大数据实战项目------中国移动运营分析实时监控平台 || 项目需求实现(文章最后有数据文件)
1.业务概况(显示总订单量、订单成功量、总金额、花费时间)
2.业务详细概述(每小时的充值订单量、每小时的充值成功订单量)
3.业务质量(每个省份的充值成功订单量)
4.实时统计每分钟的充值金额和订单量
整体步骤:
提取数据库中存储的偏移量–>广播省份映射关系–>获取kafka的数据–>数据处理(JSON对象解析,省份、时间、结果、费用)
–>计算业务概况(显示总订单量、订单成功量、总金额、花费时间)–>业务概述(每小时的充值总订单量,每小时的成功订单量)
—>业务质量(每个省份的成功订单量)—>实时统计每分钟的充值金额和订单量
下面是代码封装的包

项目需求实现:
1)用flume收集数据,放入到kafka,下面是详细配置。
#定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 描述和配置source组件:r1
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /usr/local/datas/flume
a1.sources.r1.fileHeader = true
# 描述和配置sink组件:k1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = flumeLogs
a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.ki.kafka.producer.compression.type = snappy
# 描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
2)用SparkStreaming去消费kafka里面的数据前,做一些Kafka参数的配置以及放入Redis数据库所需要的配置。
(1)在IDEA中配置kafka和Redis相关参数,方便获取kafka里面的数据并且存储到redis里面
import com.typesafe.config.{Config, ConfigFactory}
import org.apache.kafka.common.serialization.StringDeserializer
object AppParams {
/**
* 解析application.conf配置文件
* 加载resource下面的配置文件,默认规则:application.conf->application.json->application.properties
*/
private lazy val config: Config = ConfigFactory.load()
/**
* 返回订阅的主题
*/
val topic = config.getString("kafka.topic").split(",")
/**
* kafka集群所在的主机和端口
*/
val borkers = config.getString("kafka.broker.list")
/**
* 消费者的ID
*/
val groupId = config.getString("kafka.group.id")
/**
* kafka的相关参数
*/
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> borkers,
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> groupId,
"auto.offset.reset" -> "earliest",
"enable.auto.commit" -> "false"
)
/**
* redis服务器地址
*/
val redisHost = config.getString("redis.host")
/**
* 将数据写入到哪个库
*/
val selectDBIndex = config.getInt("redis.db.index")
/**
* 省份code和省份名称的映射关系
*/
import scala.collection.JavaConversions._
val pCode2PName = config.getObject("pcode2pname").unwrapped().toMap
}
(2)方便计算订单完成所需要的时间,封装了一个类
import org.apache.commons.lang3.time.FastDateFormat
object CaculateTools {
// 非线程安全的
//private val format = new SimpleDateFormat("yyyyMMddHHmmssSSS")
// 线程安全的DateFormat
private val format = FastDateFormat.getInstance("yyyyMMddHHmmssSSS")
/**
* 计算时间差
*/
def caculateTime(startTime:String,endTime:String):Long = {
val start = startTime.substring(0,17)
format.parse(endTime).getTime - format.parse(start).getTime
}
}
(3)做一个Redis池去操作Redis中的数据
import com.alibaba.fastjson.JSON
import org.apache.commons.pool2.impl.GenericObjectPoolConfig
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.rdd.RDD
import redis.clients.jedis.JedisPool
object Jpools {
private val poolConfig = new GenericObjectPoolConfig()
poolConfig.setMaxIdle(5) //最大的空闲连接数,连接池中最大的空闲连接数,默认是8
poolConfig.setMaxTotal(2000) //只支持最大的连接数,连接池中最大的连接数,默认是8
//连接池是私有的不能对外公开访问
private lazy val jedisPool = new JedisPool(poolConfig, AppParams.redisHost)
def getJedis={
val jedis = jedisPool.getResource
jedis.select(AppParams.selectDBIndex)
jedis
}
}
(4)每次放入Redis前需要判断偏移量,防止数据重复以及消耗资源
import org.apache.kafka.common.TopicPartition
import org.apache.spark.streaming.kafka010.OffsetRange
import scalikejdbc.{DB, SQL}
import scalikejdbc.config.DBs
object OffsetManager {
DBs.setup()
/**
* 获取自己存储的偏移量信息
*/
def getMydbCurrentOffset: Unit ={
DB.readOnly(implicit session =>
SQL("select * from streaming_offset where groupId=?").bind(AppParams.groupId)
.map(rs =>
(
new TopicPartition(rs.string("topicName"),rs.int("partitionId")),
rs.long("offset")
)
).list().apply().toMap
)
}
/**
* 持久化存储当前批次的偏移量
*/
def saveCurrentOffset(offsetRanges: Array[OffsetRange]) = {
DB.localTx(implicit session =>{
offsetRanges.foreach(or =>{
SQL("replace into streaming_offset values (?,?,?,?)")
