《动手学深度学习》手动导入数据集产生错误的解决方法
动手学深度学习
书本网页版 https://zh.gluon.ai/chapter_preface/preface.html
b站视频讲解 https://space.bilibili.com/209599371?spm_id_from=333.788.b_765f7570696e666f.1
书本源代码、pdf及数据集 链接:https://pan.baidu.com/s/1U53gc7ZIXsF1U23x1g8g4A 提取码:f793
在运行书本源代码的时候
需要导入数据集(没有数据集的话第一次会下载数据集
但是 可能出现各种各样的错误导致 我们不能自动下载数据集
(网络问题或者后台路径问题等等
参考资料:https://discuss.gluon.ai/t/topic/642/32
先试着加镜像
set MXNET_GLUON_REPO=https://apache-mxnet.s3.cn-north-1.amazonaws.com.cn/ jupyter notebook

如果 还是RunTimeError 可以试试我的方法
我的解决方法是 使用了同学的数据集以及修改源代码 dataset.py
最后有加 查找SHA1值的方法
1. 四个数据集放在C:\Users\OneLine\.mxnet\datasets\fashion-mnist 文件夹内
(不用解压)
也可以根据网页提示找到原本的下载路径
2. 对比我原来的dataset.py 和同学的dataset.py 稍微修改一下 (建议直接下拉到末尾
dataset.py的位置在 D:\Anaconda\envs\gluon\Lib\site-packages\mxnet\gluon\data\vision
可能不是D盘 要看自己安装软件的位置 ~\mxnet\gluon\data\vision 找到这一串应该没错
我的 :
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# coding: utf-8
# pylint: disable=
"""Dataset container."""
__all__ = ['MNIST', 'FashionMNIST', 'CIFAR10', 'CIFAR100',
'ImageRecordDataset', 'ImageFolderDataset']
import os
import gzip
import tarfile
import struct
import warnings
import numpy as np
from .. import dataset
from ...utils import download, check_sha1, _get_repo_file_url
from .... import nd, image, recordio, base
class MNIST(dataset._DownloadedDataset):
"""MNIST handwritten digits dataset from http://yann.lecun.com/exdb/mnist
Each sample is an image (in 3D NDArray) with shape (28, 28, 1).
Parameters
----------
root : str, default $MXNET_HOME/datasets/mnist
Path to temp folder for storing data.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'mnist'),
train=True, transform=None):
self._train = train
self._train_data = ('train-images-idx3-ubyte.gz','0cf37b0d40ed5169c6b3aba31069a9770ac9043d')
self._train_label = ('train-labels-idx1-ubyte.gz','236021d52f1e40852b06a4c3008d8de8aef1e40b')
self._test_data = ('t10k-images-idx3-ubyte.gz','626ed6a7c06dd17c0eec72fa3be1740f146a2863')
self._test_label = ('t10k-labels-idx1-ubyte.gz','17f9ab60e7257a1620f4ad76bbbaf857c3920701')
self._namespace = 'mnist'
super(MNIST, self).__init__(root, transform)
def _get_data(self):
if self._train:
data, label = self._train_data, self._train_label
else:
data, label = self._test_data, self._test_label
namespace = 'gluon/dataset/'+self._namespace
data_file = download(_get_repo_file_url(namespace, data[0]),
path=self._root,
sha1_hash=data[1])
label_file = download(_get_repo_file_url(namespace, label[0]),
path=self._root,
sha1_hash=label[1])
with gzip.open(label_file, 'rb') as fin:
struct.unpack(">II", fin.read(8))
label = np.frombuffer(fin.read(), dtype=np.uint8).astype(np.int32)
with gzip.open(data_file, 'rb') as fin:
struct.unpack(">IIII", fin.read(16))
data = np.frombuffer(fin.read(), dtype=np.uint8)
data = data.reshape(len(label), 28, 28, 1)
self._data = nd.array(data, dtype=data.dtype)
self._label = label
class FashionMNIST(MNIST):
"""A dataset of Zalando's article images consisting of fashion products,
a drop-in replacement of the original MNIST dataset from
https://github.com/zalandoresearch/fashion-mnist
Each sample is an image (in 3D NDArray) with shape (28, 28, 1).
