广告行业中那些趣事系列14:实战线上推理服务最简单的打开方式BERT-as-service...

摘要:本篇从理论到实战重点分析了bert-as-service开源项目。首先讲了下学习bert-as-service的起因,因为实际业务中需要使用bert做线上化文本推理服务,所以经过调研选择bert-as-service开源项目;然后从理论的角度详解了bert-as-service,很纯粹的输入一条文本数据,返回对应的embedding表示。模型层面对比max pooling和average pooling分析了如何获得一个有效的embedding向量;工程方面重点从解耦bert和下游网络、提供快速的预测服务、降低线上服务内存占用以及高可用的服务方式分析如何提供高效的线上服务;最后实战了bert-as-service,从搭建服务到获取文本语句的embedding,再到最后获取微调模型的预测结果。希望对想要使用bert提供线上推理服务的小伙伴有帮助。
下面按照如下的思维导图进行详细讲解:
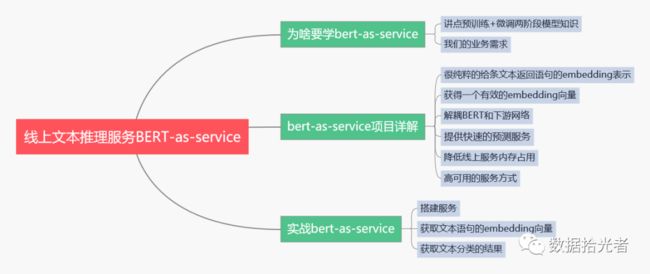
01 为啥要学bert-as-service
1. 讲点预训练+微调两阶段模型的知识
因为本篇主要使用bert-as-service开源项目为我们提供线上的文本分类服务,所以一些基础的bert知识必不可少。之前也出过一篇文章讲BERT理论知识的文章,感兴趣的小伙伴可以去看看,对于理解本文内容会帮助不少。
先说说BERT这种预训练+微调两阶段模型和端到端模型的区别。端到端模型就是使用任务相关的数据训练一个模型完成对应的任务。而BERT这种两阶段模型属于迁移学习的范畴。预训练阶段是通过无监督学习的方式学习海量的文本数据从而获得语言学知识;而微调阶段则是利用预训练阶段学习到的语言学知识结合任务相关的数据去做不同的NLP任务。
这里举个例子大家就理解了,预训练阶段就像我们从幼儿园到高中学了很多基础知识。微调阶段就是上大学时明确了自己以后要干啥工作,用预训练阶段学到的知识去精进我们的工作能力,从而能更好的胜任工作。预训练阶段因为要从海量的文本数据中学习语言学知识,所以需要大量的时间和计算资源。这就相当于我们花了十几年去学习基础知识一样。虽然预训练阶段耗时耗资源,但是可以理解为一次性的。谷歌使用4-16个TPU花费4天才完成预训练模型。不同语言的预训练模型可以通过如下链接进行下载:
https://github.com/hanxiao/bert-as-service#1-download-a-pre-trained-bert-model
和人不同的是,计算机学习到了这些语言学知识后可以将这些“知识”以模型的方式存储起来,然后其他人可以直接使用这个模型结合各自的需求微调模型完成各自下游的任务。因为我们普通人没有那么多的计算资源,所以直接下载谷歌的预训练网络使用就可以了。通过这个例子帮大家理解预训练和微调两阶段任务之间的联系。下面是端到端模型和两阶段模型的区别图:
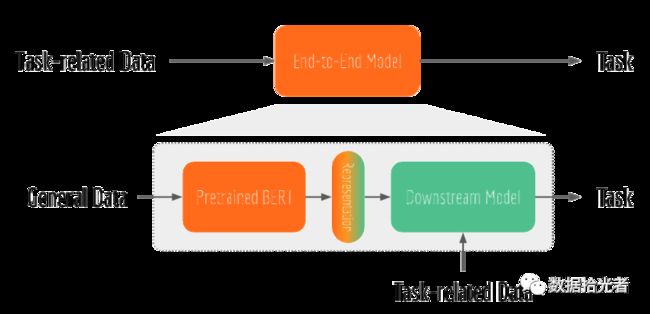
图1 端到端模型和两阶段模型的区别
2. BERT模型
BERT模型由输入层embedding、编码层Transformer encoder和输出层三部分组成。输入层将文本数据转化为词编码、句子对关系编码和位置编码三层embedding,编码层使用Transformer作为特征抽取器来获取文本语句的embedding表示,输出层则是根据下游的NLP任务来输出你想要的结果,可以是文本分类、命名体识别、翻译等等。这里重中之重就是得到编码层的语句embedding表示。得到语句的embedding表示之后,具体下游任务如何使用就可以任你想象了。比如我们的文本分类任务就可以加一个全连接层,也可以直接将语句的embedding向量作为特征用于下游深度学习任务等等。BERT模型结构如下图所示:
