《SQL基础教程》第二版 读书笔记
基于最近面试的内容,复习一下SQL的基础知识,找找感觉。
第一章 数据库和SQL
1、数据库database:存储数据的仓库,通过计算机加工而成的可以进行高效访问的数据集合。
2、数据库管理系统DBMS:用来管理数据库的计算机系统。可实现多个用户同时安全简单地操作大量数据。
DBMS的种类(以数据的保存格式分类):
- 层次数据库HDB:把数据通过层次结构(树形结构)的方式表现出来。
- 关系数据库RDBMS:由行和列组成的二维表来管理数据,使用SQL来操作数据。
- 面向对象数据库OODB:将数据以及对数据的操作集合起来以对象为单位进行管理。
- XML数据库:
- 键值存储系统Key-Value Store:用来保存查询所使用的的主键和值的组合的数据库。常用的有MangoDB
- 图数据库:用来存储关系网络的数据库,常见的有Neo4j
3、客户端——SQL语句——服务器——操作数据库——返回数据
4、SQL根据操作目的可以分为DDL、DML和DCL:
- DDL:数据定义语言,包括create、drop、alter
- DML:数据操作语言,包括select、insert、update、delete
- DCL:数据控制语言,包括commit(确认对数据库中的数据进行的变更)、rollback(取消变更)、grant(服务用户操作权限)、revoke(取消用户的操作权限)
5、SQL的基本书写规则:
- sql语句以分号结尾
- 关键字大写、表名的首字母大写、列名小写
- 在书写日期与字符串时,加单引号
6、表的创建:
-
通过CREATE TABLE 语句创建
-
表和列的命名要使用有意义的文字
-
指定列的数据类型(整数型、字符型、日期型等)
- INTEGER 整型
- CHAR \ VARCHAR(可变长度)
- DATE 日期型
-
可在表中设置约束(主键约束和NOT NULL约束等)
- 对数据进行限制或者追加条件
- NOT NULL约束
- 主键约束 PRIMARY KEY
- comment 字段备注
- DEFAULT 默认值
-
建表时注意设置默认字符集:default charset=utf8,否则不支持中文
-
# 更改已创建好的表格的字符集charset ALTER TABLE t1 CONVERT TO CHARACTER SET utf8mb4;
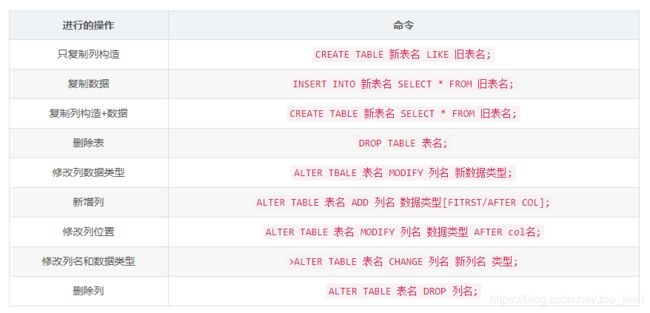
7、表的删除和更新:
-
DROP TABLE 删除表
-
ALTER TABLE 表名 ADD (COLUMN) \ DROP 在表格中添加列或者删除列
修改列的数据类型:ALTER TABLE 表名 MODIFY 列名 新数据类型;
-
INSERT INTO 向表格中插入数据
-
表重命名:RENAME TABLE poduct to product;或者ALTER TABLE poduct RENAME TO product;
第二章 查询基础
1、SELECT语句基础:
- AS 设置别名,使用中文时需要用双引号括起来
- 常数的查询:使用字符串或者日期常数时,必须使用单引号’’;常数将出现在每一行。
- 使用DISTINCT或者GROUPBY 来删除重复行,执行过程中NULL也会作为一类
- DISTINCT 关键字只能用在第一个列名之前
- 多列使用时,数据组合去重
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MTw8ud7b-1595076801591)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1594711712208.png)]
- WHERE条件筛选
SELECT <列名>, ……
FROM <表名>
WHERE <条件表达式>;
**执行顺序:**首先通过WHERE 子句查询出符合指定条件的记录,然后再选取出 SELECT 语句指定的列 (选取行再输出列)
- 注释的书写方法:
- 一行注释:-- 注释内容
- 多行注释:/* 注释内容 */
2、算数运算符和比较运算符
- 算数运算符:
