Hadoop2.6.5搭建HA(高可用)
一、环境
操作系统:CentOS6.9
软件版本:Hadoop2.6.5,Zookeeper3.4.13
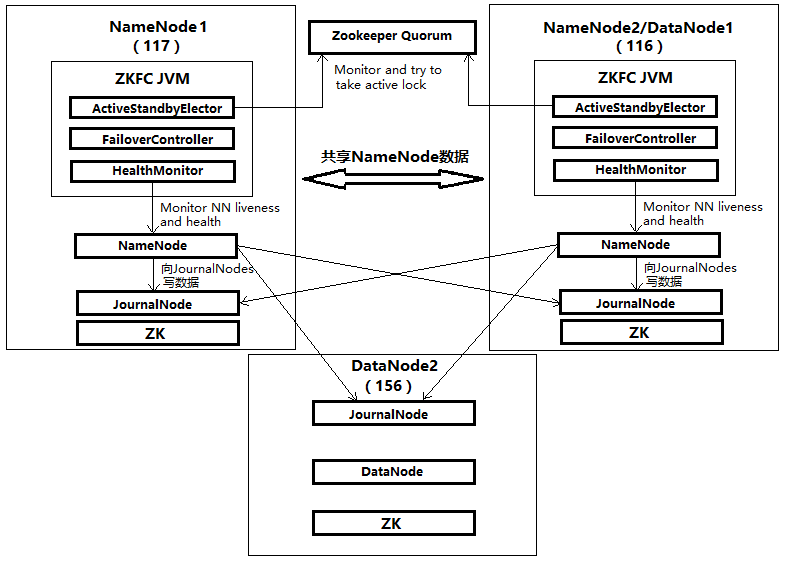
集群架构:
我手上有3台服务器,一台作为主NameNode,一台作为备NameNode和DataNode1,剩下一台作为DataNode2。也就是在3台服务器上面部署一主一备NameNode+两个DataNode。另外,由于JournalNode和ZK都至少为3个,且为奇数个,在3台服务器上面都启动JournalNode和ZK。
(关于Hadoop的HA介绍可以看这篇文章:https://blog.csdn.net/andyguan01_2/article/details/88696239 )
NameNode1:10.200.4.117(oracle02)
NameNode2/DataNode1:10.200.4.116(oracle03)
DataNode2:10.100.125.156(db01)
| 服务器 | NameNode | DataNode | ZK | ZKFC | JN |
|---|---|---|---|---|---|
| 117 | 是 | 是 | 是 | 是 | |
| 116 | 是 | 是 | 是 | 是 | 是 |
| 156 | 是 | 是 | 是 |
架构图如下(列出了各节点的关键进程):
二、搭建Hadoop的HA(高可用)
我之前已经搭建过Hadoop2.6.5非HA集群,接下来的步骤是在已有非HA集群的基础上操作。
搭建Hadoop2.6.5非HA集群(117作为NameNode,116和156作为DataNode)的方法见:
https://blog.csdn.net/andyguan01_2/article/details/86595985
1、配置HDFS(在所有节点)
1.1 配置core-site.xml
以hadoop用户登录117,执行:
vi $HADOOP_HOME/etc/hadoop/core-site.xml
配置以下内容:
fs.defaultFS
hdfs://ns
hadoop.tmp.dir
/data/hadoop/tmp
ha.zookeeper.quorum
10.200.4.117:2181,10.200.4.116:2181,10.100.125.156:2181
1.2 配置hdfs-site.xml
以hadoop用户登录117,执行:
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml
配置以下内容:
dfs.replication
2
dfs.namenode.name.dir
file:/data/hadoop/dfs/name
true
dfs.datanode.data.dir
file:/data/hadoop/dfs/data
true
dfs.datanode.max.transfer.threads
65536
dfs.nameservices
ns
dfs.ha.namenodes.ns
nn1,nn2
dfs.namenode.rpc-address.ns.nn1
10.200.4.117:9000
dfs.namenode.rpc-address.ns.nn2
10.200.4.116:9000
dfs.namenode.http-address.ns.nn1
10.200.4.117:50070
dfs.namenode.http-address.ns.nn2
10.200.4.116:50070
dfs.namenode.shared.edits.dir
qjournal://10.200.4.117:8485;10.200.4.116:8485;10.100.125.156:8485/ns
dfs.journalnode.edits.dir
/data/hadoop/ha/jn
dfs.client.failover.proxy.provider.ns
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider
dfs.ha.fencing.methods
sshfence
dfs.ha.fencing.ssh.private-key-files
/home/hadoop/.ssh/id_rsa
dfs.ha.automatic-failover.enabled
true
1.3 配置yarn-site.xml
以hadoop用户登录117,执行:
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml
配置以下内容:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.auxservices.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
yarn.resourcemanager.ha.enabled
true
yarn.resourcemanager.cluster-id
yrc
yarn.resourcemanager.ha.rm-ids
rm1,rm2
yarn.resourcemanager.hostname.rm1
10.200.4.117
yarn.resourcemanager.hostname.rm2
