力扣(LeetCode)数据库最新44题190526Oracle版(2)
排版好有颜色的文章在公众号“八哥的成长心路札记”上有,微信号是bager1912。
以下题目均来自力扣(LeetCode)官网和其他网站,仅用作数据库爱好者学习交流,严禁进行商业及任何非法用途。
570. 至少有5名直接下属的经理
Employee 表包含所有员工和他们的经理。每个员工都有一个 Id,并且还有一列是经理的 Id。
+------+----------+-----------+----------+ |Id |Name |Department |ManagerId | +------+----------+-----------+----------+ |101 |John |A |null | |102 |Dan |A |101 | |103 |James |A |101 | |104 |Amy |A |101 | |105 |Anne |A |101 | |106 |Ron |B |101 | +------+----------+-----------+----------+
给定 Employee 表,请编写一个SQL查询来查找至少有5名直接下属的经理。对于上表,您的SQL查询应该返回:
+-------+ | Name | +-------+ | John | +-------+
注意:
没有人是自己的下属。
select a.name "Name"
from employee a,employee b
where a.id = b.managerid
group by a.name
having count(*)>=5
;
571. 给定数字的频率查询中位数
Numbers 表保存数字的值及其频率。
+----------+-------------+ | Number | Frequency | +----------+-------------| | 0 | 7 | | 1 | 1 | | 2 | 3 | | 3 | 1 | +----------+-------------+
在此表中,数字为 0, 0, 0, 0, 0, 0, 0, 1, 2, 2, 2, 3,所以中位数是 (0 + 0) / 2 = 0。
+--------+ | median | +--------| | 0.0000 | +--------+
请编写一个查询来查找所有数字的中位数并将结果命名为 median 。
这道题参考了两个链接,大家也可以看看:
http://bookshadow.com/weblog/2017/05/01/leetcode-find-median-given-frequency-of-numbers/
https://blog.csdn.net/lv941002/article/details/84619808
八哥整了蛮久才算比较清楚的理解:
select avg(num) median
from (select num,frequency,accfreq,sumfreq
from (select num,frequency,sum(frequency) over(order by num rows between unbounded preceding and current row) accfreq
from numbers),(select sum(frequency) sumfreq
from numbers))
where accfreq between sumfreq/2 and sumfreq/2+frequency;
因为number是关键字,无法运行,所以替换成num。
第一个链接是这样描述思路的:
构造中间表t,包含列Number, Frequency, AccFreq(累积频率), SumFreq(频率求和)
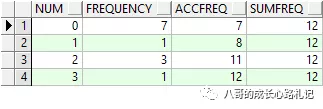
例如样例数据得到的中间表结果为
+----------+-------------+-----------+----------+ | Number | Frequency | AccFreq | SumFreq | +----------+-------------|-----------|----------| | 0 | 7 | 7 | 12 | | 1 | 1 | 8 | 12 | | 2 | 3 | 11 | 12 | | 3 | 1 | 12 | 12 | +----------+-------------+-----------+----------+
AccFreq范围在[SumFreq / 2, SumFreq / 2 + Frequency]的Number均值即为答案。
AccFreq范围的推导过程如下:
AccFreq BETWEEN SumFreq / 2 AND SumFreq / 2 + 1 OR AccFreq - Frequency <= SumFreq / 2 AND AccFreq > SumFreq / 2 + 1
上式含义为:
AccFreq本身介于[SumFreq / 2, SumFreq / 2 + 1]之间 或者上一行的AccFreq <= SumFreq / 2 并且 当前行的AccFreq > SumFreq / 2 + 1
两种情况合并即可得到AccFreq的范围:
AccFreq BETWEEN SumFreq / 2 AND SumFreq / 2 + Frequency
我的理解是:中位数的分布在累积频率中有两种情况,一种是不跨段的,即总数为奇数时的中位数只有一个在一个累积频率中,总数为偶数时的中位数同时在一个累积频率中的情况,比如本题的两个中位数是第6,7位均在第一个累积频率7中;另一种是跨段的,就是总数为偶数时的中位数分布在两个累积频率中,比如中位数是第8,9位,那么分布在8和11两个累积频率中。
我用plsql developer实验了一把:
让我们换一个角度理解:中位数要么是单独一个,要么是连续的两个再除以2,整体思路就是通过建立累加值accfreq,锁定累加值的范围来定位中位数num。所以对于只有一个数的时候,它只在上图中的一行中, 满足这个就行:
AccFreq BETWEEN SumFreq / 2 AND SumFreq / 2 + 1
对于两个数的情况,在同一行时,也只需满足上述条件即可;而不在同一行,则必定在连续的两行,所以可能的情况是1,2行,2,3行,3,4行,但中位数只能在其中之一,于是对其进行筛选,以当前行为基准,
上一行的AccFreq <= SumFreq / 2 并且 当前行的AccFreq > SumFreq / 2 + 1
也即是
AccFreq - Frequency <= SumFreq / 2 AND AccFreq > SumFreq / 2 + 1
说实话这个即是整道题的算法精髓了,八哥也不知道原作者是怎么想到的,但是做得多了,练得多了,该有的算法也就出来了,需要熟练掌握很多相关知识,我们的路还长着呢。
有了这两个区间范围,再利用中学数学知识合并一下:

就有了最终范围:
AccFreq BETWEEN SumFreq / 2 AND SumFreq / 2 + Frequency
其实吧,到这里,八哥发现avg只在中位数是跨段的情况下有用,而在同一端的时候avg没啥用。比如在同一段,比如都是0,那么其实最后是只有一个num到最外层的select,求avg(0),比如都是1,也是只有一个1到最外层的select,求avg(1)。 跨段的时候,会有两个数到最外层select,比如1,2,然后求avg。
第二个链接是用oracle中的分析函数over()来得到累加值。
#第一行至当前行的汇总select a,b,sum(b) over(order by a ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) sum_1 from t1;
A B SUM_1
---------- ---------- ----------
1 10 10
2 10 20
3 10 30
4 10 40
5 10 50
6 10 60
8 100 160
9 200 360
#当前行到第一行的汇总select a,b,sum(b) over(order by a ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) sum_1 from t1;
A B SUM_1
---------- ---------- ----------
1 10 360
2 10 350
3 10 340
4 10 330
5 10 320
6 10 310
8 100 300
9 200 200
over函数是个好家伙。
574. 当选者
表: Candidate
+-----+---------+ | id | Name | +-----+---------+ | 1 | A | | 2 | B | | 3 | C | | 4 | D | | 5 | E | +-----+---------+
表: Vote
+-----+--------------+ | id | CandidateId | +-----+--------------+ | 1 | 2 | | 2 | 4 | | 3 | 3 | | 4 | 2 | | 5 | 5 | +-----+--------------+ id 是自动递增的主键, CandidateId 是 Candidate 表中的 id.
请编写 sql 语句来找到当选者的名字,上面的例子将返回当选者 B.