- 算数运算符:+、-、*、/ 加减乘除
- 包含NULL 的计算,结果都为NULL
- 比较运算符:
- 比较运算符:=、<、>、<>、>=、<=
- 字符串数据比较时按照字典顺序进行排序
- 不能对NULL值进行比较 ,可使用IS NULL 或者 IS NOT NULL
3、逻辑运算符
- SQL中的逻辑运算是包含对真、假和不确定进行运算的三值逻辑
- NOT(取反)、AND(并且、逻辑积)、OR(或者、逻辑和)
- AND运算符优先于OR运算符,多条件查询时需注意逻辑顺序
第三章 聚合与排序
1、对表进行聚合查询
- 聚合函数包括COUNT、SUM、AVG、MAX、MIN
- MAX / MIN 函数可适用于任何数据类型的列
- SUM / AVG 函数只能对数值型的列使用
- 可用于SELECT子句、HAVING子句、以及ORDER BY 子句(可用别名)
- 聚合函数会对NULL以外的对象进行汇总
- COUNT函数的结果根据参数的不同而不同。 COUNT(*)会得到包含NULL的数据行数,而COUNT(<列名>)会得到NULL之外的数据行数。
- DISTINCT去重操作,函数间可组合使用
2、对表进行分组
- GROUP BY 子句用于分组,组合使用聚合函数时其结果是无序的
- 聚合键中包含NULL时,在结果中会以“不确定”行(空行)的形式表现出来
- 使用GROUP BY 分组后,SSLECT子句中只能存在以下三种元素:
- 常数
- 聚合函数
- GROUP BY 子句中指定的列名(聚合键/分组键)
3、为聚合结果指定条件
- 使用COUNT函数等对表中数据进行汇总操作时,为其指定条件的不是WHERE子句,而是HAVING子句
- 聚合函数可以在SELECT子句、 HAVING子句和ORDER BY子句中使用
- HAVING子句要写在GROUP BY子句之后
- WHERE子句用来指定数据行的条件, HAVING子句用来指定分组的条件
4、对查询结果进行排序
- 使用ORDER BY子句对查询结果进行排序。
- 在ORDER BY子句中列名的后面使用关键字ASC可以进行升序排序(默认),使用DESC关键字可以进行降序排序。
- ORDER BY子句中可以指定多个排序键。
- 排序健中包含NULL时,会在开头或末尾进行汇总。(NULL不能使用比较运算符)
- ORDER BY子句中可以使用SELECT子句中定义的列的别名。(执行顺序在SELECT子句后)
- ORDER BY子句中可以使用SELECT子句中未出现的列或者聚合函数。
- ORDER BY子句中不能使用列的编号。
第四章 数据更新
1、数据的插入 INSERT
-
INSERT INTO <表名> (列1, 列2, 列3, ……) VALUES (值1, 值2, 值3, ……);原则上,执行一次INSERT 语句插入一行数据。
多行INSERT时,每行数据()之间用逗号隔开(不易于查错)。
-
省略INSERT语句中的列名,就会自动设定为该列的默认值(没有默认值时会设定为NULL)。
-
插入NULL时需要在VALUES子句的值清单中写入NULL。
-
插入默认值可以通过两种方式实现,即在INSERT语句的VALUES子句中指定DEFAULT关键字(显式方法),或省略列清单(隐式方法)。——推荐使用显式方法
-
使用INSERT…SELECT可以从其他表中复制数据。
- INSERT语句的SELECT语句中,可以使用WHERE子句或者GROUP BY子句等任何SQL语法
- 使用ORDER BY子句并不会产生任何效果
2、数据的删除 DELETE
- 如果想将整个表全部删除,可以使用DROP TABLE语句,如果只想删除表中全部数据,需使用DELETE语句或者TRUNCATE语句。
- DELETE FROM 表名;
- TRUNCATE TABLE 表名;
- 如果想删除部分数据行,只需在WHERE子句中书写对象数据的条件即可。通过WHERE子句指定删除对象的DELETE语句称为搜索型DELETE语句。
- DELETE FROM 表名 WHERE 条件;
3、数据的更新 UPDATE
-
UPDATE <表名> SET <列名> = <表达式> WHERE <条件>; -