10.200.4.116
yarn.resourcemanager.zk-address
10.200.4.117:2181,10.200.4.116:2181,10.100.125.156:2181
将117上面的core-site.xml、hdfs-site.xml和yarn-site.xml拷贝到116和156:
scp $HADOOP_HOME/etc/hadoop/core-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml [email protected]:$HADOOP_HOME/etc/hadoop
scp $HADOOP_HOME/etc/hadoop/core-site.xml $HADOOP_HOME/etc/hadoop/hdfs-site.xml $HADOOP_HOME/etc/hadoop/yarn-site.xml [email protected]:$HADOOP_HOME/etc/hadoop
2、启动ZooKeeper集群(在ZK节点)
分别在117、116和156启动:
zkServer.sh start
查看状态:
zkServer.sh status

我这里只启动一个节点的zkServer时,查看状态是没有在运行:

将3个节点的zkServer全部启动后,状态就正常了。
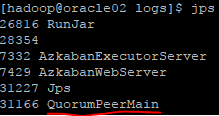
查看jps会看到有QuorumpeerMain:
3、启动journalnode(在JN节点)
后面第一次启动HDFS的时候要先格式化HDFS, 在这过程中,HA会和journalnode通讯,所以需要先把journalnode启动。
分别在117、116和156执行:
hadoop-daemon.sh start journalnode
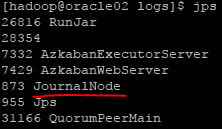
查看jps会看到有JouralNode:
4、格式化NameNode并启动(在主NameNode)
在117执行格式化NameNode命令:
hdfs namenode -format
然后启动NameNode:
hadoop-daemon.sh start namenode
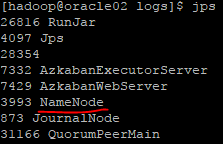
查看jps会看到出现NameNode:
5、将主NameNode同步到备NameNode(在备NameNode)
在116执行以下命令,把备NameNode的目录格式化并把元数据从主NameNode节点copy过来,并且这个命令不会把journalnode目录再格式化了。
hdfs namenode -bootstrapstandby
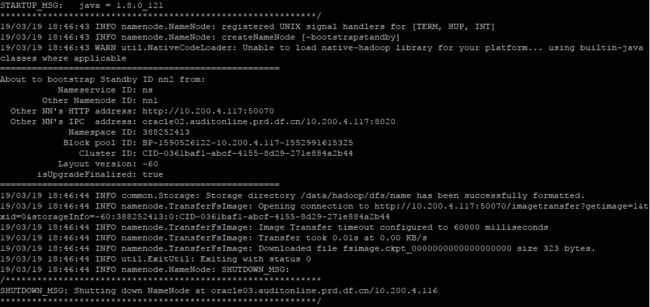
然后启动备NameNode:
hadoop-daemon.sh start namenode
6、格式化ZKFC(在主NameNode)
在117执行:
hdfs zkfc -formatZK
7、启动集群的HDFS和YARN(在主NameNode)
在117执行,启动集群的HDFS和YARN。
启动HDFS:
start-dfs.sh
相关各进程的启动顺序为:NameNode,DataNode,JournalNode,ZKFC。
以下为先停掉集群的HDFS和YARN之后,再启动HDFS的日志。也可以不停集群,如果有些进程已经启动,会报这些进程已经存在,这个不影响。
[hadoop@oracle02 sbin]$ start-dfs.sh
Mar 20, 2019 11:00:48 AM org.apache.hadoop.util.NativeCodeLoader
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [oracle02.auditonline.prd.df.cn oracle03.auditonline.prd.df.cn]
oracle03.auditonline.prd.df.cn: starting namenode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-namenode-oracle03.auditonline.prd.df.cn.out
oracle02.auditonline.prd.df.cn: starting namenode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-namenode-oracle02.auditonline.prd.df.cn.out
oracle02.auditonline.prd.df.cn: Mar 20, 2019 11:00:49 AM org.apache.hadoop.hdfs.server.namenode.NameNode startupShutdownMessage
oracle02.auditonline.prd.df.cn: INFO: STARTUP_MSG:
oracle02.auditonline.prd.df.cn: /************************************************************
