Ceph数据恢复初探
大家好,我是焱融云存储系统的研发猿小焱,本文由我和大家一起探讨下Ceph数据恢复相关的知识。
众所周知,Ceph是近年来最为炙手可热的开源分布式存储系统。跟其他分布式存储系统不一样的是,Ceph在称之为RADOS的核心对象存储架构之上,提供了块存储、文件存储以及对象存储的接口,因此Ceph可以称之为统一存储(Unified Storage)。而本文我们将讨论的是Ceph RADOS核心层面的数据恢复逻辑。
不过和一般分布式系统一样的是,Ceph同样使用多副本机制来保证数据的高可靠性(注:EC在实现层面可以理解为副本机制的一种),给定一份数据,Ceph在后台自动存储多份副本(一般使用3个副本),从而使得在硬盘损毁、服务器故障、机柜停电等故障情况下,不会出现数据丢失,甚至数据仍能保持在线。不过在故障发生后,Ceph需要及时做故障恢复,将丢失的数据副本补全,以维系持续的数据高可靠性。
因此多副本机制是分布式存储系统的核心机制之一,它带来了数据高可靠性,也提高了数据可用性。然而事情是没有十全十美的,多副本机制同时带来了分布式系统的最大问题之一:数据一致性。不过Ceph数据一致性并非本文的主题,以后有机会小焱再跟大家一起分享,本文仅会聊到数据恢复相关的数据一致性。
综上,我们讨论了为什么Ceph采用多副本机制,以及需要通过数据恢复及时补全故障带来的副本缺失。我们也讨论了保持数据一致性是故障恢复流程的难点之一。除此之外,Ceph数据恢复(或者说分布式存储数据恢复)还有其他几个难点:
感知故障,并自动触发数据恢复。做到这点,能减轻运维压力,也使发现和处理故障更为及时。
尽量降低数据恢复过程中对集群资源的消耗。比如最为明显的,如何减少网络带宽的占用。Ceph恢复数据的时候,是拷贝整个4M对象,还是只恢复有差异的数据,这两种方式直接影响网络间传输的数据量。
数据恢复是否影响用户的线上业务,Ceph是如何控制和降低这个影响的?
带着这几个问题,下面小焱和大家一起来探讨Ceph数据恢复的流程和关键细节。
Ceph故障处理的流程
我们先来看一下Ceph故障处理的主要流程,主要分为三大步骤:
感知集群状态:首先Ceph要能通过某种方法,及时感知集群故障,确定集群中节点的状态,判定哪些节点离开了集群,为确定哪些数据的副本受到故障影响提供权威依据。
确定受故障影响的数据:Ceph根据新的集群状态计算和判定副本缺失的数据。
恢复受影响的数据。
对于这些步骤,我们逐个深入来探讨一下。
感知集群状态
Ceph集群分为MON集群和OSD集群两大部分。其中MON集群由奇数个Monitor节点组成,这些Monitor节点通过Paxos算法组成一个决策者集群,共同作出关键集群事件的决策和广播。“OSD节点离开”和“OSD节点加入”就是其中两个关键的集群事件。

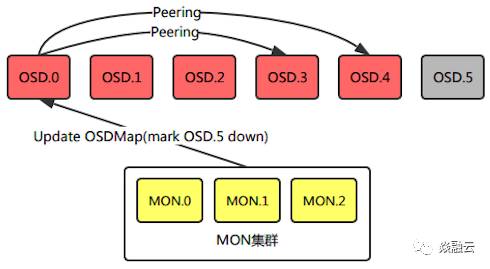
MON集群管理着整个Ceph集群的成员状态,将OSD节点的状态信息存放在OSDMap中,OSD节点定期向MON和对等OSD(Peer OSD)发送心跳包,声明自己处于在线状态。MON接收来自OSD的心跳消息确认OSD在线;同时,MON也接收来自OSD对于Peer OSD的故障检测。MON根据心跳间隔等信息判定OSD是否在线,同时更新OSDMap并向各个节点通告最新集群状态。比如某台服务器宕机,其上OSD节点和MON集群的心跳超时或是这些OSD的对等OSD发送的失败通告超过阈值后,这些OSD将被MON集群判定为离线。

判定OSD节点离线后,Ceph将最新的OSDMap通过消息机制随机分发给一个OSD,客户端(对等OSD)处理IO请求的时候发现自身的OSDMap版本过低,会向MON请求最新的OSDMap。每个OSD中PG的另外两个副本可能在集群任意OSD中,借此经过一段时间的传播,最终整个集群的OSD都会接收到OSDMap的更新。
确定受影响的数据
Ceph中对象数据的维护由PG(Placement Group)负责,PG作为Ceph中最小的数据管理单元,直接管理对象数据,每个OSD都会管理一定数量的PG。客户端对于对象数据的IO请求,会根据对象ID的Hash值均衡分布在各个PG中。PG中维护了一份PGLog,用来记录该PG的数据变化,这些记录会被持久化记录到后端存储中。
