2019JDATA店铺购买预测大赛复盘(冠军方案分析+比赛记录)
19年JDATA比赛在李哥,曹哥,以及和俞兄,室友共同努力下取得不错的成绩。这也是笔者第一次体验面向业务的数据挖掘流程,学习如何结合业务去做数据分析和建模,感觉和在实验室跑UCI数据集区别挺大的。写这篇文章好好复盘一下比赛的经历,为感兴趣的小伙伴提供一些参考,也是对自己的一个总结。文章主要包括赛题解读,数据探索(为了保证能让读者更加清楚了解数据特点,数据探索部分有引用了其他队伍的比较具有参考价值的数据图并给出了引用链接),数据集划分,特征构建,解题方案,模型设计和赛后总结。
#2020.6.4更新 为了刚入门比赛的小伙伴提供更详细的参考,整理了一下比赛的日志贴到了文章末尾。
比赛链接:https://jdata.jd.com/html/detail.html?id=8
赛题解读:
目标
提供 2018-02-01 到 2018-04-15 用户行为数据。需要对 2018-04-16 到 2018-04-22 用户对品类下店铺的购买进行预测。以 user_id, cate 和 user_id(用户id), cate(商品种类), shop_id(店铺id) F-SCORE 的加权组合作为最终评分。
评估指标

F11是对user_id, cate组合进行评估,F12是对user_id, cate,shop_id组合进行评估
业务场景及其几种解决方案
根据赛题描述和业务场景可推测,在目标区间购买的行为应该由两部分组成:一部分为复购行为,一部分为即时性购买。
解题思路有如下几种:
1. 直接对 user_id, cate, shop_id, sku_id 进行建模得到 user_id, cate, shop_id 组合。
2. 直接对 user_id, cate, shop_id 建模。
3. 对 user_id, cate 进行建模,也对 user_id,cate,shop_id 进行建模,组合两个结果得到最后的结果。
4. 先对 user_id, cate 组合建模进行召回再对 user_id, cate, shop_id 建模。
在后续过程中会介绍模型选择的思路并给出我们选择方案4的理由
数据探索
用户行为序列分析(1浏览,2下单,3关注,4加购,5评论)
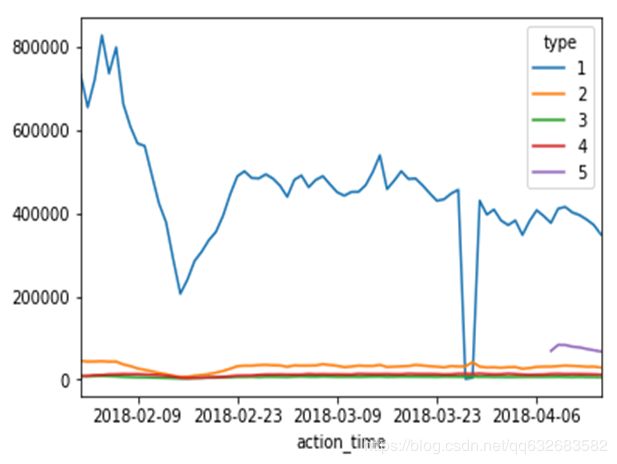
- 春节时段用户行为数据是有异常的(比如浏览,下单数减少,推测是用户春节聚会活动使用app时间减少,在春节前年货促销活动时已经完成了大部分购买等原因导致),出于分布一致性考虑,在后面建模中会避免使用到这段数据
- 3月27日和3月28日两天浏览数据异常低而购买量增加(推测浏览数据没有正常采集和有一波小促销活动),这一点在构建特征时需要特别考虑
- 用户行为中的type=5的情况(加入购物车)仅在4.08之后出现,这个是一个难点,影响到后面特征和数据集的构建
有交互行为用户占全部购买比(该图引用自 https://github.com/DuncanZhou/jdata2019)

