MirrorGAN
CVPR 2019 《MirrorGAN: Learning Text-to-image Generation by Redescription》

在Text-to-Image的任务中,我们需要根据对图像的描述文本来生成和它语义一致的图像,同时也要保证生成的图像足够真实。在此之前已有很多GAN的变体可以完成相关的工作,例如StackGAN、StackGAN++、GAN-INT-CLS、AttenGAN……,以及在CVPR 2019上发表的StoryGAN、ObjGAN……
更多Text-to-Image的论文可见:http://bbs.cvmart.net/topics/356/arbitrary-text-to-image-papers-tu-xiang-wen-ben-sheng-cheng-lun-wen-hui-zong
在上述的诸多方法中,大多数将描述文本作为输入传入模型,希望生成和描述文本语义一致且足够真实的图像。为了保证生成图像的效果,通常需要设置各种损失项,其中常见的做法是将生成的图像和描述文本所指的真实图像进行比较,使用一些度量方式进行衡量两者的差异,从而指导生成器生成更接近真实的图像。而MirrorGAN在前面的模型上多加了一步,它不仅完成了Text-to-Image的工作,而且还完成了Image-to-Text的部分,将生成图像转换得到的描述文本与原始的描述文本进行比较,从而可以得到更好的梯度信息,最后得到的模型的效果更好。

MirrorGAN全称a novel global-local attentive and semantic-preserving text-to-image-to-text framework,从名字中我们可以看出它所关注的个点:全局-局部的注意力、语义保留和T2I2T。整个模型主要包括三个重要的部分:
- semantic text embedding module,STEM:文本语义嵌入模型,用于将描述文本生成更符合语义的词和句子两个层级的嵌入向量
- global-local collaborative attentive module,GLAM:全局和局部的注意力协同模块,通过在两个层级上的注意力机制,使用一致建联的结构,逐步生成语义一致且逼真的图像
- semantic text regeneration and alignment module,STREAM:语义文本再生和对齐模块,用于最后的根据生成图像再生成和输入语义对齐的描述文本
模型涉及的损失项为visual realism adversarial loss、text-image paired semantic consistency adversarial loss和text-semantics reconstruction loss。
关于注意力机制可见另一篇博文:Transformer
MirrorGAN
模型的整体架构是如下这种镜像的结构:

STEM
STEM根据给定的关于真实图像的描述文本生成局部性词级别的嵌入向量 w w w和全局性句子级别的嵌入向量 s s s。
the semantic text embedding module to embed the given text description into local word-level features and global sentence-level features
它的基本结构就是一个循环神经网络(RNN),中间第 i i i个隐状态(latent state)就是第 i i i个单词的嵌入向量,最后一个隐状态就是句子的嵌入向量。 w , s = R N N ( T ) w, s=R N N(T) w,s=RNN(T)其中 T = { T l ∣ l = 0 , … , L − 1 } T=\left\{T_{l} | l=0, \ldots, L-1\right\} T={Tl∣l=0,…,L−1}, w = { w l ∣ l = 0 , … , L − 1 } ∈ R D × L w=\left\{w^{l} | l=0, \ldots, L-1\right\} \in \mathbb{R}^{D \times L} w={wl∣l=0,…,L−1}∈RD×L。
由于不同的描述文本可能具有相似的语义,那么生成的图像就同样应是相似的。因此,为了提高模型的鲁棒性,这里作者还使用了StackGAN中提出的conditioning augmentation method,从而产生更多的图像-文本对数据,增强对条件文本流形上的小扰动的鲁棒性。 s c a = F c a ( s ) s_{c a}=F_{c a}(s) sca=Fca(s)
《StackGAN:Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks》探析
GLAM
GLAM通过连续叠加三个图像生成网络,构造一个多级级联发生器,基本得网络模型都是采用AttenGAN的相关部分。 { F 0 , F 1 , … , F m − 1 } \left\{F_{0}, F_{1}, \ldots, F_{m-1}\right\} {F0,F1,…,Fm−1}表示 m m m个视觉特征转换器, { G 0 , G 1 , … , G m − 1 } \left\{G_{0}, G_{1}, \ldots, G_{m-1}\right\} {G0,G1,…,Gm−1}表示 m m m个图像生成器。那么在每一阶段根据视觉特征 f i f_{i} fi生成图像 I i I_{i} Ii的过程如下所示:
f 0 = F 0 ( z , s c a ) f i = F i ( f i − 1 , F a t t 1 ( f i − 1 , w , s c a ) ) , i ∈ { 1 , 2 , … , m − 1 } I i = G i ( f i ) , i ∈ { 0 , 1 , 2 , … , m − 1 } \begin{aligned} f_{0} &=F_{0}\left(z, s_{c a}\right) \\ f_{i} &=F_{i}\left(f_{i-1}, F_{a t t_{1}}\left(f_{i-1}, w, s_{c a}\right)\right), i \in\{1,2, \ldots, m-1\} \\ I_{i} &=G_{i}\left(f_{i}\right), i \in\{0,1,2, \ldots, m-1\} \end{aligned} f0fiIi=F0(z,sca)=Fi(fi−1,Fatt1(fi−1,w,sca)),i∈{1,2,…,m−1}=Gi(fi),i∈{0,1,2,…,m−1}
其中 F a t t i F_{att_{i}} Fatti指的就是GLAM模块。
首先使用word-level的注意力模型生成word-context的注意力特征,其中词嵌入向量 w w w需要通过感知层 U i − 1 U_{i-1} Ui−1将其转换到和视觉特征公共的语义空间中,从而得到 U i − 1 w U_{i-1}w Ui−1w,然后将其和视觉特征 f i − 1 f_{i-1} fi−1相乘得到注意力分数。最后通过计算注意力分数和注意力上下文间的内积得到注意力上下文特征(the attentive word-context feature)。
A t t i − 1 w = ∑ l = 0 L − 1 ( U i − 1 w l ) ( softmax ( f i − 1 T ( U i − 1 w l ) ) ) T A t t_{i-1}^{w}=\sum_{l=0}^{L-1}\left(U_{i-1} w^{l}\right)\left(\operatorname{softmax}\left(f_{i-1}^{T}\left(U_{i-1} w^{l}\right)\right)\right)^{T} Atti−1w=l=0∑L−1(Ui−1wl)(softmax(fi−1T(Ui−1wl)))T
同样的使用sentence-level的注意力模型来加强生成器对于全局的约束。 A t t i − 1 s = ( V i − 1 s c a ) ∘ ( softmax ( f i − 1 ∘ ( V i − 1 s c a ) ) ) A t t_{i-1}^{s}=\left(V_{i-1} s_{c a}\right) \circ\left(\operatorname{softmax}\left(f_{i-1} \circ\left(V_{i-1} s_{c a}\right)\right)\right) Atti−1s=(Vi−1sca)∘(softmax(fi−1∘(Vi−1sca)))
STREAM
STREAM用于从生成的图像中重新生成文本描述,使图像在语义上与给定的文本描述保持一致。这里作者使用的是一个简单的Encoder-Decoder架构的图片标题框架。其中编码器是一个在ImageNet上预训练过的CNN,解码器为RNN。生成过程如下所示:
x − 1 = C N N ( I m − 1 ) x t = W e T t , t ∈ { 0 , … L − 1 } p t + 1 = R N N ( x t ) , t ∈ { 0 , … L − 1 } \begin{array}{l}{x_{-1}=C N N\left(I_{m-1}\right)} \\ {x_{t}=W_{e} T_{t}, t \in\{0, \ldots L-1\}} \\ {p_{t+1}=R N N\left(x_{t}\right), t \in\{0, \ldots L-1\}}\end{array} x−1=CNN(Im−1)xt=WeTt,t∈{0,…L−1}pt+1=RNN(xt),t∈{0,…L−1}
作者指出STREAM需要在MirrorGAN之前的部分训练之前预训练好,否则会导致模型训练过程的不稳定,同时良妃时间和内存资源。
目标函数
如上所述,整体的损失项包括visual realism adversarial loss、text-image paired semantic consistency adversarial loss和text-semantics reconstruction loss三个。
其中前两个如下所示

