多进程编程就是孙悟空拔猴毛--变猢狲
Our bravest and best lessons are not learned through success, but through misadventure.--------我们最好的教训不是透过成功而学到,而是透过不幸的遭遇。
文章目录
- 1, 进程回顾
- 2, 进程内存空间回顾
- 3, 系统调用fork()
- 4, 系统调用vfork()
- 5, fork和vfork的区别
- 6, 写时复制
- 6.1 写时复制的好处
- 6.2 写时复制扩展知识
- 7,子进程继承了父进程什么东西
- 8, 其他相关API函数
- exec*()
- wait()和waitpid()
- system()(慎用)和popen()
小黑喜欢把多进程编程看成孙悟空拔毛,拔一根毛就是fork()一下,就会将自己的本领复制到新的孙悟空上,但是又有独特的地方,然后新的分身就会去干其他事情。
1, 进程回顾
程序与进程的区别: 正在正常运行的程序及其所占用的系统资源(CPU时间片、内存等)就叫做进程,一个进程可以执行多个程序。
例如你平常打开的QQ就是一个进程。
想要进一步了解进程的同学可以移步
https://blog.csdn.net/weixin_46027505/article/details/104812719
- 在Linux系统下可以使用
ps aux 命令用来查看所有进程ID
Linux停止一个进程的运行命令: kill [进程ID] 或 killall [进程名]
Linux停止一个进程运行的函数:int kill(pid_t pid, int sig);
获取进程ID的函数:
pid_t getpid(void); //获取自己进程ID
pid_t getppid(void); //获取父进程ID
2, 进程内存空间回顾
这部分小黑另外写了一篇博客,生疏的同学可以移步:
https://blog.csdn.net/weixin_46027505/article/details/105076010
还有关于僵尸进程的博客:
https://blog.csdn.net/weixin_46027505/article/details/105097361
3, 系统调用fork()
Linux下有两个基本的系统调用可以用于创建子进程:fork()和vfork()。fork在英文中是"分叉"的意思。为什么取这个名字呢? 因为一个进程在运行中,如果使用了fork,就产生了另一个进程,于是进程就”分叉”了,所以这个名字取得很形象。
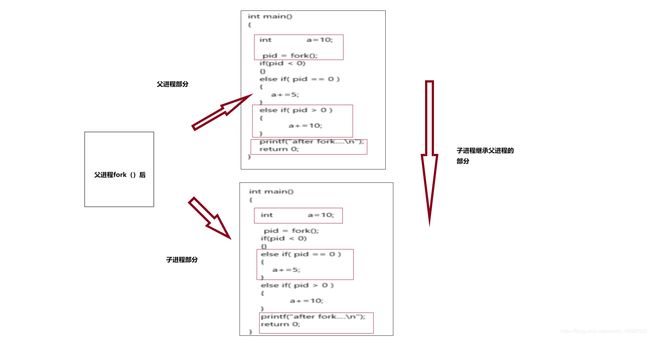
- fork之后,操作系统会复制一个与父进程完全相同的子进程,虽说是父子关系,但是在操作系统看来,他们更像兄弟关系,这 2个进程共享代码空间,但是数据空间是互相独立的,子进程数据空间中的内容是父进程的完整拷贝,指令指针也完全相同,子 进程拥有父进程当前运行到的位置(两进程的程序计数器pc值相同,也就是说,子进程是从fork返回处开始执行的)。
- 可以这样想象,两个进程一直同时运行,而且步调一致,在fork之后,他们分别作不同的工作,也就是分岔了。至于哪一个最先运行,这个与操作系统进程调度算法有关,而且这个问题在实际应用中并不重要,如果需 要父子进程协同,可以通过原语的办法解决。
#include 由fork()创建的新进程被称为子进程。fork()函数被调用一次,但有两次返回。
返回值=0: 子进程在运行,fork()返回0
大于0:父进程在运行,fork返回值为子进程的进程ID。
小于0:出错
说明
- 我们在调用fork()后,需要通 过其返回值来判断当前的代码是在父进程还是子进程运行,
- fork 函数调用失败的原因主要有两个:
- 系统中已经有太多的进程;
- 该实际用户 ID 的进程总数超过了系统限制。
