Python 在Online Judge上自动挂题脚本
Pre-Reading:
学弟搭建的开源OJ-青岛大学OJ
想了一下大概凡是用这个开源项目的基本上可以用这个脚本吧。
脚本用的是python的selenium(自动化测试工具)
关于安装selenium、Chrom或者Firefox的Driver
请参考我这篇博客:Selenium初步
使用手册
1.题目的目录为(可以存在其他文件 但以下文件是必须的)
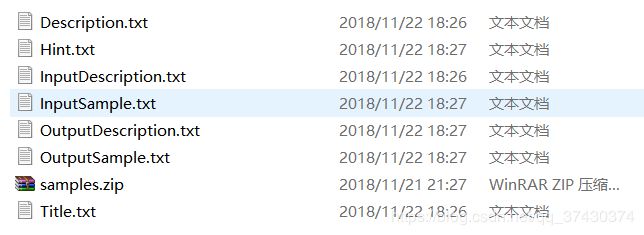
- samples中的测试数据得是1.in, 1.out形式的 etc.
- 如果是测试数据是TXT懒得手动修改文件的后缀名和手动压缩,可以参考我另一篇博客:批量修改后缀名以及压缩
2.传入题目目录为:
upload = Upload();
upload.batchCreateQ("D:/safemon/test")其中的D:/safemon/test为主目录 该目录下有多个题目 每个题目文件夹如1所示:

3.Chrome或者Firefox下运行
Chrome端:注释部分去掉之后就可以实现在后台自动操作
# 无界面操作
# chrome_options = Options()
# chrome_options.add_argument("--headless")
# driver = webdriver.Chrome("D:/software/python/module/chromedriver.exe", chrome_options=chrome_options)
driver = webdriver.Chrome("D:/software/python/module/chromedriver.exe")FireFox端:
fireFoxOptions = webdriver.FirefoxOptions()
fireFoxOptions.set_headless()
driver = webdriver.Firefox(firefox_options=fireFoxOptions)4.ID号每次要自己改
因为不知道你一次要添加多少道题,每道题的起始编号是多少
ID = 8000如果ID=8001,则第一道题的ID号为8002
5.用户名和密码要改成具有超级管理员的权限(才能加题)不用我说吧。
6.Cookies保存
短时间多次登录可以通过一个Session,脚本会在第一次访问的时候在执行文件目录下生产一个cookies.json,如果 很长一段时间之后想再次使用该脚本,该cookies可能会失效,所以直接删除那个cookies.json文件,会再产生一个最新的cookies的。
难点解析
1.关于如何在自动化测试(模拟手动驱动浏览器)时,保持session连接
屁话:一开始我是这么想的,如果成功登陆之后,在get其他的页面,应该也是可以访问的,毕竟我刚刚才登陆过了。
事实:get其他页面的结局是...需要再次登陆
So what should we do under this kind of circumstances?
解决方案:
- 分析发送请求的cookies格式
cookies = self.driver.get_cookies()- 得到json格式的cookies
- 根据分析的cookie格式向driver里add_cookie
- 带着cookies(即保持着session连接)去get页面就好
for cookie in cookies:
self.driver.add_cookie(cookie_dict={
'domain': cookie['domain'],
'expiry':cookie['expiry'],
'httpOnly':cookie['httpOnly'],
'name': cookie['name'],
'path': '/',
'secure': cookie['secure'],
'value': cookie['value']
})2.这个问题我至今没有解决:服务器返回403错误
屁话:一个上午和中午的时间,我大概通过selenium连续登陆了十几(几十?)次我的管理员账号。我在通过后台登陆管理员账号的时候,按照道理来说,我手动操作和我通过selenium模拟应该是完全一样的效果,然而在下午的某个时刻它向我返回403错误。
我想了可能有很多原因:
- 服务器把我IP给封掉了(这个在我尝试通过VPN代理IP、换网线、换wifi改变我的IP地址后失败)我不知道是因为我应该在代码里设置干净的代理 还是这个封掉的IP到底是什么IP?
