一个超详细的 Python 入门爬虫实战案例
本文转自公众号:超哥的杂货铺
写在前面:本文从北京公交路线数据的获取和预处理入手,记录使用python中requests库获取数据,pandas库预处理数据的过程。文章在保证按照一定处理逻辑的前提下,以自问自答的方式,对其中每一个环节进行详细阐述。本次代码均在jupyter notebook中测试通过,希望对大家有所启示。
数据获取:
本次我们从公交网获取北京公交的数据。
(http://beijing.gongjiao.com/lines_all.html)
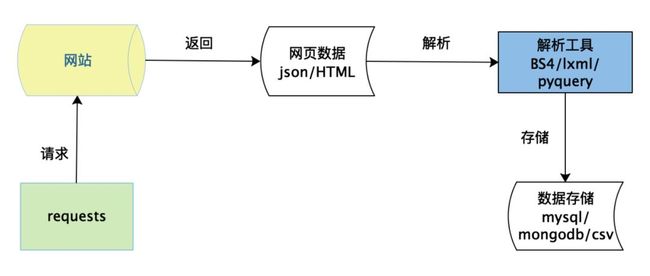
如上图所示,数据获取分为请求,解析,存储三个最主要的步骤。
1.如何用python模拟网络请求?
使用request库可以模拟不同的请求,例如requests.get()模拟get请求,requests.post()模拟post请求。必要的时候可以添加请求头header,header通常包括user-agent,cookie,refer等信息,还可以增加请求参数data和代理信息。主要代码形式为:response = requests.request("GET", url, headers=headers, params=querystring)response是网站返回的响应信息,可以调用其text方法获取网站的HTML源码。本次我们的目标网站比较简单,获取网页源码的代码如下:
1url = 'http://beijing.gongjiao.com/lines_all.html'2text = requests.get(url).text'http://beijing.gongjiao.com/lines_all.html'
2text = requests.get(url).text
2.如何对网页进行解析?
python中提供了多种库用于网页解析,例如lxml,BeautifulSoup,pyquery等。每一个工具都有相应的解析规则,但都是把HTML文档当做一个DOM树,通过选择器进行节点和属性的定位。本次我们使用lxml对网页进行解析,主要用到了xpath的语法。lxml的执行效率通常也比BeautifulSoup更高一些。
1doc = etree.HTML(text)2all_lines = doc.xpath("//div[@class='list']/ul/li")3for line in all_lines:4 line_name = line.xpath("./a/text()")[0].strip()5 line_url = line.xpath("./a/@href")[0]
2all_lines = doc.xpath("//div[@class='list']/ul/li")
3for line in all_lines:
4 line_name = line.xpath("./a/text()")[0].strip()
5 line_url = line.xpath("./a/@href")[0]

我们将图和代码结合起来看。第一行代码将上一步返回的HTML文本转换为xpath可以解析的对象。第二行代码定位到class=list的div下面所有的li标签,即右图中的红色框的部分,得到的是一个列表。从第三行开始对其进行遍历,处理每一个li下面的a标签。第4行取出a标签下的文本,用到了xpath的text()方法,对应到第一个li就是“北京1路公交车路线”,第5行取出a标签下对应的链接,用到了xpath的@href取出a标签下的href属性值。直接取都是列表的形式,所以需要用索引取出具体的值。
这样我们就可以得到整个公交线路列表中的线路名称和线路url。然后从线路url出发,就可以获取每条线路的具体信息。如下面代码和图片所示,虽然数据略多,但主要的逻辑和上面类似,可以查看代码中的注释。
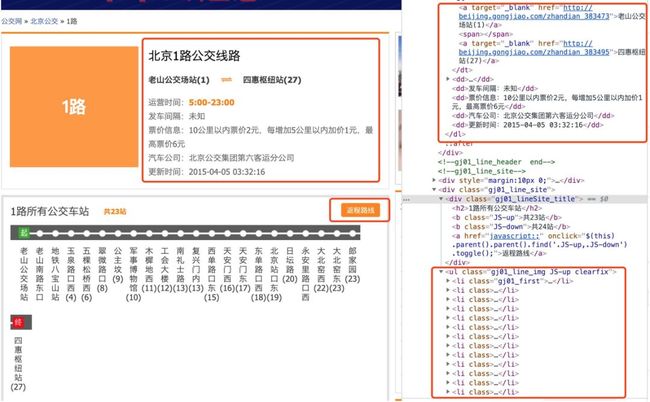
注:左右滑动查看详细代码
