Linux系统多处理器运行队列平衡——负载均衡
| 日期 | 内核版本 | 架构 | 作者 | 内容 |
|---|---|---|---|---|
| 2018-4-7 | Linux-2.6.32 | X86 |
Bystander | Linux系统负载均衡 |
1绪论
Linux中采用对称多处理器模型,所以内核不会对任何一个CPU有偏向行为;在现在多处理机器中有多种处理方式,随之而来的调度程序的实现也随之不同,一下我将介绍常见的3中处理方式:
标准的多处理器体系结构:
多处理器系统采用对称多处理(Symmetric Multiprocessing,SMP),每个处理器都参与完成操作系统的所有任务。SMP 表示所有处理器对等,处理器之间没有主从关系。图 1 显示了一个典型的 SMP 结构。注意,每个处理器都有自己的寄存器集,也有私有或本地缓存;不过,所有处理器都共享物理内存。
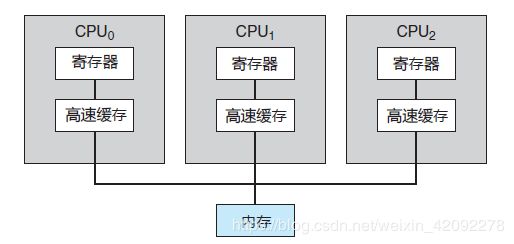
图1对称多处理的体系结构
超线程技术:
超线程(HT, Hyper-Threading)是英特尔研发的一种技术,于2002年发布。英特尔实现在一个实体CPU中,提供两个逻辑线程,但实际上,在某些程序或未对多线程编译的程序而言,超线程反而会降低性能(笔者在实际项目中遇见此类问题,我猜测跟cache有关具体以后再说明)
NUMA:
非统一内存访问(NUMA)是一种用于多处理器的电脑记忆体设计,内存访问时间取决于处理器的内存位置。在NUMA下,处理器访问它自己的本地存储器的速度比非本地存储器(存储器的地方到另一个处理器之间共享的处理器或存储器)快一些。NUMA架构在逻辑上遵循对称多处理(SMP)架构。
这些是基本的处理方式,它们进常被组合使用。但是任何一个可运行进程绝不可能出现在两个及以上的运行队列中,所以一个可运行状态的进程通常被限制在一个固定的CPU上。这样可运行状态进程的数据可能填满每个CPU的硬件高速缓存,这样提高cache的命中,但是在某些情况下可能会引起性能的严重损失。因此。内核周期性的检查运行队列的工作量是否平衡,在负载不均衡时,就把繁忙的CPU的运行队列进程迁移到另外一个CPU的运行队列中去,以此来获得最佳性能,所以Linux提出一种基于“调度域”概念的运行队列平衡算法。
注:笔者在实际高速通信的项目中遇到当多个业务线程同时进行大量数据传输时,此时进行运行队列平衡会影响数据速率会导致速率波动和速度下降,是由于当平衡运行队列时首先上下文切换损耗,再次迁移到其余CPU运行队列时cache miss 必须从内存同步数据 ,最后如果在不同物理CPU时不共享cache将会导致速率大大降低。所以笔者在项目中将业务线程进行绑定CPU大大提高数据传输速率,也减少速率的波动。
2调度域(Scheduling Domains)
调度域(Scheduling Domains)其实就是具有相同属性的一组CPU的集合,他们的工作量由内核保持平衡。并且跟据 Hyper-threading, Multi-core, SMP, NUMA architectures 这样的系统结构划分成不同的级别。不同级之间通过指针链接在一起,从而形成一种的树状的关系,从叶节点往上遍历。直到所有的域中的负载都是平衡的负载均衡是针对每个域里的 CPU 进行的,而每个域中都有一个或多个组,因此负载均衡是在调度域的组之间进行的。调度域层级结构如下图2所示:
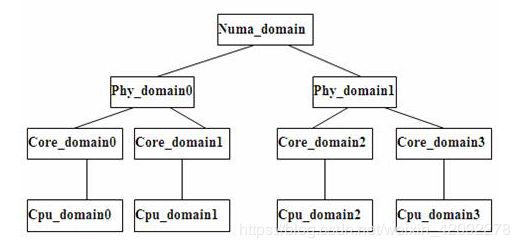
图2调度域分层关系
每个调度域由sched_domain 数据结构表示,而每个调度域组由sched_group 数据结构表示,所以每个sched_domain数据结构中都有一个sched_group 数据结构,指向组描述符链表中的第一个元素。
sched_domain 数据结构:
struct sched_domain {
/* These fields must be setup */
struct sched_domain *parent; /* top domain must be null terminated ;指向当前调度域的父调度域的描述符*/
struct sched_domain *child; /* bottom domain must be null terminated ;指向当前调度域的子调度域描述符*/
struct sched_group *groups; /* the balancing groups of the domain */
unsigned long min_interval; /* Minimum balance interval ms */
unsigned long max_interval; /* Maximum balance interval ms */
unsigned int busy_factor; /* less balancing by factor if busy */
unsigned int imbalance_pct; /* No balance until over watermark */
unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
unsigned int busy_idx;
unsigned int idle_idx;
unsigned int newidle_idx;
unsigned int wake_idx;
unsigned int forkexec_idx;
unsigned int smt_gain;
int flags; /* See SD_* */
enum sched_domain_level level; /*当前调度域级别*/
/* Runtime fields. */
unsigned long last_balance; /* init to jiffies. units in jiffies,当前调度域 最近一次进行 balance 时的时间 */
unsigned int balance_interval; /* initialise to 1. units in ms.进行 balance 的时间间隔 */
