作者|ALAKH SETHI
编译|VK
来源|Analytics Vidhya
目标检测
我喜欢深度学习。坦率地说,这是一个有大量技术和框架可供倾注和学习的广阔领域。当我看到现实世界中的应用程序,如面部识别和板球跟踪等时,建立深度学习和计算机视觉模型的真正兴奋就来了。
我最喜欢的计算机视觉和深入学习的概念之一是目标检测。建立一个模型的能力,可以通过图像,告诉我什么样的物体存在!

当人类看到一幅图像时,我们在几秒钟内就能识别出感兴趣的物体。机器不是这样的。因此,目标检测是一个在图像中定位目标实例的计算机视觉问题。
好消息是,对象检测应用程序比以往任何时候都更容易开发。目前的方法侧重于端到端的管道,这大大提高了性能,也有助于开发实时用例。
目录
- 一种通用的目标检测框架
- 什么是API?为什么我们需要一个API?
- TensorFlow对象检测API
一种通用的目标检测框架
通常,我们在构建对象检测框架时遵循三个步骤:
- 首先,使用深度学习模型或算法在图像中生成一组的边界框(即对象定位)

- 接下来,为每个边界框提取视觉特征。它们将根据视觉特征进行评估,并确定框中是否存在以及存在哪些对象

- 在最后的后处理步骤中,重叠的框合并为一个边界框(即非最大抑制)

就这样,你已经准备好了你的第一个目标检测框架!
什么是API?为什么我们需要一个API?
API代表应用程序编程接口。API为开发人员提供了一组通用操作,这样他们就不必从头开始编写代码。
想想一个类似于餐馆菜单的API,它提供了一个菜品列表以及每种菜品的描述。当我们指定要吃什么菜时,餐厅会为我们提供成品菜。我们不知道餐厅是如何准备食物的,我们也不需要。
从某种意义上说,api是很好的节省时间的工具。在许多情况下,它们也为用户提供了便利。
因此在本文中,我们将介绍为目标检测任务开发的TensorFlow API。
TensorFlow对象检测API
TensorFlow对象检测API是一个框架,用于创建一个深度学习网络来解决对象检测问题。
在他们的框架中已经有了预训练的模型,他们称之为Model Zoo。这包括在COCO数据集、KITTI数据集和Open Images数据集上训练的预训练模型的集合。
它们对于在新数据集上进行训练时也很有用,可以用来初始化。下表描述了预训练模型中使用的各种体系结构:

