Flink on zeppelin 结合kafka实时计算pv uv写入mysql
上一篇文章主要介绍了Flink on zeppelin的安装和使用,配置了yarn的模式跑通了一个streaming wordcount的例子,本文主要介绍结合kafka的使用,实时计算一个简单的pv,uv把结果写入到mysql的例子.
添加依赖包
首先需要添加kafka以及mysql的jar包,有两种方式,第一种是直接把jar包添加到Flink的lib下面,如下所示:

只需要添加 flink-sql-connector-kafka_2.11-1.11.0.jar , flink-json-1.11.0.jar , flink-jdbc_2.11-1.10.1.jar , mysql-connector-java-5.1.47.jar 这4个jar包就可以了,我加的比较多是别的地方用到了,用不到的可以不用加防止出现jar包冲突的问题.
第二种是在zeppelin的UI上运行添加依赖包的命令,添加的格式如下所示,
flink.execution.packages groupId:artifactId:version 然后点击运行就可以了,执行完后需要重启一下 interpreter.
%flink.conf
flink.execution.packages org.apache.flink:flink-jdbc_2.11:1.10.1
flink.execution.packages 这个配置也类似flink.execution.jars,但它不是用来指定jar包,而是用来指定package的。Zeppelin会下载这个package以及这个package的依赖,并且放到flink interpreter的classpath上。如果需要添加多个依赖的话,中间用逗号隔开就可以了.
创建表
先来创建一个kafka的流表,SQL语句如下所示.
%flink.ssql
DROP TABLE IF EXISTS kafka_table;
CREATE TABLE kafka_table (
name VARCHAR COMMENT '姓名',
age int COMMENT '年龄',
city VARCHAR,
borth VARCHAR,
ts BIGINT COMMENT '时间戳',
t as TO_TIMESTAMP(FROM_UNIXTIME(ts/1000,'yyyy-MM-dd HH:mm:ss')),
proctime as PROCTIME(),
WATERMARK FOR t AS t - INTERVAL '5' SECOND
)
WITH (
'connector' = 'kafka', -- 使用 kafka connector
'topic' = 'jason_flink', -- kafka topic
'scan.startup.mode' = 'latest-offset', -- 从起始 offset 开始读取
'properties.bootstrap.servers' = 'master:9092,storm1:9092,storm2:9092', -- broker连接信息
'properties.group.id' = 'jason_flink_test',
'scan.startup.mode' = 'latest-offset', -- 读取数据的位置
'format' = 'json' -- 数据源格式为 json
)
这里使用的是Flink1.11.0的版本,所以Connector 的参数个数已经变了,虽然现在也兼容老的写法,不过还是建议使用新版本的写法,这样更加的简洁,然后可以先执行一下查询kafka表的SQL看一下是否可以获取到数据.

数据正常的打印出来了,说明是可以接收到数据的.然后继续创建一个mysql的结果表.
%flink.ssql
drop table if EXISTS a;
CREATE TABLE a (
name STRING,
pv INT not null,
uv INT not null,
t_start TIMESTAMP(3),
t_end TIMESTAMP(3),
PRIMARY KEY (name) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/test',
'table-name' = 'a',
'username' = 'mysql',
'password' = '12345678'
)
这里先执行一下show tables也可以看到刚才创建的2个表

执行SQL
然后就可以做一个简单的基于滚动窗口的pv,uv的统计了,SQL语句非常的简单,这里要注意的是query的字段类型要和sink的字段类型保持一致,否则会报字段类型不匹配的错.
%flink.ssql(type=update,parallelism=4)
insert into a
select name,
cast(count(name) as INT) as pv,
cast(count(distinct name) as INT) as uv,
TUMBLE_START(t, INTERVAL '5' second) as t_start,
TUMBLE_END(t, INTERVAL '5' second) as t_end
from kafka_table
group by name,TUMBLE(t, INTERVAL '5' second);
点击右上角的Flink Job,就可以调到Flink的UI页面看到Job运行的情况了.

从上面的records received和records send能看到数据进来了.最后再来看一下mysql里面是否有数据.
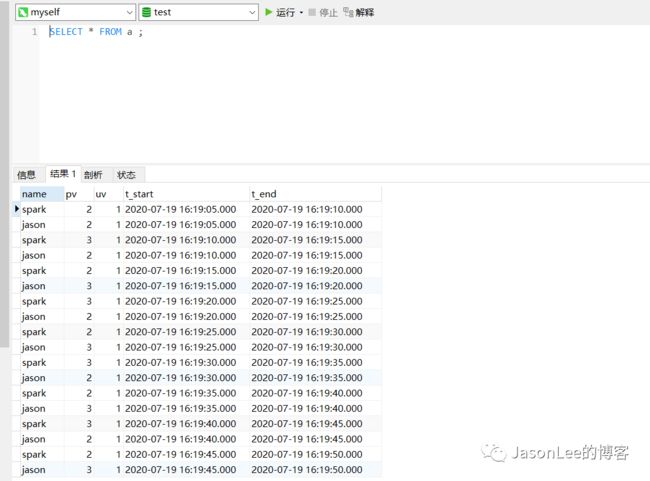
后面会介绍使用Flink on zeppelin实现更多的场景,大家可以持续关注一下.
推荐阅读:
Flink on zepplien的使用体验
JasonLee,公众号:JasonLee的博客Flink on zepplien的使用体验
更多spark和flink的内容可以关注下面的公众号