- 服务器屏蔽掉我这个管理员了(我是超级管理员耶?也封??但是我通过自己打开网页手动登录就没有问题 失败告终)
- 服务器可以识别出来我是通过模拟登录而不是手动登录 (我一直在网上查:为什么会遇到这样的情况,虽然我没有查到原因,也没有查到什么解决办法。不过我查到一个网站,有人在爬Twitter的虫的时候遇到同样的问题,下面有一个人这么说,而且如果我如果有一天能够找到解决办法 应该就是从这之中找到 ) 以及我观察了通过手动和selenium模拟返回403时的区别 其中有一个csrf token 我觉得这个也应该是一个突破点
I have this problem from time to time with my own script.
What I found while debugging is I missed sending something when posting data.
Check that you post a valid user-agent, a referer, all the fields found in the form (especially the authenticity token), the cookie you must convince Twitter you use a normal browser.
It's 403 response means you didn't.
然而这些都触及到了我的知识盲区了,我寻求了很多人的帮助,但是也没能找到一个解决方案,我还给自己立下一个flag:
如果我有朝一日能够解决这个问题
I will answer this question.
如果看我这篇文章的某个人 能够解决这个问题 请一定要告诉我 救救孩子吧
3.技术提示:必须首先加载网站,这样Selenium 才能知道cookie 属于哪个网站,即使加载网站的行为对我们没任何用处
4.上传文件
其实上传文件特别好玩,举个栗子吧,如果你在一个网页上,上传某个文件,它一定会弹出一个windows窗口,让你选择文件路径,而这个窗口不属于这个浏览器,就没法驱动driver去点click,去send_keys.。然后其实发现上传文件其实特别简单,因为只用像那个Button中的input输入框,send_keys(文件路径名)就可以了,这个操作其实就是弹出的windows窗口所做的事情,就是选择路径。
然后就可以直接上传文件了,我选择等待3sec让文件上传完。
其他的傻逼操作就不想再讲了 学了就会写了
from selenium import webdriver
from selenium.webdriver.support import expected_conditions as EC
from urllib import parse, request
import json
import requests
import time
import sys
import time
import os
class Upload:
url = "http://oj.ctgu.work/admin/contest/1/problem/create"
# 无界面操作
# chrome_options = Options()
# chrome_options.add_argument("--headless")
# driver = webdriver.Chrome("D:/software/python/module/chromedriver.exe", chrome_options=chrome_options)
driver = webdriver.Chrome("D:/software/python/module/chromedriver.exe")
ID = 8001
dic = {'Title' : '1', 'Description' : '1', 'InputDescription' : '1', 'OutputDescription' : '1', 'InputSample' : '1', 'OutputSample' : '1', 'Hint' : '1'}
path = 'question/'
postfix = '.txt'
def __init__(self):
pass
def getSession(self):
cookies = self.driver.get_cookies()
jsonCookies = json.dumps(cookies)
with open('cookies.json', 'w') as f:
f.write(jsonCookies)
def loadSession(self):
username="XXXXXXXX"
password="XXXXXXXX"
#技术提示:必须首先加载网站,这样Selenium 才能知道cookie 属于哪个网站,即使加载网站的行为对我们没任何用处
self.driver.get("http://oj.ctgu.work")
self.options = webdriver.ChromeOptions()
self.options.add_argument('Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36')
self.options.add_argument('lang=zh_CN.UTF-8')
# options.add_argument('O9PuzSZ6reUETDMbVhgv53o2o7PGwPYvGkse5poA3EbSr3mY1n9I4ScMyQ9yJKp7')
self.driver.get("http://oj.ctgu.work")
if(os.path.exists('cookies.json') == False):
self.getSession()
self.driver.find_element_by_xpath("//*[@id='header']/ul/div[2]/button[1]").click()
# driver.execute_script('document.getElementById("/html/body").style.padding-right="17px"');
# driver.execute_script('document.getElementById("/html/body").style.overflow="hidden"');
self.driver.find_element_by_xpath("/html/body/div[3]/div[2]/div/div/div[2]/div/form/div[1]/div/div/input").send_keys(username)
self.driver.find_element_by_xpath("/html/body/div[3]/div[2]/div/div/div[2]/div/form/div[2]/div/div/input").send_keys(password)
self.driver.find_element_by_xpath("/html/body/div[3]/div[2]/div/div/div[2]/div/div/button").click()