1url = 'http://beijing.gongjiao.com/xianlu_38753'#先以一个url为例,进行页面的分析 2text = requests.get(url).text 3print(len(text)) 4doc = etree.HTML(text) 5infos = doc.xpath("//div[@class='gj01_line_header clearfix']")#定位到相应的div块 6for info in infos: 7 start_stop = info.xpath("./dl/dt/a/text()")#获取起点站和终点站的文本,xpath的逻辑为:div->dl->dt->a 8 op_times = info.xpath("./dl/dd[1]/b/text()")#获取运营时间的文本,xpath的逻辑为:div->dl->第一个dd->b 9 interval = info.xpath("./dl/dd[2]/text()")#获取发车间隔的文本,xpath的逻辑为:div->dl->第二个dd10 price = info.xpath("./dl/dd[3]/text()")#获取票价信息的文本,xpath的逻辑为:div->dl->第三个dd11 company = info.xpath("./dl/dd[4]/text()")#获取汽车公司的文本,xpath的逻辑为:div->dl->第四个dd12 up_times = info.xpath("./dl/dd[5]/text()")#获取更新时间的文本,xpath的逻辑为:div->dl->第五个dd13 all_stations_up = doc.xpath('//ul[@class="gj01_line_img JS-up clearfix"]')#定位到相应的div块14 for station in all_stations_up:15 station_name = station.xpath('./li/a/text()')#遍历取出该条线路上的站点名称16 all_stations_down = doc.xpath('//ul[@class="gj01_line_img JS-down clearfix"]')#定位到返程线路相应的div块17 for station in all_stations_down:18 station_name = station.xpath('./li/a/text()')#遍历取出该条线路上返程的站点名称19如果将获取的文本都输出(请自行添加相应的print语句)运行结果如下:20['老山公交场站(1)', '四惠枢纽站(27)']21['5:00-23:00']22['5:00-23:00']23['发车间隔:未知']24['票价信息:10公里以内票价2元,每增加5公里以内加价1元,最高票价6元']25['汽车公司:北京公交集团第六客运分公司']26['更新时间:2015-04-05 03:32:16']27['老山公交场站(1)', '老山南路东口(2)', '地铁八宝山站(3)', '玉泉路口西(4)', '五棵松桥西(6)', '翠微路口(8)', '公主坟(9)', '军事博物馆(10)', '木樨地西(11)', '工会大楼(12)', '南礼士路(13)', '复兴门内(13)', '西单路口东(15)', '天安门西(16)', '天安门东(17)', '东单路口西(18)', '北京站口东(19)', '日坛路(20)', '永安里路口西(21)', '大北窑西(22)', '大北窑东(23)', '郎家园(23)', '四惠枢纽站(27)']28['四惠枢纽站(27)', '八王坟西(24)', '郎家园(23)', '大北窑东(23)', '大北窑西(22)', '永安里路口西(21)', '日坛路(20)', '北京站口东(19)', '东单路口西(18)', '天安门东(17)', '天安门西(16)', '西单路口东(15)', '复兴门内(13)', '南礼士路(13)', '工会大楼(12)', '木樨地西(11)', '军事博物馆(10)', '公主坟(9)', '翠微路口(8)', '五棵松桥东(6)', '玉泉路口西(4)', '地铁八宝山站(3)', '老山南路东口(2)', '老山公交场站(1)']'http://beijing.gongjiao.com/xianlu_38753'#先以一个url为例,进行页面的分析
