【11】缓存设计
缓存能够有效地加速应用的读写速度,同时也可以降低后端的负载,对日常开发至关重要。
本文包括如下内容:
: 缓存的收益和成本分析
: 缓存更新策略的选择和使用场景
: 缓存粒度控制方法
: 穿透问题优化
: 无底洞问题优化
: 雪崩问题优化
: 热点KEY重建优化
11.1 缓存的收益和成本
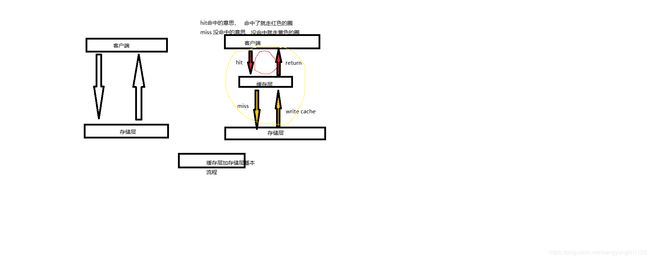
如上图所示,左侧为客户端直接调用存储层的架构,右侧为比较典型的缓存层+存储层架构,下面分析一下缓存加入后带来的收益和成本
收益如下:
- 加速读写:因为缓存通常都是全内存的,而存储层通常读写性能不够强悍,通过缓存的使用可以有效地加速读写,优化用户体验。
- 降低后端的负载,帮助后端减少访问量和复杂度计算,在很大程度降低了后端的负载。
成本如下:
- 数据不一致性 :缓存的数据和存储层的数据存在着一定时间窗口的不一致性,时间窗口跟更新策略有关
- 代码维护成本:加入缓存后,需要同时处理缓存层和存储层的逻辑,增大了开发者维护代码的成本。
- 运维成本:redis拍错、架空、扩容、伸缩都是比较耗费运维成本的,而不用缓存,则会省掉这些成本
缓存的使用场景包括如下两种:
- 开销大的复杂计算:开销大的复杂计算,比如(大量链表操作,或者一些分组计算),如果不加缓存,不但无法满足高并发量,同时也给MySql带来巨大的负担
- 加速请求响应:即使查询单条后端数据足够快(例如:select * from table where id=?),那么依然可以使用缓存,以redis为例子,每秒可以完成数百万次读写,并且提供批量操作可以优化整个IO链的相应时间。
11.2 缓存更新策略
缓存中的数据都是有生命周期的,需要在指定时间后被删除或者更新,这样可以保证缓存空间在一个可控的范围内。但是缓存中的数据和数据源中的真实数据有一段时间窗口的不一致,需要利用某些策略进行更新。下面将分别从使用场景、一致性、开发人员开发/维护三个方面介绍三种缓存的更新策略
11.2.1 LRU/LFU/FIFO算法剔除
使用场景。剔除算法通常用于缓存使用量超过了预设的最大值的时候,如何对现有的数据进行剔除。例如Redis使用maxmemory-policy这个配置作为内存最大值后对于数据的剔除策略。
- The Least Recently Used
LRU(The Least Recently Used,最近最久未使用算法)是一种常见的缓存算法,在很多分布式缓存系统(如Redis, Memcached)中都有广泛使用。
- Least Frequently Used
LFU(Least Frequently Used ,最近最少使用算法)也是一种常见的缓存算法。
顾名思义,LFU算法的思想是:如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
LRU算法的思想是:如果一个数据在最近一段时间没有被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最久没有访问的数据最先被置换(淘汰)。
- First in First Out
FIFO 算法是一种比较容易实现的算法。它的思想是先进先出(FIFO,队列),这是最简单、最公平的一种思想,即如果一个数据是最先进入的,那么可以认为在将来它被访问的可能性很小。空间满的时候,最先进入的数据会被最早置换(淘汰)掉
11.2.2 超时剔除
使用场景。超时剔除通过给缓存数据设置过期时间,让其在过期时间后自动删除,例如Redis提供的expire命令。如果业务可以容忍一段时间内,缓存层数据和存储层数据不一致,那么可以为其设置过期时间。在数据过期后,再从真实数据源获取数据,重新放到缓存并设置过期时间。例如一个视频的描述信息,可以容忍几分钟内数据不一致,但是涉及交易方面的业务,后果可想而知。
11.2.3 主动更新
使用场景。真实数据更新后要求缓存数据马上更新
三种常见策略的对比

