通过案例来给你分享几个特征构造的方法
特征构造
特征构造常用方法
统计值构造法
连续数据离散化
离散数据编码化
函数变换法
算术运算构造法
特征构造
「1. 概念及工作原理」
概念:特征构造主要是产生衍生变量,所谓衍生变量是指对原始数据进行加工、特征组合,生成有商业意义的新变量(新特征)
「2. 别称」
特征构造也可称为特征交叉、特征组合、数据变换
「3. 优缺点」
优点:新构造的有效且合理的特征可提高模型的预测表现能力。
「缺点:」
(1)新构造的特征不一定是对模型有正向影响作用的,也许对模型来说是没有影响的甚至是负向影响,拉低模型的性能。
(2)因此构造的新特征需要反复参与模型进行训练验证或者进行特征选择之后,才能确认特征是否是有意义的。
特征构造常用方法
下面介绍一些常用的案例方法,作为特征构造的参考方向。特征构造需要根据具体的问题
构造出与目标高度相关的新特征,如此一来说明特征构造是有点难度的。需要不断结合具体业务
情况做出合理分析,才能有根据性的构造出有用的新特征。
统计值构造法
「概念及工作原理」
概念:指通过统计单个或者多个变量的统计值(max,min,count,mean)等而形成新的特征。
「单变量:」
如果某个特征与目标高度相关,那么可以根据具体的情况取这个特征的统计值作为新的特征。
「多变量:」
如果特征与特征之间存在交互影响时,那么可以聚合分组两个或多个变量之后,再以统计值构造出新的特征。
# ------------------------------------
# 代码实现功能
# ------------------------------------
import seaborn as sns
import numpy as np
import pandas as pd
import warnings
from sklearn.preprocessing import LabelEncoder
warnings.filterwarnings('ignore')
df = sns.load_dataset('iris')
le = LabelEncoder()
df['species'] = le.fit_transform(df['species'])
df = df.rename(columns={'species':'labels'})
df = df[['labels', 'sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
print(df.shape)
df.head()
(150, 5)
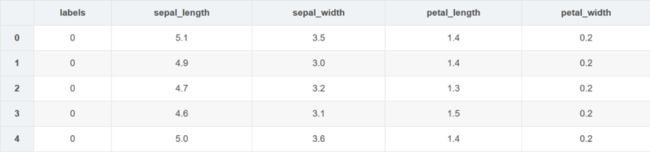
# 单变量
# 计数特征
# 简单示例:统计单个变量数值次数作为新的特征
newF1 = df.groupby(['petal_width'])['petal_width'].count().to_frame().rename(columns={'petal_width':'petal_width_count'}).reset_index()
df_newF1 = pd.merge(df, newF1, on=['petal_width'], how='inner')
print('>>>新构建的计数特征的唯一值数据:\n', df_newF1['petal_width_count'].unique())
df_newF1.head()
>>>新构建的计数特征的唯一值数据:
[29 7 5 1 8 12 13 4 3 2 6]
就这样,我们构造出一个新的特征 petal_width_count
# 多变量
name = {'count': 'petal_width_count', 'min':'petal_width_min',
'max':'petal_width_max', 'mean':'petal_width_mean',
'std':'petal_width_std'}
newF2 = df.groupby(by=['sepal_length'])['petal_width'].agg(['count', 'min', 'max', 'mean', 'std']).rename(columns=name).reset_index()
df_newF2 = pd.merge(df, newF2, on='sepal_length', how='inner')
# 由于聚合分组之后有一些样本的 std 会存在缺失值,所以统一填充为 0
df_newF2['petal_width_std'] = df_newF2['petal_width_std'].fillna(0)
df_newF2.head()
# df_newF2.columns.tolist()
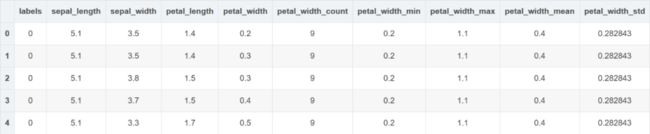
就这样,我们基于两个变量聚合分组之后,使用统计值构建出 5 个新的特征,下面简单地来 验证演示一下新构造特征的有效性如何?
