JDK源码阅读计划(Day10) ConcurrentHashMap 扩容,计数部分
扩容
Hash表的扩容一般分为:
哈希数组的扩容
一般是建立一个原来数组大小两倍的数组,通常由单线程完成
数据迁移
把旧数组中的各个槽的结点重新分配到新的table中。通常涉及到Key值的rehash
而HashMap与ConcurrentHashMap并不会重新计算每个key的hash值,而是数组扩容后,新的索引要么在原idx,要么在idx+n(n为扩容前数组容量)
这种处理方式的好处:
方便多线程同时进行数据迁移。可以把整个哈希数组划分为多个部分,每一个部分包含一定区间需要迁移的桶,每个线程分别处理其要负责的桶。
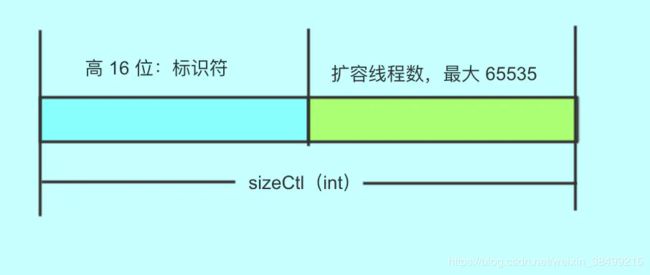
sizeCtl
-1 :代表table正在初始化,其他线程应该交出CPU时间片
-N: 表示正有N-1个线程执行扩容操作(高 16 位是 length 生成的标识符,低 16 位是扩容的线程数)
大于 0: 如果table已经初始化,代表table容量,默认为table大小的0.75,如果还未初始化,代表需要初始化的大小
何时发生扩容
我们看回treeifyBin函数
// 哈希数组的容量还未达到形成一棵红黑树的最低要求
if((n = tab.length)<MIN_TREEIFY_CAPACITY) {
// 尝试调整哈希数组的大小,以容纳指定数量的元素(默认增加一倍)
tryPresize(n << 1);
如果你只知道背面试题的话都会知道链表数目大于>=8就会转成红黑树。事实上这是不严谨的说法,只有在哈希数组容量大于等于64并且链表数目大于等于8才会转成红黑树。
否则会使用扩容哈希数组的方法来解决问题!
tryPresize方法
总结:
-
CASE1:
如果数组尚未初始化,或者容量无效,需要初始化一个哈希数组,并且CAS保证只有一个线程能够执行数组内存分配 -
CASE2:
如果预备扩容到的目标容量小于阙值(无需扩容),或者哈希数组当前容量已达上限(无法扩容),直接退出 -
CASE3:
CAS保证只有一条线程执行transfer, 同时使用一个经过移位处理的数组容量的stamp来唯一标识该次扩容。
// 尝试调整哈希数组的大小,以容纳指定数量的元素
private final void tryPresize(int size) {
// 预备扩容到的目标容量
int cap = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY // 如果哈希数组容量已经为最大容量的一半,则直接使用最大容量
: tableSizeFor(size + (size >>> 1) + 1); // 理想情形下,哈希数组容量增加0.5倍
int sc;
while((sc = sizeCtl) >= 0) {
Node<K, V>[] tab = table;
int len;
// 如果哈希数组还未初始化,或者容量无效,则需要初始化一个哈希数组
if(tab == null || (len = tab.length) == 0) {
// 确定待扩容的新容量
len = Math.max(sc, cap);
// 原子地将sizeCtl字段更新为-1,代表当前Map进入了初始化哈希数组的阶段
if(U.compareAndSetInt(this, SIZECTL, sc, -1)) {
try {
if(table == tab) {
@SuppressWarnings("unchecked")
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[len];
table = nt;
// 确定容量阙值为0.75*容量
sc = len - (len >>> 2);
}
} finally {
// 恢复sizeCtl标记为非负数
sizeCtl = sc;
}
}
// 在哈希数组已经初始化的情形下:如果预备扩容到的目标容量小于阙值(无需扩容),或者哈希数组当前容量已达上限(无法扩容),直接退出
} else if(cap<=sc || len >= MAXIMUM_CAPACITY) {
break;
// 如果需要扩容
} else if(tab == table) {
// 移位操作生成一个唯一的标记此次扩容的标志
int stamp = resizeStamp(len) << RESIZE_STAMP_SHIFT;
//CAS操作保证只有一个线程执行扩容
if(U.compareAndSetInt(this, SIZECTL, sc, stamp + 2)) {
transfer(tab, null);
}
}
}
}
transfer方法
/**
* 扩容时需要用到的一个下标变量.
