SparkContext详解
官方解释:SparkContext是spark功能的主要入口。其代表与spark集群的连接,能够用来在集群上创建RDD、累加器、广播变量。每个JVM里只能存在一个处于激活状态的SparkContext,在创建新的SparkContext之前必须调用stop()来关闭之前的SparkContext。
下面我们看下SparkContext究竟有什么作用:
首先,每一个Spark应用都是一个SparkContext实例,可以理解为一个SparkContext就是一个spark application的生命周期,一旦SparkContext创建之后,就可以用这个SparkContext来创建RDD、累加器、广播变量,并且可以通过SparkContext访问Spark的服务,运行任务。spark context设置内部服务,并建立与spark执行环境的连接。
先来看一个spark架构组成图
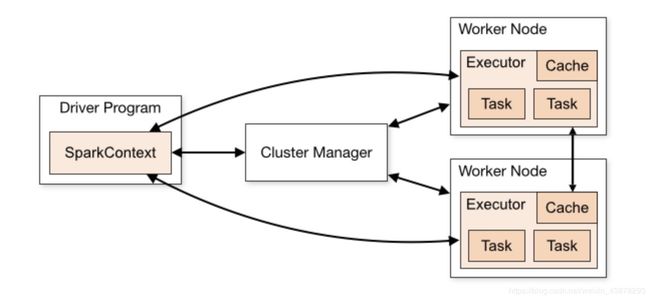
再结合下一张图,SparkContext组成

通过这两张图我们不难发现,SparkContext在spark应用中起到了master的作用,掌控了所有Spark的生命活动,统筹全局,除了具体的任务在executor中执行,其他的任务调度、提交、监控、RDD管理等关键活动均由SparkContext主体来完成。
一、SparkContext提供的功能
1、获取spark应用的当前状态
-SparkEnv
-SparkConf
-部署环境master URL
-应用名称
-任务执行的唯一标识符
-部署模式
-应用执行的默认并行度(指明在未显示指定分区数的情况下的RDDs分区)
-Spark 用户
-SparkContext创建后的持续时间(ms)
-web UI 的URL
-Spark 版本
-存储状态
2、配置
-master URL
-本地属性,创建物理工作组(为了让不同线程launch的分离的任务归属于同一个组)
-设置log等级
3、创建分布式的实体
-RDDs
-Accumulators
-Broadcast Variables
4、访问服务,例如 AppStatusStore, TaskScheduler, LiveListenerBus, BlockManager, SchedulerBackends, ShuffleManager 和 可选的ContextCleaner服务.
5、同步运行jobs
6、异步提交jobs
7、取消job
8、取消stage
9、分配自定义的Scheduler Backend, TaskScheduler and DAGScheduler
10、清理闭包(spark在序列化和通过线路发送到执行环境之前清理闭包,即清理动作的主体)
11、访问持久化的RDDs
12、将持久化的RDDs去持久化
13、注册SparkListener
14、动态内存分配
二、SparkContext维护了很多私有变量用来维护SparkContext的内部状态
private var _conf: SparkConf = _
private var _eventLogDir: Option[URI] = None
private var _eventLogCodec: Option[String] = None
private var _listenerBus: LiveListenerBus = _
private var _env: SparkEnv = _
private var _statusTracker: SparkStatusTracker = _
private var _progressBar: Option[ConsoleProgressBar] = None
private var _ui: Option[SparkUI] = None
private var _hadoopConfiguration: Configuration = _
private var _executorMemory: Int = _
private var _schedulerBackend: SchedulerBackend = _
private var _taskScheduler: TaskScheduler = _
private var _heartbeatReceiver: RpcEndpointRef = _
@volatile private var _dagScheduler: DAGScheduler = _
private var _applicationId: String = _
private var _applicationAttemptId: Option[String] = None
private var _eventLogger: Option[EventLoggingListener] = None
private var _executorAllocationManager: Option[ExecutorAllocationManager] = None
private var _cleaner: Option[ContextCleaner] = None
private var _listenerBusStarted: Boolean = false
private var _jars: Seq[String] = _
private var _files: Seq[String] = _
private var _shutdownHookRef: AnyRef = _
private var _statusStore: AppStatusStore = _
这些对象都是要在SparkContext里进行初始化和关闭的。下面对这里的一些比较核心的对象做些说明。
1、SparkEnv
