Android音频系统之AudioTrack(一)
1.1 AudioTrack
1.1.1 AudioTrack应用实例
对于Android应用开发人员来讲,音频回放最熟悉的莫过于MediaPlayer,而AudioTrack相信用的人相对会少很多。这是因为MediaPlayer提供了更完整的封装和状态控制,使得我们用很少的代码就可以实现一个简单的音乐播放器。而相比MediaPlayer,AudioTrack更为精练、高效,实际上MediaPlayerService的内部实现就是使用了AudioTrack。
AudioTrack被用于PCM音频流的回放,在数据传送上它有两种方式:
Ø 调用write(byte[],int,int)或write(short[],int,int)把音频数据“push”到AudioTrack中。
Ø 与之相对的,当然就是“pull”形式的数据获取,即数据接收方主动索取的过程,如下图所示:
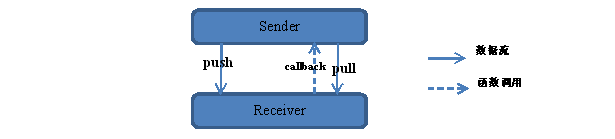
图 13‑20 “push”和“pull”两种数据传送模式
除此之外,AudioTrack还同时支持static和streaming两种模式:
§ static
静态的言下之意就是数据一次性交付给接收方。好处是简单高效,只需要进行一次操作就完成了数据的传递;缺点当然也很明显,对于数据量较大的音频回放,显然它是无法胜任的,因而通常只用于播放铃声、系统提醒等对内存小的操作
§ streaming
流模式和网络上播放视频是类似的,即数据是按照一定规律不断地传递给接收方的。理论上它可用于任何音频播放的场景,不过我们一般在以下情况下采用:
Ø 音频文件过大
Ø 音频属性要求高,比如采样率高、深度大的数据
Ø 音频数据是实时产生的,这种情况就只能用流模式了
下面我们选取AudioTrackTest.java为例来讲解,先从使用者的角度来了解下AudioTrack。
/*cts/tests/tests/media/src/android/media/cts*/
public voidtestSetStereoVolumeMax() throwsException {
final String TEST_NAME= "testSetStereoVolumeMax";
final int TEST_SR =22050;
final int TEST_CONF =AudioFormat.CHANNEL_CONFIGURATION_STEREO;
final int TEST_FORMAT= AudioFormat.ENCODING_PCM_16BIT;
final int TEST_MODE =AudioTrack.MODE_STREAM;
final intTEST_STREAM_TYPE = AudioManager.STREAM_MUSIC;
// --------initialization --------------
/*Step1.*/
int minBuffSize = AudioTrack.getMinBufferSize(TEST_SR, TEST_CONF, TEST_FORMAT);
/*Step 2.*/
AudioTrack track = newAudioTrack(TEST_STREAM_TYPE, TEST_SR, TEST_CONF,
TEST_FORMAT, 2 * minBuffSize,TEST_MODE);
byte data[] = newbyte[minBuffSize];
// -------- test--------------
track.write(data, OFFSET_DEFAULT, data.length);
track.write(data, OFFSET_DEFAULT, data.length);
track.play();
float maxVol =AudioTrack.getMaxVolume();
assertTrue(TEST_NAME, track.setStereoVolume(maxVol, maxVol) == AudioTrack.SUCCESS);
// -------- tear down--------------
track.release();
}
这个TestCase是测试立体声左右声道最大音量的。顺便提一下,关于自动化测试的更多描述,可以参照本书最后一个篇章。用例中涉及到AudioTrack的常规操作都用高显标示出来了。可见大概是这么几个步骤:
Step1@ testSetStereoVolumeMax,getMinBufferSize
字面意思就是获取最小的buffer大小,这个buffer将用于后面AudioTrack的构造函数。它是AudioTrack可以正常使用的一个最低保障,根据官方的建议如果音频文件本身要求较高的话,最好可以采用比MinBufferSize更大的数值。这个函数的实现相对简单:
static public int getMinBufferSize(int sampleRateInHz, int channelConfig,int audioFormat) {
int channelCount = 0;
switch(channelConfig){
caseAudioFormat.CHANNEL_OUT_MONO:
caseAudioFormat.CHANNEL_CONFIGURATION_MONO:
channelCount = 1;
break;
case AudioFormat.CHANNEL_OUT_STEREO:
caseAudioFormat.CHANNEL_CONFIGURATION_STEREO:
channelCount = 2;
break;
default:
…
}
首先得出声道数,目前最多只支持双声道。
if ((audioFormat !=AudioFormat.ENCODING_PCM_16BIT)
&& (audioFormat !=AudioFormat.ENCODING_PCM_8BIT)) {
returnAudioTrack.ERROR_BAD_VALUE;
}
得出音频采样深度,只支持8bit和16bit两种。
// sample rate, notethese values are subject to change
if ( (sampleRateInHz< 4000) || (sampleRateInHz > 48000) ) {
loge("getMinBufferSize(): " + sampleRateInHz +"Hz is nota supported sample rate.");
returnAudioTrack.ERROR_BAD_VALUE;
}
得出采样频率,支持的范围是4k-48kHZ.