*/
private transient volatile int transferIndex;
用到一个volatile修饰的变量,其中[transferIndex-bound, transferIndex-1] 表示当前进行数据迁移的桶区间
int n = tab.length;
int stride = (NCPU>1) ? (n >>> 3) / NCPU : n;
// 每个线程至少负责16个桶的迁移
if(stride<MIN_TRANSFER_STRIDE) {
stride = MIN_TRANSFER_STRIDE; // subdivide range
}
首先要计算stride,即每个线程负责的迁移的桶的数目
if(nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K, V>[] nt = (Node<K, V>[]) new Node<?, ?>[n << 1];
nextTab = nt;
} catch(Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
如果数组为空,则初始化为2倍
while(true) {
Node<K, V> f;
int fh;
//定位本轮处理的桶区间
while(advance) {
int nextIndex;
int nextBound;
if(--i >= bound || finishing) {
advance = false;
} else if((nextIndex = transferIndex)<=0) {
i = -1;
advance = false;
//预处理完成后:i == transferIndex-1,bound == transferIndex-stride
} else if(U.compareAndSetInt(this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex>stride ? nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
整个数据迁移过程是在一个大的while自旋进行的,其中每一次进行桶的迁移前都要进行上述预处理,即定位好bound和nextIndex,区间[transferIndex-stride]即本次需要迁移的区间
然后迁移具体有4种case:
CASE1: 当前是最后一个迁移任务或出现扩容冲突
if(i<0 || i >= n || i + n >= nextn) {
int sc;
if(finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 扩容线程数减1,表示当前线程已完成自己的transfer任务
if(U.compareAndSetInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
int stamp = resizeStamp(n) << RESIZE_STAMP_SHIFT;
//如果出现了扩容冲突,则本线程直接结束工作
if((sc - 2) != stamp) {
return;
}
finishing = advance = true;
i = n; // recheck before commit
}
CASE2: 桶为空,CAS原子更新其为占位结点
else if((f = tabAt(tab, i)) == null) {
// 原子地更新tab[i]为fwd
advance = casTabAt(tab, i, null, fwd);
CASE3:桶table[i]已迁移完成
桶已经用ForwardingNode结点占用了,表示该桶的数据都迁移完了。
else if((fh = f.hash) == MOVED) {
advance = true; // already processed
CASE4: 桶table[i]未迁移完成
分为链表迁移和红黑树迁移两种情况讨论
链表迁移:
synchronized(f) {
//double check
if(tabAt(tab, i) == f) {
Node<K, V> ln, hn;
//普通链表情况
if(fh >= 0) {
// n为2的幂次方,所以runBit要么为1要么为0
int runBit = fh & n;
// lastRun为从头节点开始遍历的第一个与头节点runBit不同的结点,作为划分的新节点的头节点
Node<K, V> lastRun = f;
for(Node<K, V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if(b != runBit) {
runBit = b;
lastRun = p;
}
}
if(runBit == 0) {
ln = lastRun;
hn = null;
} else {
hn = lastRun;
ln = null;
}
for(Node<K, V> p = f; p != lastRun; p = p.next) {
int ph = p.hash;
K pk = p.key;
V pv = p.val;
//根据hash值与n与操作划分链表
if((ph & n) == 0) {
ln = new Node<K, V>(ph, pk, pv, ln);
} else {
hn = new Node<K, V>(ph, pk, pv, hn);
}
}
// nextTab[i]=ln
setTabAt(nextTab, i, ln);
// nextTab[i+n]=hn
setTabAt(nextTab, i + n, hn);
// tab[i]=fwd
setTabAt(tab, i, fwd);
//迁移完成
advance = true;
红黑树迁移:
else if(f instanceof TreeBin) {
//t为原来的treeBin
TreeBin<K, V> t = (TreeBin<K, V>) f;
//新红黑子树1的头,尾
TreeNode<K, V> lo = null, loTail = null;
//新红黑子树2的头,尾
TreeNode<K, V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for(Node<K, V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K, V> p = new TreeNode<K, V>(h, e.key, e.val, null, null);
if((h & n) == 0) {
if((p.prev = loTail) == null) {
lo = p;
} else {
loTail.next = p;
}
loTail = p;
++lc;
} else {
if((p.prev = hiTail) == null) {
hi = p;
} else {
hiTail.next = p;
}
hiTail = p;
++hc;
}
}
//如果分裂后的红黑树数目少于6则变回链表,如果另一个红黑树为空,那么还是用原来的TreeBin,否则红黑树的根节点变为TreeBin
ln = (lc<=UNTREEIFY_THRESHOLD) ? untreeify(lo) : (hc != 0) ? new TreeBin<K, V>(lo) : t;
hn = (hc<=UNTREEIFY_THRESHOLD) ? untreeify(hi) : (lc != 0) ? new TreeBin<K, V>(hi) : t;
// nextTab[i]=ln
setTabAt(nextTab, i, ln);
// nextTab[i+n]=hn
setTabAt(nextTab, i + n, hn);
// tab[i]=fwd
setTabAt(tab, i, fwd);
advance = true;
helpTransfer
在调用如putVal,clear等方法时,如果当前线程发现哈希数组正在扩容(桶元素的哈希值=MOVED),将会调用helpTransfer方法加快扩容
// 加速扩容过程