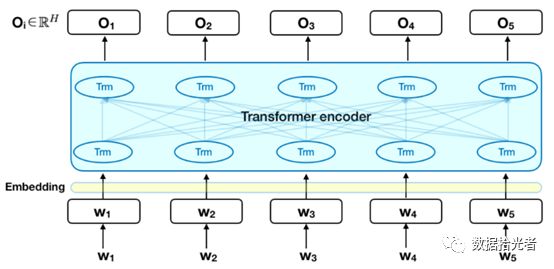
图2 BERT模型结构
3. 我们的业务需求
我们主要是使用BERT模型来对用户搜索query和浏览资讯news等文本数据进行文本分类。目前已经完成了离线服务的方式,也就是给一批数据调用文本分类模型,返回对应的分类结果。在实际业务场景中,我们还想提供线上文本推理服务。比如现在有个页面,你输入一句话:成龙大哥的传奇游戏好玩么?那么页面会给你返回传奇游戏标签,也就是在线文本分类服务。
02 bert-as-service项目详解
1. 模型调研
经过调研,腾讯AI实验室开源的bert-as-service项目是一个不错的选择,打算使用该开源项目提供我们的线上文本推理服务。bert-as-service简单来说就是通过Tensorflow和ZeroMQ来提供BERT线上化服务从而获取语句的embedding向量。既然是线上文本分类服务,那么就有服务端和客户端,我们希望对于服务端来说,需要一个预测速度快、内存占用少和高稳定性的bert服务;对于客户端来说,服务要简单易用,api简单的像vector = encode(texts),输入文本texts,返回对应的文本向量vector。
2. 获得有效的embedding向量表示
BERT输入层是将文本转化成词编码、句子对关系编码和位置编码,需要将三层embedding进行融合进入编码器。论文中使用uncased_L-12_H-768_A-12版本预训练模型在UCI-News Aggregator Dataset数据集下对比了max pooling和average pooling两种不同的pooling操作对语句embedding表示的影响。下面是随机选取2W条资讯的title文本数据,分别使用max pooling和average pooling时BERT编码器中不同的transform层得到的embedding经过pca降维得到的可视化图:

图3 不同pooling策略下BERT编码器各层pca可视化图
从图中可以看出,2W条资讯数据主要分成四类。整体来看,不同的pooling方式得到的embedding表示结果有一定差异。同时,查看各自的pooling方式下相邻层之间的embedding表示类似;第一层和最后一层的embedding表示差距很大;最后一层embedding的表示最接近词编码,能最好的保留初始的词语信息。
3. 解耦bert模型和下游网络
Bert-as-service项目将bert预训练网络和下游网络解耦。将bert预训练网络放在配置GPU资源的服务端,同时服务多用户;下游网络一般是简单的轻量级模型,不需要复杂的深度学习库,放在CPU或者手机终端上使用。下面是解耦服务端和客户端图:
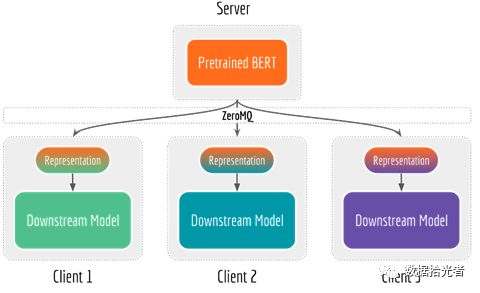
图4 解耦bert模型和下游网络
通过解耦bert模型和下游网络,当特征提取成为瓶颈时可以通过使用或者增加GPU资源来优化服务端,同理当下游网络成为瓶颈时可以添加CPU或者量化操作来优化客户端。同时当训练数据没有更新或者定义发生变化时只需在服务端重新训练BERT模型即可满足下游网络获取更新后的特征向量。这种请求汇集在一个地方的方法可以使服务端的GPU利用率大大提高。
服务端和客户端通信主要使用的是轻而快的ZeroMQ库,支持TCP、IPC或者其他协议的信息发送和接收。下面是发送和接受信息代码:

图5 ZeroMQ通信代码
4. 提供快速的预测服务
因为Google的BERT源码中包含训练和验证的代码,而线上服务主要是预测功能,所以可以在线上服务时将计算图中非必须的代码移除。举例来说假如我们使用第K层编码用于pooling操作,那么K层之后的参数对于线上预测没有作用,那么就可以安全的移除。下图总结了生产中服务于深度神经网络之前的一般过程:

