最高最快最小目标检测模型 | 可收缩且高效的目标检测(附源码下载)
计算机视觉研究院专栏
作者:Edison_G杭州市
疫情以来,已经被研究出很多高效高精度的框架,在深度学习领域,模型效率也是越来越重的一个研究课题。不仅仅停留在训练的提速,现在推理应用的速度更加关键。因此,现在很多研究趋势朝着更高效更小型化发展!
1.摘要
模型效率在计算机视觉领域中越来越重要。作者研究了神经网络结构在目标检测中的设计选择,并提出了提高检测效率的几个关键优化方案。
首先提出了一种加权双向特征金字塔网络(BiFPN),该网络能够方便、快速的进行多尺度特征融合;其次,提出了一种混合缩放方法,可以同时对所有主干网络、特征网络以及最后的预测网络(boxes/classes)的分辨率、深度和宽度进行均匀缩放。特别地,是在单模型和单比例尺的情况下,EfficientDet-D7在52M参数和325B FLOPs的情况下,实现了map在 COCO数据集的最高水平(52.2),比之前最好的检测器更小,使用更少的FLOPs(325B),但仍然更准确(+0.2% mAP)。
2.背景
近年来,在更精确的目标检测方面取得了巨大的进展;同时,最先进的物体探测器也变得越来越昂贵(消耗)。例如,最新的基于AmoebaNet-based NAS-FPN检测器[Barret Zoph, Ekin D. Cubuk, Golnaz Ghiasi, Tsung-Yi Lin, Jonathon Shlens, and Quoc V. Le. Learning data aug- mentation strategies for object detection. arXiv preprint arXiv:1804.02767, 2019]需要167M参数和3045B FLOPs(比RetinaNet多30倍)才能达到最先进的精度。大型的模型尺寸和昂贵的计算成本阻止了他们在许多现实世界的应用,如机器人和自动驾驶,其中模型大小和延迟受到高度限制。鉴于这些现实世界的资源约束,模型效率对于目标检测变得越来越重要。
一个自然的问题是:是否有可能在广泛的资源约束(例如从3B到300B FLOP)中建立一个具有更高精度和更高效率的可伸缩检测体系结构? 作者旨在通过系统研究检测器结构的各种设计选择来解决这一问题。基于one- stage detector paradigm,研究了主干网络、特征融合和类/box网络的设计选择,并确定了两个主要挑战:
挑战1:高效的多尺度特征融合 自[Tsung-Yi Lin, Piotr Dolla ́r, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. CVPR, 2017]引入以来,FPN已被广泛应用于多尺度特征融合。最近,PANET、NAS-FPN和其他研究开发了更多的跨尺度特征融合网络结构。在融合不同的输入特征的同时,大多数以前的工作只是不加区分地总结它们;然而,由于这些不同的输入特征具有不同的分辨率,我们观察到它们通常对融合的输出特征作出不平等的贡献。为了解决这一问题,作者提出了一个简单而高效的加权双向特征金字塔网络(BiFPN),它引入可学习的权重来学习不同输入特征的重要性,同时反复应用自顶向下和自底向上的多尺度特征融合。
挑战2:模型缩放 虽然以前的工作主要依靠更大的主干网络[如:Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. arXiv preprint arXiv:1804.02767, 2018;Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks. NIPS, 2015]或更大的输入图像大小[Kaiming He, Georgia Gkioxari, Piotr Dolla ́r, and Ross Girshick. Mask r-cnn. ICCV, pages 2980–2988, 2017]来获得更高的精度,但我们观察到,在考虑精度和效率时,扩展特征网络和框/类预测网络也是至关重要的。 在最近的工作[Mingxing Tan and Quoc V. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. ICML, 2019]的启发下,作者提出了一种目标检测器的复合缩放方法,它联合缩放所有主干网络、特征网络、框/类预测网络的分辨率/深度/宽度。
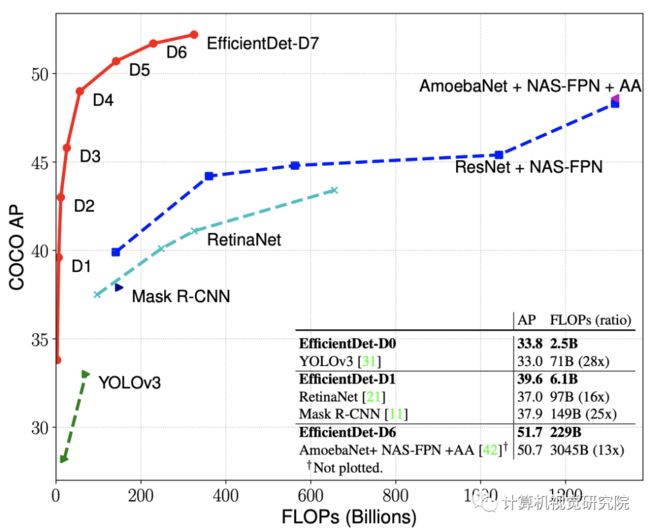
最后,我们还观察到,最近引入的Efficientnet比以前使用的主干网获得了更好的效率。将有效的网络骨架与作者提出的BiFPN和复合缩放相结合,开发了一个新的目标检测器集合,称为EfficientDet,它始终以比以前的目标检测器更少的参数和FLOPs来获得更好的精度。在类似的Accuracy约束下,EfficinetDet使用的FLOPS比YOLOv3少28倍,比RetinaNet少30倍,FLOPs比最近基于ResNet的NAS-FPN少19倍。 特别是,在单模型和单一测试时间尺度下,EfficinetDet-D7实现了最先进的52.2AP,具有52M参数和325B FLOPs,在1.5AP的情况下优于预期的最佳检测器[Barret Zoph, Ekin D. Cubuk, Golnaz Ghiasi, Tsung-Yi Lin, Jonathon Shlens, and Quoc V. Le. Learning data aug- mentation strategies for object detection],同时更小4倍,使用13倍的FLOPs。 EfficinetDet检测器在GPU/CPU上的速度也比以前的检测器快3倍至8倍。
3.BiFPN
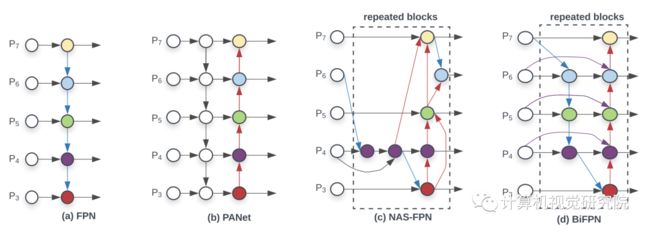
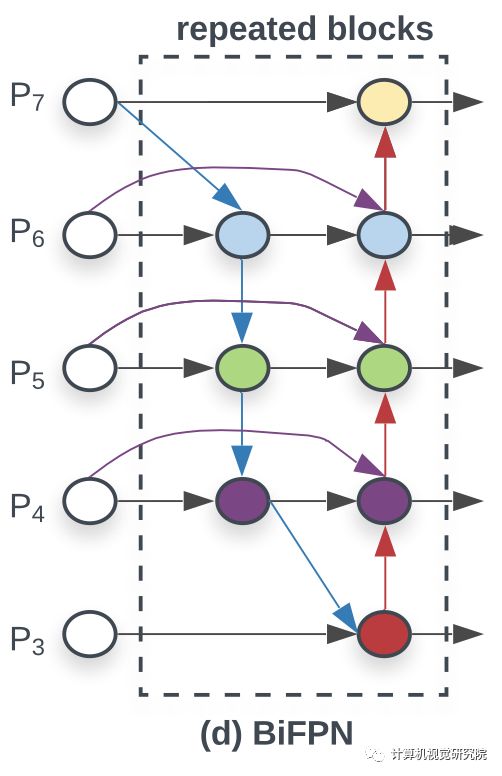
CVPR 2017的FPN指出了不同层之间特征融合的重要性,并且以一种比较简单,Heuristic的方法把底层的特征乘两倍和浅层相加来融合。之后人们也试了各种别的融合方法,比如PANet先从底向上连,再自顶向下连回去;NAS-FPN通过搜索找到一种不规则的连接结构。
总之上述都是一些人工各种连接的设计,包含Conv,Sum,Concatenate,Resize,Skip Connection等候选操作。很明显使用哪些操作、操作之间的顺序是可以用NAS搜的。进入Auto ML时代之后,NAS-FPN在前,搜到了一个更好的 neck部分的结构。
PANet效果好于FPN和NAS-FPN,计算代价也更高;
如果一个结点本身没有融合的特征,那么对以特征融合为目标的结构贡献就不大,所以PANet中移除了P3,P7的中间结点;