final Node<K, V>[] helpTransfer(Node<K, V>[] tab, Node<K, V> f) {
Node<K, V>[] nextTab;
int sc;
if(tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode<K, V>) f).nextTable) != null) {
//rs是一个负数
int rs = resizeStamp(tab.length) << RESIZE_STAMP_SHIFT;
//sc<0 -> 正在扩容
while(nextTab == nextTable && table == tab && (sc = sizeCtl)<0) {
if((sc >>> RESIZE_STAMP_SHIFT) != rs //当前sizeCtl标识符不相同,说明标识符发生了变化
|| sc == rs + 1
|| sc == rs + MAX_RESIZERS //达到了最大扩容线程的数量
|| transferIndex<=0) { //扩容结束
break;
}
//CAS源自增加一个扩容线程,本线程再调用一个transfer函数
if(U.compareAndSetInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nextTab);
break;
}
}
return nextTab;
}
return table;
}
size方法
public int size() {
long n = sumCount();
return ((n<0L) ? 0 : (n>(long) Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int) n);
}
但是map的容量有可能会超过int范围,因此1.8之后建议采用如下方法替代size
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n; // ignore transient negative values
}
核心都是sumCount方法
final long sumCount() {
CounterCell[] cs = counterCells;
long sum = baseCount;
if(cs != null) {
for(CounterCell c : cs) {
if(c != null) {
sum += c.value;
}
}
}
return sum;
}
这里用到了两个成员:baseCount和counterCells
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
//没有竞争时候的计数
private transient volatile long baseCount;
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;
这个CounterCell是什么意思啊?注释说这是改编自LongAdder与Striped64,
/**
* A padded cell for distributing counts. Adapted from LongAdder
* and Striped64. See their internal docs for explanation.
*/
@jdk.internal.vm.annotation.Contended
static final class CounterCell {
volatile long value;
CounterCell(long x) {
value = x;
}
}
这里的注解:避免伪共享问题,这个注解的作用是可以把缓存行填满,防止多个变量共享一个缓存行,避免修改互相独立的变量时候频繁发生缓存抖动影响性能
addCount方法
额外提一句,我参考https://www.jianshu.com/p/749d1b8db066
阅读源码的时候,发现评论区有人提出
( sc == rs + 1 || sc == rs + MAX_RESIZERS) 其实是dead code,并且给Oracle发了PR把这个bug改过来。作者还专门在stackoverflow发帖,可以下:
传送门:https://stackoverflow.com/questions/53493706/how-the-conditions-sc-rs-1-sc-rs-max-resizers-can-be-achieved-in
另外这位仁兄也提出了这个问题:
https://www.cnblogs.com/christmad/p/11385863.html
private final void addCount(long x, int check) {
CounterCell[] cs;
long b, s;
// 如果counterCells不为空或者修改baseCount失败
if((cs = counterCells) != null || !U.compareAndSetLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell c;
long v;
int m;
boolean uncontended = true;
if(cs == null //如果counterCell为空
|| (m = cs.length - 1)<0 // counterCell 大小为0
|| (c = cs[ThreadLocalRandom.getProbe() & m]) == null ////随机取余一个数组位置为空
|| !(uncontended = U.compareAndSetLong(c, CELLVALUE, v = c.value, v + x))) //CAS失败,说明出现并发
{
fullAddCount(x, uncontended);
return;
}
if(check<=1) {
return;
}
s = sumCount();
}
//如果需要检查,检查其是否需要扩容,putVal方法默认要检查
if(check >= 0) {
Node<K, V>[] tab, nt;
int n, sc;
while(s >= (long) (sc = sizeCtl) //map的大小 大于 sizeCtl
&& (tab = table) != null //table不为空
&& (n = tab.length)<MAXIMUM_CAPACITY) //table长度小于 1<<30
{
int rs = resizeStamp(n) << RESIZE_STAMP_SHIFT; // JDK12应该是这样子,JDK11没有左移操作
// sc < 0 表示正在扩容
if(sc<0) {
if((sc >>> RESIZE_STAMP_SHIFT) != rs //sc的低16位与标识符不同,说明sc发生了变化!
|| sc == rs + 1 //你看看最后一个else if,如果是第一个扩容的线程,会设置sc=rs+2,结束之后sc--,就变成了rs+1,因此这个条件就是说扩容结束了
|| sc == rs + MAX_RESIZERS //帮助扩容线程数量达到了最大
|| (nt = nextTable) == null //3857行表明结束后nextTable就是null,这里判断条件表示扩容结束
|| transferIndex<=0) //transferIndex只在transfer发生变化,意味着数组容量发生了变化
{
break;
}
//竞争成为帮助扩容的线程
if(U.compareAndSetInt(this, SIZECTL, sc, sc + 1)) {
transfer(tab, nt);
}
//竞争成为第一个进行扩容的线程
} else if(U.compareAndSetInt(this, SIZECTL, sc, rs + 2)) {
transfer(tab, null);
}
s = sumCount();
}
}
}
ref
CHM的扩容
https://www.jianshu.com/p/39b747c99d32
https://www.jianshu.com/p/88881fdfcf4c
https://www.jianshu.com/p/749d1b8db066