2text = requests.get(url).text
3print(len(text))
4doc = etree.HTML(text)
5infos = doc.xpath("//div[@class='gj01_line_header clearfix']")#定位到相应的div块
6for info in infos:
7 start_stop = info.xpath("./dl/dt/a/text()")#获取起点站和终点站的文本,xpath的逻辑为:div->dl->dt->a
8 op_times = info.xpath("./dl/dd[1]/b/text()")#获取运营时间的文本,xpath的逻辑为:div->dl->第一个dd->b
9 interval = info.xpath("./dl/dd[2]/text()")#获取发车间隔的文本,xpath的逻辑为:div->dl->第二个dd
10 price = info.xpath("./dl/dd[3]/text()")#获取票价信息的文本,xpath的逻辑为:div->dl->第三个dd
11 company = info.xpath("./dl/dd[4]/text()")#获取汽车公司的文本,xpath的逻辑为:div->dl->第四个dd
12 up_times = info.xpath("./dl/dd[5]/text()")#获取更新时间的文本,xpath的逻辑为:div->dl->第五个dd
13 all_stations_up = doc.xpath('//ul[@class="gj01_line_img JS-up clearfix"]')#定位到相应的div块
14 for station in all_stations_up:
15 station_name = station.xpath('./li/a/text()')#遍历取出该条线路上的站点名称
16 all_stations_down = doc.xpath('//ul[@class="gj01_line_img JS-down clearfix"]')#定位到返程线路相应的div块
17 for station in all_stations_down:
18 station_name = station.xpath('./li/a/text()')#遍历取出该条线路上返程的站点名称
19如果将获取的文本都输出(请自行添加相应的print语句)运行结果如下:
20['老山公交场站(1)', '四惠枢纽站(27)']
21['5:00-23:00']
22['5:00-23:00']
23['发车间隔:未知']
24['票价信息:10公里以内票价2元,每增加5公里以内加价1元,最高票价6元']
25['汽车公司:北京公交集团第六客运分公司']
26['更新时间:2015-04-05 03:32:16']
27['老山公交场站(1)', '老山南路东口(2)', '地铁八宝山站(3)', '玉泉路口西(4)', '五棵松桥西(6)', '翠微路口(8)', '公主坟(9)', '军事博物馆(10)', '木樨地西(11)', '工会大楼(12)', '南礼士路(13)', '复兴门内(13)', '西单路口东(15)', '天安门西(16)', '天安门东(17)', '东单路口西(18)', '北京站口东(19)', '日坛路(20)', '永安里路口西(21)', '大北窑西(22)', '大北窑东(23)', '郎家园(23)', '四惠枢纽站(27)']
28['四惠枢纽站(27)', '八王坟西(24)', '郎家园(23)', '大北窑东(23)', '大北窑西(22)', '永安里路口西(21)', '日坛路(20)', '北京站口东(19)', '东单路口西(18)', '天安门东(17)', '天安门西(16)', '西单路口东(15)', '复兴门内(13)', '南礼士路(13)', '工会大楼(12)', '木樨地西(11)', '军事博物馆(10)', '公主坟(9)', '翠微路口(8)', '五棵松桥东(6)', '玉泉路口西(4)', '地铁八宝山站(3)', '老山南路东口(2)', '老山公交场站(1)']
3.如何存储获取的数据?