.bind(or.topic,or.partition,or.untilOffset,AppParams.groupId)
.update()
.apply()
})
})
}
}
(5)设置自己的kafka、mysql(存储偏移量)、redis的配置
kafka.topic = "flumeLog"
kafka.broker.list = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
kafka.group.id = "day2_001"
# MySQL example
db.default.driver="com.mysql.jdbc.Driver"
db.default.url="jdbc:mysql://localhost/bigdata?characterEncoding=utf-8"
db.default.user="root"
db.default.password="926718"
# redis
redis.host="hadoop02"
redis.db.index=10
# 映射配置
pcode2pname {
100="北京"
200="广东"
210="上海"
220="天津"
230="重庆"
240="辽宁"
250="江苏"
270="湖北"
280="四川"
290="陕西"
311="河北"
351="山西"
371="河南"
431="吉林"
451="黑龙江"
471="内蒙古"
531="山东"
551="安徽"
571="浙江"
591="福建"
731="湖南"
771="广西"
791="江西"
851="贵州"
871="云南"
891="西藏"
898="海南"
931="甘肃"
951="宁夏"
971="青海"
991="新疆"
}
3)做好一系列配置之后就开始SparkStreaming数据处理的核心
先说明一下日志文件中字段的含义

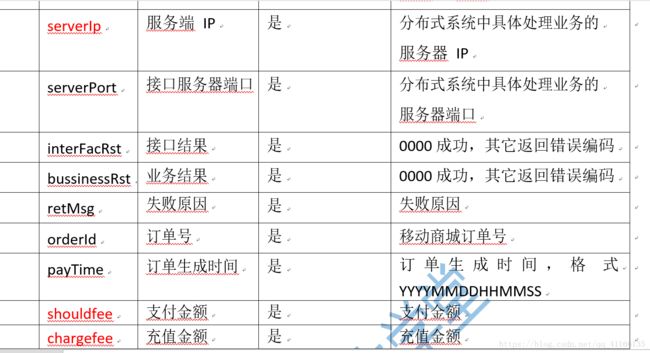
(1)下面是SparkStreaming核心代码
import com.alibaba.fastjson.JSON
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
object KpiTools {
/**
* 业务概况(总订单量、成功订单量、总金额、花费时间
*
* @param baseData
*/
def kpi_general(baseData: RDD[(String, String, List[Double], String, String)]): Unit = {
baseData.map(tp => (tp._1, tp._3)).reduceByKey((list1, list2) => {
//将所有的元素拉链为一个列表之后进行相加计算
list1.zip(list2).map(tp => tp._1 + tp._2)
})
.foreachPartition(partition => {
val jedis = Jpools.getJedis
partition.foreach(tp => {
//所有的数据都计算完成之后,显示在数据库中
jedis.hincrBy("A-" + tp._1, "total", tp._2(0).toLong)
jedis.hincrBy("A-" + tp._1, "succ", tp._2(1).toLong)
jedis.hincrByFloat("A-" + tp._1, "money", tp._2(2))
jedis.hincrBy("A-" + tp._1, "cost", tp._2(3).toLong)
// key的有效期
jedis.expire("A-" + tp._1, 48 * 60 * 60)
})
jedis.close()
})
}
/**
* 业务概述:每小时的充值总订单量,每小时的成功订单量
* 日期、时间、LIST(总订单量、成功订单量、充值成功总金额、时长)、
*
* @param baseData
*/
def kpi_general_hour(baseData: RDD[(String, String, List[Double], String, String)]): Unit = {
baseData.map(tp => ((tp._1, tp._2), List(tp._3(0), tp._3(1)))).reduceByKey((list1, list2) => {
//将所有的元素拉链为一个列表之后进行相加计算
list1.zip(list2).map(tp => tp._1 + tp._2)
})
.foreachPartition(partition => {
val jedis = Jpools.getJedis
partition.foreach(tp => {
//所有的数据都计算完成之后,显示在数据库中
jedis.hincrBy("B-" + tp._1._1, "T:" + tp._1._2, tp._2(0).toLong)
jedis.hincrBy("B-" + tp._1._1, "S" + tp._1._2, tp._2(1).toLong)
// key的有效期
jedis.expire("B-" + tp._1, 48 * 60 * 60)
})
jedis.close()