Parameters
----------
root : str, default $MXNET_HOME/datasets/fashion-mnist'
Path to temp folder for storing data.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'fashion-mnist'),
train=True, transform=None):
self._train = train
self._train_data = ('train-images-idx3-ubyte.gz','0cf37b0d40ed5169c6b3aba31069a9770ac9043d')
self._train_label = ('train-labels-idx1-ubyte.gz','236021d52f1e40852b06a4c3008d8de8aef1e40b')
self._test_data = ('t10k-images-idx3-ubyte.gz','626ed6a7c06dd17c0eec72fa3be1740f146a2863')
self._test_label = ('t10k-labels-idx1-ubyte.gz','17f9ab60e7257a1620f4ad76bbbaf857c3920701')
self._namespace = 'fashion-mnist'
super(MNIST, self).__init__(root, transform) # pylint: disable=bad-super-call
class CIFAR10(dataset._DownloadedDataset):
"""CIFAR10 image classification dataset from https://www.cs.toronto.edu/~kriz/cifar.html
Each sample is an image (in 3D NDArray) with shape (32, 32, 3).
Parameters
----------
root : str, default $MXNET_HOME/datasets/cifar10
Path to temp folder for storing data.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'cifar10'),
train=True, transform=None):
self._train = train
self._archive_file = ('cifar-10-binary.tar.gz', 'fab780a1e191a7eda0f345501ccd62d20f7ed891')
self._train_data = [('data_batch_1.bin', 'aadd24acce27caa71bf4b10992e9e7b2d74c2540'),
('data_batch_2.bin', 'c0ba65cce70568cd57b4e03e9ac8d2a5367c1795'),
('data_batch_3.bin', '1dd00a74ab1d17a6e7d73e185b69dbf31242f295'),
('data_batch_4.bin', 'aab85764eb3584312d3c7f65fd2fd016e36a258e'),
('data_batch_5.bin', '26e2849e66a845b7f1e4614ae70f4889ae604628')]
self._test_data = [('test_batch.bin', '67eb016db431130d61cd03c7ad570b013799c88c')]
self._namespace = 'cifar10'
super(CIFAR10, self).__init__(root, transform)
def _read_batch(self, filename):
with open(filename, 'rb') as fin:
data = np.frombuffer(fin.read(), dtype=np.uint8).reshape(-1, 3072+1)
return data[:, 1:].reshape(-1, 3, 32, 32).transpose(0, 2, 3, 1), \
data[:, 0].astype(np.int32)
def _get_data(self):
if any(not os.path.exists(path) or not check_sha1(path, sha1)
for path, sha1 in ((os.path.join(self._root, name), sha1)
for name, sha1 in self._train_data + self._test_data)):
namespace = 'gluon/dataset/'+self._namespace
filename = download(_get_repo_file_url(namespace, self._archive_file[0]),
path=self._root,
sha1_hash=self._archive_file[1])
with tarfile.open(filename) as tar:
tar.extractall(self._root)
if self._train:
data_files = self._train_data
else:
data_files = self._test_data
data, label = zip(*(self._read_batch(os.path.join(self._root, name))
for name, _ in data_files))
data = np.concatenate(data)
label = np.concatenate(label)
self._data = nd.array(data, dtype=data.dtype)
self._label = label
class CIFAR100(CIFAR10):
"""CIFAR100 image classification dataset from https://www.cs.toronto.edu/~kriz/cifar.html
Each sample is an image (in 3D NDArray) with shape (32, 32, 3).