更新部分数据行时可以使用WHERE来指定更新对象的条件。通过WHERE子句指定更新对象的UPDATE语句称为搜索UPDATE语句。
-
使用UPDATE语句可以将值清空为NULL(但只限于未设置NOT NULL约束的列) 。
-
同时更新多列时,可以在UPDATE语句的SET子句中,使用逗号分隔更新对象的多个列 。
-- 使用逗号对列进行分隔排列 UPDATE Product SET sale_price = sale_price * 10, purchase_price = purchase_price / 2 WHERE product_type = '厨房用具'; -- 将列用()括起来的清单形式(在MYSQL中执行报错) UPDATE Product SET (sale_price, purchase_price) = (sale_price * 10, purchase_price / 2) WHERE product_type = '厨房用具';
4、事务
-
事务是需要在同一个处理单元中执行的一系列更新处理的集合。通过使用事务,可以对数据库中的数据更新处理的提交和取消进行管理。
-
事务的语法:
事务开始语句(START TRANSACTION); DML语句①; DML语句②; DML语句③; . . 事务结束语句( COMMIT或者ROLLBACK) ; —— 例子: START TRANSACTION; -- 将运动T恤的销售单价降低1000日元 UPDATE Product SET sale_price = sale_price - 1000 WHERE product_name = '运动T恤'; -- 将T恤衫的销售单价上浮1000日元 UPDATE Product SET sale_price = sale_price + 1000 WHERE product_name = 'T恤衫'; COMMIT; -
事务处理的终止指令包括COMMIT(提交处理)和ROLLBACK(取消处理)两种。
- COMMIT 是提交事务包含的全部更新处理的结束指令,相当于文件处理中的覆盖保存。一旦提交,就无法恢复到事务开始前的状态。
- ROLLBACK 是取消事务包含的全部更新处理的结束指令,相当于文件处理中的放弃保存。一旦回滚,数据库就会恢复到事务开始之前的状态 。
-
DBMS的事务具有**原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)**四种特性。通常将这四种特性的首字母结合起来,统称为ACID特性。
- 原子性:原子性是指在事务结束时,其中所包含的更新处理要么全部执行(COMMIT),要么完全不执行(ROLLBACK)。
- 一致性:一致性指的是事务中包含的处理要满足数据库提前设置的约束,如主键约束或者 NOT NULL 约束等。
- 隔离性:隔离性指的是保证不同事务之间互不干扰的特性。
- 持久性:指的是在事务(不论是提交还是回滚)结束后, DBMS 能够保证该时间点的数据状态会被保存的特性。即使由于系统故障导致数据丢失,数据库也一定能通过某种手段进行恢复。
第五章 复杂查询
1、视图
-
**视图和表的区别:**从SQL的角度来看,视图和表是相同的,两者的区别在于表中保存的是实际的数据,而视图中保存的是SELECT语句(视图本身并不存储数据)。从视图中读取数据时,视图会在内部执行该SELECT 语句并创建出一张临时表。
-
视图的优点:
- 由于视图无需保存数据,因此可以节省存储设备的容量。
- 可以将频繁使用的SELECT 语句保存为视图,不需每次重新书写。(类似于Python中函数封装)。
- 视图中的数据会随原表的变化自动更新。
-
创建视图需要使用CREATE VIEW语句。
CREATE VIEW 视图名称(<视图列名1>, <视图列名2>, ……) AS -
使用视图注意事项:
- 不能使用ORDER BY
- 可对其进行有限制的更新(未使用DISTINCT\GROPUBY\HAVING,FROM子句中只有一张表);视图和表需要同时进行更新,因此通过汇总得到的视图无法进行更新。
- 避免在视图的基础上创建视图,多重视图会降低SQL的性能
-