同一尺度的输入和输出又加了一个连接,因为计算量不大,得到上图(d);
上图(d)中虚线框内作为一层,会重复多次以得到high-level feature fusion。
加权融合
当融合具有不同分辨率的特征时,一种常见的方法是首先将它们调整到相同的分辨率,然后对它们进行融合。金字塔注意网络[Hanchao Li, Pengfei Xiong, Jie An, and Lingxue Wang. Pyramid attention networks. BMVC, 2018]引入全局自注意上采样来恢复像素定位,在[Golnaz Ghiasi, Tsung-Yi Lin, Ruoming Pang, and Quoc V. Le. Nas-fpn: Learning scalable feature pyramid architecture for object detection. CVPR, 2019]中进一步研究。以前的所有方法都一视同仁地对待所有输入特性。 然而,我们观察到,由于不同的输入特征具有不同的分辨率,它们通常对输出特征的贡献是不平等的。 为了解决这个问题,作者建议为每个输入增加一个额外的权重,并让网络学习每个输入特性的重要性。 基于这一思想,考虑了三种加权融合方法。
① Unbounded fusion
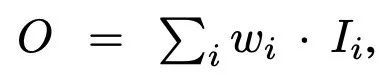
我们发现一个尺度可以达到与其他方法相当的精度,以最小的计算成本。然而,由于标量权重是无界的,它可能会导致训练不稳定。因此,作者采用权重归一化来约束每个权重的值范围。
② Softmax-based fusion
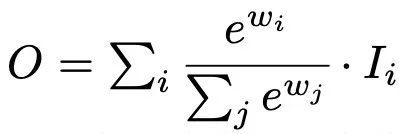
一个直观的想法是将softmax应用于每个权重,这样所有权重都被归一化为一个值范围为0到1的概率,表示每个输入的重要性。然而,如下文的ablation研究所示,额外的Softmax导致GPU硬件的显著减速。 为了最小化额外的延迟成本,作者进一步提出了一种快速融合方法。
③ Fast normalized fusion