df_newF2.corr()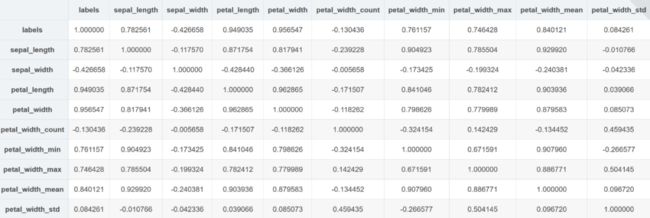
通过上面的相关系数表可以发现,新构建的 5 个特征,除了 count、std 之外,其余 3 个特征跟目标相关性系数较高, 可以初步认为这 3 个特征是有实际意义的特征,下面进行模型训练简单验证一下。
from sklearn.svm import SVC
# 原数据特征表征能力
original_feature = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
X, Y = df_newF2[original_feature] , df_newF2['labels']
svc = SVC()
svc.fit(X,Y)
print('>>>原数据特征的表征能力得分:{}'.format(svc.score(X,Y)), '\n')
# 单个新特征对应的表征能力
# 新特征的表征能力大小与其对应目标之间高度相关系数成正比
# 比如 mean 对应 labels 相关系数最大,所训练得出的 score 也是最大的
new_feature_test = ['petal_width_count', 'petal_width_min', 'petal_width_max', 'petal_width_mean', 'petal_width_std']
for col in new_feature_test:
X, Y = df_newF2[[col]] , df_newF2['labels']
svc = SVC()
svc.fit(X,Y)
print('>>>新特征 {} 的表征能力得分:{}'.format(col, svc.score(X,Y)))
# 多个新特征组合对应的表征能力
print()
for col2 in new_feature_test:
merge_feature = original_feature + [col2]
X, Y = df_newF2[merge_feature] , df_newF2['labels']
svc = SVC()
svc.fit(X,Y)
print('>>>原始特征组合新特征 {} 的表征能力得分:{}'.format(col2, svc.score(X,Y)))
>>>原数据特征的表征能力得分:0.9733333333333334
>>>新特征 petal_width_count 的表征能力得分:0.4866666666666667
>>>新特征 petal_width_min 的表征能力得分:0.6866666666666666
>>>新特征 petal_width_max 的表征能力得分:0.66
>>>新特征 petal_width_mean 的表征能力得分:0.76
>>>新特征 petal_width_std 的表征能力得分:0.5
>>>原始特征组合新特征 petal_width_count 的表征能力得分:0.9733333333333334
>>>原始特征组合新特征 petal_width_min 的表征能力得分:0.9733333333333334
>>>原始特征组合新特征 petal_width_max 的表征能力得分:0.9666666666666667
>>>原始特征组合新特征 petal_width_mean 的表征能力得分:0.9733333333333334
>>>原始特征组合新特征 petal_width_std 的表征能力得分:0.9733333333333334
通过上面简单演示,可以知道在构造新特征之后类似于上面模型训练的方式来验证 新特征的表征能力以及有效性。当然,上面的验证方式只是简单的演示,具体且更标准 的验证方法可以自己去尝试。
连续数据离散化
一般可对年龄、收入等连续数据进行离散化。
优缺点:优点:(1)降低数据的复杂性 (2)可在一定程度上消除多余的噪声
离散数据编码化
常用方法有序号编码、独热编码和二进制编码。
优缺点:
优点:(1)有些模型不支持离散字符串数据,离散编码便于模型学习
函数变换法
「1. 概念及工作原理」
简单常用的函数变换法(一般针对于连续数据):
(1)平方(小数值—>大数值)
(2)开平方(大数值—>小数值)
(3)指数
(4)对数
(5)差分
「2. 理论公式及推导」
平方
开平方
指数
对数
多项式
差分
「为什么要对时间序列数据进行差分?」
首先来看下为什么要对数据进行差分变化,差分变化可以消除数据对时间的依赖性,
也就是降低时间对数据的影响,这些影响通常包括数据的变化趋势以及数据周期性变化的规律。进行差分操作时,
一般用现在的观测值减去上个时刻的值就得到差分结果,就是这么简单,按照这种定义可以计算一系列的差分变换。
「3. 优缺点」
优点:
(1)将不具有正态分布的数据变换成具有正态分布的数据
(2)对于时间序列分析,有时简单的对数变换和差分运算就可以将非平稳序列转换成平稳序列
「4. 应用场景及意义」
应用场景:(1)数据不呈正态分布时可运用 (2)当前特征数据不利于被模型捕获利用
「5. 功能实现」
代码实现如下
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
X = np.array([[0,1,2],
[3,4,5],
[6,7,8]])