with open('cookies.json', 'r') as f:
cookies = json.loads(f.read())
#这里需要自己分析cookies的信息内容
for cookie in cookies:
self.driver.add_cookie(cookie_dict={
'domain': cookie['domain'],
'expiry':cookie['expiry'],
'httpOnly':cookie['httpOnly'],
'name': cookie['name'],
'path': '/',
'secure': cookie['secure'],
'value': cookie['value']
})
time.sleep(5)
def createQ(self, newPath):
inputID = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[1]/div[1]/div/div/div[1]/input")
inputID.send_keys(self.ID)
inputTitle = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[1]/div[2]/div/div/div[1]/input")
inputTitle.send_keys(self.dic['Title'])
inputDescription = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[2]/div/div/div/div/div[1]/div[3]/textarea")
inputDescription.send_keys(self.dic['Description'])
inputDescription = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[3]/div[1]/div/div/div/div[1]/div[3]/textarea")
inputDescription.send_keys(self.dic['InputDescription'])
outputDescription = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[3]/div[2]/div/div/div/div[1]/div[3]/textarea")
outputDescription.send_keys(self.dic['OutputDescription'])
inputSample = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[6]/div/div/div/div/div/div[1]/div/div/div/textarea")
inputSample.send_keys(self.dic['InputSample'])
outputSample = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[6]/div/div/div/div/div/div[2]/div/div/div/textarea")
outputSample.send_keys(self.dic['OutputSample'])
hint = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[7]/div/div/div[1]/div[3]/textarea")
hint.send_keys(self.dic['Hint'])
try:
#上传文件
uploadFile = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[11]/div[2]/div/div/div/div/input")
uploadFile.send_keys(newPath + '/' + 'samples.zip')
except:
if EC.alert_is_present:
print("There is something wrong with upload samples.zip")
print("in" + newPath)
return 0
time.sleep(5)
#添加tag
self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[5]/div[2]/div/div/button").click()
inputTag = self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/div[5]/div[2]/div/div/div/div[1]/input")
inputTag.send_keys('蓝桥杯')
#over
self.driver.find_element_by_xpath("//*[@id='app']/div/div[3]/div[1]/div/div/form/button").click()
return 1
def loadInfo(self, infoPath):
self.ID = self.ID + 1;
for key in self.dic:
with open(infoPath + '/' + key + self.postfix, 'r') as f:
self.dic[key] = f.read()
def batchCreateQ(self, path):
self.loadSession()
files = os.listdir(path)
for file in files:
portion = os.path.splitext(file)
if portion[1] == '': #后缀为空表示是文件夹
newPath = path + '/' + portion[0]
self.driver.get(self.url)
self.loadInfo(newPath);
if self.createQ(newPath) == 0:
break;
upload = Upload();
upload.batchCreateQ("D:/safemon/test")
写在最后面吧。因为没有人能看到最后面,我其实很开心我能写出来这个,像之前的那个自动签到,selenium一直带给我很多惊喜,让我觉得“原来爬虫、脚本、Python”也不是这么难。
我虽然口头上说它是傻逼操作,但是我其实特别喜欢它,我其实特别菜,什么都不会,这是我第一次有一种“学计算机不后悔”的成就感,我想把selenium学透,其他的爬虫手段也学透。
我这段时间收集了很多关于爬虫和selenium的资料。
后续会列一个清单。
两句话想送给和我一样迷茫的人:
“一切恐惧 源于未知”
“有需求的时候再去学 学习不是味同嚼蜡一般过一遍教材就好了的”