unsigned int nr_balance_failed; /* initialise to 0 ,balance 失败的次数*/
u64 last_update;
#ifdef CONFIG_SCHEDSTATS
/* load_balance() stats */
unsigned int lb_count[CPU_MAX_IDLE_TYPES];
unsigned int lb_failed[CPU_MAX_IDLE_TYPES];
unsigned int lb_balanced[CPU_MAX_IDLE_TYPES];
unsigned int lb_imbalance[CPU_MAX_IDLE_TYPES];
unsigned int lb_gained[CPU_MAX_IDLE_TYPES];
unsigned int lb_hot_gained[CPU_MAX_IDLE_TYPES];
unsigned int lb_nobusyg[CPU_MAX_IDLE_TYPES];
unsigned int lb_nobusyq[CPU_MAX_IDLE_TYPES];
/* Active load balancing */
unsigned int alb_count;
unsigned int alb_failed;
unsigned int alb_pushed;
/* SD_BALANCE_EXEC stats */
unsigned int sbe_count;
unsigned int sbe_balanced;
unsigned int sbe_pushed;
/* SD_BALANCE_FORK stats */
unsigned int sbf_count;
unsigned int sbf_balanced;
unsigned int sbf_pushed;
/* try_to_wake_up() stats */
unsigned int ttwu_wake_remote;
unsigned int ttwu_move_affine;
unsigned int ttwu_move_balance;
#endif
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
/*
* Span of all CPUs in this domain.
*
* NOTE: this field is variable length. (Allocated dynamically
* by attaching extra space to the end of the structure,
* depending on how many CPUs the kernel has booted up with)
*
* It is also be embedded into static data structures at build
* time. (See 'struct static_sched_domain' in kernel/sched.c)
*/
unsigned long span[0];
}sched_group数据结构:
struct sched_group {
struct sched_group *next; /* Must be a circular list,下一个 group 的指针 */
/*
* CPU power of this group, SCHED_LOAD_SCALE being max power for a
* single CPU.
*/
unsigned int cpu_power; /*当前 group 的 CPU power*/
/*
* The CPUs this group covers.
*
* NOTE: this field is variable length. (Allocated dynamically
* by attaching extra space to the end of the structure,
* depending on how many CPUs the kernel has booted up with)
*
* It is also be embedded into static data structures at build
* time. (See 'struct static_sched_group' in kernel/sched.c)
*/
unsigned long cpumask[0]; /*当前 group 有哪些 CPU */
};3负载均衡触发方式
3.1周期性的负载均衡
每次时钟中断到来,如果发现当前CPU的运行队列需要进行下一次的 balance 的时间已
经到了,则触发 SCHED_SOFTIRQ 软中断。
open_softirq(SCHED_SOFTIRQ, run_rebalance_domains);由open_softirq()向SCHED_SOFTIRQ软中断注册run_rebalance_domains()->rebalance_domains()->load_balance(),最后是由load_balance()实现负载均衡(由于load_balance()函数与load_balance_newidle函数实现方式相同,为了衔接schedule()函数中的idle_balance()函数讲解这里就不详细讲解load_balance()函数)。
3.2 进入IDLE 状态
当调用schedule()时,如果当前CPU运行队列无可运行进程则进入IDLE 状态,将调用idle_balance()进而调用load_balance_newidle函数实现多处理器运行队列平衡功能。
/*
* idle_balance is called by schedule() if this_cpu is about to become
* idle. Attempts to pull tasks from other CPUs.