同样,每个归一化权重的值也在0到1之间,但由于这里没有Softmax操作,所以效率要高得多。ablation研究表明,这种快速融合方法与基于Softmax的融合具有非常相似的学习行为和准确性,但在GPU上运行速度高达30%(如下表6)。

最终BiFPN集成了双向跨尺度连接和快速归一化融合。作为一个具体的例子,描述了上图(d)所示的BiFPN在level 6的两个融合特征。

4.EfficientDet
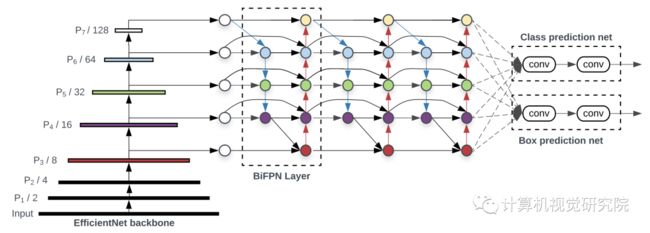
Compound Scaling
backbone:
作者重用了EfficientNet-B0到B6的相同宽度/深度缩放系数,因此可以轻松地重用ImageNet预训练的检查点。
BiFPN network:
作者将线性增加BiFPN深度(#layers),因为深度需要四舍五入为整数。对于BiFPN宽度(#channels),将BiFPN宽度指数增长,类似于EfficientNet。在值列表{1.2、1.25、1.3、1.35、1.4、1.45}上,并选择最佳值1.35作为宽度尺度因子。BiFPN的宽度和深度通过以下公式缩放:

Box/class prediction network:
作者将它们的宽度固定为与BiFPN相同,但使用方程线性增加深度:

Input image resolution:
由于在BiFPN中使用了特征level3-7,所以输入分辨率必须可分2^7=128,所以作者用方程线性地增加分辨率:

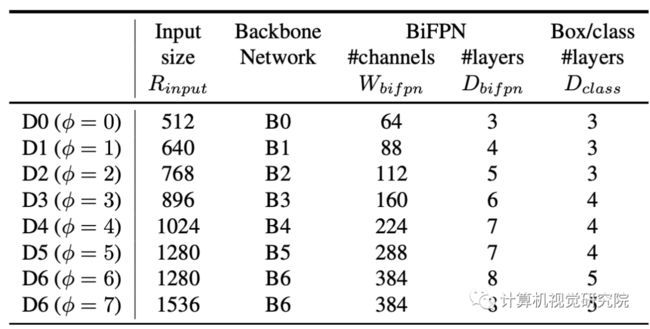
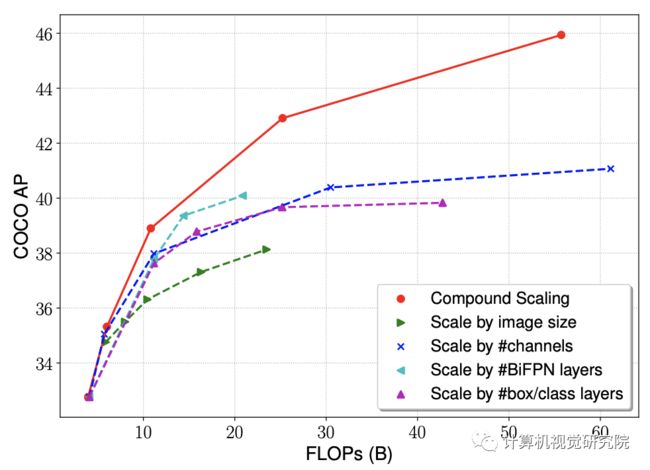
在具有不同φ的方程之后,作者开发了EfficientDet-D0(φ=0)到D7(φ7),如下表所示,其中D7与D6相同,但分辨率较高。值得注意的是,作者的缩放是基于启发式的,可能不是最优的,但这种简单的缩放方法可以显著提高效率,相比下图中的其他单维缩放方法。
✄-------------------------------------------
如果想加入我们“计算机视觉研究院”,请扫二维码加入我们。我们会按照你的需求将你拉入对应的学习群!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注我们
公众号 : 计算机视觉战队
扫码回复:efficientdet,获取下载链接