最佳实践:
- 低一致性建议配置最大内存和淘汰策略的方式使用
- 高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新出了问题,也能保证数据过期时间后删除脏数据。
11.3 缓存粒度控制
下图是很多项目关于缓存比价常用的选型,缓存层选用Redis,存储层选用MySQL。
例如现在需要将MySQL的用户信息使用Redis缓存,可以执行如下操作:
从MySQL获取用户信息:
select * from user where id={id}
将用户信息缓存到Redis中:
set user:{id} 'select * from user where id={id}
假设用户表有100个列,需要缓存到什么维度呢?
缓存全部列:
set user:{id} 'select * from user where id={id}
缓存部分重要列:
set user:{id} 'select {importantColumn1}, {important Column2} ... {importantColumnN} from user where id={id}
上述这个问题就是缓存粒度问题,究竟是缓存全部属性还是只缓存部分重要属性呢?下面将从通用性、空间占用、代码维护三个角度进行说明。
通用性。缓存全部数据比部分数据更加通用,但从实际经验看,很长时间内应用只需要几个重要的属性。
空间占用。缓存全部数据要比部分数据占用更多的空间,可能存在以下问题:
全部是数据会造成内存的浪费。
全部数据可能每次传输产生的网络流量会比较大,耗时相对较大,在极端情况下会阻塞网络。
全部数据的序列化和反序列化的CPU开销更大。
代码维护。全部数据的优势更加明显,而部分数据一旦要加新字段需要修改业务代码,而且修改后通常还需要刷新缓存数据。
下表给出缓存全部数据和部分数据在通用性、空间占用、diamante维护上的对比,开发人员酌情选择。

缓存粒度问题是一个容易被忽视的问题,如果使用不当,可能会造成很多无用空间的浪费,网络带宽的浪费,代码通用性较差等情况,需要综合数据通用性、空间占用比、代码维护性三点进行取舍。
11.4 穿透优化
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓存层。
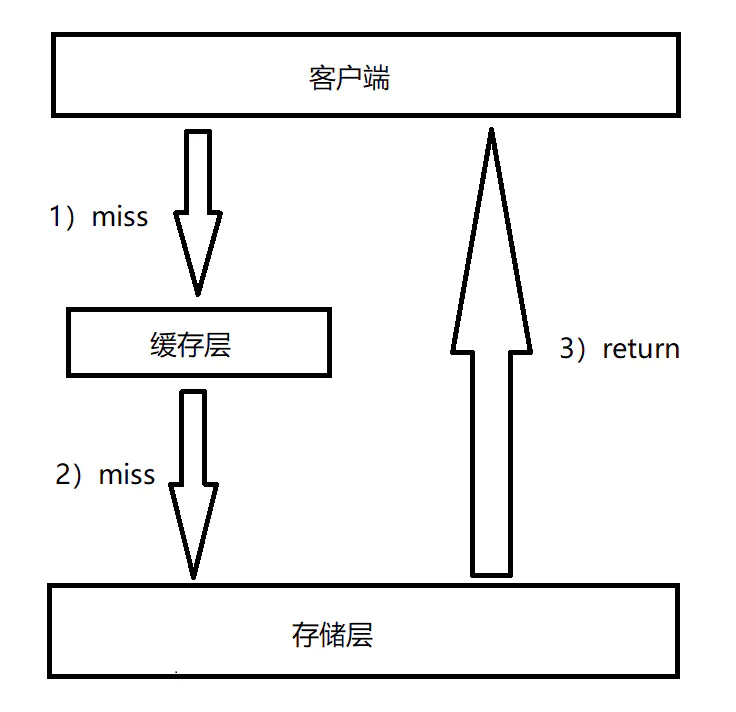
1)缓存层不命中。
2)存储层不命中,不将空结果写回缓存。
3)返回空结果。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。
缓存穿透问题可能会使后端存储负载加大,由于很多后端存储不具备高并发性,甚至可能造成后端存储宕掉。通常可以在程序中分别统计总调用数、缓存层命中数、存储层命中数,如果发现大量存储层空命中,可能就是出现了缓存穿透问题。
造成缓存穿透的基本原因有两个。第一,自身业务代码或者数据出现问题,第二,一些恶意攻击、爬虫等造成大量空命中。下面我们来看一下如何解决缓存穿透问题。
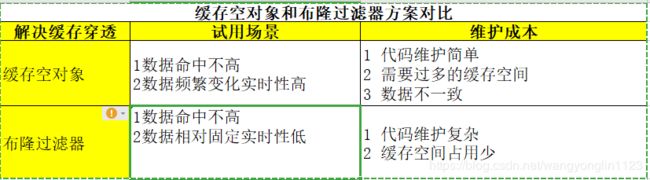
11.4.1 缓存空对象
缓存空对象会有两个问题:第一、空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间(如果是攻击,问题更严重),比较有效地方法是针对这列数据设置一个较短的过期时间,让其自动剔除。第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
11.4.2 布隆过滤器拦截

如上图所示,在访问缓存层和存储层之前,将存在的key用布隆过滤器提前保存起来,做第一层拦截。例如:一个推荐系统有4亿个用户id,每个小时算法工程师会根据每个用户之前历史行为计算出推荐数据放到存储层中,但是最新的用户由于没有历史行为,就会发生缓存穿透的行为,为此可以将所有推荐数据的用户做成布隆过滤器。如果布隆过滤器认为该用户id不存在,那么就不会访问存储层,在一定程度上保护了存储层。
有关布隆过滤器的相关知识https://cloud.tencent.com/developer/article/1418392
11.4.3 两种方案对比
11.5 无底洞优化
https://www.jianshu.com/p/f472e7c33f62
11.6 雪崩优化
https://www.jianshu.com/p/2b6bc0889713
11.7 热点key重建优化
https://www.jianshu.com/p/b4dfbe351f0d