MobileNet-SSD
SSD架构是一个单卷积网络,它学习和预测框的位置,并在一次通过中对这些位置进行分类。因此,SSD可以进行端到端的训练。SSD网络由基本架构(本例中为MobileNet)和几个卷积层组成:
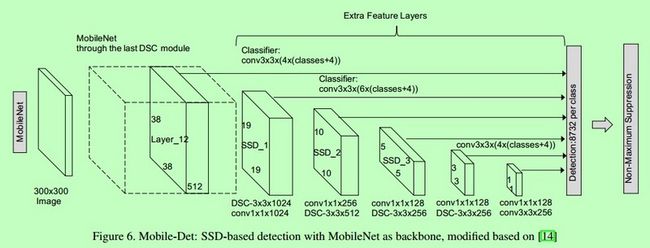
SSD操作特征图以检测边界框的位置。请记住,特征图的大小为Df Df M。对于每个特征图位置,将预测k个边界框。每个边界框都包含以下信息:
- 边界框的4个角的偏移位置(cx、cy、w、h)
- 对应类的概率(c1,c2,…cp)
SSD并不预测盒子的形状,而只是预测盒子的位置。k个边界框各自具有预定的形状。这些形状是在实际训练之前设置的。例如,在上图中,有4个框,表示k=4。
MobileNet-SSD 损失函数
通过最后一组匹配的框,我们可以这样计算损失:
L = 1/N (L class + L box)这里,N是匹配框的总数。"L class"是用于分类的softmax损失,“L box”是表示匹配框错误的L1平滑损失。L1平滑损失是L1损失的一种修正,它对异常值更具鲁棒性。如果N为0,则损失也设置为0。
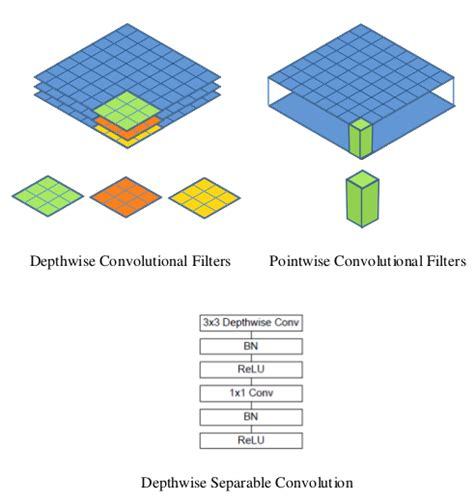
MobileNet
MobileNet模型是基于一种可分解卷积操作的可分离深度卷积。它们将一个标准卷积分解为一个深度卷积和一个称为点卷积的1×1卷积。
对于MobileNets,深度卷积对每个输入通道应用单个滤波器。然后,逐点卷积应用1×1卷积来合并深度卷积的输出。
一个标准的卷积方法,它既能滤波,又能一步将输入合并成一组新的输出。深度可分离卷积将其分为两层,一层用于滤波,另一层用于合并。这种分解有显著减少计算和模型大小的效果。
如何加载模型?
下面是一个循序渐进的过程,遵循Google Colab。你也可以调试查看代码。
安装模型
!pip install -U --pre tensorflow=="2.*"确保已安装pycocotools:
!pip install pycocotools获取tensorflow/models或进入父目录:
import os
import pathlib
if "models" in pathlib.Path.cwd().parts:
while "models" in pathlib.Path.cwd().parts:
os.chdir('..')
elif not pathlib.Path('models').exists():
!git clone --depth 1 https://github.com/tensorflow/models编译protobufs并安装object_detection包:
%%bash
cd models/research/
protoc object_detection/protos/*.proto --python_out=.%%bash
cd models/research
pip install 导入所需的库
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
from IPython.display import display导入对象检测模块:
from object_detection.utils import ops as utils_ops
from object_detection.utils import label_map_util
from object_detection.utils import visualization_utils as vis_util模型准备
加载器
def load_model(model_name):
base_url = 'http://download.tensorflow.org/models/object_detection/'
model_file = model_name + '.tar.gz'
model_dir = tf.keras.utils.get_file(
fname=model_name,
origin=base_url + model_file,
untar=True)
model_dir = pathlib.Path(model_dir)/"saved_model"
model = tf.saved_model.load(str(model_dir))
model = model.signatures['serving_default']
return model加载标签map
标签索引映射到类别名称,以便例如当我们的卷积网络预测5时,我们就可以知道这对应于一架飞机:
# 用于为每个框添加正确标签的字符串列表。
PATH_TO_LABELS = 'models/research/object_detection/data/mscoco_label_map.pbtxt'
category_index = label_map_util.create_category_index_from_labelmap(PATH_TO_LABELS, use_display_name=True)为了简单起见,我们将在两个图像上进行测试:
# 如果要用图像测试代码,只需将图像的路径添加到测试图像路径。
PATH_TO_TEST_IMAGES_DIR = pathlib.Path('models/research/object_detection/test_images')
TEST_IMAGE_PATHS = sorted(list(PATH_TO_TEST_IMAGES_DIR.glob("*.jpg")))
TEST_IMAGE_PATHS基于TensorFlow API的目标检测模型
加载对象检测模型:
model_name = 'ssd_mobilenet_v1_coco_2017_11_17'
detection_model = load_model(model_name)检查模型的输入签名(它需要int8类型的3通道图像):
print(detection_model.inputs)
detection_model.output_dtypes添加包装函数以调用模型并清除输出:
def run_inference_for_single_image(model, image):
image = np.asarray(image)
# 输入必须是张量,请使用“tf.convert to tensor”将其转换。
input_tensor = tf.convert_to_tensor(image)
# 模型需要一批图像,因此添加一个带有“tf.newaxis”的轴。
input_tensor = input_tensor[tf.newaxis,...]
#运行推理
output_dict = model(input_tensor)
#所有输出都是张量。
# 转换为numpy数组,并获取索引[0]以删除批处理维度。
# 我们只对第一个num_detections检测感兴趣。
num_detections = int(output_dict.pop('num_detections'))
output_dict = {key:value[0, :num_detections].numpy()
for key,value in output_dict.items()}
output_dict['num_detections'] = num_detections
# detection_classes应为int。.
output_dict['detection_classes'] = output_dict['detection_classes'].astype(np.int64)
#使用mask处理模型:
if 'detection_masks' in output_dict:
# 将bbox mask重新设置为图像大小.
detection_masks_reframed = utils_ops.reframe_box_masks_to_image_masks(
output_dict['detection_masks'], output_dict['detection_boxes'],
image.shape[0], image.shape[1])
detection_masks_reframed = tf.cast(detection_masks_reframed > 0.5,
tf.uint8)
output_dict['detection_masks_reframed'] = detection_masks_reframed.numpy()
return output_dict在每个测试图像上运行它并显示结果:
def show_inference(model, image_path):
# 稍后将使用基于数组的图像表示,以便准备带有框和标签的结果图像。
image_np = np.array(Image.open(image_path))
# 检测.
output_dict = run_inference_for_single_image(model, image_np)
# 可视化检测结果
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
output_dict['detection_boxes'],
output_dict['detection_classes'],
output_dict['detection_scores'],
category_index,
instance_masks=output_dict.get('detection_masks_reframed', None),
use_normalized_coordinates=True,
line_thickness=8)
display(Image.fromarray(image_np))for image_path in TEST_IMAGE_PATHS:
show_inference(detection_model, image_path)下面是在ssd_mobilenet_v1_coco 上测试的示例图像