oracle02.auditonline.prd.df.cn: STARTUP_MSG: Starting NameNode
oracle02.auditonline.prd.df.cn: STARTUP_MSG: host = oracle02.auditonline.prd.df.cn/10.200.4.117
oracle02.auditonline.prd.df.cn: STARTUP_MSG: args = []
oracle02.auditonline.prd.df.cn: STARTUP_MSG: version = 2.6.5
oracle02.auditonline.prd.df.cn: STARTUP_MSG: classpath = /u01/app/hadoop-2.6.5/etc/hadoop:/u01/app/hadoop-2.6.5/share/hadoop/common/lib/......省略部分内容
oracle02.auditonline.prd.df.cn: STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997; compiled by 'sjlee' on 2016-10-02T23:43Z
oracle02.auditonline.prd.df.cn: STARTUP_MSG: java = 1.8.0_121
10.100.125.156: starting datanode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-datanode-db01.rcas.out
10.200.4.116: starting datanode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-datanode-oracle03.auditonline.prd.df.cn.out
Starting journal nodes [10.200.4.117 10.200.4.116 10.100.125.156]
10.100.125.156: starting journalnode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-db01.rcas.out
10.200.4.116: starting journalnode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-oracle03.auditonline.prd.df.cn.out
10.200.4.117: starting journalnode, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-journalnode-oracle02.auditonline.prd.df.cn.out
10.200.4.117: Mar 20, 2019 11:01:00 AM org.apache.hadoop.hdfs.qjournal.server.JournalNode startupShutdownMessage
10.200.4.117: INFO: STARTUP_MSG:
10.200.4.117: /************************************************************
10.200.4.117: STARTUP_MSG: Starting JournalNode
10.200.4.117: STARTUP_MSG: host = oracle02.auditonline.prd.df.cn/10.200.4.117
10.200.4.117: STARTUP_MSG: args = []
10.200.4.117: STARTUP_MSG: version = 2.6.5
10.200.4.117: STARTUP_MSG: classpath = /u01/app/hadoop-2.6.5/etc/hadoop:/u01/app/hadoop-2.6.5/share/hadoop/common/lib/commons-configuration-1.6.jar:/u01/app......省略部分内容
10.200.4.117: STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997; compiled by 'sjlee' on 2016-10-02T23:43Z
10.200.4.117: STARTUP_MSG: java = 1.8.0_121
Mar 20, 2019 11:01:05 AM org.apache.hadoop.util.NativeCodeLoader
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting ZK Failover Controllers on NN hosts [oracle02.auditonline.prd.df.cn oracle03.auditonline.prd.df.cn]
oracle03.auditonline.prd.df.cn: starting zkfc, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-zkfc-oracle03.auditonline.prd.df.cn.out
