Java高并发之ConcurrentHashMap(锁分段技术、结构、初始化、如何定位、常见操作、JDK1.8中的变化)
1. 为什么要使用ConcurrentHashMap?
① HashMap线程不安全
- HashMap是非线程安全的,并发执行put操作时会引起Entry链表形成死循环。
- 由于Entry链表中的next结点永远不为null,就会在执行get操作时触发死循环,导致CPU使用率到达
100%。 - 形成死循环的原因: 并发执行put操作会导致HashMap的扩容。当调用
resize()方法进行扩容时,需要将旧的HashMap中的Entry移动到新的HashMap中,该操作由transfer()方法负责完成。 transfer()方法在移动的过程中,如果出现以下情况,将会导致Entry链表形成死循环。- 具体的图解见博客:疫苗:JAVA HASHMAP的死循环
② HashTable效率低下
- HashTable使用synchronized关键字实现线程安全,一个线程占用锁访问HashTable的同步方法,其他线程也想要访问同步方法,必须进入阻塞状态,等待锁的释放。
- 例如,线程1使用put操作进行元素添加;线程2不但不能执行put操作添加元素,也不能执行get操作获取元素。
- 因此,在线程竞争激烈的情况下,HashTable的效率非常低下。
③ ConcurrentHashMap的锁分段技术
ConcurrentHashMap使用锁分段技术,现将数据分成一段一段的存储,然后给每一段数据加一把锁。- 当线程占用锁访问某段数据时,其他线程可以并发访问其他段的数据。
只要不是并发访问同一段数据,就不会出现锁竞争的情况。 - 因此,
ConcurrentHashMap的锁分段技术有效地提高了并发访问率。
2. ConcurrentHashMap详解
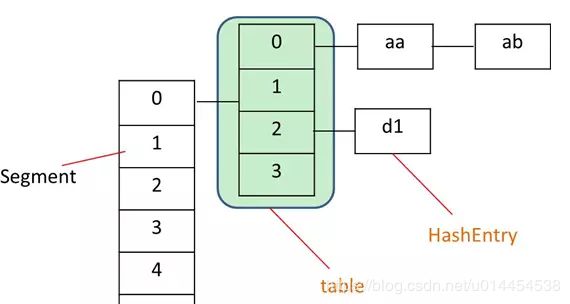
① 结构:Segment数组 + HashEntry数组(桶)
ConcurrentHashMap是由 Segment 数组结构和 HashEntry 数组结构组成。
- Segment 是一种可重入锁
ReentrantLock,在ConcurrentHashMap里扮演锁的角色;HashEntry 则用于存储键值对数据,就是HashMap中的Node。 - 一个
ConcurrentHashMap里包含一个 Segment 数组,每个Segment包含一个HashEntry数组,其实就是一个HashMap,为桶+链表的结构。 - 每个 Segment 守护者一个 HashEntry 数组里的元素, 当对 HashEntry 数组的数据进行修改时,必须首先获得它对应的 Segment 锁。
② ConcurrentHashMap的初始化
- ConcurrentHashMap的初始化主要包括:segments数组的初始化、每个segment的初始化。
- 通过
initialCapacity、loadFactor、concurrencyLevel几个参数来初始化 segments 数组的长度ssize、段偏移量 segmentShift、段掩码 segmentMask ,每个 segment 里的 HashEntry 数组的长度 cap,每个segment的容量阈值threshold。
segments数组的初始化
concurrencyLevel是允许访问的最大并发数,ssize是segments数组的长度,即整个ConcurrentHashMap中锁的个数。
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
int sshift = 0;
int ssize = 1;
// ssize是大于等于concurrencyLevel的最小2^N,sshift是1左移的次数,也就是前面的N
//比如我输入的concurrencyLevel=12,那么sshift = 4,ssize =16
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1; //ssize = ssize << 1 , ssize = ssize * 2
}
segmentShift = 32 - sshift;
segmentMask = ssize - 1; //segmentMask的二进制是一个全是1的数
this.segments = Segment.newArray(ssize); //segment个数是ssize,默认为16
- ssize的计算:
- segments数组的长度是ssize是由
concurrencyLevel计算得出的:先将ssize初始化为1,只要ssize < concurrencyLevel,就将ssize向左移一位,即将ssize扩大两倍。直到ssize是大于或等于concurrencyLevel的最小的 2 N 2^N 2N - 为什么ssize是大于或等于
concurrencyLevel的最小的 2 N 2^N 2N?答: 为了能通过按位与的hash算法定位segments数组的索引,要求ssize = 2^N。 - 例如,
concurrencyLevel = 14,则计算出来的ssize = 16。 concurrencyLevel的最大值为65535( 2 16 − 1 2^{16}-1 216−1),所以ssize 的最大值为65536)( 2 16 2^{16} 216)。
- 要想通过按位与的hash算法定义segments数组的索引,还需要使用
segmentShift和segmentMask这两个全局变量。前者定位参与hash运算的位数,后者表示hash运算的掩码。 - segmentShift的计算:
- 在计算ssize时,ssize的初始值是1,通过对1进行向左移位,可以得到满足条件的ssize。同时,有个sshift的变量,记录了1发生左移的次数。
- 完成ssize的计算后,sshift的值也就确定了。然后开始计算
