小白都能看懂的HashMap面试问题
目录
- 前言
- 简单回顾
- HashMap的内部数据结构
- HashMap允许空键空值么
- 影响HashMap性能的重要参数
- HashMap的工作原理
- HashMap中put()的工作原理
- `HashMap 的底层数组长度为何总是2的n次方`
- 1.8中做了哪些优化优化?
- `HashMap线程安全方面会出现什么问题`
- 难点剖析
- 为什么HashMap的底层数组长度为何总是2的n次方
- 第一:当length为2的N次方的时候,h & (length-1) = h % length
- 第二:当length为2的N次方的时候,数据分布均匀,减少冲突
- 那么为什么默认是16呢?怎么不是4?不是8?
- HashMap线程安全方面会出现什么问题
- 为什么1.8改用红黑树
- 1.8中的扩容为什么逻辑判断更简单
前言
对于HashMap,可谓是面试必问的点。无论你是刚毕业的大学生,还是工作三年的高级开发工程师。HashMap可谓是JDK源码中比较经典的源码设计。
在上学的时候就知道它的重要性,但是有一些比较复杂的地方当时很难理解,只是模糊记忆,面试官问的时候也是将记住的答案背下来,其实在面试官眼中早就露馅了。
简单回顾
一些基础的问题我们就简单回顾一下就好。其中要讲解的难点先标注,后文进行详细剖析。
HashMap的内部数据结构
数组 + 链表/红黑树
HashMap允许空键空值么
HashMap最多只允许一个键为Null(多条会覆盖),但允许多个值为Null
影响HashMap性能的重要参数
初始容量:创建哈希表(数组)时桶的数量,默认为 16
负载因子:哈希表在其容量自动增加之前可以达到多满的一种尺度,默认为 0.75
HashMap的工作原理
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象
HashMap中put()的工作原理
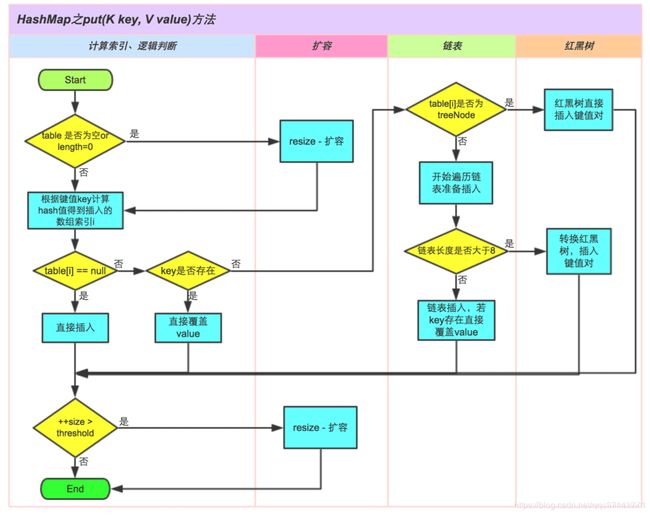
HashMap 的底层数组长度为何总是2的n次方
HashMap根据用户传入的初始化容量,利用无符号右移和按位或运算等方式计算出第一个大于该数的2的幂。
- `使数据分布均匀,减少碰撞
- 当length为2的n次方时,h&(length - 1) 就相当于对length取模,而且在速度、效率上比直接取模要快得多
1.8中做了哪些优化优化?
数组+链表改成了数组+链表或红黑树链表的插入方式从头插法改成了尾插法扩容的时候1.7需要对原数组中的元素进行重新hash定位在新数组的位置,1.8采用更简单的判断逻辑,位置不变或索引+旧容量大小;- 在插入时,1.7先判断是否需要扩容,再插入,1.8先进行插入,插入完成再判断是否需要扩容;
HashMap线程安全方面会出现什么问题
- 在jdk1.7中,在多线程环境下,扩容时会造成环形链或数据丢失。
- 在jdk1.8中,在多线程环境下,会发生数据覆盖的情况
难点剖析
为什么HashMap的底层数组长度为何总是2的n次方
这里我觉得可以用逆向思维来解释这个问题,我们计算桶的位置完全可以使用h % length,如果这个length是随便设定值的话当然也可以,但是如果你对它进行研究,设计一个合理的值得话,那么将对HashMap的性能发生翻天覆地的变化。
没错,JDK源码作者就发现了,那就是当length为2的N次方的时候,那么,为什么这么说呢?
