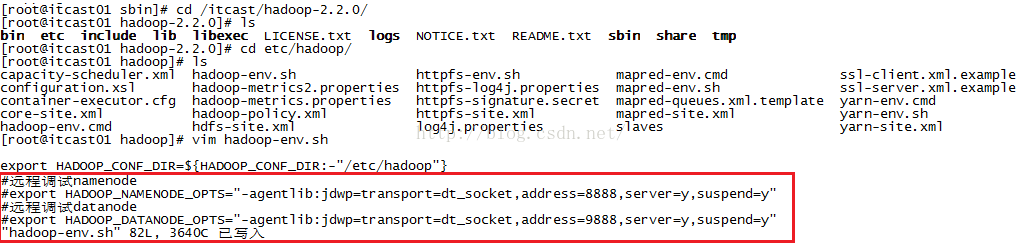
注释掉上图中的两句配置之后我们来启动dfs和yarn如下图所示

启动完dfs和yarn之后我们查看进程,看是否所有进程都启动起来了,如下图所示,我们发现所有进程确实都正常启动了。

接下来我们看一下第十二课所写的那个DataCount的例子的执行结果是什么样子的,如下图所示,我们可以看到,程序把所有手机或网卡的所有上行流量、下行流量还有总流量给统计出来了。
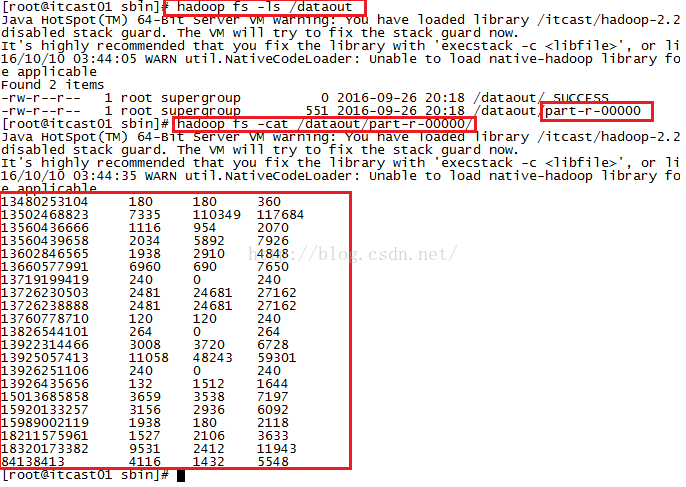
现在我们想在这个例子的基础上进行改进,就是想把这个结果文件拆分成多个,我们姑且认为135、136、137、138、139是中国移动的手机号码,150、159是中国联通的手机号码、182、183是中国电信的手机号码,134还有84138413这样的网卡归结为其它。这样一来,结果文件应该被分成4份。接下来我们便使用Hadoop的Partitioner功能来实现。我们在DataCount类中增加了一个内部类ProviderPartitioner,让它继承Partitioner并且重写getPartition方法,写完内部类后,我们还需要在main方法中把ProviderPartitioner加载到Job当中,要不然Hadoop不知道你定义了一个内部类,也不会去执行它。我们还需要设置Reducer的数量。
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public static void main(String[] args) throws Exception {
Configuration conf=new Configuration();
Job job=Job.getInstance(conf);
job.setJarByClass(DataCount.class);
job.setMapperClass(DCMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(DataBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
//告诉Job我们自定义了分区功能
job.setReducerClass(DCReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(DataBean.class);
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//设置Reducer的数量,默认情况下只启动一个Reducer,一个Reducer对应一个文件,我们现在想要得到4个文件,自然而然我们得启动多个Reducer,为了程序的灵活性我
job.setNumReduceTasks(Integer.parseInt(args[2]));
job.waitForCompletion(true);
}
public static class DCMapper extends Mapper