X1 = X**2
print('>>>平方\n', X1)
X2 = np.sqrt(X)
print('>>>开平方\n', X2)
X3 = np.exp(X)
print('>>>指数\n', X3)
X4 = np.log(X)
print('>>>对数\n', X4)
>>>平方
[[ 0 1 4]
[ 9 16 25]
[36 49 64]]
>>>开平方
[[0. 1. 1.41421356]
[1.73205081 2. 2.23606798]
[2.44948974 2.64575131 2.82842712]]
>>>指数
[[1.00000000e+00 2.71828183e+00 7.38905610e+00]
[2.00855369e+01 5.45981500e+01 1.48413159e+02]
[4.03428793e+02 1.09663316e+03 2.98095799e+03]]
>>>对数
[[ -inf 0. 0.69314718]
[1.09861229 1.38629436 1.60943791]
[1.79175947 1.94591015 2.07944154]]
# 时间序列常用方法
# 非平稳序列转换成平稳序列
# 对数&差分
y = np.array([1.3, 5.5, 3.3, 5.3, 3.4, 8.0, 6.6, 8.7, 6.8, 7.9])
x = list(range(1, y.shape[0]+1))
# 假设这是一个时间序列图
plt.plot(x,y)
plt.title('original plot')
plt.xlabel('time')
Text(0.5, 0, 'time')
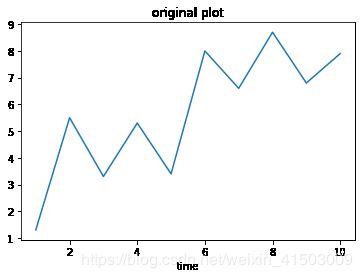
y_log = np.log(y)
# 假设这是一个时间序列图
plt.plot(x,y_log)
plt.title('log plot')
plt.xlabel('time')
Text(0.5, 0, 'time')
def diff(dataset):
DIFF = []
# 由于差分之后的数据比原数据少一个
DIFF.append(dataset[0])
for i in range(1, dataset.shape[0]): # 1 次差分
value = dataset[i] - dataset[i-1]
DIFF.append(value)
for i in range(1, dataset.shape[0]): # 2 次差分
value = DIFF[i] - DIFF[i-1]
DIFF.append(value)
x = list(range(1, len(DIFF)+1))
plt.plot(x,DIFF)
plt.title('biff after')
plt.xlabel('time')
return DIFF
DIFF = diff(y)

从上面图像发现经过对数变换的数据明显比差分变换的效果更好,对数变换后的数据更加的平稳。以后可以根据具体情况使用不同方法处理。
# 多项式
from sklearn.preprocessing import PolynomialFeatures
print('>>>原始数据\n', X)
ploy1 = PolynomialFeatures(1)
print('>>>1 次项\n', ploy1.fit_transform(X))
ploy2 = PolynomialFeatures(2)
print('>>>2 次项\n', ploy2.fit_transform(X))
ploy3 = PolynomialFeatures(3)
print('>>>3 次项\n', ploy3.fit_transform(X))
# 1,x1,x2,x3
>>>原始数据
[[0 1 2]
[3 4 5]
[6 7 8]]
>>>1 次项
[[1. 0. 1. 2.]
[1. 3. 4. 5.]
[1. 6. 7. 8.]]
>>>2 次项
[[ 1. 0. 1. 2. 0. 0. 0. 1. 2. 4.]
[ 1. 3. 4. 5. 9. 12. 15. 16. 20. 25.]
[ 1. 6. 7. 8. 36. 42. 48. 49. 56. 64.]]
>>>3 次项
[[ 1. 0. 1. 2. 0. 0. 0. 1. 2. 4. 0. 0. 0. 0.
0. 0. 1. 2. 4. 8.]
[ 1. 3. 4. 5. 9. 12. 15. 16. 20. 25. 27. 36. 45. 48.
60. 75. 64. 80. 100. 125.]
[ 1. 6. 7. 8. 36. 42. 48. 49. 56. 64. 216. 252. 288. 294.
336. 384. 343. 392. 448. 512.]]
算术运算构造法
「概念及工作原理」
概念:根据实际情况需要,结合与目标相关性预期较高的情况下,由原始特征进行算数运算而形成新的特征。
解读概念为几种情况:
(1)原始单一特征进行算术运算:类似于无量纲那样处理,比如:X/max(X), X+10等
(2)特征之间进行算术运算:X(featureA)/X(featureB),X(featureA)-X(featureB)等