Parameters
----------
root : str, default $MXNET_HOME/datasets/cifar100
Path to temp folder for storing data.
fine_label : bool, default False
Whether to load the fine-grained (100 classes) or coarse-grained (20 super-classes) labels.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'cifar100'),
fine_label=False, train=True, transform=None):
self._train = train
self._archive_file = ('cifar-100-binary.tar.gz', 'a0bb982c76b83111308126cc779a992fa506b90b')
self._train_data = [('train.bin', 'e207cd2e05b73b1393c74c7f5e7bea451d63e08e')]
self._test_data = [('test.bin', '8fb6623e830365ff53cf14adec797474f5478006')]
self._fine_label = fine_label
self._namespace = 'cifar100'
super(CIFAR10, self).__init__(root, transform) # pylint: disable=bad-super-call
def _read_batch(self, filename):
with open(filename, 'rb') as fin:
data = np.frombuffer(fin.read(), dtype=np.uint8).reshape(-1, 3072+2)
return data[:, 2:].reshape(-1, 3, 32, 32).transpose(0, 2, 3, 1), \
data[:, 0+self._fine_label].astype(np.int32)
class ImageRecordDataset(dataset.RecordFileDataset):
"""A dataset wrapping over a RecordIO file containing images.
Each sample is an image and its corresponding label.
Parameters
----------
filename : str
Path to rec file.
flag : {0, 1}, default 1
If 0, always convert images to greyscale. \
If 1, always convert images to colored (RGB).
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, filename, flag=1, transform=None):
super(ImageRecordDataset, self).__init__(filename)
self._flag = flag
self._transform = transform
def __getitem__(self, idx):
record = super(ImageRecordDataset, self).__getitem__(idx)
header, img = recordio.unpack(record)
if self._transform is not None:
return self._transform(image.imdecode(img, self._flag), header.label)
return image.imdecode(img, self._flag), header.label
class ImageFolderDataset(dataset.Dataset):
"""A dataset for loading image files stored in a folder structure.
like::
root/car/0001.jpg
root/car/xxxa.jpg
root/car/yyyb.jpg
root/bus/123.jpg
root/bus/023.jpg
root/bus/wwww.jpg
Parameters
----------
root : str
Path to root directory.
flag : {0, 1}, default 1
If 0, always convert loaded images to greyscale (1 channel).
If 1, always convert loaded images to colored (3 channels).
transform : callable, default None
A function that takes data and label and transforms them::
transform = lambda data, label: (data.astype(np.float32)/255, label)
Attributes
----------
synsets : list
List of class names. `synsets[i]` is the name for the integer label `i`
items : list of tuples
List of all images in (filename, label) pairs.
"""
def __init__(self, root, flag=1, transform=None):
self._root = os.path.expanduser(root)
self._flag = flag
self._transform = transform
self._exts = ['.jpg', '.jpeg', '.png']
self._list_images(self._root)
def _list_images(self, root):
self.synsets = []
self.items = []
for folder in sorted(os.listdir(root)):
path = os.path.join(root, folder)
if not os.path.isdir(path):
warnings.warn('Ignoring %s, which is not a directory.'%path, stacklevel=3)
continue
label = len(self.synsets)
self.synsets.append(folder)
for filename in sorted(os.listdir(path)):
filename = os.path.join(path, filename)
ext = os.path.splitext(filename)[1]
if ext.lower() not in self._exts:
warnings.warn('Ignoring %s of type %s. Only support %s'%(
filename, ext, ', '.join(self._exts)))
continue
self.items.append((filename, label))
def __getitem__(self, idx):
img = image.imread(self.items[idx][0], self._flag)
label = self.items[idx][1]
if self._transform is not None:
return self._transform(img, label)
return img, label
def __len__(self):
return len(self.items)
同学的:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
# coding: utf-8
# pylint: disable=
"""Dataset container."""
__all__ = ['MNIST', 'FashionMNIST', 'CIFAR10', 'CIFAR100',
'ImageRecordDataset', 'ImageFolderDataset']
import os
import gzip
import tarfile
import struct
import warnings
import numpy as np
from .. import dataset
from ...utils import download, check_sha1, _get_repo_file_url
from .... import nd, image, recordio, base
from .... import numpy as _mx_np # pylint: disable=reimported
from ....util import is_np_array
class MNIST(dataset._DownloadedDataset):
"""MNIST handwritten digits dataset from http://yann.lecun.com/exdb/mnist
Each sample is an image (in 3D NDArray) with shape (28, 28, 1).