*/
static void idle_balance(int this_cpu, struct rq *this_rq)
{
struct sched_domain *sd;
int pulled_task = 0;
unsigned long next_balance = jiffies + HZ;
for_each_domain(this_cpu, sd) {
unsigned long interval;
if (!(sd->flags & SD_LOAD_BALANCE))
continue;
if (sd->flags & SD_BALANCE_NEWIDLE)
/* If we've pulled tasks over stop searching: */
pulled_task = load_balance_newidle(this_cpu, this_rq,
sd);
interval = msecs_to_jiffies(sd->balance_interval);
if (time_after(next_balance, sd->last_balance + interval))
next_balance = sd->last_balance + interval;
if (pulled_task)
break;
}
if (pulled_task || time_after(jiffies, this_rq->next_balance)) {
/*
* We are going idle. next_balance may be set based on
* a busy processor. So reset next_balance.
*/
this_rq->next_balance = next_balance;
}
}load_balance()函数:检查是否调度域处于严重不平衡状态,它可以检查把最繁忙的组中一些进程迁移到本地CPU运行 队列中来减轻不平衡状态,达到维持多处理器系统中运行队列平衡。此函数通过idle_balance函数间接调用。
/*
* Check this_cpu to ensure it is balanced within domain. Attempt to move
* tasks if there is an imbalance.
*
* Called from schedule when this_rq is about to become idle (CPU_NEWLY_IDLE).
* this_rq is locked.
* 输入参数:
* this_cpu-本地CPU下标
* this_rq-本地运行队列描述符地址
* sd-指向被检查的调度域的描述符
*/
static int
load_balance_newidle(int this_cpu, struct rq *this_rq, struct sched_domain *sd)
{
struct sched_group *group;
struct rq *busiest = NULL;
unsigned long imbalance;
int ld_moved = 0;
int sd_idle = 0;
int all_pinned = 0;
struct cpumask *cpus = __get_cpu_var(load_balance_tmpmask);
cpumask_setall(cpus);
/*
* When power savings policy is enabled for the parent domain, idle
* sibling can pick up load irrespective of busy siblings. In this case,
* let the state of idle sibling percolate up as IDLE, instead of
* portraying it as CPU_NOT_IDLE.
*/
if (sd->flags & SD_SHARE_CPUPOWER &&
!test_sd_parent(sd, SD_POWERSAVINGS_BALANCE))
sd_idle = 1;
schedstat_inc(sd, lb_count[CPU_NEWLY_IDLE]);
redo:
update_shares_locked(this_rq, sd);
/*
* 分析调度域中各组的工作量,返回最繁忙的sched_group,
* 如果所有组本来就是平衡的就返回NULL.
*/
group = find_busiest_group(sd, this_cpu, &imbalance, CPU_NEWLY_IDLE,
&sd_idle, cpus, NULL);
/*
* 这里表示所有组都处于平衡状态,函数结束,平衡终止
*/
if (!group) {
schedstat_inc(sd, lb_nobusyg[CPU_NEWLY_IDLE]);
goto out_balanced;
}
/*
* 在最繁忙的组中(sched_group)找到最繁忙的CPU
*/
busiest = find_busiest_queue(group, CPU_NEWLY_IDLE, imbalance, cpus);
if (!busiest) {
schedstat_inc(sd, lb_nobusyq[CPU_NEWLY_IDLE]);
goto out_balanced;
}
BUG_ON(busiest == this_rq);
schedstat_add(sd, lb_imbalance[CPU_NEWLY_IDLE], imbalance);
ld_moved = 0;
/*
* 判断最忙CPU中运行进程数是否大于1
*/
if (busiest->nr_running > 1) {
/* Attempt to move tasks */
/*
* 获取两个队列的锁
*/
double_lock_balance(this_rq, busiest);
/* this_rq->clock is already updated */
update_rq_clock(busiest);
/*
* 把进程从源运行队列迁移到本地运行队列
*/
ld_moved = move_tasks(this_rq, this_cpu, busiest,
imbalance, sd, CPU_NEWLY_IDLE,
&all_pinned);
double_unlock_balance(this_rq, busiest);
if (unlikely(all_pinned)) {
cpumask_clear_cpu(cpu_of(busiest), cpus);
if (!cpumask_empty(cpus))
goto redo;
}
}
if (!ld_moved) {
int active_balance = 0;
schedstat_inc(sd, lb_failed[CPU_NEWLY_IDLE]);
if (!sd_idle && sd->flags & SD_SHARE_CPUPOWER &&
!test_sd_parent(sd, SD_POWERSAVINGS_BALANCE))
return -1;
if (sched_mc_power_savings < POWERSAVINGS_BALANCE_WAKEUP)
return -1;
if (sd->nr_balance_failed++ < 2)
return -1;
/*
* The only task running in a non-idle cpu can be moved to this
* cpu in an attempt to completely freeup the other CPU
* package. The same method used to move task in load_balance()
* have been extended for load_balance_newidle() to speedup
* consolidation at sched_mc=POWERSAVINGS_BALANCE_WAKEUP (2)
*
* The package power saving logic comes from
* find_busiest_group(). If there are no imbalance, then
* f_b_g() will return NULL. However when sched_mc={1,2} then
* f_b_g() will select a group from which a running task may be
* pulled to this cpu in order to make the other package idle.