这个对象持有一个运行着的spark实例的所有运行时环境对象。不论是master还是worker节点。注意,源代码中标识的是所有,这意味这通过SparkEnv对象就可以掌握Spark的所有运行时信息。我们可以通过SparkEnv中拥有的对象来窥得一些有用的信息。
class SparkEnv (
val executorId: String,
private[spark] val rpcEnv: RpcEnv,
val serializer: Serializer,
val closureSerializer: Serializer,
val serializerManager: SerializerManager,
val mapOutputTracker: MapOutputTracker,
val shuffleManager: ShuffleManager,
val broadcastManager: BroadcastManager,
val blockManager: BlockManager,
val securityManager: SecurityManager,
val metricsSystem: MetricsSystem,
val memoryManager: MemoryManager,
val outputCommitCoordinator: OutputCommitCoordinator,
val conf: SparkConf) extends Logging
目前(截至最新2.4.3版本)SparkEnv还是作为全局变量来实现的,可通过SparkEnv.get来获取。虽说是全局变量,但并不是用来给外界使用的,官方也说在将来的版本中可能改成private形式。
2、TaskScheduler
显然,这是用来做任务调度用的。不过是一个低级的程序调度接口,目前仅由
- [ 后边的文章再讨论] TaskSchedulerImpl
实现该接口。任务从DAGScheduler发过来,每次发给TaskScheduler的是已经被DAGScheduler划分为不同stage的每个stage的任务集TaskSets。TaskScheduler在接收到任务之后,会将他们发送到集群并运行他们,并监控运行的任务,当任务失败会重试and mitigating stragglers。TaskScheduler会给DAGScheduler返回event。
3、DAGScheduler
DAGScheduler介绍
这在spark中是个相当重要的角色。作为一个高级调度层,在stage级别进行调度。DAGScheduler将一个job划分成不同的stage,并且持续跟踪哪些RDD与stage输出有实质的对应关系。然后据此找出最优的调度方案来运行该job。划分好stage之后,DAGScheduler将stage作为TaskSets提交给TaskScheduler。这里应该关注的是DAGScheduler是将不同的stage作为任务集来提交的,而且每个TaskSet任务集中的任务是相互独立的,也就是说这些任务可以基于集群上的已有数据直接运行。
stage划分
DAGScheduler将任务划分为不同stage的依据是宽依赖和窄依赖。判断是宽依赖和窄依赖可以依据是否有shuffle操作来进行。任务执行过程中有shuffle操作的就是宽依赖,这样的任务得划分到不同的stage,一个写出map output file,另一个读取这些输出文件做进一步处理。而不存在shuffle操作的可以组合成一组任务作为一个stage来执行。
还可以从父RDD和子RDD之间的依赖关系来确定是宽依赖还是窄依赖,通常RDD是有多个分区的,被用来当输入的RDD作为父RDD,对这些分区进行计算转换等操作后生成新的RDD(子),如果父RDD中的一个分区只与子RDD中的一个分区对应,这就是窄依赖。如果父RDD中的一个分区,会与多个子RDD中的分区相对应,这就是宽依赖。所以,本质上还是有没有shuffle。
除此之外,DAGScheduler还决定运行任务的最佳位置,它将当前的缓存状态传递给TaskScheduler,然后TaskScheduler据此提交任务。
另外,由shuffle file丢失造成的任务执行失败也由DAGScheduler来处理,这种情况需要该stage依赖的上一个stage被重新提交计算。不是由shuffle 文件丢失造成的stage内部的任务失败则由TaskScheduler处理,会进行重试,这种失败重试会进行多次,直到失败超过次数导致该stage被取消。
下面来看看失败重试中DAGScheduler所起的作用
上面说到当失败是由于map output file lost导致的时候,需要DAGScheduler提交lost stage重新计算。那么这种错误在spark中是怎么发现的呢?源码中讲到了,通过Event,具体为CompletionEvent with FetchFailed和 ExecutorLost Event,前边讲到TaskScheduler在任务监控中会通过Event向DAGScheduler返回信息。在任务提交计算之后,DAGScheduler会等待一定的时间来看是否有node或者任务失败,如果有,就提交lost stage的任务集重新计算。这个时候,之前已经完成的stage 对象必须被重新创建,因为在stage 对应的任务集跑完之后,对应的stage 对象就被清理了。需要注意的是,在映射从stage接收的Event的时候需要格外小心,因为之前old stage的重试任务可能仍在运行。
后边的文章中会有更多关于Spark的文章,希望通过阅读英文原版的Spark论文和源码来更加贴近Spark这一优秀计算框架的思想。如果阅读的小伙伴发现有错误请帮忙指出,将在后续的文章中加以改正。
参阅文档:
https://jaceklaskowski.gitbooks.io/mastering-apache-spark/spark-SparkContext.html