图6 深度神经网络线上一般流程
Freezed指冻结变量为常量。对于一些不需要训练的网络,对应的参数也不需要更新,可以设置为常量。Pruned指删除计算图中不必要的节点和边,可以有效提升模型线上预测的效率。Quantized指降低参数精度,使用tf.float16 或者tf.uint8代替tf.float32等。因为大多数量化方法是针对移动设备实现的,所以可能无法在X86架构上观察到明显的加速。
下面通过指定输入和输出节点来优化计算图:

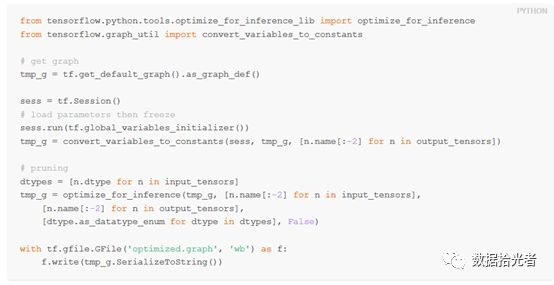
5. 降低线上服务内存占用
Bert-as-service项目只需要在第一次收到新请求时生成一个新的BERT模型,后续只需要在事件循环中监听请求并提供服务即可。原始的BERT代码使用了高级的tf.Estimator API,注入监听器的时候需要做一些调整,使用input_fn的生成器。具体代码如下:
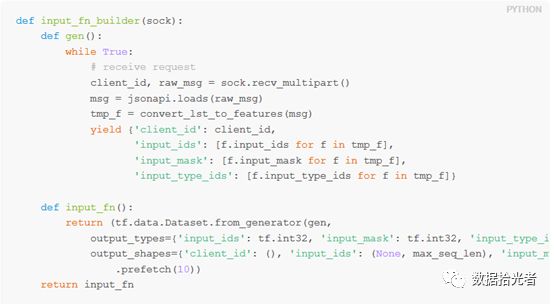
因为咱们前期的目的是对bert-as-service开源工程有大致的了解,同时把工程跑起来,后续要应用到实际业务进行二次开发的时候再深入研究各个模块的源码,所以这里不再深入讲解。总结下来就是一次导入,多次调用,通过这种方式可以降低内存占用。
6. 高可用的服务方式
如何解决多个客户端同时请求服务端的场景?比如现在小白和小黑同时想获取文本线上推理服务。如果小白先来并且需求巨大,比如每秒发送1W条文本数据。此时服务端分配了四个worker,也就是说有四个工人工作。服务端将工作并行化为四个子任务,分别交给四个工人来完成。这时候小黑来了,小黑每秒只发送一条文本。这时候因为服务端还在处理小白的任务,所以小黑只能等了。其实有点像操作系统里面的任务调度策略。从用户体验的角度来说我们希望小任务的小黑能很快得到满足。因为任务量大,所以需要等待更长的时间这是合乎常理的,也是用户可接受的。而任务量小却要等待很长时间则会让用户体验极差。
下面看看bert-as-service项目如何解决这个问题。当服务端收到多个客户端的请求后,主要通过ventilator组件来进行批处理调度和负载均衡。当收到多个客户端请求后,ventilator首先会将这些请求划分成多个小任务,然后将这些小任务分别发送给工人们。工人们收到这些小任务后开始工作,工作内容就是使用bert进行预测,预测完之后会将结果统一发送给sink组件。sink组件会将所有工人的预测结果统一装配,同时检查ventilator组件中各个客户端请求的完整性,如果某个客户端请求的数据已经全部预测完成了,那么就返回预测结果给对应的客户端完成本次请求。通过这种方式,可以轻松解决上面小任务调度体验问题。下面是服务端和客户端通信架构图:

图7 通信端和客户端通信架构图
想进一步了解bert-as-service通信架构设计的小伙伴可以到作者的博客中详细学习,这里只需要明白通过这种通信架构可以提供稳定的线上服务。
小结下,本章主要讲解bert-as-service的理论知识。只需要输入文本数据即可返回语句对应的embedding表示。模型角度分析了不同的pooling策略对embedding向量的影响。通过解耦bert和下游网络、提供快速的预测服务、降低线上服务内存占用和高可用的服务方式,bert-as-service可以又快又好的提供线上推理服务。
03 实战bert-as-service
上面从理论的角度详细分析了下bert-as-service项目,接下来从实战的角度看看怎么将该项目应用到我们的线上推理服务。
1. 搭建服务
这里咱们先在一台机器上同时安装服务端和客户端。实际应用的时候会将服务端统一部署在配置GPU硬件资源的服务器上,客户端则遵循谁用谁安装即可。
服务端安装命令是:pip install bert-serving-server