另一个是基于交叉熵的文本语义重建损失,希望从生成图像中重建的文本描述和真实的描述文本相近
L stream = − ∑ t = 0 L − 1 log p t ( T t ) \mathcal{L}_{\text { stream }}=-\sum_{t=0}^{L-1} \log p_{t}\left(T_{t}\right) L stream =−t=0∑L−1logpt(Tt)
因此生成器的目标函数为 L G = ∑ i = 0 m − 1 L G t + λ L stream \mathcal{L}_{G}=\sum_{i=0}^{m-1} \mathcal{L}_{G_{t}}+\lambda \mathcal{L}_{\text {stream}} LG=∑i=0m−1LGt+λLstream。
判别器希望最大程度的判别出图像的真假,其中某个判别器的目标函数为

总判别器的目标函数为 L D = ∑ i = 0 m − 1 L D i \mathcal{L}_{D}=\sum_{i=0}^{m-1} \mathcal{L}_{D_{i}} LD=∑i=0m−1LDi
实验
基准模型:GAN-INT-CLS 、GAWWN、 StackGAN 、 StackGAN++ 、PPGN、AttnGAN。
数据集:CUB、COCO
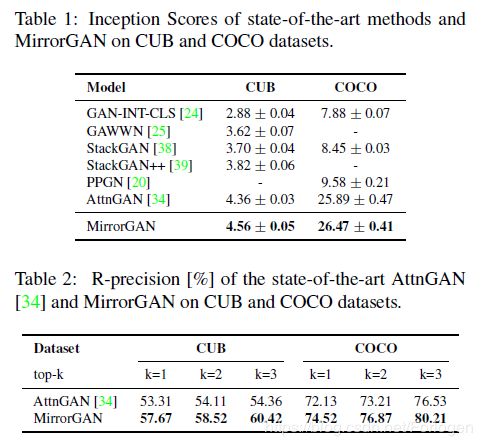
度量指标:Inception score、R-precision
生成图像质量对比,直观上就可以看出Mirror的效果更好一些

定量评估上也可以看出MirrorGAN的效果更好,在CUB和COCO两个数据集上都提高了Inception score和R-precision
另外对参数 λ \lambda λ的取值不同对于模型的效果会有影响,通过实验证实了在 λ = 20 \lambda = 20 λ=20时,模型整体效果最好

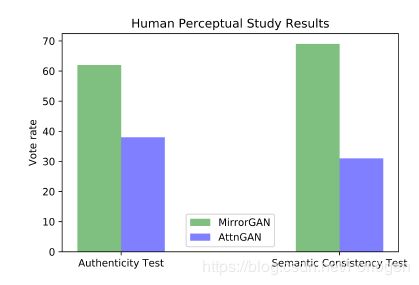
处理使用度量指标评估外,在人的直接感知评估下也可以看出MirrorGAN生成的图像更真实、更符合描述文本的语义
通过可视化注意力层的图像可以看出模型可以较好的关注不同的词来生成对应部分的图像

最后作者通过实验表明了MirrorGAN可以根据描述文本中的细微改变生成不同的图像

总结
整体看下来,论文的基本思想并不复杂,而且模型的架构大部分也是继承自AttenGAN,但最后实验的效果很好。其中比较新奇的是STREAM,希望后面放出源码后对其进行进一步的研究,并考虑将其应用到其他的方向。