Parameters
----------
root : str, default $MXNET_HOME/datasets/mnist
Path to temp folder for storing data.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'mnist'),
train=True, transform=None):
self._train = train
self._train_data = ('train-images-idx3-ubyte.gz',
'6c95f4b05d2bf285e1bfb0e7960c31bd3b3f8a7d')
self._train_label = ('train-labels-idx1-ubyte.gz',
'2a80914081dc54586dbdf242f9805a6b8d2a15fc')
self._test_data = ('t10k-images-idx3-ubyte.gz',
'c3a25af1f52dad7f726cce8cacb138654b760d48')
self._test_label = ('t10k-labels-idx1-ubyte.gz',
'763e7fa3757d93b0cdec073cef058b2004252c17')
self._namespace = 'mnist'
super(MNIST, self).__init__(root, transform)
def _get_data(self):
if self._train:
data, label = self._train_data, self._train_label
else:
data, label = self._test_data, self._test_label
namespace = 'gluon/dataset/'+self._namespace
data_file = download(_get_repo_file_url(namespace, data[0]),
path=self._root,
sha1_hash=data[1])
label_file = download(_get_repo_file_url(namespace, label[0]),
path=self._root,
sha1_hash=label[1])
with gzip.open(label_file, 'rb') as fin:
struct.unpack(">II", fin.read(8))
label = np.frombuffer(fin.read(), dtype=np.uint8).astype(np.int32)
if is_np_array():
label = _mx_np.array(label, dtype=label.dtype)
with gzip.open(data_file, 'rb') as fin:
struct.unpack(">IIII", fin.read(16))
data = np.frombuffer(fin.read(), dtype=np.uint8)
data = data.reshape(len(label), 28, 28, 1)
array_fn = _mx_np.array if is_np_array() else nd.array
self._data = array_fn(data, dtype=data.dtype)
self._label = label
class FashionMNIST(MNIST):
"""A dataset of Zalando's article images consisting of fashion products,
a drop-in replacement of the original MNIST dataset from
https://github.com/zalandoresearch/fashion-mnist
Each sample is an image (in 3D NDArray) with shape (28, 28, 1).
Parameters
----------
root : str, default $MXNET_HOME/datasets/fashion-mnist'
Path to temp folder for storing data.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'fashion-mnist'),
train=True, transform=None):
self._train = train
self._train_data = ('train-images-idx3-ubyte.gz',
'0cf37b0d40ed5169c6b3aba31069a9770ac9043d')
self._train_label = ('train-labels-idx1-ubyte.gz',
'236021d52f1e40852b06a4c3008d8de8aef1e40b')
self._test_data = ('t10k-images-idx3-ubyte.gz',
'626ed6a7c06dd17c0eec72fa3be1740f146a2863')
self._test_label = ('t10k-labels-idx1-ubyte.gz',
'17f9ab60e7257a1620f4ad76bbbaf857c3920701')
self._namespace = 'fashion-mnist'
super(MNIST, self).__init__(root, transform) # pylint: disable=bad-super-call
class CIFAR10(dataset._DownloadedDataset):
"""CIFAR10 image classification dataset from https://www.cs.toronto.edu/~kriz/cifar.html
Each sample is an image (in 3D NDArray) with shape (32, 32, 3).