Text text=null;
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line=value.toString();
String[] fields=line.split("\t");
String telNo=fields[1];
long up=Long.parseLong(fields[8]);
long down=Long.parseLong(fields[9]);
DataBean bean=new DataBean(telNo, up, down);
text=new Text(telNo);
context.write(text,bean);
}
}
public static class ProviderPartitioner extends Partitioner
/**
* numPartitions---分区的值是由Reducer的数量决定的,起几个Reducer就创建几个分区
*/
public static Map
static{
providerMap.put("135", 1);
providerMap.put("136", 1);
providerMap.put("137", 1);
providerMap.put("138", 1);
providerMap.put("139", 1);
providerMap.put("150", 2);
providerMap.put("159", 2);
providerMap.put("182", 3);
providerMap.put("183", 3);
}
@Override
public int getPartition(Text key, DataBean value, int numPartitions) {
//key是电话号码
String telNo=key.toString();
//我们截取前3位,比如135、136、150、182等等,通过前三位就可以知道是移动、联通还是电信或是其它
String sub_tel=telNo.substring(0, 3);
Integer num=providerMap.get(sub_tel);
return num;
}
}
public static class DCReducer extends Reducer
protected void reduce(Text key, Iterable
throws IOException, InterruptedException {
long up_sum=0;
long down_sum=0;
for(DataBean bean:v2s){
up_sum+=bean.getUpPayLoad();
down_sum+=bean.getDownPayLoad();
}
DataBean bean=new DataBean(key.toString(), up_sum, down_sum);
context.write(key, bean);
}
}
}