Inception-SSD
Inception-SSD模型的架构与上述MobileNet SSD模型的架构相似。区别在于,这里的基本架构是Inception模型。
如何加载模型?
只需在API的检测部分更改模型名称:
model_name = 'ssd_inception_v1_coco_2017_11_17'
detection_model = load_model(model_name)然后按照前面的步骤进行预测。
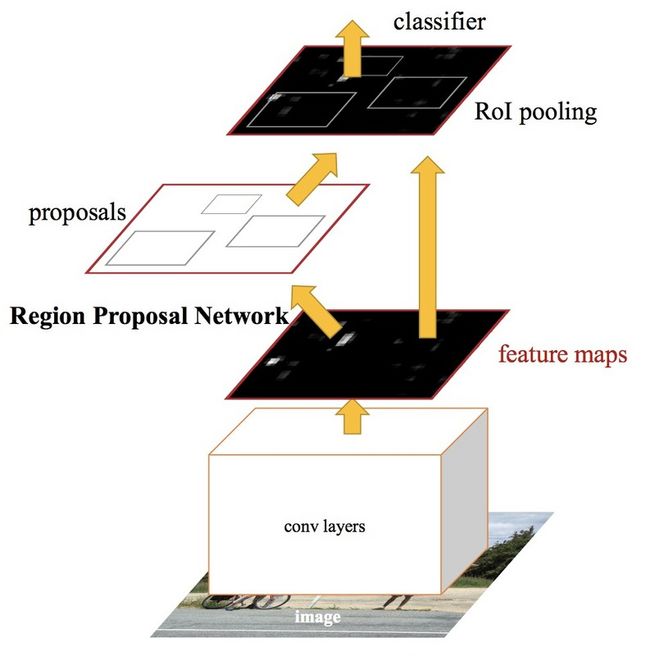
Faster RCNN
目前最先进的目标检测网络依赖于区域建议算法来假设目标位置。SPPnet和Fast-R-CNN等技术的发展减少了这些检测网络的运行时间。
在Faster RCNN中,我们将输入图像输入到卷积神经网络中生成卷积特征映射。从卷积特征图中,我们识别出建议的区域并将其扭曲成正方形。通过使用一个RoI(感兴趣区域层)层,我们将它们重塑成一个固定的大小,这样它就可以被送入一个全连接层。
从RoI特征向量出发,我们使用softmax层来预测提出区域的类别以及边界框的偏移值。
如何加载模型?
只需再次更改API的检测部分中的模型名称:
model_name = 'faster_rcnn_resnet101_coco'
detection_model = load_model(model_name)然后使用与前面相同的步骤进行预测。下面是给faster RCNN模型的示例图像:
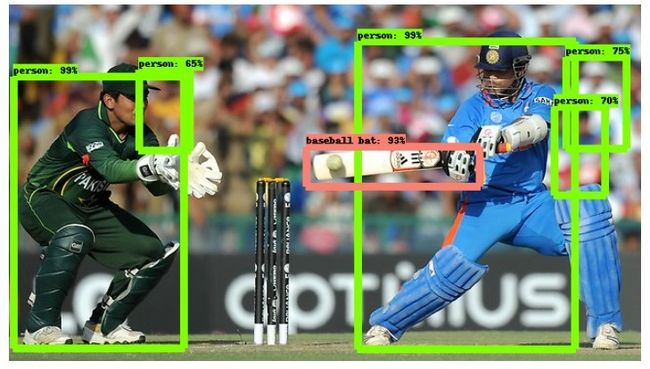
如你所见,这比SSD Mobilenet模型要好得多。但它比之前的模型慢得多。
你应该选择哪种目标检测模型?
根据你的特定需求,你可以从TensorFlow API中选择正确的模型。如果我们想要一个高速模型,SSD网络的工作效果最好。顾名思义,SSD网络一次性确定了所有的边界盒概率;因此,它是一个速度更快的模型。
但是,使用SSD,你可以以牺牲准确性为代价获得速度。有了FasterRCNN,我们将获得高精度,但是速度变慢。
原文链接:https://www.analyticsvidhya.c...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/