数据存储的载体通常有文件(例如csv,excel)和数据库(例如mysql,MongoDB)。我们这里选择了csv文件的形式,一方面是数据量不是太大,另一方面也不需要进行数据库安装,只需将数据整理成dataframe的格式,直接调用pandas的to_csv方法就可以将dataframe写入csv文件中。主要代码如下:
注:左右滑动查看详细代码
1#准备一个存储数据的字典 2df_dict = { 3 'line_name': [], 'line_url': [], 'line_start': [], 'line_stop': [], 4 'line_op_time': [], 'line_interval': [], 'line_price': [], 'line_company': [], 5 'line_up_times': [], 'line_station_up': [], 'line_station_up_len': [], 6 'line_station_down': [], 'line_station_down_len': [] 7} 8#将上面获取的数据写入到字典中,注意这里只是示例,实际运行时候要将下面的代码放到循环中,每解析一条线路就需要append一次。 9df_dict['line_name'].append(line_name)10df_dict['line_url'].append(line_url)11df_dict['line_start'].append(start_stop[0])12df_dict['line_stop'].append(start_stop[1])13df_dict['line_op_time'].append(op_times[0])14df_dict['line_interval'].append(interval[0][5:])#为了把前面的文字“发车间隔”截掉,其余的类似15df_dict['line_company'].append(company[0][5:])16df_dict['line_price'].append(price[0][5:])17df_dict['line_up_times'].append(up_times[0][5:])18df_dict['line_station_up'].append(station_up_name)19df_dict['line_station_up_len'].append(len(station_up_name))20df_dict['line_station_down'].append(station_down_name)21df_dict['line_station_down_len'].append(len(station_down_name))22#将数据保存成csv文件23df = pd.DataFrame(df_dict)24df.to_csv('bjgj_lines_utf8.csv', encoding='utf-8', index=None)#准备一个存储数据的字典
2df_dict = {
3 'line_name': [], 'line_url': [], 'line_start': [], 'line_stop': [],
4 'line_op_time': [], 'line_interval': [], 'line_price': [], 'line_company': [],
5 'line_up_times': [], 'line_station_up': [], 'line_station_up_len': [],
6 'line_station_down': [], 'line_station_down_len': []
7}
8#将上面获取的数据写入到字典中,注意这里只是示例,实际运行时候要将下面的代码放到循环中,每解析一条线路就需要append一次。
9df_dict['line_name'].append(line_name)
10df_dict['line_url'].append(line_url)
11df_dict['line_start'].append(start_stop[0])
12df_dict['line_stop'].append(start_stop[1])
13df_dict['line_op_time'].append(op_times[0])
14df_dict['line_interval'].append(interval[0][5:])#为了把前面的文字“发车间隔”截掉,其余的类似
15df_dict['line_company'].append(company[0][5:])
16df_dict['line_price'].append(price[0][5:])
17df_dict['line_up_times'].append(up_times[0][5:])
18df_dict['line_station_up'].append(station_up_name)
19df_dict['line_station_up_len'].append(len(station_up_name))
20df_dict['line_station_down'].append(station_down_name)
21df_dict['line_station_down_len'].append(len(station_down_name))
22#将数据保存成csv文件
23df = pd.DataFrame(df_dict)
24df.to_csv('bjgj_lines_utf8.csv', encoding='utf-8', index=None)
4.看一看完整代码?
以上我们分模拟请求,网页解析,数据存储3个步骤,学习了数据获取的流程。实际运行过程中,还需要增加一些保证代码“健壮性”的逻辑。例如,控制爬取的频率,处理请求失败的情况,处理不同的线路网页结构可能有差异的情况等等。本次的数据源没有做很多反扒限制,因此前两种情况我们可以不处理。至于第三种,有的路线会出现线路运营时间是空值的情况,需要进行判断。另外还可以增加一些爬虫运行过程的提示信息,让我们知道爬取进度,当然你也可以增加多线程,代理,ua切换等代码,此处我们还用不上这些。完整的代码可以在后台回复“北京公交”进行获取。
数据预处理
在上一步获取数据之后,我们就可以使用pandas进行数据的分析工作。在正式的分析之前,数据预处理非常重要,它保证了数据的质量,也为后续的工作奠定了重要的基础。通常数据预处理在实际工作中都会占用比较多的时间。虽然我们这里的数据已经足够“结构化”,但仍然不可避免存在一些问题。下面我们就来一探究竟。
5.如何读取数据?