- 将子进程id返回给父进程的理由是:因为一个进程的子进程可以多于一个,没有一个函数使一个进程可以获得其所有子进程的进程id。
- 对子进程来说, 之所以fork返回0给它,是因为它随时可以调用getpid()来获取自己的pid;也可以调用getppid()来获取父进程的id。
- 一般我们fork()后就会在子进程中exec()去执行其他的事情。
- 子进程是父进程的副本,它将得到父进程的文本段、数据段、堆和栈副本,这样父子进程都将继续执行fork()之后的代码。但父子进程并不共享这些存储空间,父子进程只是共享文本段。
- 新创建的父子进程谁先执行没有规定,由系统调用决定
下面我们给出示例代码,进一步理解fork()
#include 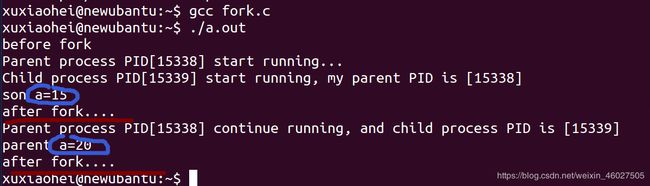
我们观察运行结果父进程和子进程都是将a在原先的全局变量的值上进行自己的操作,说明a = 10在父子进程间有自己的独立的空间,互不干扰,
还有我们发现after fork 打印了两次,是因为子进程退出运行了一次,父进程退出也运行了。
4, 系统调用vfork()
在实现写时复制(这个之后会具体介绍)之前,Unix的设计者们就一直很关注在fork后立刻执行exec所造成的地址空间的浪费。
这样前辈大佬们就想出了vfork()
- vfork()的函数原型和 fork原型一样:
#include 除了子进程必须要立刻执行一次对exec的系统调用,或者调用_exit( )退出,对vfork( )的成功调用所产生的结果和fork( )是一样的。
5, fork和vfork的区别
| fork() | vfork() |
|---|---|
| 子进程拷贝父进程的数据段和代码段 | 子进程与父进程共享数据段,当需要改变共享数据段中变量的值,则拷贝父进程。 |
| 父子进程的执行次序不确定 | 保证子进程先运行,在调用exec或exit之前与父进程数据是共享的,在它调用exec或exit之后父进程才可能被调度运行。 |
| 父子进程相互独立 | 如果在调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。 |
为什么会有vfork,因为以前的fork很傻, 它创建一个子进程时,将会创建一个新的地址
空间,并且拷贝父进程的资源,而往往在子进程中会执行exec 调用,这样,前面的拷贝工
作就是白费力气了,
这种情况下,聪明的人就想出了vfork,它产生的子进程刚开始暂时与
父进程共享地址空间(其实就是线程的概念了),因为这时候子进程在父进程的地址空间中
运行,所以子进程不能进行写操作,并且在儿子“霸占”着老子的房子时候,要委屈老子一
下了,让他在外面歇着(阻塞),一旦儿子执行了exec 或者exit 后,相于儿子买了自己的
房子了,这时候就相于分家了。
//上面这段是从网上看到的,觉得不错,具体从哪来的忘了,就无法附上链接,如果原作者看到的话,望谅解,可以留言,我后面附上链接。
vfork( )是一个历史遗留产物,Linux本不应该实现它。需要注意的是,即使增加了写时复制,vfork( )也要比fork( )快,因为它没有进行页表项的复制。然而,写时复制的出现减少了对于替换fork( )争论。实际上,直到2.2.0内核,vfork( )只是一个封装过的fork( )。因为对vfork( )的需求要小于fork( ),所以vfork( )的这种实现方式是可行的。
6, 写时复制
Linux采用了写时复制的方法,以减少fork时对父进程空间进程整体复制带来的开销。
fork()之后常会紧跟着调用exec来执行另外一个程序,而exec会抛弃父进程的文本段、数据 段和堆栈等并加载另外一个程序,所以现在的很多fork()实现并不执行一个父进程数据段、堆和栈的完全副本拷贝。
写时复制是一种采取了惰性优化方法来避免复制时的系统开销。