* If there is no opportunity to make a package idle and if
* there are no imbalance, then f_b_g() will return NULL and no
* action will be taken in load_balance_newidle().
*
* Under normal task pull operation due to imbalance, there
* will be more than one task in the source run queue and
* move_tasks() will succeed. ld_moved will be true and this
* active balance code will not be triggered.
*/
/* Lock busiest in correct order while this_rq is held */
double_lock_balance(this_rq, busiest);
/*
* don't kick the migration_thread, if the curr
* task on busiest cpu can't be moved to this_cpu
*/
if (!cpumask_test_cpu(this_cpu, &busiest->curr->cpus_allowed)) {
double_unlock_balance(this_rq, busiest);
all_pinned = 1;
return ld_moved;
}
/*
* move_tasks()没有成功把某些进程迁移到本地运行队列中,
* 则把busiest->active_balance 置为1然后唤醒migration线程
* 顺着调度域链搜索-从最繁忙运行队列的基本域到最上层,寻找空闲CPU.
*/
if (!busiest->active_balance) {
busiest->active_balance = 1;
busiest->push_cpu = this_cpu;
active_balance = 1;
}
double_unlock_balance(this_rq, busiest);
/*
* Should not call ttwu while holding a rq->lock
*/
spin_unlock(&this_rq->lock);
if (active_balance)
/*
* 此处唤醒migration线程
*/
wake_up_process(busiest->migration_thread);
spin_lock(&this_rq->lock);
} else
sd->nr_balance_failed = 0;
update_shares_locked(this_rq, sd);
return ld_moved;
out_balanced:
schedstat_inc(sd, lb_balanced[CPU_NEWLY_IDLE]);
if (!sd_idle && sd->flags & SD_SHARE_CPUPOWER &&
!test_sd_parent(sd, SD_POWERSAVINGS_BALANCE))
return -1;
sd->nr_balance_failed = 0;
return 0;
}load_balance()函数实现把进程从源运行队列迁移到本地运行队列中来是通过move_tasks()函数实现的,在move_tasks()函数中优先级最高的(sched_class_highest)busiest运行队列的过期进程开始寻找,如果过期进程没有则在busiest的运行队列的活动进程中寻找。这个过程通过struct sched_class中钩子load_balance挂上load_balance_fair()函数,然后调用__load_balance_fair()函数,而__load_balance_fair()函数调用balance_tasks()函数,在balance_tasks()函数中会通过can_migrate_task()函数判断当前进程能否被迁移需要满足一下几个条件:
- 本地CPU包含在进程描述符cpus_allowed中。
- 进程有没有在远程CPU上执行。
- 以下条件满足其一:
- 本地CPU空闲。如果支持超线程,则所有本地物理芯片中逻辑CPU必须空闲。
- 在平衡调度域时反复进行进程迁移都不成功
- 被迁移进程未被高速缓存命中
以上条件都满足则can_migrate_task()函数返回1,则调用pull_task()函数把候选进程迁移到本地运行队列中。pull_task()函数调用deactivate_task()-dequeue_task()把进程从远程运行队列中删除,调用activate_task()-enqueue_task()
把进程插入到本地运行队列。
3.3针对 fork(), exec() 的处理
当一个进行调用 exec() 执行时,本来就是要加载一个新进程,缓存本来就会失效。所以,move 到哪里都可以。因此找设置了 SD_BALANCE_EXEC 标记的 domain 。然后把进程移动到那个 domain 中最闲的 CPU group 的 CPU 上。fork() 时也进行类似的处理。
4结语
以上就是笔者对于Linux系统中多处理器运行队列平衡学习的一些知识,希望对大家有一定帮助,由于笔者对知识理解分析问题本篇文章对调度域的分层还未进行细致的讲解,因为笔者计划把这个问题与cache的知识结合起来写一篇文章分析对cache的的理解和性能方面的问题,最后如果文章有纰漏,错误之处希望大家指出笔者将及时纠正。