蓝色表示每天的产生下单的购买数。B040?表示那天有行为的用户的每天的下单样本数,可以发现的是存在大量的用户是缺少历史行为的。召回率存在上限。注:就我们看来,在本次比赛中缺少历史交互的购买行为几乎是无法预测到的(如果有更多场景下的数据其实也可以考虑尝试协同过滤等基于相似度推荐的做法),我们的目的是尽可能地捕捉到到目标区间前发生交互行为的用户的购买可能性,而这个用户候选集的区间选择要结合购买趋势来分析,在A榜前期我们尝试了购买区间前1,3,5,7天等时间段的候选区间,将1天变为3天线上排名上升不少,但是继续增多反而下降,这其实就是关于precision和recall指标的一个权衡,增加候选集recall会升高但是precision会下降。当然区间覆盖度也会影响到模型的泛化性能,有候选时间区间比较小的队伍A榜在前10,B榜翻车了,所以一定要注意过拟合问题
物品复购率分析
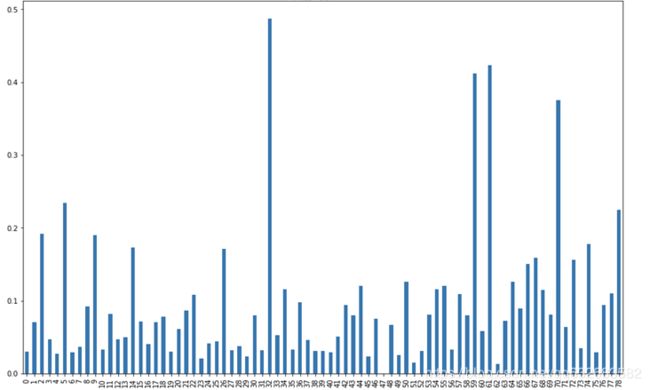
不同的类别在复购率上具有明显的差异,这验证了我们在上面对于业务场景的推测,即存在着即时购买(复购率低)和日用购买(复购率高)的行为。
用户购买累计分布图(同日购买同一商品超过2次按刷单用户过滤后统计得到)
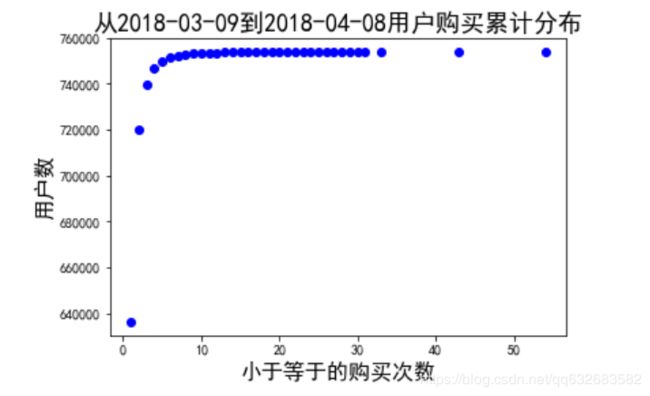
大部分用户购买次数在4次以内,基本符合普通消费习惯。我们还发现一些特点,例如对于一个月内每天购买不多,但是总购买次数很多的用户可能是剁手党或者炒信用户,这种特征在建模的时候可以考虑进来。
用户平均商品复购的时间
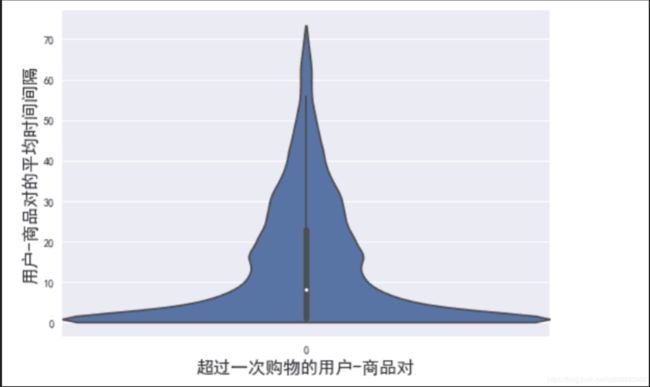
用户平均复购时间为14天,这一点为候选区间的选择提供了一定的参考,候选区间不能设置太小,不然很多用户会覆盖不到
在目标区间购买样本在目标区间前的交互情况
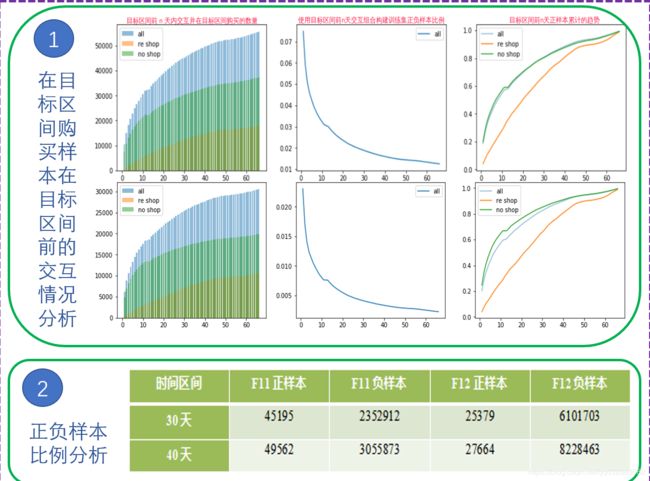
- 在目标区间点购买由两部分组成一部分为复购,一部分为即时性购买并且即时性购买远多于复购行为。
- 复购和及时性购买增长不一致。从re_shop该曲线在目标区间10多天时已经达到0.6可得知及时性购买以近期的交互为主。
- user_id, cate 和 user_id, cate, shop_id 的增长情况非常一致,统计发现许多用户在目标类目选择了前面有交互的店铺进行购买,但是仍然存在换店铺购买的情况。
目标区间未交互的店铺购买分析


可以看到仍然有相当的品类,用户在购买前是没有过店铺交互行为,通过这个现象加上上面客户换店铺购买的可能性,我们在F12指标上提出了top店铺召回策略,正样本数量得到明显增加,并且该策略被证实是有效的。
异常数据分析

用户短时间内对一个产品重复下单,在type=2的数据中这种出现还比较多。我们对于这种情况复购率进行了统计,复购率在1.5%。考虑到这种情况的影响,一方面会影响到后续购买时间间隔和复购率的计算,另外如果时针对sku建模,那么这种复购很低的sku会使模型偏向于即时购买,接下来我们统计了cate和shop的复购率,在10%左右,根据这个情况,我们决定取消针对sku_id进行建模,把重点放在cate和shop上面,去掉sku_id后,cate直接变成了强特,模型线上性能有所提升。