客户端安装命令是:pip install bert-serving-client
通过这两条简单的命令我们已经安装好服务端和客户端的python程序了。这里需要注意的是服务端必须安装python 3.5及以上,TensorFlow1.1及以上。客户端则同时支持python2和python3。
2. 获取文本的embedding向量
服务安装好之后,咱们先试试获取文本的embedding向量,也就是输入一条文本数据,返回文本对应的embedding向量。这里先把服务端启动起来,使用命令如下:
bert-serving-start -model_dir/tmp/english_L-12_H-768_A-12/ -num_worker=4
这里有两个参数需要说明下,一个是num_worker,这是分配的worker数目,一般分配的worker数目要少于GPU的颗数;另一个是model_dir,这是预训练模型的地址。我们将谷歌训练好的bert预训练网络下载下来,解压到/tmp/english_L-12_H-768_A-12/目录下。解压之后的数据目录大概是这样的:
图8 预训练网络文件目录
输入命令服务开启之后大概长这个样子:
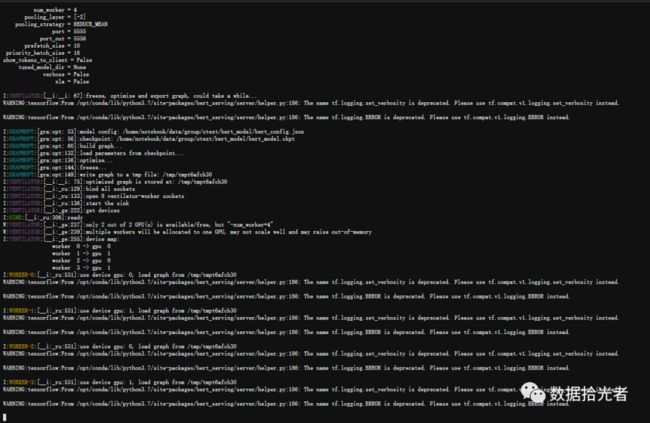
图9 服务端开启服务
然后通过如下三行代码,我们就能轻松返回语句的embedding表示,简单到没朋友:
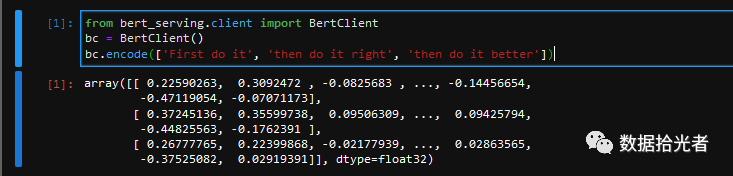
图10 客户端输入文本返回embedding表示
就是这么简单,咱们就能使用BERT预训练模型得到文本的embedding表示向量。
3. 获取文本分类的结果
上面已经得到BERT模型最重要的encodding编码向量。实际业务中我们是文本分类任务,其实就是添加了一层全连接层的一个微调的模型。通过如下命令即可实现bert-as-service项目用于文本分类任务:
bert-serving-start -model_dir=/pretrained/uncased_L-12_H-768_A-12
-tuned_model_dir=/tmp/mrpc_output/-ckpt_name=model.ckpt-343
这里有三个参数,model_dir是预训练模型的路径,tuned_model_dir则是经过微调的模型的存储路径,而ckpt_name是微调的模型的checkpoint。只需要配置这三个参数就可以进行线上文本分类服务了。
总结
本篇从理论到实战重点分析了bert-as-service开源项目。首先讲了下学习bert-as-service的起因,因为实际业务中需要使用bert做线上化文本推理服务,所以经过调研选择bert-as-service开源项目;然后从理论的角度详解了bert-as-service,很纯粹的输入一条文本数据,返回对应的embedding表示。模型层面对比max pooling和average pooling分析了如何获得一个有效的embedding向量;工程方面重点从解耦bert和下游网络、提供快速的预测服务、降低线上服务内存占用以及高可用的服务方式分析如何提供高效的线上服务;最后实战了bert-as-service,从搭建服务到获取文本语句的embedding,再到最后获取微调模型的预测结果。
参考资料
[1] https://hanxiao.io/2019/01/02/Serving-Google-BERT-in-Production-using-Tensorflow-and-ZeroMQ/
[2] https://github.com/hanxiao/bert-as-service#1-download-a-pre-trained-bert-model
最新最全的文章请关注我的微信公众号:数据拾光者。