使用pandas提供的read_csv方法,该方法有很多可选的参数,例如指定索引,列名,编码等。对于本次数据,直接使用默认的即可。读取的ori_data是dataframe类型,调用head方法可以输出前5行的样例数据。
1ori_data = pd.read_csv('bjgj_lines_utf8.csv')2ori_data.head()'bjgj_lines_utf8.csv')
2ori_data.head()
6.如何查看每一列数据的唯一值的个数?(如何查看有多少条线路)
可以使用dataframe的nunique方法,该方法输出每一列有几个唯一的值。
1ori_data.nunique() 2输出结果如下: 3line_name 1986 4line_url 2002 5line_start 989 6line_stop 1123 7line_op_time 560 8line_interval 4 9line_price 12610line_company 8211line_up_times 65012line_station_up 192813line_station_up_len 8014line_station_down 170015line_station_down_len 8016dtype: int64ori_data.nunique()
2输出结果如下:
3line_name 1986
4line_url 2002
5line_start 989
6line_stop 1123
7line_op_time 560
8line_interval 4
9line_price 126
10line_company 82
11line_up_times 650
12line_station_up 1928
13line_station_up_len 80
14line_station_down 1700
15line_station_down_len 80
16dtype: int64
由于线路很多,我们在原始网页中很难发现是否会有重复的线路。但从上面观察line_name和line_url两个字段,line_name有1986个唯一值,line_url有2002个唯一值。说明line_name存在重复:会有名称相同的线路对应不同的line_url。所以接下来我们需要进行重复值的剔除。
7.如何找出重复的值?
出现了线路名称的重复,但却有不同的line_url,究竟是确实是线路“重名”还是线路“重复”?我们需要看一下数据重复的具体情况。因此需要把重复的行都找出来看看。可以使用pandas的duplicated方法,它可以对dataframe的指定列查看是否重复,返回True和False,代码如下。
1d = ori_data.duplicated(subset=['line_name'])2dup_data = ori_data[d]3dup_data
2dup_data = ori_data[d]
3dup_data
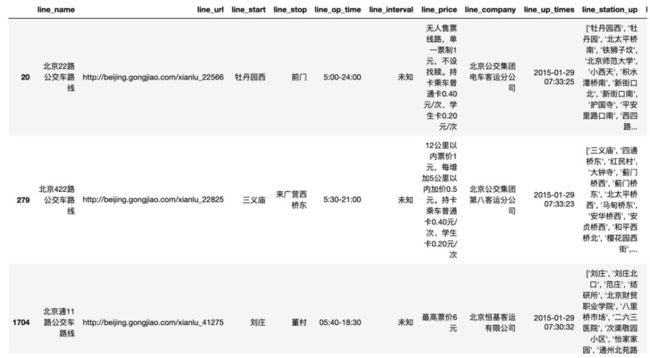
这是所有重复出现过的line_name值,但并不是所有重复的值(例如22路重复出现过,但22路在结果中只有一条,不便于观察除了名字之外是否还有其他字段的重复)。为了找出所有重复的值(例如输出所有22路的记录),我们可以从原数据中取line_name是这些值的所有行,代码和思路如下:
1#首先定义一个列表,每找出一行line_name在上面范围内的,2#就将这行加入列表,然后调用concat方法将列表拼接成#dataframe3dup_lines = []4for name in dup_data.line_name:5 tmp_lines = ori_data[ori_data['line_name'] == name]6 dup_lines.append(tmp_lines)7 dup_data_all = pd.concat(dup_lines)8dup_data_all#首先定义一个列表,每找出一行line_name在上面范围内的,
2#就将这行加入列表,然后调用concat方法将列表拼接成#dataframe
3dup_lines = []
4for name in dup_data.line_name:
5 tmp_lines = ori_data[ori_data['line_name'] == name]
6 dup_lines.append(tmp_lines)
7 dup_data_all = pd.concat(dup_lines)
8dup_data_all
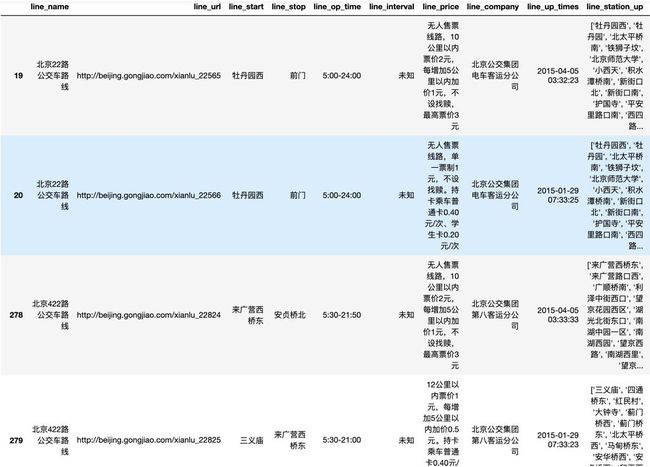