第一:当length为2的N次方的时候,h & (length-1) = h % length
为什么&效率更高呢?因为位运算直接对内存数据进行操作,不需要转成十进制,所以位运算要比取模运算的效率更高
第二:当length为2的N次方的时候,数据分布均匀,减少冲突
此时我们基于第一个原因进行分析,此时hash策略为h & (length-1)。
我们来举例当length为奇数、偶数时的情况:
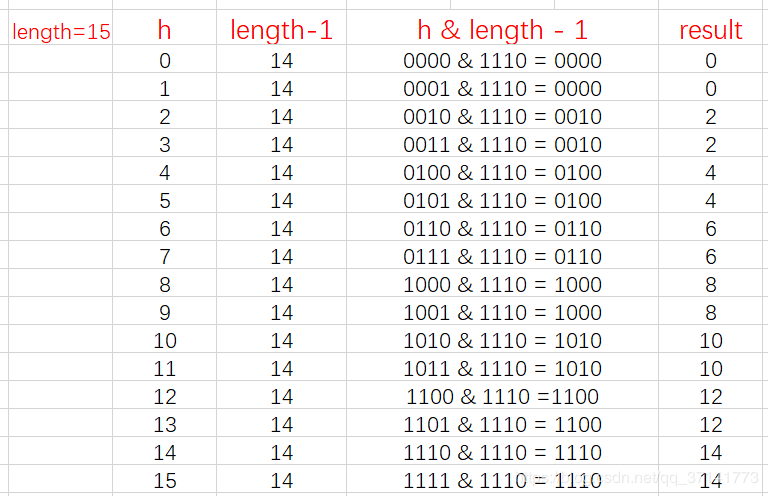
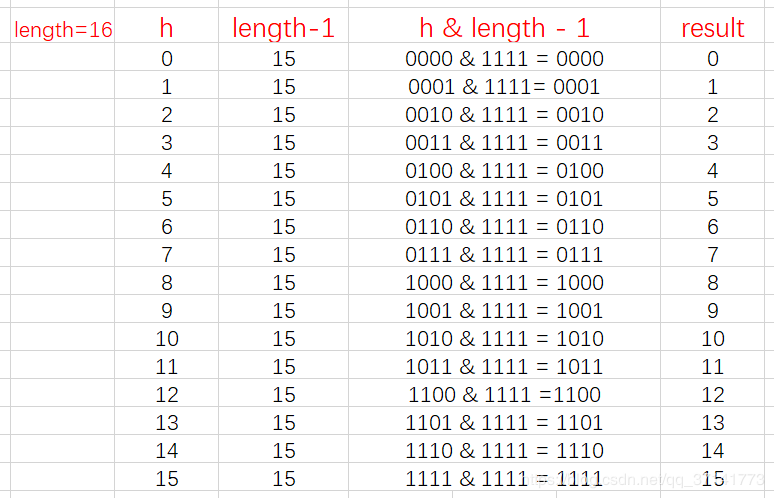
从上面的图表中我们可以看到,当 length 为15时总共发生了8次碰撞,同时发现空间浪费非常大,因为在 1、3、5、7、9、11、13、15 这八处没有存放数据。
这是因为hash值在与14(即 1110)进行&运算时,得到的结果最后一位永远都是0,那么最后一位为1的位置即 0001、0011、0101、0111、1001、1011、1101、1111位置处是不可能存储数据的。这样,空间的减少会导致碰撞几率的进一步增加,从而就会导致查询速度慢。
而当length为16时,length – 1 = 15, 即 1111,那么,在进行低位&运算时,值总是与原来hash值相同,而进行高位运算时,其值等于其低位值。所以,当 length=2^n 时,不同的hash值发生碰撞的概率比较小,这样就会使得数据在table数组中分布较均匀,查询速度也较快。
如果上面这句话大家还看不明白的话,可以多试一些数,就可以发现规律。当length为奇数时,length-1为偶数,而偶数二进制的最后一位永远为0,那么与其进行 & 运算,得到的二进制数最后一位永远为0,那么结果一定是偶数,那么就会导致下标为奇数的桶永远不会放置数据,这就不符合我们均匀放置,减少冲突的要求了。
那么可能钻牛角尖的同学还会问,那length是偶数不就行了么,为什么一定要是2的N次方,这不就又回到第一点原因了么?JDK 的工程师把各种位运算运用到了极致,想尽各种办法优化效率。
那么为什么默认是16呢?怎么不是4?不是8?