int size =native_get_min_buff_size(sampleRateInHz, channelCount, audioFormat);
…
}
也就是说最小buffer大小取决于采样率、声道数和采样深度三个属性。那么具体是如何计算的呢?我们接着看下native层代码实现:
frameworks/base/core/jni/android_media_AudioTrack.cpp
static jint android_media_AudioTrack_get_min_buff_size(JNIEnv*env, jobject thiz,
jint sampleRateInHertz,jint nbChannels, jint audioFormat) {
int frameCount = 0;
if(AudioTrack::getMinFrameCount(&frameCount, AUDIO_STREAM_DEFAULT,
sampleRateInHertz) != NO_ERROR) {
return -1;
}
return frameCount * nbChannels * (audioFormat ==javaAudioTrackFields.PCM16 ? 2 : 1);
}
这里又调用了getMinFrameCount,这个函数用于确定至少需要多少Frame才能保证音频正常播放。那么Frame代表了什么意思呢?可以想象一下视频中帧的概念,它代表了某个时间点的一幅图像。这里的Frame也是类似的,它应该是指某个特定时间点时的音频数据量,所以android_media_AudioTrack_get_min_buff_size中最后采用的计算公式就是:
至少需要多少帧*每帧数据量
= frameCount * nbChannels * (audioFormat ==javaAudioTrackFields.PCM16 ? 2 : 1);
公式中frameCount就是需要的帧数,每一帧的数据量又等于:
Channel数*每个Channel数据量= nbChannels * (audioFormat ==javaAudioTrackFields.PCM16 ? 2 : 1)
层层返回getMinBufferSize就得到了保障AudioTrack正常工作的最小缓冲区大小了。
Step2@ testSetStereoVolumeMax,创建AudioTrack实例
有了minBuffSize后,我们就可以创建一个AudioTrack对象了。它的构造函数原型是:
public AudioTrack (int streamType, int sampleRateInHz, intchannelConfig, int audioFormat, int bufferSizeInBytes, int mode)
除了倒数第二个参数是计算出来的,其它入参在这个TestCase中都是直接指定的。比如streamType是STREAM_MUSIC,sampleRateInHz是22050等等。如果是编写一个音乐播放器,这些参数自然都是需要通过分析音频文件得出来的,所幸的是Android提供了更加易用的MediaPlayer,使得我们不需要理会这些琐碎细节。
创建AudioTrack的一个重要任务就是和AudioFlinger建立联系,它是由native层的代码来实现的:
public AudioTrack(intstreamType, int sampleRateInHz, int channelConfig, int audioFormat,
intbufferSizeInBytes, int mode, int sessionId)
throwsIllegalArgumentException {
…
int initResult = native_setup(new WeakReference
mStreamType,mSampleRate, mChannels, mAudioFormat,
mNativeBufferSizeInBytes, mDataLoadMode, session);
…
}
这里调用了native_setup来创建一个本地AudioTrack对象,如下:
/*frameworks/base/core/jni/android_media_AudioTrack.cpp*/
static int android_media_AudioTrack_native_setup(JNIEnv*env, jobject thiz, jobject weak_this,
jint streamType, jintsampleRateInHertz, jint javaChannelMask,
jint audioFormat, jintbuffSizeInBytes, jint memoryMode, jintArray jSession)
{
…
sp
…
AudioTrackJniStorage* lpJniStorage =new AudioTrackJniStorage();
创建一个Storage对象,直觉告诉我们这可能是存储音频数据的地方,后面我们再详细分析。
…
if (memoryMode== javaAudioTrackFields.MODE_STREAM) {
lpTrack->set(…
audioCallback, //回调函数
&(lpJniStorage->mCallbackData),//回调数据
0,
0,//shared mem
true,// thread cancall Java
sessionId);//audio session ID
} else if (memoryMode ==javaAudioTrackFields.MODE_STATIC) {