数据集划分

关于时序数据,一定要注意好数据穿越数据泄露的问题,比如在比赛前期我们有对3,4月份的数据采用sklearn进行交叉验证,这使得训练集和验证集会同时包含3,4月份数据,线下效果不错,线上效果下降,这个原因可能就是4月份的数据穿越到了训练集导致过拟合问题,更加科学的做法是要训练集和验证集“分离”,比如训练用3月,验证用4月就不会出现上述问题。
特征构建

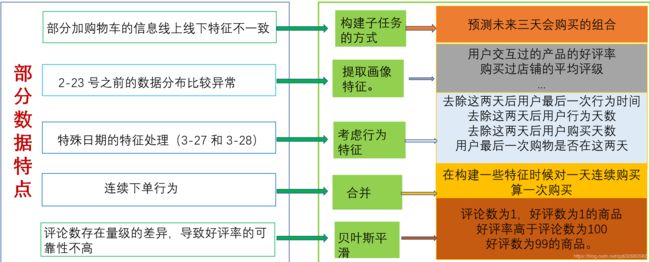
这里要说明的是,前期通过实验提取出来比较强的特征有用户评论,商品品类,涨粉速度这些,后期没有多余时间做特征筛选和交叉,应该也有比较大的提升空间。
解题方案
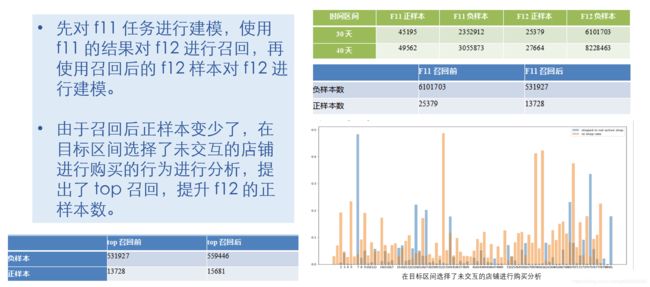
使用未交互的店铺进行召回这一策略受到评委老师的好评,因为相当于对目标区间未交互过的user,shop对提出了购买的推测,而且根据日常经验,会存在着人们浏览了一些店铺,然后过两天选另外的优质店铺购买的情况(对应于赛题场景就是用户在目标区间前没有互动过,但是在目标区间内购买了)
模型设计


模型融合
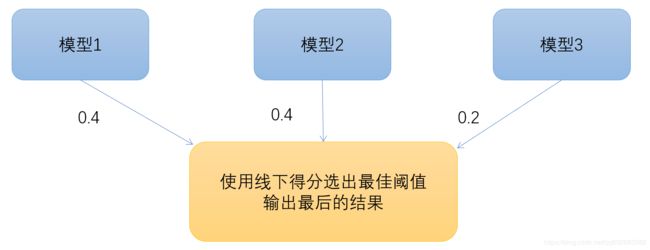
模型的融合就是图中的,采用了stakcing的方案,不过最后的权重没有足够的时间去优化,应该还有提升空间。
比赛总结
1.一定要构建合理的数据划分方式(考虑好分布差异,数据穿越,特征泄露等问题),模型稳定性很重要(CV调优,集成基本是必备),能做到线上线下的得分趋势一致(比赛中做的比较好的队伍甚至可以在提交前预测线上得分大概在多少)是一个很大的优势。
2.EDA很重要,不要凭主观臆测,比如比赛时有想过利用目标区间前更多的天数(不包括春节)来扩充训练集,但是效果不太好,经过分析后发现,和目标区间越接近的数据分布和目标区间越一致,所以并不是数据越多泛化性能越好,一定要保证分布的一致性。
3.分析好优化目标,对于预测变量组合(user,cate,shop),可以考虑拆分的做法(即先对user,cate召回,再预测user,cate,shop)有以下优点:a.从指标层面来说便于指标的优化,在实际比赛中,经常出现F11和F12此升彼降的情况,这其实可以从precision,recall的角度来解释,我们选择将F11优化到最高然后再对F12进行优化,这种做法可能不是最优的,因为这种做法有可能会限制F12的上限,但是在有限的时间和技术限制下,这是一种比稳妥的做法。 b.从训练层面,这种拆解的形式也有利于实验的优化,比如user,cate的召回过程可以大大降低样本不平衡比率,有利于模型学习)
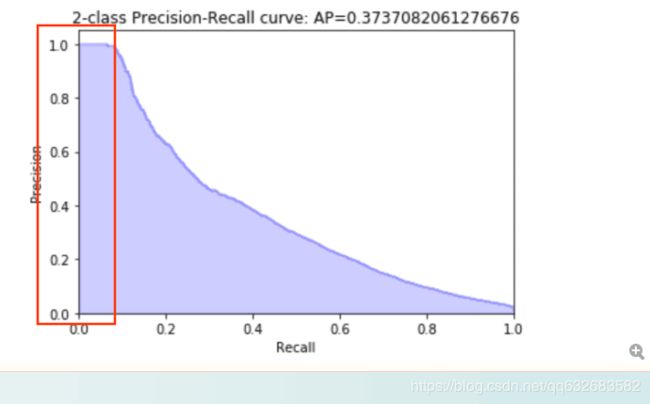