segmentShift,segmentShift = 32 - sshift。 - 使用32减去sshift,是因为
ConcurrentHashMap里的 hash() 方法输出的最大数是 32 位。 - 因为ssize的最大值为 2 16 2^{16} 216,所以sshift的最大值为16,所以
segmentShift的最小值为16。
- segmentMask的计算:
segmentMask的计算非常简单,segmentMask = ssize - 1。- 作为掩码,要求其二进制数为全为1。通过减一,刚好可以让
segmentMask的二进制数全为1。 - 因为ssize的最大值为65536( 2 16 2^{16} 216),所以
segmentMask的最大值为65535,二进制数16位,每位都为1。
segment的初始化
initialCapacity是ConcurrentHashMap 的初始化容量,即segments数组中HashEntry数组的总长度。- 每个segment中HashEntry数组的长度cap,是大于等于c的最小 2 N 2^N 2N。
loadFactor是每个 segment 的负载因子,在构造方法中初始化segment,需要使用cap和loadFactor这两个参数
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = 1;
while (cap < c)
cap <<= 1;
for (int i = 0; i < this.segments.length; ++i)
//cap=2^N,默认是1,也就是每个segment下都构造了cap大小的table数组
this.segments[i] = new Segment<K,V>(cap, loadFactor);
- cap的计算:
- 计算
initialCapacity/ssize,可以得到initialCapacity是ssize的倍数c。 - 考虑到整数除法的特性,如果c是向下取整了,需要将c加一。即如果
c * ssize < initialCapacity,则c++。 - 将每个segment中HashEntry数组的长度cap初始化为1,如果
cap < c就将cap向左移一位,即将cap扩大两倍。直到cap是大于等于c的最小 2 n 2^n 2n。
- segment的初始化
- 传入 cap 和 loadFactor 初始化每个segment,其中每个segment的阈值
threshold = cap * loadFactor。
③ ConcurrentHashMap的实例化
- ConcurrentHashMap使用默认构造函实例化,三个参数都使用默认初始值,
concurrencyLevel = 16,initialCapocity = 16,loadFactor = 0.75f。
ConcurrentMap<String, Long> wordCounts = new ConcurrentHashMap<>()
- 也可以指定
initialCapocity、loadFactor、concurrencyLevel的值:
new ConcurrentHashMap<>(initialCapocity)
new ConcurrentHashMap<>(initialCapocity, loadFactor)
new ConcurrentHashMap<>(initialCapocity, loadFactor, concurrencyLevel)
④ segment的定位和table中的定位
- 键值对要想存入ConcurrentHashMap中,必须先确定它所在的segment,然后确定它所在的HashEntry。
- ConcurrentHashMap使用 Wang/Jenkins hash 的变种算法对元素的 hashCode 进行一次再散列,确定键值对所在的segment。
- 再散列的目的: 通过让数字的每一位都参与到散列运算中,减少散列冲突,使元素能够均匀的分布在不同的segment中。
- 对散列后的hash值,计算segment的index:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
- 先对再散列的hash值进行无符号右移(
>>>),右移segmentShift那么多位,意思是让该值的高32 - segmentShift参与散列运算。 - 然后将无符号右移后的值与
segmentMask进行按位与,计算出键值对在segment中的位置。 - 按照默认初始值,
segmentShift = 32 - 4 = 28,segmentMask = 16 - 1 = 15。
- 键值对存放在HashEntry数组中的哪个位置,也是通过再散列的后值进行定位的。与segment的定位相比,是直接将再散列的hash值与数组长度减一相与。
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
3. ConcurrentHashMap的操作
① get操作
- get操作非常高效: 整个get操作的过程不需要加锁,除非读到的value为null才加锁。(
readValueUnderLock(e)) - get操作非常高效的原因:
- 将get操作中的共享变量count和value定义成volatile,使得它能够在线程之间保持可见性,能够多线程同时读,并且保证不会读到过期的值,但是只能单线程写。
- get操作只需要读不需要写共享变量count和value,因此不需要加锁。
- 定义成volatitle的变量既然能多线程同时读,单线程写,如果保证不会读到过期值?根据java 内存模型的 happens before 原则,对 volatile 字段的写入操作先于读操作,即使两个线程同时修改和获取 volatile 字段,get 操作也能拿到最新的值。
- get操作是volatile替换锁的经典场景。
- 注意: volatile变量要先赋值给局部变量,然后操作局部变量后,最后再写回volatile变量。因为,读写volatitle变量的开销很大。