})
}
/**
* 业务质量
* 总的充值成功订单量
*/
def kpi_quality(baseData: RDD[(String, String, List[Double], String, String)], p2p: Broadcast[Map[String, AnyRef]]) = {
baseData.map(tp => ((tp._1,tp._4),tp._3(1))).reduceByKey(_+_).foreachPartition(partition => {
val jedis = Jpools.getJedis
partition.foreach(tp => {
//总的充值成功和失败订单数量
jedis.hincrBy("C-" + tp._1._1,p2p.value.getOrElse(tp._1._2,tp._1._2).toString,tp._2.toLong)
jedis.expire("C-" + tp._1._1, 48 * 60 * 60)
})
jedis.close()
})
}
/**
* 实时统计每分钟的充值金额和订单量
* // (日期, 小时, Kpi(订单,成功订单,订单金额,订单时长),省份Code,分钟数)
*/
def kpi_realtime_minute(baseData: RDD[(String, String, List[Double], String, String)]) = {
baseData.map(tp => ((tp._1,tp._2,tp._5),List(tp._3(1),tp._3(2)))).reduceByKey((list1,list2)=>{
list1.zip(list2).map(tp => tp._1+tp._2)
}).foreachPartition(partition => {
val jedis = Jpools.getJedis
partition.foreach(tp => {
//每分钟充值成功的笔数和充值金额
jedis.hincrBy("D-" + tp._1._1,"C:"+ tp._1._2+tp._1._3,tp._2(0).toLong)
jedis.hincrByFloat("D-" + tp._1._1,"M"+tp._1._2+tp._1._3,tp._2(1))
jedis.expire("D-" + tp._1._1, 48 * 60 * 60)
})
jedis.close()
})
}
/**
* 整理基础数据
*/
def baseDataRDD(rdd: RDD[ConsumerRecord[String, String]]): RDD[(String, String, List[Double], String, String)] = {
rdd // ConsumerRecord => JSONObject
.map(cr => JSON.parseObject(cr.value())) // 过滤出充值通知日志
.filter(obj => obj.getString("serviceName").equalsIgnoreCase("reChargeNotifyReq")).map(obj => {
// 判断该条日志是否是充值成功的日志
val result = obj.getString("bussinessRst")
val fee = obj.getDouble("chargefee")
// 充值发起时间和结束时间
val requestId = obj.getString("requestId")
// 数据当前日期
val day = requestId.substring(0, 8)
val hour = requestId.substring(8, 10)
val minute = requestId.substring(10, 12)
val receiveTime = obj.getString("receiveNotifyTime")
//省份Code
val provinceCode = obj.getString("provinceCode")
val costTime = CaculateTools.caculateTime(requestId, receiveTime)
val succAndFeeAndTime: (Double, Double, Double) = if (result.equals("0000")) (1, fee, costTime) else (0, 0, 0)
// (日期, 小时, Kpi(订单,成功订单,订单金额,订单时长),省份Code,分钟数)
(day, hour, List[Double](1, succAndFeeAndTime._1, succAndFeeAndTime._2, succAndFeeAndTime._3), provinceCode, minute)
}).cache()
}
}
(2)将封装好的方法调用
import cn.sheep.utils.{AppParams, KpiTools, OffsetManager}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 中国移动实时监控平台(优化版)
* Created by zhangjingcun on 2018/10/16 16:34.