删除视图需要使用DROP VIEW语句。
DROP VIEW 视图名称(<视图列名1>, <视图列名2>, ……)
2、子查询(嵌套)
- 一言以蔽之,子查询就是一次性视图( SELECT语句)。与视图不同,子查询在SELECT语句执行完毕之后就会消失。
- 子查询作为内层查询会首先执行。
- 使用子查询注意事项:
- 避免使用多层嵌套子查询,层数增加,SQL语句难懂,且性能变差
- 需要根据处理内容来指定恰当的名称
- 标量子查询就是只能返回一行一列的子查询(返回单一值)
- 书写位置:能够使用常数或者列名的地方,无论是 SELECT 子句、 GROUP BY 子句、 HAVING 子句,还是ORDER BY 子句,几乎所有的地方都可以使用
- **使用注意事项:**不能返回多行结果
3、关联子查询
- 关联子查询会在细分的组内进行比较时使用。起到关键作用的就是在子查询中添加的 WHERE 子句的条件,起分组键效果。
- 关联子查询和GROUP BY子句一样,也可以对表中的数据进行切分。
- 关联子查询的结合条件如果未出现在子查询之中就会发生错误。子查询内部设定的关联名称,只能在该子查询内部使用。
- 可出现在外层查询的SELECT子句、WHERE子句中。
第六章 函数、谓词、CASE 表达式
1、函数的类别
-
根据用途,函数可以大致分为算术函数、字符串函数、日期函数、转换函数和聚合函数。
-
算数函数:
- 加减乘除四则远算
- ROUND()四舍五入函数
- ABS() 绝对值函数
- MOD()求余函数
ABS(数值) MOD(被除数,除数) ROUND(对象数值,保留小数的位数) -
字符串函数:
- || 字符串拼接函数(||在MYSQL中无法使用,需使用CONCAT函数拼接)
- LENGTH函数
- LOWER 小写转换函数(针对英文字母)、UPPER 大写转换函数
- REPLACE 字符串替换函数
REPLACE(对象字符串,替换前的字符串,替换后的字符串)- SUBSTRING 字符串截取函数
SUBSTRING(对象字符串 FROM 截取的起始位置 FOR 截取的字符数) SUBSTRING(对象字符串, 截取的起始位置, 截取的字符数) —— 从1开始计数 -
日期函数:
-
CURRENT_DATE函数——获得当前日期
-
CURRENT_TIME函数——获得当前时间
-
NOW函数 / CURRENT_TIMESTAMP函数——获得当前日期与时间
-
EXTRACT 截取日期元素
YEAR() 、MONTH() 、 DAY()都可实现日期截取
TO_DATE(CURRENT_TIMESTAMP)日期提取函数等同于 CURRENT_DATE
EXTRACT(日期元素 FROM 日期) 日期元素包括:YEAR \ MONTH \ DAY \ HOUR \ MINUTE \ SECOND EXTRACT(MONTH FROM CURRENT_TIMESTAMP) 等同于 MONTH(CURRENT_TIMESTAMP) -
时间戳转换为日期 FROM_UNIXTIME函数
FROM_UNIXTIME(BIGINT UNIXTIME, string_format) -
计算时间间隔DATE_DIFF函数
DATE_DIFF(string enddate, string startdate) -
DATE_ADD \ DATE_SUB 日期增减函数
-
-
转换函数:
-
数据类型的转换 CAST 函数 或者CONVERT函数
CAST(转换前的值 AS 想要转换的数据类型) CONVRET(转换前的值,想要转换的数据类型)将任意类型的表达式expr转换成指定类型type的值。type可以是以下任意类型之一:
BINARY[(N)] :二进制字符串,转换后长度小于N个字节( 不足长度N则尾部补上0x00 )
CHAR[(N)] :字符串,转换后长度小于N个字符
DATE :日期
DATETIME :日期时间
DECIMAL[(M[,N])] :浮点数,M为数字总位数(包括整数部分和小数部分),N为小数点后的位数
SIGNED [INTEGER] :有符号整数
TIME :时间
UNSIGNED [INTEGER] :无符号整数 -