4.善用指标曲线评估样本,例如利用precision,recall曲线来选择比较有把握的样本, 在尝试建立短期购车模型时,我们只选取方框中的结果加入到现有预测,不过受时间限制,没有调出很好的效果
5.小tricks
- 对lgb几个重要参数做一下扰动,训练多个模型然后取平均(比如学习率和迭代次数建立一个函数使得学习率大了迭代步数减少,然后扰动学习率)
- 因为比赛提交的结果是预测一周购买情况,我们统计了现有数据集用户的周平均购买数量,并且用来作为TOP-N对测试集结果进行过滤,在A榜取得了很好的效果,但是这种策略仅仅适合冲一下分,模型泛化性能得不到保证。
6.关于不同的场景需要制定不同的策略
比如在商品购买的场景,商品和类别很多,浏览记录很多,正负样本比例差距太大,所以需要采用召回的策略。而在别的场景,比如游戏道具购买的场景,采用的策略可能会有所不同,需要具体问题具体分析。
7.比赛中有一些想法但是没有时间做,在复盘时看到别的队友有这么做的而且有一定效果的,例如单独利用购物车信息建立模型(举个例子,我们现在手上只有8天的购物车记录,那么可以利用这8天数据建立一个有加购行为但是在当天没有购买的用户是否会在接下来x天内购买sku_id的短期模型,也可以按照赛季1的思路建立回归模型预测加购后的购买时间和现有结果融合),此外也有利用LSTM对时序行为提取特征的思路觉得很有想法(见https://github.com/DuncanZhou/jdata2019),关于模型融合的权值也有优化的空间
8.关注比赛群的信息和官方回复会有不少收获,比如老师在群里面会给出一些tips,例如对cate分开建模来防止类别干扰(比如有的cate是高奢,有的是日用,这样会使模型学不到正确的参数)
9.特征选择工具:https://github.com/duxuhao/Feature-Selection
比赛日志
2019.5.1 搭建baseline,调研了第一届的有关方案并根据本届比赛进行相应的修改,暂时不考虑对统计数据进行权重衰减,xgboost:0.0308, rank:8
2019.5.6 将logloss指标替换成auc指标,lgb线上 0.031896,xgboost线上0.03129,rank:38,说明了不平衡问题处理上auc指标具有一定的优势
2019.5.7 经过统计发现comment表,有一些情况比如,某个商品,好评数为20,差评数为1,另外一个商品好评数为50,差评数为30,那么对于这两个商品,统计好评和差评的ratio比统计好评差评次数更具有实际意义,另外对商品评论量取对数来减少量纲差异,经过xgboost特征重要性排序后发现comment重要性排名1,xgboost线上0.03163,rank:49,有一定提升;
2019.5.8
1.采用网格搜索对lgb进行调优,线下auc提升2个点,但是线上指标并没有明显提升
2.尝试构造用户特征,查询了京东会员级别的成长模式,构造特征:2^会员级别除以账号使用时间(会员级别和购买力是正相关,除以使用时间表示升级速度,可以从一定程度上代表消费频率),没有明显提升
2019.5.9