Parameters
----------
root : str, default $MXNET_HOME/datasets/cifar10
Path to temp folder for storing data.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'cifar10'),
train=True, transform=None):
self._train = train
self._archive_file = ('cifar-10-binary.tar.gz', 'fab780a1e191a7eda0f345501ccd62d20f7ed891')
self._train_data = [('data_batch_1.bin', 'aadd24acce27caa71bf4b10992e9e7b2d74c2540'),
('data_batch_2.bin', 'c0ba65cce70568cd57b4e03e9ac8d2a5367c1795'),
('data_batch_3.bin', '1dd00a74ab1d17a6e7d73e185b69dbf31242f295'),
('data_batch_4.bin', 'aab85764eb3584312d3c7f65fd2fd016e36a258e'),
('data_batch_5.bin', '26e2849e66a845b7f1e4614ae70f4889ae604628')]
self._test_data = [('test_batch.bin', '67eb016db431130d61cd03c7ad570b013799c88c')]
self._namespace = 'cifar10'
super(CIFAR10, self).__init__(root, transform)
def _read_batch(self, filename):
with open(filename, 'rb') as fin:
data = np.frombuffer(fin.read(), dtype=np.uint8).reshape(-1, 3072+1)
return data[:, 1:].reshape(-1, 3, 32, 32).transpose(0, 2, 3, 1), \
data[:, 0].astype(np.int32)
def _get_data(self):
if any(not os.path.exists(path) or not check_sha1(path, sha1)
for path, sha1 in ((os.path.join(self._root, name), sha1)
for name, sha1 in self._train_data + self._test_data)):
namespace = 'gluon/dataset/'+self._namespace
filename = download(_get_repo_file_url(namespace, self._archive_file[0]),
path=self._root,
sha1_hash=self._archive_file[1])
with tarfile.open(filename) as tar:
tar.extractall(self._root)
if self._train:
data_files = self._train_data
else:
data_files = self._test_data
data, label = zip(*(self._read_batch(os.path.join(self._root, name))
for name, _ in data_files))
data = np.concatenate(data)
label = np.concatenate(label)
array_fn = _mx_np.array if is_np_array() else nd.array
self._data = array_fn(data, dtype=data.dtype)
self._label = array_fn(label, dtype=label.dtype) if is_np_array() else label
class CIFAR100(CIFAR10):
"""CIFAR100 image classification dataset from https://www.cs.toronto.edu/~kriz/cifar.html
Each sample is an image (in 3D NDArray) with shape (32, 32, 3).
Parameters
----------
root : str, default $MXNET_HOME/datasets/cifar100
Path to temp folder for storing data.
fine_label : bool, default False
Whether to load the fine-grained (100 classes) or coarse-grained (20 super-classes) labels.
train : bool, default True
Whether to load the training or testing set.
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, root=os.path.join(base.data_dir(), 'datasets', 'cifar100'),
fine_label=False, train=True, transform=None):
self._train = train
self._archive_file = ('cifar-100-binary.tar.gz', 'a0bb982c76b83111308126cc779a992fa506b90b')
self._train_data = [('train.bin', 'e207cd2e05b73b1393c74c7f5e7bea451d63e08e')]
self._test_data = [('test.bin', '8fb6623e830365ff53cf14adec797474f5478006')]
self._fine_label = fine_label
self._namespace = 'cifar100'
super(CIFAR10, self).__init__(root, transform) # pylint: disable=bad-super-call
def _read_batch(self, filename):
with open(filename, 'rb') as fin:
data = np.frombuffer(fin.read(), dtype=np.uint8).reshape(-1, 3072+2)
return data[:, 2:].reshape(-1, 3, 32, 32).transpose(0, 2, 3, 1), \
data[:, 0+self._fine_label].astype(np.int32)
class ImageRecordDataset(dataset.RecordFileDataset):
"""A dataset wrapping over a RecordIO file containing images.
Each sample is an image and its corresponding label.