关于这个默认容量的选择,JDK并没有给出官方解释,那么这应该就是个经验值,既然一定要设置一个默认的2^n 作为初始值,那么就需要在效率和内存使用上做一个权衡。这个值既不能太小,也不能太大。
太小了就有可能频繁发生扩容,影响效率。太大了又浪费空间,不划算。
所以,16就作为一个经验值被采用了。
HashMap线程安全方面会出现什么问题
1.put的时候导致的多线程数据不一致
比如有两个线程A和B,首先A希望插入一个key-valu对到HashMap中,首先计算记录所要落到的 hash桶的索引坐标,然后获取到该桶里面的链表头结点,此时线程A的时间片用完了,而此时线程B被调度得以执行,和线程A一样执行,只不过线程B成功将记录插到了桶里面,假设线程A插入的记录计算出来的 hash桶索引和线程B要插入的记录计算出来的 hash桶索引是一样的,那么当线程B成功插入之后,线程A再次被调度运行时,它依然持有过期的链表头但是它对此一无所知,以至于它认为它应该这样做,如此一来就覆盖了线程B插入的记录,这样线程B插入的记录就凭空消失了,造成了数据不一致的行为。
2.resize而引起死循环
这种情况发生在HashMap自动扩容时,当2个线程同时检测到元素个数超过 数组大小 ×负载因子。此时2个线程会在put()方法中调用了resize(),两个线程同时修改一个链表结构会产生一个循环链表(JDK1.7中,会出现resize前后元素顺序倒置的情况)。接下来再想通过get()获取某一个元素,就会出现死循环。
如果还不明白的话看这两篇文章就可以:
HashMap死循环
HashMap线程不安全的体现
为什么1.8改用红黑树
比如某些人通过找到你的hash碰撞值,来让你的HashMap不断地产生碰撞,那么相同key位置的链表就会不断增长,当你需要对这个HashMap的相应位置进行查询的时候,就会去循环遍历这个超级大的链表,性能及其地下。java8使用红黑树来替代超过8个节点数的链表后,查询方式性能得到了很好的提升,从原来的是O(n)到O(logn)。
1.8中的扩容为什么逻辑判断更简单
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
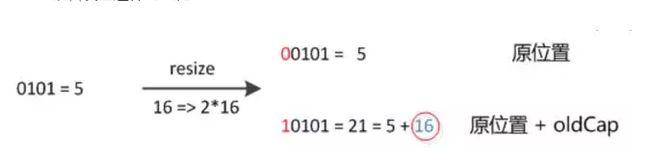
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:
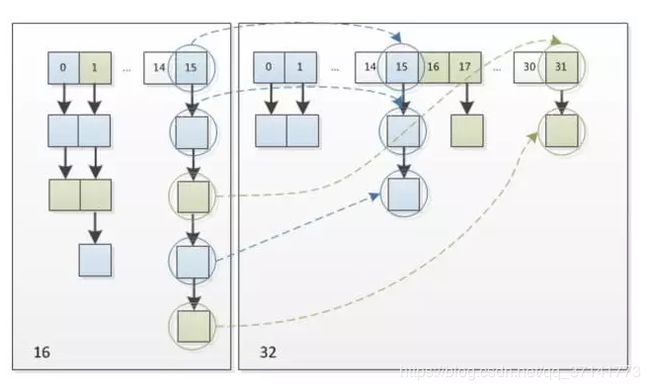
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
以上有部分内容为个人理解,有误请指正,谢谢
欢迎访问我的个人小站:我爱吃土豆