观察dup_data_all,确实同一个线路名字存在重复的记录,而且其余信息也是几乎都相同的,这确认了我们认为的线路”重名“现象是不存在的。但同一条线路的信息具体以哪一个为准呢?注意到有更新时间line_up_time字段,因此我们可以以最新时间的信息为准。
8.如何对原数据剔除重复值?
这里考虑两种思路。第一种,直接对原数据进行操作,当line_name存在重复时,保留最近更新时间的记录。第二种,将原数据中的dup_data_all部分完全删除,拼接上dup_data_all去除重复的部分。两种思路都需要删除line_name重复的记录,保留一个时间最新的。pandas本身有drop_duplicates方法,使用keep=last或keep=first参数就可以指定保留的记录。但在这之前我们需要将line_up_time转换为pandas可以识别的时间类型,然后对其进行排序。下面来看代码:
注:左右滑动查看详细代码
1#方法1 2ori_data['line_up_times'] = pd.to_datetime(ori_data['line_up_times'], format='%Y-%m-%d %H:%M:%S')#使用to_datetime方法,指定format,将字符串转换为pandas的时间类型。 3ori_data.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#使用sort_values方法,对line_name和line_up_time排序 4drop_dup_line1 = ori_data.drop_duplicates(subset=['line_name'], keep='last')#由于是升序排列,所以keep=last就可以保留最新事件的记录 5len(drop_dup_line1)#结果是1986 6 7方法2: 8dup_data_all['line_up_times'] = pd.to_datetime(dup_data_all['line_up_times'], format='%Y-%m-%d %H:%M:%S')#使用to_datetime方法,指定format,将字符串转换为pandas的时间类型。 9dup_data_all.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#使用sort_values方法,对line_name和line_up_time排序10dup_data_all.drop_duplicates(subset=['line_name'], keep='last', inplace=True)#使用keep=last保留时间更新的记录1112other_data = ori_data[~ori_data['line_name'].isin(dup_data_all.line_name)]#获取原数据中剔除了重复线路的数据:取名字不在dup_data_all的line_name集合中的记录13drop_dup_line2 = pd.concat([other_data, dup_data_all]) #拼接两部分数据14len(drop_dup_line2)#结果是1986 #方法1
2ori_data['line_up_times'] = pd.to_datetime(ori_data['line_up_times'], format='%Y-%m-%d %H:%M:%S')#使用to_datetime方法,指定format,将字符串转换为pandas的时间类型。
3ori_data.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#使用sort_values方法,对line_name和line_up_time排序
4drop_dup_line1 = ori_data.drop_duplicates(subset=['line_name'], keep='last')#由于是升序排列,所以keep=last就可以保留最新事件的记录
5len(drop_dup_line1)#结果是1986
6
7方法2:
8dup_data_all['line_up_times'] = pd.to_datetime(dup_data_all['line_up_times'], format='%Y-%m-%d %H:%M:%S')#使用to_datetime方法,指定format,将字符串转换为pandas的时间类型。
9dup_data_all.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#使用sort_values方法,对line_name和line_up_time排序
10dup_data_all.drop_duplicates(subset=['line_name'], keep='last', inplace=True)#使用keep=last保留时间更新的记录