public V get(Object key) {
// 对key的hashCode进行再散列,使元素均匀分布
int hash = hash(key.hashCode());
// 先定位segment,再获取元素
return segmentFor(hash).get(key, hash);
}
// 真正的get操作
V get(Object key, int hash) {
// count是一个volatile变量,每次put和remove之后的最后一步都要更新count
if (count != 0) {
HashEntry<K,V> e = getFirst(hash);// 定位桶下标
while (e != null) {
// 判断键相等:要求hash值相同且key相等
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // 加锁读
}
e = e.next;
}
}
return null;
}
HashEntry<K,V> getFirst(int hash) {
HashEntry<K,V>[] tab = table;
return tab[hash & (tab.length - 1)];
}
② put操作
- put操作需要对共享变量进行写入操作,为了保证线程安全,需要在操作共享变量时加锁。
- 先定segment,然后将键值对插入到segment中。
- 插入操作需要经历两个步骤:
- 先判断segment中的HashEntry数组是否需要扩容。即判断segment中的HashEntry数组是否超过容量阈值(
threshold)。 - 再定位键值对在HashEntry数组中的位置,然后插入到HashEntry数组中。
- segment的扩容与HashEntryMap相比:
- 扩容的时间不同: HashMap是先将键值对插入后,再判断是否需要进行扩容;而ConcurrentHashMap的segment是先判断是否需要扩容,再插入键值对。HashMap很可能在扩容之后没有键值对再插入,这时就进行了一次无效的扩容。
- 扩容倍数相同: segment的扩容也是将HashEntry数组容量扩大两倍。
- 扩容的范围不同: 为了高效, ConcurrentHashMap 不会对整个容器进行扩容,而只对某个 segment 进行扩容。
public V put(K key, V value) {
if (value == null)
throw new NullPointerException(); //明确指定value不能为null
int hash = hash(key.hashCode());
return segmentFor(hash).put(key, hash, value, false);
}
//真正的put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock(); // 对segment加锁,在finally中释放锁
try {
int c = count;// volatile变量,先赋值给局部变量,再读写。
if (c++ > threshold) // ensure capacity
rehash(); //判断容量,如果不够了就扩容
//table是volatile变量,读写volatile变量的开销很大
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1); //寻找table的下标
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
//遍历单链表,找到key相同的为止,或者直到链表结尾为止
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) { //如果有相同的key,那么直接替换
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else { //否则在链表表头插入新的结点
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- put方法的具体过程:
- 对整个segment加锁,
lock()。 - 先通过
c > threshold判断是否需要进行扩容,如果需要,调用rehash()方法进行扩容。 - 定位键值对在HashEntry数组中的位置,找到所在链表的表头:
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1); //寻找table的下标
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
- 遍历链表,直到找到相同的key,或者遍历到链表末尾。
- 如果存在相同的key,则更新value;否则,将键值对通过头插法插入到链表中。
- 在
finally语句块中,对整个segment进行解锁,unlock()。
③ size操作
- 每个 segment 维护了一个 count 变量,用于统计该 segment 中的键值对个数。
- 如果我们要统计整个 ConcurrentHashMap 里元素的大小,最直观的想法:将所有segment中的count值进行求和。
- 实际上,直接把所有 segment 的 count 相加得到的 ConcurrentHashMap 大小并不准确。
- ConcurrentHashMap 的解决办法:
- 先通过两次不加锁的方式,对segment中的count变量进行累加。
- 如果两次操作的结果不一致,则使用加锁的方式,对segment中的count变量进行累加。
- 两次操作结果不一致,是通过 modCount 变量进行判断的: 如果segment的modCount在第二次统计时和第一次统计时不一样,则直接退出统计,使用加锁的方式重新统计。
- modCount会在segment的