*/
object BootStarpAppV2 {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf()
sparkConf.setAppName("中国移动运营实时监控平台-Monitor") //如果在集群上运行的话,需要去掉:sparkConf.setMaster("local[*]")
sparkConf.setMaster("local[*]") //将rdd以序列化格式来保存以减少内存的占用
//默认采用org.apache.spark.serializer.JavaSerializer
//这是最基本的优化
sparkConf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") //rdd压缩
sparkConf.set("spark.rdd.compress", "true") //batchSize = partitionNum * 分区数量 * 采样时间
sparkConf.set("spark.streaming.kafka.maxRatePerPartition", "10000") //优雅的停止
sparkConf.set("spark.streaming.stopGracefullyOnShutdown", "true")
val ssc = new StreamingContext(sparkConf, Seconds(2))
/**
* 提取数据库中存储的偏移量
*/
val currOffset = OffsetManager.getMydbCurrentOffset
/**
* 广播省份映射关系
*/
val pcode2PName: Broadcast[Map[String, AnyRef]] = ssc.sparkContext.broadcast(AppParams.pCode2PName)
/** 获取kafka的数据
* LocationStrategies:位置策略,如果kafka的broker节点跟Executor在同一台机器上给一种策略,不在一台机器上给另外一种策略
* 设定策略后会以最优的策略进行获取数据
* 一般在企业中kafka节点跟Executor不会放到一台机器的,原因是kakfa是消息存储的,Executor用来做消息的计算,
* 因此计算与存储分开,存储对磁盘要求高,计算对内存、CPU要求高
* 如果Executor节点跟Broker节点在一起的话使用PreferBrokers策略,如果不在一起的话使用PreferConsistent策略
* 使用PreferConsistent策略的话,将来在kafka中拉取了数据以后尽量将数据分散到所有的Executor上 */
val stream: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](AppParams.topic, AppParams.kafkaParams)
)
/**
* 数据处理
*/
stream.foreachRDD(rdd=>{
val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val baseData = KpiTools.baseDataRDD(rdd)
/**
* 计算业务概况
*/
KpiTools.kpi_general(baseData)
KpiTools.kpi_general_hour(baseData)
/**
* 业务质量
*/
KpiTools.kpi_quality(baseData, pcode2PName)
/**
* 实时充值情况分析
*/
KpiTools.kpi_realtime_minute(baseData)
/**
* 存储偏移量
*/
OffsetManager.saveCurrentOffset(offsetRanges)
})
ssc.start()
ssc.awaitTermination()
}
}
pom文件
4.0.0
cn.sheep
cmcc_monitor
1.0-SNAPSHOT
2.2.1
5.1.40
2.9.0
1.3.3
1.2.51
3.3.1
org.apache.spark
spark-streaming_2.11
${spark.version}
org.apache.spark
spark-streaming-kafka-0-10_2.11
${spark.version}
mysql
mysql-connector-java
${mysql.version}
redis.clients
jedis
${jedis.version}
com.typesafe
config
${config.version}
com.alibaba
fastjson
${fastjson.version}
org.scalikejdbc
scalikejdbc_2.11
3.3.1
org.scalikejdbc
scalikejdbc-core_2.11
3.3.1
org.scalikejdbc
scalikejdbc-config_2.11
3.3.1
junit
junit
4.12
compile
链接:https://pan.baidu.com/s/1kjK9XK0yhbojUUexu3oFXQ
提取码:rrow