COALESCE函数,返回可变参数中左侧开始第一个不是NULL的值。函数可以将 NULL 变S换为其他的值。

-
2、谓词
- 谓词就是返回值为真值的函数,返回值全部都为真值(TRUE / FALSE / UNKNOW)
- LIKE
- BETWEEN
- IS NULL \ IS NOT NULL
- IN
- EXISTS
- LIKE 谓词——字符串的部分一致查询
- 前方一致:str%
- 中间一致:%str%
- 后方一致:%str
- _代表任意一个字符
- BETWEEN 谓词——范围查询
- 字段 BETWEEN 左边界 AND 右边界;
- 效果等同于<= AND >=
- IS NULL、IS NOT NULL——判断是否为NULL
- 用于选取值为NULL的数据
- IN 谓词——OR的简便用法
- 使用IN 和 NOT IN 时无法选取出NULL 数据
- 可将子查询作为参数
- NOT IN的参数中包含NULL时结果通常会为空,也就是无法选取出任何记录
- EXIST 谓词 ——效率优于IN谓词
- EXIST (存在) 谓词的主语是”记录“,作用是判断是否存在满足某种条件的记录
- 关联子查询作为谓词参数(WHERE中加入联接条件),EXIST 只会判断是否存在满足子查询中 WHERE 子句指定的条件 ,满足条件时才返回真(TRUE)。
3、CASE 表达式
-
CASE 表达式用于(条件)分支,所有分支的返回值必须一致
-
CASE表达式分为简单CASE表达式和搜索CASE表达式两种。
CASE WHEN <求值表达式> THEN <表达式> WHEN <求值表达式> THEN <表达式> WHEN <求值表达式> THEN <表达式> . . . ELSE <表达式> END -
CASE 表达式应用:
-
行列转换
-- 对按照商品种类计算出的销售单价合计值进行行列转换 SELECT SUM(CASE WHEN product_type = '衣服' THEN sale_price ELSE 0 END) AS sum_price_clothes, SUM(CASE WHEN product_type = '厨房用具' THEN sale_price ELSE 0 END) AS sum_price_kitchen, SUM(CASE WHEN product_type = '办公用品' THEN sale_price ELSE 0 END) AS sum_price_office FROM Product; -
统计分布情况——数值型数据离散化
-
数据转换、插入所需字符串等
-
-
可使用IF表达式(可嵌套实现)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EgH7z5Qs-1595077048360)(C:\Users\Administrator\AppData\Roaming\Typora\typora-user-images\1594957781865.png)]
第七章 集合运算
1、表的加减法(以记录为单位——记录的增减)
- 集合运算就是对满足同一规则的记录进行的加减等四则运算。
- UNION(并集)
- INTERSECT(交集)
- EXCEPT(差集)等集合运算符
- 集合运算符的注意事项:
- 作为运算对象的记录的列数必须相同
- 作为运算对象的记录中列的类型必须一致
- 可以使用任何SELECT语句,但ORDER BY子句只能在最后使用一次
- 表的加法——UNION
- UNION运算符会去除重复的记录
- UNION ALL 会保留重复的记录
- 选取表中公共部分——INTERSECT
- INTERSECT 应用于两张表,选取出它们当中的公共记录
- 记录的减法——EXCEPT
2、联结(以列为单位对表进行联结——添加列)
- 联结( JOIN)就是将其他表中的列添加过来,进行“添加列”的集合运算。UNION是以行(纵向)为单位进行操作,而联结则是以列(横向)为单位进行的。
- 内联结——INNER JOIN
- FROM子句中包含多张表,可使用别名简化
- ON子句标明联结条件——联结键