PGLog中记录了每次操作的数据和PG的版本,每次数据变更操作都会使PG的版本自增,PGLog中默认保存3000条记录,PG会定期触发Trim操作清理多余的PGLog。通常情况下,在同一个PG的不同副本中的PGLog应该是一致的,故障发生后,不同副本的PGLog可能会处于不一致的状态。
OSD在收到OSDMap更新消息后,会扫描该OSD下所有的PG,清理已经不存在的PG(已经被删除等情况),对PG进行初始化,如果该OSD上的PG是Primary PG的话,PG将进行Peering操作。在Peering的过程中,PG会根据PGLog检查多个副本的一致性,并尝试计算PG的不同副本的数据缺失,最后得到一份完整的对象缺失列表,用作后续进行Recovery操作时的依据。对于无法根据PGLog计算丢失数据的PG,需要通过Backfill操作拷贝整个PG的数据来恢复。需要注意的是,在这Peering过程完成前,PG的数据都是不可靠的,因此在Peering过程中PG会暂停所有客户端的IO请求。
数据恢复
Peering完成后,PG进入Active状态,并根据PG的副本状态将自己标记为Degraded/Undersized状态,在Degraded状态下,PGLog存储的日志数量默认会扩展到10000条记录,提供更多的数据记录便于副本节点上线后的数据恢复。进入Active状态后,PG可用并开始接受数据IO的请求,并根据Peering的信息决定是否进行Recovery和Backfill操作。
Primary PG将根据对象的缺失列表进行具体对象的数据拷贝,对于Replica PG缺失的数据Primary 会通过Push操作推送缺失数据,对于Primary PG缺失的数据会通过Pull操作从副本获取缺失数据。在恢复操作过程中,PG会传输完整4M大小的对象。对于无法依靠PGLog进行Recovery的,PG将进行Backfill操作,进行数据的全量拷贝。待各个副本的数据完全同步后,PG被标记为Clean状态,副本数据保持一致,数据恢复完成。
控制恢复影响
通过Ceph处理故障的流程,我们可以看到Ceph如何应对集群故障常见的问题。首先是减少对资源的消耗:在断电重启这类故障中,Ceph可以只恢复有变化的数据,从而减少数据恢复量;另一方面,MON不会主动向所有OSD推送集群状态,而是采用OSD主动获取最新OSDMap的方式防止大规模集群发生故障场景下产生突发流量。
另外,由于Ceph的IO流程必须要通过Primary PG进行,一旦Primary PG所在的OSD宕机,IO将无法正常进行。为了保证恢复过程中不会中断正常的业务IO,MON会分配PG Temp临时处理IO请求,在数据恢复完成后再移除PG Temp。
同时在整个恢复过程中,Ceph也允许用户通过配置文件调整恢复线程数,同时进行的恢复操作数,恢复数据网络传输优先级等相关参数来限制恢复的速度,从而降低对正常业务的影响。
总结
以上小焱跟大家一起探讨了Ceph数据恢复的主要技术流程,以及关键点。可以看出Ceph在数据恢复方面,设计和细节做的都相当不错。但是,目前Ceph恢复的颗粒度仍然比较大,需要更多的IO消耗;并且,被动的OSDMap更新可能会导致PG不会及时恢复故障数据,在一段时间内数据可靠性会降低。
同时,提醒我们在Ceph日常处理故障时需要注意的细节:
PGLog是Ceph进行数据恢复的重要依据,但是记录的日志数量有限,所以在发生故障后,尽快让故障节点重新上线,尽量避免产生Backfill操作,能极大的缩短恢复时间。
PG在Peering阶段会阻塞客户端IO,所以要保证PG能快速进行Peering。
如果在故障过程中PGLog丢失,导致无法完成Peering,PG会进入Incomplete状态,这种情况下需要让故障节点上线帮助完成数据修复。
虽然Ceph的Recovery操作能够避免很多不必要的对象数据恢复,但是使用的还是完全对象拷贝,进一步的优化,可以考虑在PGLog中记录操作对象的具体数据位置、或是利用类似rsync的机制,只恢复对象副本间的差异数据。
本文通过简单梳理Ceph对于集群故障的处理,帮助我们在日常应用中更好的维护Ceph集群,保证业务数据持续可用。未来我们将陆续推出一系列的文章,解析云计算/存储相关技术的细节、分析应用场景中的问题和解决方案。请期待我们焱融云的下一篇技术文章。