…
lpTrack->set(…
audioCallback, &(lpJniStorage->mCallbackData),0,
lpJniStorage->mMemBase,// shared mem
true,// thread cancall Java
sessionId);//audio session ID
}
…// native_setup结束
函数native_setup首先新建了一个AudioTrack(native)对象,然后进行各种属性的计算,最后调用set函数为AudioTrack设置这些属性——我们只保留两种内存模式(STATIC和STREAM)有差异的地方,便于大家比对理解。对于静态数据,入参中的倒数第三个是lpJniStorage->mMemBase,而STREAM类型时为null(0)。
到目前为止我们还没有看到它与AudioFlinger有交互的地方,看来谜底应该就在这个set函数中了。
status_t AudioTrack::set(…
callback_t cbf, void* user, int notificationFrames, constsp
boolthreadCanCallJava, int sessionId)
{
AutoMutex lock(mLock);
…
if (streamType ==AUDIO_STREAM_DEFAULT) {
streamType =AUDIO_STREAM_MUSIC;
}
当不设置streamType时,会被改为默认的AUDIO_STREAM_MUSIC。
…
if (format ==AUDIO_FORMAT_DEFAULT) {
format =AUDIO_FORMAT_PCM_16_BIT;
}
if (channelMask == 0) {
channelMask =AUDIO_CHANNEL_OUT_STEREO;
}
采样深度和声道数默认为16bit和立体声
…
if (format ==AUDIO_FORMAT_PCM_8_BIT && sharedBuffer != 0) {
ALOGE("8-bit datain shared memory is not supported");
return BAD_VALUE;
}
当sharedBuffer!=0时表明是STATIC模式,也就是说静态数据模式下只支持16bit深度否则就报错直接返回,这点要特别注意。
…
audio_io_handle_t output = AudioSystem::getOutput(streamType,sampleRate, format, channelMask, flags);
通过上述的有效性检查后,AudioTrack接着就可以使用底层的音频服务了。那么是直接调用AudioFlinger服务提供的接口吗?理论上这样子做也是可以的,但Android系统考虑得更细,它在AudioTrack与底层服务间又提供了AudioSystem和AudioService。其中前者同时提供了Java和native两层的实现,而AudioService则只有native层的实现。这样子就降低了使用者(AudioTrack)与底层实现(AudioPolicyService、AudioFlinger等等)间的藕合。换句话说,不同版本的Android音频系统通常改动很大,但只要AudioSystem和AudioService向上的接口不变,那么AudioTrack就不需要做修改。
所以上面的getOutput是由AudioSystem来提供的,可以猜测到其内部只是做了些简单的中转功能,最终还是得由AudioPolicyService/AudioFlinger来实现。这个getOutput寻找最适合当前AudioTrack的audio interface以及Output输出(也就是前面通过openOutput打开的通道),然后AudioTrack会向这个Output申请一个Track。
…
mVolume[LEFT] = 1.0f;
mVolume[RIGHT] = 1.0f; /*左右声道的初始值都是最大,另外还有其它成员变量都会在这里赋值,
我们直接省略掉了*/
…
if (cbf != NULL) {
mAudioTrackThread =new AudioTrackThread(*this, threadCanCallJava);
mAudioTrackThread->run("AudioTrack",ANDROID_PRIORITY_AUDIO, 0 /*stack*/);
}
status_t status = createTrack_l(…sharedBuffer, output);
…
} //AudioTrack::set函数结束
因为cbf是audioCallback不为空,所以这里会启动一个AudioTrack线程。这个线程是用于AudioTrack(native)与AudioTrack(java)间的数据事件通知的,这就为上层应用处理事件提供了一个入口,包括:
EVENT_MORE_DATA = 0, /*请求写入更多数据*/
EVENT_UNDERRUN = 1, /*PCM 缓冲发生了underrun*/
EVENT_LOOP_END = 2, /*到达loop end,如果loop count不为空的话
将从loop start重新开始回放*/
EVENT_MARKER = 3, /*Playback head在指定的位置,参考setMarkerPosition*/
EVENT_NEW_POS = 4, /*Playback head在一个新的位置,参考setPositionUpdatePeriod */
EVENT_BUFFER_END = 5 /*Playback head在buffer末尾*/