它的前提很简单:如果有多个进程要读取它们自己的那部门资源的副本,那么复制是不必要的。每个进程只要保存一个指向这个资源的指针就可以了。只要没有进程要去修改自己的“副本”,就存在着这样的幻觉:每个进程好像独占那个资源。从而就避免了复制带来的负担。如果一个进程要修改自己的那份资源“副本”,那么就会复制那份资源,并把复制的那份提供给进程。不过其中的复制对进程来说是透明的。这个进程就可以修改复制后的资源了,同时其他的进程仍然共享那份没有修改过的资源。
所以这就是名称的由来:在写入时进行复制。
6.1 写时复制的好处
写时复制的主要好处在于:如果进程从来就不需要修改资源,则不需要进行复制。
惰性算法的好处就在于它们尽量推迟代价高昂的操作,直到必要的时刻才会去执行。
6.2 写时复制扩展知识
1, 在使用虚拟内存的情况下,写时复制(Copy-On-Write)是以页为基础进行的。所以,只要进程不修改它全部的地址空间,那么就不必复制整个地址空间。在fork( )调用结束后,父进程和子进程都相信它们有一个自己的地址空间,但实际上它们共享父进程的原始页,接下来这些页又可以被其他的父进程或子进程共享。
2, 写时复制在内核中的实现非常简单。与内核页相关的数据结构可以被标记为只读和写时复制。如果有进程试图修改一个页,就会产生一个缺页中断。内核处理缺页中断的方式就是对该页进行一次透明复制。这时会清除页面的COW属性,表示着它不再被共享。
3, 现代的计算机系统结构中都在内存管理单元(MMU)提供了硬件级别的写时复制支持,所以实现是很容易的。在调用fork( )时,写时复制是有很大优势的。因为大量的fork之后都会跟着执行exec,那么复制整个父进程地址空间中的内容到子进程的地址空间完全是在浪费时间:如果子进程立刻执行一个新的二进制可执行文件的映像,它先前的地址空间就会被交换出去。写时复制可以对这种情况进行优化。
7,子进程继承了父进程什么东西
由子进程自父进程继承到:
进程的资格
环境(environment)变量 堆栈
内存
打开文件的描述符
等。。。
子进程所独有:
进程号
不同的父进程号
等。。。
这部分可以自己查阅
8, 其他相关API函数
exec*()
int execl(const char *path, const char *arg, ...);
int execlp(const char *file, const char *arg, ...);
int execle(const char *path, const char *arg, ..., char * const envp[]);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
上面7种不同的函数都称为exec函数,再fork()之后再调用这些函数中的任何一个都会让新创建的进程执行另外一个程序。
- 其中execl()参数比较简单,所以用得较多
用法:
execl(“程序所在路径”, “命令”, “命令的参数”, NULL);
wait()和waitpid()
wait和waitpid函数是用来处理僵死进程的。
徐小黑在这之前写了一篇相关的博客:
https://blog.csdn.net/weixin_46027505/article/details/105097361
system()(慎用)和popen()
如果我们在程序中,想执行另外一个Linux命令时,可以调用fork()然后再exec执行相应的命令即可,但这样相对比较麻烦。 Linux系统提供了一个system()库函数,该库函数可以快速创建一个进程来执行相应的命令。
int system(const char *command);
- 例如
system("ping -c 4 -I eth0 4.2.2.2");
//执行ping命令
这两个函数同学们可以另外搜索相关博客学习