11
12other_data = ori_data[~ori_data['line_name'].isin(dup_data_all.line_name)]#获取原数据中剔除了重复线路的数据:取名字不在dup_data_all的line_name集合中的记录
13drop_dup_line2 = pd.concat([other_data, dup_data_all]) #拼接两部分数据
14len(drop_dup_line2)#结果是1986
如何比较两种方法获得的结果线路是否一致?我们可以用下面的代码进行。
1drop_dup_line2.sort_values(by=['line_name', 'line_up_times'], ascending=[True, True], inplace=True)#由于drop_dup_line1排序过,我们也对drop_dup_line2进行相同规则的排序2res = drop_dup_line1['line_name'].values.ravel() == drop_dup_line2['line_name'].values.ravel()#ravel()方法将数组展开,res是一个布尔值组成的ndarray数组,结果为true表示对应元素相等3res = [1 for i in res.flat if i] 4sum(res)#使用flat方法可以对ndarray进行遍历,sum看一下一共有多少个true,结果是1986,说明drop_dup_line1和drop_dup_line2对应每一个位置的元素都相同'line_name', 'line_up_times'], ascending=[True, True], inplace=True)#由于drop_dup_line1排序过,我们也对drop_dup_line2进行相同规则的排序
2res = drop_dup_line1['line_name'].values.ravel() == drop_dup_line2['line_name'].values.ravel()#ravel()方法将数组展开,res是一个布尔值组成的ndarray数组,结果为true表示对应元素相等
3res = [1 for i in res.flat if i]
4sum(res)#使用flat方法可以对ndarray进行遍历,sum看一下一共有多少个true,结果是1986,说明drop_dup_line1和drop_dup_line2对应每一个位置的元素都相同
这样对于重复数据的处理就结束了,我们使用drop_dup_line1来进行下面的分析。
9.如何删除地铁线路?
虽然我们爬取的是公交路线,但程序运行过程中我也发现了地铁的线路(其实地铁也是广义上的公交啦)。如果我们的目的是对纯粹的公交线路进行分析,就需要将地铁的线路删除。直观的思路是剔除线路名称中含有“地铁”的记录。
1is_subway = drop_dup_line1.line_name.str.contains('地铁')#使用.str将其转换为字符串就可以使用字符串的contains方法。2subway_data = drop_dup_line1[is_subway]3subway_data'地铁')#使用.str将其转换为字符串就可以使用字符串的contains方法。
2subway_data = drop_dup_line1[is_subway]
3subway_data

从上图左侧可以看到subway_data的结果不仅仅有地铁,还有一些地铁有关的通勤线路,其实是公交。因此不能直接删除line_name中含有“地铁”的记录,我们使用line_conpany中含有“地铁”来区分,效果更好。代码如下所示:
1is_subway2 = drop_dup_line1.line_company.str.contains('地铁')2subway_data2 = drop_dup_line1[is_subway2]3subway_data2'地铁')
2subway_data2 = drop_dup_line1[is_subway2]
3subway_data2
结果如上图右侧所示,虽然最后一条也有一条“公交车路线”,但观察整条记录就会发现它其实是特殊的机场线地铁。
到这里,你会不会想到根据线路名称中是否含有“公交车路线”将地铁线路剔除?我们可以试一试。但其实上面的图已经告诉了我们答案:有的公交线路是“接驳线”,并不含有“公交车路线”。
10.获取删除地铁数据之后的全部数据
在drop_dup_line1的基础上,筛选出线路名称不在subway_data2中的线路名称的记录即可:
1clean_data = drop_dup_line1[~drop_dup_line1['line_name'].isin(subway_data2.line_name)]2len(clean_data) #结果是1963,也就是北京的公交车一共有1963条线路34clean_data3 = drop_dup_line1[drop_dup_line1.line_name.str.contains("公交车路线")]5len(clean_data3) #通过是否含有“公交车线路”进行筛选,结果是1955,应该就是少了那些“接驳线”'line_name'].isin(subway_data2.line_name)]
2len(clean_data) #结果是1963,也就是北京的公交车一共有1963条线路
3
4clean_data3 = drop_dup_line1[drop_dup_line1.line_name.str.contains("公交车路线")]
5len(clean_data3) #通过是否含有“公交车线路”进行筛选,结果是1955,应该就是少了那些“接驳线”
如何比较clean_data和clean_data3。这个问题其实是如何求两个dataframe差集的问题,我们转化为求列表的差集,代码和结果如下所示。
1list(set(clean_data.line_name.values).difference(set(clean_data3.line_name.values))) #找出在clean_data的line_name中但是不在clean_data3的line_name中的数据2list(set(clean_data3.line_name.values).difference(set(clean_data.line_name.values))) #找出在clean_data3的line_name中但是不在clean_data的line_name中的数据#找出在clean_data的line_name中但是不在clean_data3的line_name中的数据
2list(set(clean_data3.line_name.values).difference(set(clean_data.line_name.values))) #找出在clean_data3的line_name中但是不在clean_data的line_name中的数据

至此我们将重复数据进行了删除,并剔除了“地铁”线路。但其实我们的数据预处理工作还没有结束,我们还没有观察数据中是否含有缺失值。
11.如何查看数据集中的缺失值情况?
可以使用isnull().sum()方法查看。发现票价有230个缺失值。参见后面的图片。对于缺失值我们需要在预处理阶段对其进行填充。考虑到票价数据本身不是纯粹的价格数据,而是一大串的文字描述,并且在公交的这种场景下,其实不同线路的票价差别不是很大,因此我们可以使用众数对缺失值进行填充。使用mode方法查看众数,使用fillna方法填补缺失值。
1#查看众数的方法:2clean_data.line_price.mode()#使用mode()方法查看line_price的众数3clean_data.line_price.value_counts()#使用value_counts()方法查看每一个取值出现的次数,第一个也是众数45clean_data.line_price.fillna(clean_data.line_price.mode()[0], inplace=True)6clean_data.isnull().sum()#查看众数的方法:
2clean_data.line_price.mode()#使用mode()方法查看line_price的众数
3clean_data.line_price.value_counts()#使用value_counts()方法查看每一个取值出现的次数,第一个也是众数
4
5clean_data.line_price.fillna(clean_data.line_price.mode()[0], inplace=True)
6clean_data.isnull().sum()

至此我们基本完成了重复值和缺失值的处理。
总结
本文我们主要借助于北京公交数据的实例,学习了使用python进行数据获取和数据预处理的流程。内容虽然简单但不失完整性。数据获取部分主要使用requests模拟了get请求,使用lxml进行了网页解析并将数据存储到csv文件中。数据预处理部分我们进行了重复值和缺失值的处理,但应该说数据预处理并没有完成。(比如我们可以对运营时间拆分成两列,对站点名称进行清理等,如何进行预处理工作与后续的分析紧密相关)。文章的重点不在于例子的难度,而在于通过具体问题学习python中数据处理的方法。所处理的问题虽然有一定的特殊性,但也方便扩展到其他场景。希望对读到这里的你有一定的帮助。读者可以在后台回复“北京公交”获取本文的数据和爬取代码,欢迎交流学习~以清净心看世界。