1.构建1|2|3|5|...|30时间区间内,用户行为(type 1-5)的min,mean,max统计特征,线下auc提升3个点,而且xgboost特征重要性打印出来是有部分特征排在了前列,但是线上0.029,有少许下降
2.为了和线上评价标准保持一致,自行构造线下评价指标(F11+F12),测得线下0.028,和线上差不多,所以暂且将该目标作为我们线下的优化目标
2019.5.10
1.利用店铺信息构造了涨粉速度,和涨会员速度,线上0.043,rank 35,这两个特征为强特,位于前5,原有的特征重要性排序出现了变化,比如用户的下单频率累计排在了第1
2.线上0.043的线下评价指标依然在0.03左右,所以线下指标构建可能有错误,准备进行重建
4.构建特征,用户对一个商品的最后一次某一操作的时间到预测日前的时间差,线下auc和特征重要性不占优
5.将xgboost替换为lgb模型并进行调优,线上0.047,rank 25
6.尝试了lgb模型 stacking和boosting,线下auc无明显提升
2019.5.11
1.当前用户行为构建是根据1|2|3|5|...|30时间区间left join,相当于使用的预测日前一天有活动的用户构建的样本集,为了增大用户的样本数量,我们将用户活动时间扩大到3天和7天,即构建时间区间按照3|1|2|5|...|30,7|1|2|3|5|...|30进行left join,测的3天的结果和1天接近,均为0.047,7天的有所下降
2.构建了用户浏览行为,购物车行为的转化率,物品的被浏览,被加入购物车的转化率,线下auc提升4个点,特征排名在前5,待线上测试
3.重建线下评价指标,测得线上线下差异依然比较大,经过分析可能是val数据集和train数据集由同一时间区间(3.1-4.9)数据集split而来,val的提升只代表对于该时间区间的一种拟合,线上泛化性能不太好
2019.5.12
1.往前滑7天,利用3.1-4.2构造一个训练集合,将和预测区间比较接近的3.1-4.9的做验证集,auc在0.83,线下评估指标只有0.045
2.分析了action的分布,在过年期间,用户的下单,浏览等行为明显变少,除此之外分布基本是一致的
3.因为训练集中只有4.8日有添加购物车行为,而预测集中4.9-4.15均有添加购物车操作,模型特征重要性显示购物车行为十分重要,经过分析可能会有这样一种情况就是,训练出来的模型会认为凡是有添加购物车行为的均会被打上1的标签,但是对于预测集来说,也许在9号添加到购物车的物品会在9号-15号之间就已经被购买,真实标签反而是0,导致预测错误,为了避免4.8日该日购物行为的过拟合影响,打算将预测模型拆分为2个模型,一个长期模型,包含浏览转化率,涨粉速度这些长期特征,另外一个模型包括加入购物车,浏览这些短期特征
4.为了确定长期模型训练集验证集的构造时间跨度,首先需要对用户的最小最大时间间隔进行统计,经过统计发现用户的平均购物间隔在30之内,所以暂时以30天为时间跨度进行训练集验证集构建,线下auc0.83
5.对用户的action进行时间权重衰减,无明显提升
2019.5.13