AudioTrack在AudioFlinger中是以Track来管理的。不过因为它们之间是跨进程的关系,自然需要一个“桥梁”来维护,这个沟通的媒介是IAudioTrack(这有点类似于显示系统中的IWindow)。函数createTrack_l除了为AudioTrack在AudioFlinger中申请一个Track外,还会建立两者间IAudioTrack桥梁:
status_t AudioTrack::createTrack_l(
audio_stream_type_t streamType,uint32_t sampleRate, audio_format_tformat, uint32_t channelMask,
int frameCount,audio_output_flags_t flags, const sp
audio_io_handle_t output)
{
const sp
获得AudioFlinger服务,还记得上一小节的介绍吗?AudioFlinger在ServiceManager中注册,以“media.audio_flinger”为服务名。
…
IAudioFlinger::track_flags_t trackFlags = IAudioFlinger::TRACK_DEFAULT;
…
sp
channelMask, frameCount, trackFlags, sharedBuffer, output, tid,&mSessionId, &status);
//未完待续…
利用AudioFlinger创建一个IAudioTrack,这是它与AudioTrack之间的跨进程通道。除此之处,AudioFlinger还做了什么?我们深入AudioFlinger分析下。
sp
constsp
pid_t tid, int*sessionId, status_t *status)
{
sp
sp
…
PlaybackThread *thread = checkPlaybackThread_l(output);
PlaybackThread*effectThread = NULL;
…
track = thread->createTrack_l(client, streamType, sampleRate, format,
channelMask,frameCount, sharedBuffer, lSessionId, flags, tid, &lStatus);
…
if (lStatus == NO_ERROR) {
trackHandle = new TrackHandle(track);
} else {
client.clear();
track.clear();
}
return trackHandle;
}
我们只留下createTrack中最重要的几个步骤,即:
· AudioFlinger::checkPlaybackThread_l
在AudioFlinger::openOutput时,产生了全局唯一的audio_io_handle_t值,这个值是与PlaybackThread相对应的,它作为mPlaybackThreads键值对的key值存在。
当AudioTrack调用createTrack时,需要传入这个全局标记值,checkPlaybackThread_l借此找到匹配的PlaybackThread
· PlaybackThread::createTrack_l
找到匹配的PlaybackThread后,还需要在其内部创建一个PlaybackThread::Track对象(所有Track都由PlaybackThread::mTracks全局变量管理),这些工作由PlaybackThread::createTrack_l完成。我们以下图表示它们之间的关系:
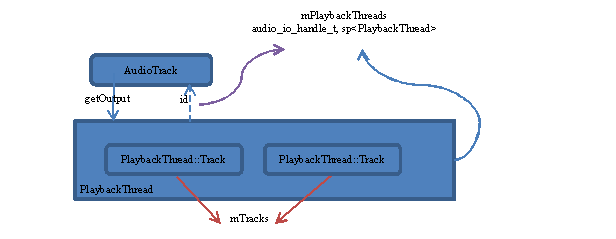
图 13‑21 PlaybackThread:Track的管理
· new TrackHandle
TrackHandle实际上就是IAudioTrack,后续AudioTrack将利用这个binder服务来调用getCblk等接口
我们再接着前面AudioTrack::createTrack_l“未完待续”的部分往下看。
…
sp
…
mAudioTrack = track;
mCblkMemory = cblk;
mCblk= static_cast
…
if (sharedBuffer == 0) {
mCblk->buffers =(char*)mCblk + sizeof(audio_track_cblk_t);
} else {
mCblk->buffers =sharedBuffer->pointer();
mCblk->stepUser(mCblk->frameCount);
}
…
return NO_ERROR;
}
事实上当PlaybackThread创建一个PlaybackThread::Track对象时,所需的缓冲区空间就已经分配了。这块空间是可以跨进程共享的,所以AudioTrack可以通过track->getCblk()来获取。看起来很简单的一句话,但其中涉及到很多的细节,我们会在后面的数据流小节做集中分析。
到目前为止,AudioTrack已经可以通过IAudioTrack(即上面代码段中的track变量)来调用AudioFlinger提供的服务了。我们以序列图来总结这一小节:
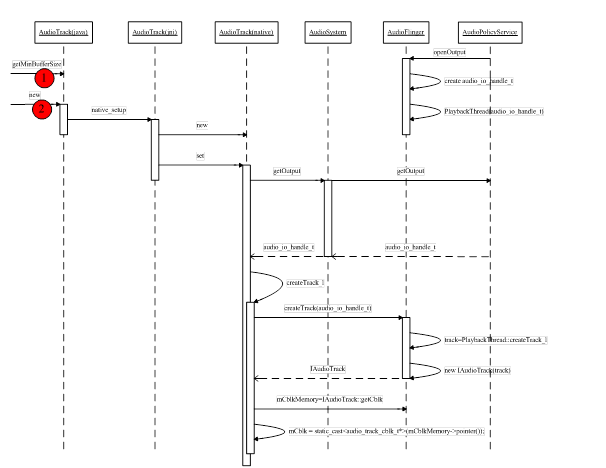
图 13‑22 AudioTrack的创建流程
创建了AudioTrack后,应用实例通过不断写入(AudioTrack::write)数据来回放音频,这部分代码与音频数据流有关,我们也放在后面小节中分析。