写完了程序,我们把datacount工程打包,在工程上右键,然后点击"Export",如下图所示
点击上图的"Export"之后,我们会看到如下图所示界面,我们点击Java目录下的JAR file,然后点击下一步。
点击上图的"Next"之后我们会看到如下图所示的界面,我们勾选上红色框框住的那项,这项的意思是只导出jar文件不导出依赖的第三方jar包,这样会很快。程序运行所需要的jar包在Hadoop环境中有。JAR file的名字及要导出到哪个目录下我们可以点击“Browse...”来设置。
我们点击上图的"Browse..."之后会看到如下图所示的界面,我们在名称的输入框中起个名字,我这里取名为mr,然后点击“确定”。
点击上图的“确定”按钮之后我们回到了如下图所示的界面,发现JAR file的路径是/root/mr.jar,我们点击"Finish"
导出成功后,我们到root根目录下看一看是否有我们刚才导出的mr.jar文件,如下图所示,发现确实有mr.jar这个文件。

我们在执行mr.jar之前先看看hdfs系统根目录下是否有我们的上网数据data.dat(如果不知道是什么东东的话,可以仔细看一下第十二课所说的内容),我们发现确实是有这个文件的。
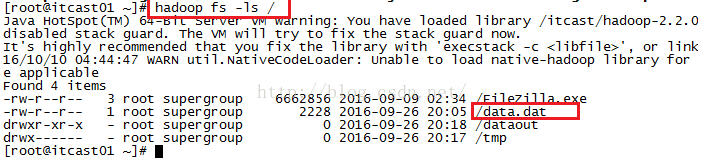
接下来我们便开始执行mr.jar这个文件了,如下图所示,执行命令hadoop jar mr.jar myhadoop.mr.dc.DataCount /data.dat /dataout-p4 4之后我们可以看到执行过程中Reducer的进度是从0到25%再到50%再到100%,这说明Hadoop确实是用多个Reducer在工作。
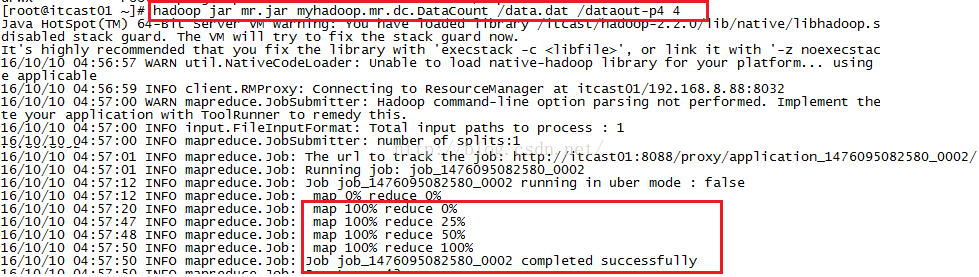
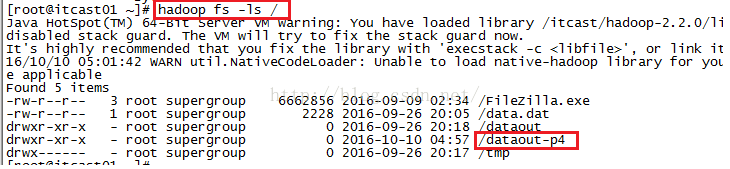
命令执行成功之后,在hdfs系统根目录下会有一个dataout-p4的文件夹,如下图所示
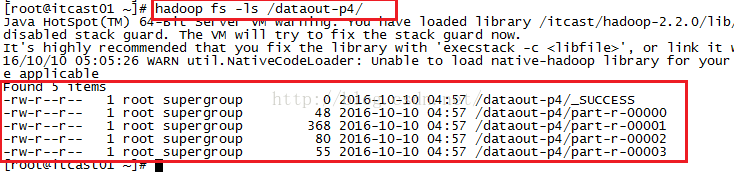
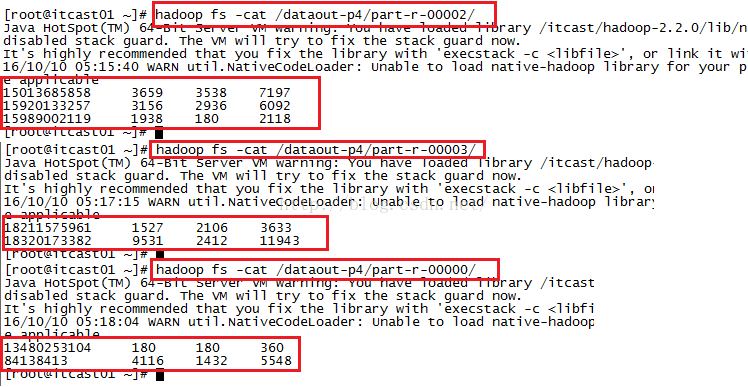
我们来看一下这个dataout-p4文件夹下都有哪些文件,如下图所示,我们发现生成了4个结果文件part-r-00000到part-r-00003。
我们查看一下part-r-00001这个文件中的内容是什么,如下图所示,我们发现确实是把我们自定义的中国移动的所有手机号码的内容都写到了这个文件当中!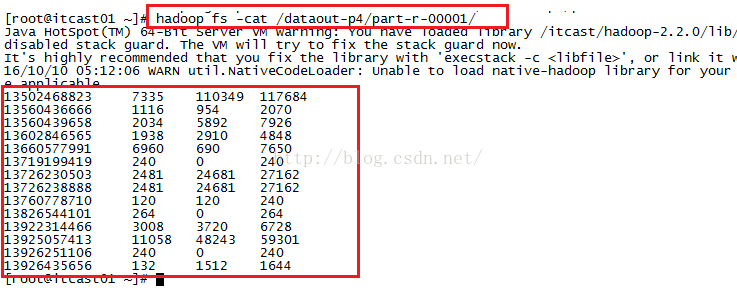
我们再来看看其它几个文件的内容,我们发现所有文件的结果都正确,这说明我们的分区功能成功了!
注意:这里需要说明的是,如果我们指定Reducer的数量多于1个少于4个的话,由于实际我们需要4个Reducer,但是指定的数量不够4个,这样就会报错。但是如果我们设置的Reducer的数量多于4个的话,不会出错,只是会生成多余的空文件。因此我们的原则是宁可多起Reducer也不能少起,否则会有问题。
好了,至此本小节课我们便一起学完了。