1.将user_id-cate-shop_id预测拆分为2步,先预测user-cate是否购买,再预测哪个店铺购买, 候选用户为4.8日有行为记录的用户,线上F11指标提升明显,达到0.09,然后shop_id根据目前效果最好的baseline(线上0.047)进行填充,线上0.052,rank10
2.F12指标仍然比较低,对于提升店铺的预测准确度进行分析,首先因为user-cate-shop是采用的4.8日,画图分析得4.8出现的组合相比于后七天购买的组合占比比较低,如果用前一天训练,某种角度来说限制了上限,所以打算将候选时间区间扩大到15天时间,线上提高0.5个点
目前的结论就是,如果一个特征对于auc提升很大,而且特征重要性排名靠前,那么这个特征很可能就是有用的,而且我们会将线下的结果和目前为止最优的结果进行交并比的计算,除了强特导致预测结果出现很大的变化外,我们一般认为可能较优的结果不会和当前最优结果有较大的交并比浮动
2019.5.16
1.对原始数据进行分析,发现对于(user,skuid)的建模方式,并不合适,因为对于商品的复购率很低低于1%,重新建模为(user,cate,shop),复购率达到10%。根据调整的模型调整特征。线上测试达到0.049
2.引入新特征,测试期间内,user购买/点击转化率,cate购买/点击转化率,shop购买/点击转化率,user购买/购物车转化率,cate购买/购物车转化率,shop购买/购物车转化率。
3.优化取Top的结果输出方法,首先根据原始数据滑动统计得出,1月对1周预测复购数为12858,所以对输出先过滤负值预测,在对(user,cate,shop)求和合并,排序后输出Top N,N取12858,线上测试达到0.052。更新单模型baseline。
2019.5.17
1.比赛评委老师提到将cate分类进行建模会是一个比较好的做法,推测是cate之中含有复购率比较高得日用品和及时性购买得奢侈品,所以使用不同得模型分别进行建模可能会有比较好的效果,将该思路拓展到user,shop,所以首先根据user,cate的分布进行统计,看能不能找到分类建模的依据
2.目前模型的特征比较多,可能会需要对特征进行筛选,对特征筛选方法进行调研
3.经过对用户的分析发现刷单用户的存在,占数据1%,对这部分用户需要进行去重和删除,没有明显的提升
2019.5.18
1.增加特征的多样性,调研特征交叉,特征组合,确定了往届top队伍的特征选择方案和cateboost方法用来进行特征组合
2.对模型进行cv调优和融合
two-stage方案,首先对User-cate进行购买预测,根据购买概率进行召回(top召回和比例召回),可以大大减小不平衡样本比率,然后通过对即时性购买品类的分析,根据生活经验,可能是类似于家电,数码一类物品,用户通常是会挑选比较有名的店铺进行购买,所以采用top3店铺对现有样本进行扩充,以此来提高店铺的召回率,即F12分数,然后采用不同时间区间训练模型,并且采用了stacking的思想进行特征拼接,最后进行模型融合,获得比赛的冠军