put,remove和clean方法中加一,直接判断统计前后的modCount值是否发生变化,就可以知道容器大小是否发生变化。
public int size() {
final Segment<K,V>[] segments = this.segments;
long sum = 0;
long check = 0;
int[] mc = new int[segments.length];
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
for (int k = 0; k < RETRIES_BEFORE_LOCK; ++k) {
check = 0;
sum = 0;
int mcsum = 0;
for (int i = 0; i < segments.length; ++i) {//第一次统计
sum += segments[i].count;
mcsum += mc[i] = segments[i].modCount;
}
if (mcsum != 0) {
for (int i = 0; i < segments.length; ++i) {//第二次统计
check += segments[i].count;
if (mc[i] != segments[i].modCount) {//modCount发生该变则结束当次尝试
check = -1; // force retry
break;
}
}
}
if (check == sum)
break;
}
if (check != sum) { // Resort to locking all segments
sum = 0;
for (int i = 0; i < segments.length; ++i)
segments[i].lock();
for (int i = 0; i < segments.length; ++i)
sum += segments[i].count;
for (int i = 0; i < segments.length; ++i)
segments[i].unlock();
}
if (sum > Integer.MAX_VALUE)
return Integer.MAX_VALUE;
else
return (int)sum;
}
④ 与Hashtable的比较
- 并发访问的实现不同、锁住的范围不同:
HashTable中get、put、remove、clear操作都是用synchronized关键字进行修饰,是对整个HashTable加锁。而ConcurrentHashMap在put、remove、clear操作中使用锁,只是对某个segment单独加锁。 - get操作是否支持同时读:
HashTable的get操作使用synchronized字修饰,因此不支持同时读。而ConcurrentHashMap的get操作在整个过程中不加锁,除非读到的value为null才加锁重读,支持同时读,而且保证不会读到过期值。(使用volatitle关键字代替锁的经典场景) - 并发访问率: 某个线程占用锁访问
HashTable的同步方法,其他线程也访问HashTable的同步方法,必须进入阻塞状态,等待锁的释放。而某个线程占用锁访问ConcurrentHashMap中的某个segment,其他线程可以访问ConcurrentHashMap的其他segment。
4. ConcurrentHashMap在JDK1.8中的变化
- 锁机制的变化:
- JDK 1.7 使用锁分段技术实现并发更新操作,核心类为 Segment,它继承自可重入锁
ReentrantLock,并发度与 Segment 数量相等。 - JDK 1.8 使用了 CAS 操作来支持更高的并发度,在 CAS 操作失败时使用内置锁 synchronized。
- 结构的变化:
- JDK1.7中,HashEntry数组与JDK1.7中的HashMap一样,采用数组 + 链表的方式。
- JDK 1.8 中,没有使用segment,而且HashEntry数组与JDK1.8中一致,采用数组 + 链表 + 红黑树的方式。
- 链表长度大于等于8,链表转为红黑树;结点数小于等于6,红黑树转回链表。
5. 常见的问题
1. HashMap,HashTable,三者的区别,底层源码
- 从为什么要使用
ConcurrentHashMap入手:HashMap线程不安全,HashTable效率低下,ConcurrentHashMap锁分段技术提高并发访问率。 - 底层源码:讲解
ConcurrentHashMap的结构、HashTable的put、get、remove、clear操作使用synchronized关键字修饰。
2. JDK1.7中ConcurrentHashMap的size()操作
- 两次不加锁的方式进行统计,如果统计结果不一致,使用加锁的方式重新统计。
3. HashMap与ConcurrentHashMap的区别
- HashMap非线程安全,并发执行put操作容易形成链表死循环;
ConcurrentHashMap支持多线程的并发访问:ConcurrentHashMap的锁分段技术 - HashMap先插入元素再扩容,ConcurrentHashMap先扩容再插入。
- HashMap如何转化为线程安全的:① 使用Collections.synchronized(hashMap); ② 直接使用ConcurrentHashMap。
4. ConcurrentHashMap源码实现
ConcurrentHashMap锁分段技术、初始化过程、get操作、put操作、size操作
5. ConcurrentHashMap与HashTable在性能上的差异?形成差异的原因?
- HashTable使用
synchronized关键字实现并发访问时的线程安全,效率低下。 ConcurrentHashMap使用锁分段机制实现并发访问,提高了并发访问率。
6. JDK1.7和JDK1.8中,ConcurrentHashMap的区别
- 锁机制的变化、结构的变化