Parameters
----------
filename : str
Path to rec file.
flag : {0, 1}, default 1
If 0, always convert images to greyscale. \
If 1, always convert images to colored (RGB).
transform : function, default None
A user defined callback that transforms each sample. For example::
transform=lambda data, label: (data.astype(np.float32)/255, label)
"""
def __init__(self, filename, flag=1, transform=None):
super(ImageRecordDataset, self).__init__(filename)
self._flag = flag
self._transform = transform
def __getitem__(self, idx):
record = super(ImageRecordDataset, self).__getitem__(idx)
header, img = recordio.unpack(record)
if self._transform is not None:
return self._transform(image.imdecode(img, self._flag), header.label)
return image.imdecode(img, self._flag), header.label
class ImageFolderDataset(dataset.Dataset):
"""A dataset for loading image files stored in a folder structure.
like::
root/car/0001.jpg
root/car/xxxa.jpg
root/car/yyyb.jpg
root/bus/123.jpg
root/bus/023.jpg
root/bus/wwww.jpg
Parameters
----------
root : str
Path to root directory.
flag : {0, 1}, default 1
If 0, always convert loaded images to greyscale (1 channel).
If 1, always convert loaded images to colored (3 channels).
transform : callable, default None
A function that takes data and label and transforms them::
transform = lambda data, label: (data.astype(np.float32)/255, label)
Attributes
----------
synsets : list
List of class names. `synsets[i]` is the name for the integer label `i`
items : list of tuples
List of all images in (filename, label) pairs.
"""
def __init__(self, root, flag=1, transform=None):
self._root = os.path.expanduser(root)
self._flag = flag
self._transform = transform
self._exts = ['.jpg', '.jpeg', '.png']
self._list_images(self._root)
def _list_images(self, root):
self.synsets = []
self.items = []
for folder in sorted(os.listdir(root)):
path = os.path.join(root, folder)
if not os.path.isdir(path):
warnings.warn('Ignoring %s, which is not a directory.'%path, stacklevel=3)
continue
label = len(self.synsets)
self.synsets.append(folder)
for filename in sorted(os.listdir(path)):
filename = os.path.join(path, filename)
ext = os.path.splitext(filename)[1]
if ext.lower() not in self._exts:
warnings.warn('Ignoring %s of type %s. Only support %s'%(
filename, ext, ', '.join(self._exts)))
continue
self.items.append((filename, label))
def __getitem__(self, idx):
img = image.imread(self.items[idx][0], self._flag)
label = self.items[idx][1]
if self._transform is not None:
return self._transform(img, label)
return img, label
def __len__(self):
return len(self.items)
主要修改了两个地方
(因为数据集和源代码都来自同学 所以SHA值不需要修改了)
(1)删除红框里面的内容 (因为在另一个py文件里没有包含对numpy包的导入
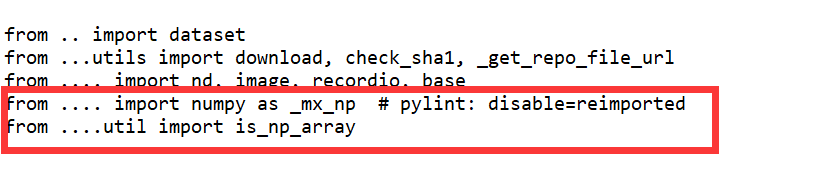
(2) 删除与numpy 和 is_np_array有关的函数

1的部分全部删除
2的部分改成
self._data = nd.array(data, dtype=data.dtype)
self._label = label
后面的部分函数也有包含is_np_array 但是我没删除 (因为没有影响我做的实验 如果有影响的话再删除8
最后写一下 我自己查找SHA1值的方法 虽然后来没改变SHA1值
在对应的文件夹目录栏输入 cmd 跳转之后输入certutil -hashfile 文件名 SHA1
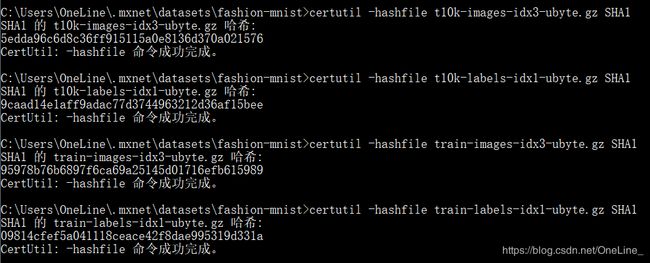
大概这样子啦~~