- SELECT 子句中使用“< 表的别名 >.< 列名 >”的形式来指定列
- 外联结——OUTER JOIN
- 选取出单张表中全部的信息
- 左联结——LEFT JOIN
- 以左边表为主表进行联结,右表中缺少相应数据时,返回结果中为NULL值
- 交叉联结——笛卡尔积 CROSS JOIN
第八章 SQL高级处理
1、窗口函数(OLAP函数)
-
窗口函数语法
<窗口函数> OVER ([PARTITION BY <列清单>] ORDER BY <排序用列清单>) —— []中的内容可省略,原则上窗口函数只能在SELECT子句中使用 ——PARTITION BY 能够设定排序的对象范围 ——ORDER BY 能够指定按照哪一列、何种顺序进行排序- 能够作为窗口函数的聚合函数( SUM、 AVG、 COUNT、 MAX、 MIN)——累计计算窗口函数
- RANK、 DENSE_RANK、 ROW_NUMBER ——排序窗口函数
- NTILE——分组查询窗口函数
- LAG、LEAD——偏移分析窗口函数
-
窗口函数兼具之前我们学过的 GROUP BY 子句的分组功能以及ORDER BY 子句的排序功能 ,但是, PARTITION BY 子句并不具备GROUP BY 子句的汇总功能 。
-
排序窗口函数:
- RANK 函数:计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
例:有 3 条记录排在第 1 位时:1 位、1 位、1 位、4 位…… - DENSE_RANK函数:同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
例:有 3 条记录排在第 1 位时:1 位、1 位、1 位、2 位…… - ROW_NUMBER函数:赋予唯一的连续位次。
例:有 3 条记录排在第 1 位时:1 位、2 位、3 位、4 位……
- RANK 函数:计算排序时,如果存在相同位次的记录,则会跳过之后的位次。
-
累计计算窗口函数——作为窗口函数的聚合函数
-
SUM( 字段) OVER(PARTITION BY 字段 ORDER BY 字段 ROWS BETWEEN D1 AND D2)
指定更加详细的汇总范围——框架 (D1-D2)
**框架关键字:**BETWEEN、PRECEDING、FOLLOWING
-
AVG
指定框架——移动平均,用于股票趋势分析等
-
2、GROUPING 运算符
-
使用GROUPING运算符可同时得出小计和合计,包含以下三种:
-
ROLLUP——从最小的聚合级开始,聚合单位逐渐扩大
GROUP BY product_type WITH ROLLUP一次计算以下N+1(N为分组键个数)种组合的汇总结果:
-
GROUP BY()——超级分组记录
超级分组记录默认使用NULL作为聚合键。
-
GROUP BY (分组键1)
-
GROUP BY (分组键1,分组键2)
-
-
CUBE——聚合键的所有组合
一次计算以下2^N(N为分组键个数)种组合的汇总结果:
- GROUP BY()
- GROUP BY (分组键1)
- GROUP BY (分组键2)
- GROUP BY (分组键1,分组键2)
-
GROUPING SETS
-
-
GROUPING函数:
-
在其参数列的值为超级分组记录所产生的 NULL 时返回 1,其他情况返回 0
-
用于分辨超级分组记录中的 NULL 和原始数据本身的 NULL
-
在超级分组记录的键值中插入恰当的字符串
SELECT CASE WHEN GROUPING(product_type) = 1 THEN '商品种类 合计' ELSE product_type END AS product_type, CASE WHEN GROUPING(regist_date) = 1 THEN '登记日期 合计' ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date, SUM(sale_price) AS sum_price FROM Product GROUP BY ROLLUP(product_type, regist_date);
-