oracle02.auditonline.prd.df.cn: starting zkfc, logging to /u01/app/hadoop-2.6.5/logs/hadoop-hadoop-zkfc-oracle02.auditonline.prd.df.cn.out
oracle02.auditonline.prd.df.cn: Mar 20, 2019 11:01:06 AM org.apache.hadoop.util.NativeCodeLoader
oracle02.auditonline.prd.df.cn: WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
启动YARN:
start-yarn.sh
相关各进程的启动顺序为:ResourceManager,NodeManager。
以下为先停掉集群的HDFS和YARN之后,再启动YARN的日志。也可以不停集群,如果有些进程已经启动,会报这些进程已经存在,这个不影响。
[hadoop@oracle02 sbin]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /u01/app/hadoop-2.6.5/logs/yarn-hadoop-resourcemanager-oracle02.auditonline.prd.df.cn.out
Mar 20, 2019 11:47:15 AM org.apache.hadoop.yarn.server.resourcemanager.ResourceManager startupShutdownMessage
INFO: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting ResourceManager
STARTUP_MSG: host = oracle02.auditonline.prd.df.cn/10.200.4.117
STARTUP_MSG: args = []
STARTUP_MSG: version = 2.6.5
STARTUP_MSG: classpath = /u01/app/hadoop-2.6.5/etc/hadoop:/u01/app/hadoop-2.6.5/etc/hadoop:/u01/app/hadoop-2.6.5/etc/hadoop:/u01/app/hadoop/share/hadoop/......省略部分内容
STARTUP_MSG: build = https://github.com/apache/hadoop.git -r e8c9fe0b4c252caf2ebf1464220599650f119997; compiled by 'sjlee' on 2016-10-02T23:43Z
STARTUP_MSG: java = 1.8.0_121
10.100.125.156: starting nodemanager, logging to /u01/app/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-db01.rcas.out
10.200.4.116: starting nodemanager, logging to /u01/app/hadoop-2.6.5/logs/yarn-hadoop-nodemanager-oracle03.auditonline.prd.df.cn.out
三、测试验证
1、查看NameNode状态
在任一节点执行(NameNode和DataNode均可):
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

可以看到两台NameNode的状态,117为active,116为standby。也可以打开以下网址查看:
10.200.4.117:50070
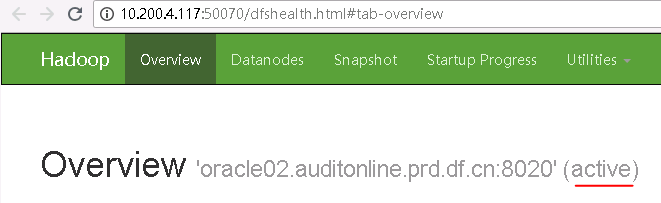
10.200.4.116:50070

2、停掉active节点的NameNode进程
在117执行:
jps #找到NameNode进程ID
kill -9 NameNode进程ID

再查看两台NameNode的状态:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
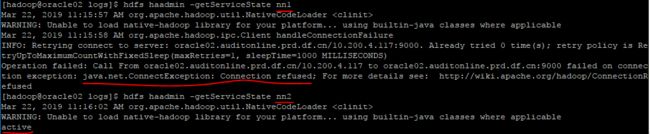
117无法查看(NameNode进程被kill),116由standby变为active。
3、重新启动被停掉的NameNode进程
在117执行:
hadoop-daemon.sh start namenode
再查看两台NameNode的状态:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2

117为standby,116为active。
补充说明下,117上面安装了Hive,在117为standby,116为active的情况,执行Sqoop将数据同步到Hive的时候会报错,错误原因和解决方法见:
Hive错误解决:Failed with exception Operation category READ is not supported in state standby
完毕。