+------+ | Name | +------+ | B | +------+
注意:
-
你可以假设没有平局,换言之,最多只有一位当选者。
select distinct name
from candidate c,vote v
where c.id = v.candidateid and v.candidateid = (select candidateid
from (select candidateid,dense_rank() over(order by cn desc) rn
from (select candidateid,count(*) cn
from vote
group by candidateid))
where rn=1);
577. 员工奖金
选出所有 bonus < 1000 的员工的 name 及其 bonus。
Employee 表单
+-------+--------+-----------+--------+ | empId | name | supervisor| salary | +-------+--------+-----------+--------+ | 1 | John | 3 | 1000 | | 2 | Dan | 3 | 2000 | | 3 | Brad | null | 4000 | | 4 | Thomas | 3 | 4000 | +-------+--------+-----------+--------+ empId 是这张表单的主关键字
Bonus 表单
+-------+-------+ | empId | bonus | +-------+-------+ | 2 | 500 | | 4 | 2000 | +-------+-------+ empId 是这张表单的主关键字
输出示例:
+-------+-------+ | name | bonus | +-------+-------+ | John | null | | Dan | 500 | | Brad | null | +-------+-------+
select name,bonus
from employee e left join bonus b
on e.empid=b.empid
where nvl(bonus,0)<1000;
578. 查询回答率最高的问题
从 survey_log 表中获得回答率最高的问题,survey_log 表包含这些列:uid, action, question_id, answer_id, q_num, timestamp。
uid 表示用户 id;action 有以下几种值:"show","answer","skip";当 action 值为 "answer" 时 answer_id 非空,而 action 值为 "show" 或者 "skip" 时 answer_id 为空;q_num 表示当前会话中问题的编号。
请编写SQL查询来找到具有最高回答率的问题。
示例:
输入: +------+-----------+--------------+------------+-----------+------------+ | uid | action | question_id | answer_id | q_num | timestamp | +------+-----------+--------------+------------+-----------+------------+ | 5 | show | 285 | null | 1 | 123 | | 5 | answer | 285 | 124124 | 1 | 124 | | 5 | show | 369 | null | 2 | 125 | | 5 | skip | 369 | null | 2 | 126 | +------+-----------+--------------+------------+-----------+------------+ 输出: +-------------+ | survey_log | +-------------+ | 285 | +-------------+ 解释: 问题285的回答率为 1/1,而问题369回答率为 0/1,因此输出285。
注意: 回答率最高的含义是:同一问题编号中回答数占显示数的比例。
select question_id "survey_log"
from (select question_id,dense_rank() over(order by count(answer_id)/sum(case when action='show' then 1 else 0 end) desc) rn
from survey_log
group by question_id)
where rn=1;
579. 查询员工的累计薪水
Employee 表保存了一年内的薪水信息。
请你编写 SQL 语句,来查询一个员工三个月内的累计薪水,但是不包括最近一个月的薪水。
结果请按 'Id' 升序,然后按 'Month' 降序显示。
示例:
输入:
| Id | Month | Salary | |----|-------|--------| | 1 | 1 | 20 | | 2 | 1 | 20 | | 1 | 2 | 30 | | 2 | 2 | 30 | | 3 | 2 | 40 | | 1 | 3 | 40 | | 3 | 3 | 60 | | 1 | 4 | 60 | | 3 | 4 | 70 |
输出:
| Id | Month | Salary | |----|-------|--------| | 1 | 3 | 90 | | 1 | 2 | 50 | | 1 | 1 | 20 | | 2 | 1 | 20 | | 3 | 3 | 100 | | 3 | 2 | 40 |
解释:
员工 '1' 除去最近一个月(月份 '4'),有三个月的薪水记录:月份 '3' 薪水为 40,月份 '2' 薪水为 30,月份 '1' 薪水为 20。
所以近 3 个月的薪水累计分别为 (40 + 30 + 20) = 90,(30 + 20) = 50 和 20。
| Id | Month | Salary | |----|-------|--------| | 1 | 3 | 90 | | 1 | 2 | 50 | | 1 | 1 | 20 |
员工 '2' 除去最近的一个月(月份 '2')的话,只有月份 '1' 这一个月的薪水记录。
| Id | Month | Salary | |----|-------|--------| | 2 | 1 | 20 |
员工 '3' 除去最近一个月(月份 '4')后有两个月,分别为:月份 '4' 薪水为 60 和 月份 '2' 薪水为 40。所以各月的累计情况如下:
| Id | Month | Salary | |----|-------|--------| | 3 | 3 | 100 | | 3 | 2 | 40 |
select id,month,salary
from
(select e1.id,e1.month,sum(e2.salary) salary,row_number() over(partition by e1.id order by e1.month desc) rn
from employee e1, employee e2
where e1.id = e2.id and e1.month-e2.month <= 2 and e1.month-e2.month >= 0
group by e1.id,e1.month)
where rn>1
order by id,month desc;
这道题也比较搞,八哥简单说下吧,把过滤条件变一下:
e1.month-2<=e2.month<=e1.month,
然后就把e1.month=1,2,3,4;1,2;2,3,4代入上面不等式,得出
e2.month=1 1,2 1,2,3 2,3,4 ; 1 1,2 ; 2 2,3 2,3,4
于是发现里面一层在没按month倒排序前是下面这样的,即求三个月内的累加值:

排序以后是这样的:

最后再把rn>1的剔除掉,就有了最终的结果了。
580. 统计各专业学生人数
一所大学有 2 个数据表,分别是 student 和 department ,这两个表保存着每个专业的学生数据和院系数据。
写一个查询语句,查询 department 表中每个专业的学生人数 (即使没有学生的专业也需列出)。
将你的查询结果按照学生人数降序排列。 如果有两个或两个以上专业有相同的学生数目,将这些部门按照部门名字的字典序从小到大排列。
student 表格如下:
| Column Name | Type | |--------------|-----------| | student_id | Integer | | student_name | String | | gender | Character | | dept_id | Integer |
其中, student_id 是学生的学号, student_name 是学生的姓名, gender 是学生的性别, dept_id 是学生所属专业的专业编号。
department 表格如下:
| Column Name | Type | |-------------|---------| | dept_id | Integer | | dept_name | String |
dept_id 是专业编号, dept_name 是专业名字。
这里是一个示例输入:
student 表格:
| student_id | student_name | gender | dept_id | |------------|--------------|--------|---------| | 1 | Jack | M | 1 | | 2 | Jane | F | 1 | | 3 | Mark | M | 2 |
department 表格:
| dept_id | dept_name | |---------|-------------| | 1 | Engineering | | 2 | Science | | 3 | Law |
示例输出为:
| dept_name | student_number | |-------------|----------------| | Engineering | 2 | | Science | 1 | | Law | 0 |
select dept_name,sum(case when s.dept_id is not null then 1 else 0 end) "student_number"
from department d left join student s
on d.dept_id=s.dept_id
group by dept_name
order by "student_number" desc,dept_name;
584. 寻找用户推荐人
给定表 customer ,里面保存了所有客户信息和他们的推荐人。
+------+------+-----------+ | id | name | referee_id| +------+------+-----------+ | 1 | Will | NULL | | 2 | Jane | NULL | | 3 | Alex | 2 | | 4 | Bill | NULL | | 5 | Zack | 1 | | 6 | Mark | 2 | +------+------+-----------+
写一个查询语句,返回一个编号列表,列表中编号的推荐人的编号都 不是 2。
对于上面的示例数据,结果为:
+------+ | name | +------+ | Will | | Jane | | Bill | | Zack | +------+
select name
from customer
where referee_id is null or referee_id != 2;
585. 2016年的投资
写一个查询语句,将 2016 年 (TIV_2016) 所有成功投资的金额加起来,保留 2 位小数。
对于一个投保人,他在 2016 年成功投资的条件是:
-
他在 2015 年的投保额 (TIV_2015) 至少跟一个其他投保人在 2015 年的投保额相同。
-
他所在的城市必须与其他投保人都不同(也就是说维度和经度不能跟其他任何一个投保人完全相同)。
输入格式:
表 insurance 格式如下:
| Column Name | Type | |-------------|---------------| | PID | INTEGER(11) | | TIV_2015 | NUMERIC(15,2) | | TIV_2016 | NUMERIC(15,2) | | LAT | NUMERIC(5,2) | | LON | NUMERIC(5,2) |
PID 字段是投保人的投保编号, TIV_2015 是该投保人在2015年的总投保金额, TIV_2016 是该投保人在2016年的投保金额, LAT 是投保人所在城市的维度, LON 是投保人所在城市的经度。
样例输入
| PID | TIV_2015 | TIV_2016 | LAT | LON | |-----|----------|----------|-----|-----| | 1 | 10 | 5 | 10 | 10 | | 2 | 20 | 20 | 20 | 20 | | 3 | 10 | 30 | 20 | 20 | | 4 | 10 | 40 | 40 | 40 |
样例输出
| TIV_2016 | |----------| | 45.00 |
解释
就如最后一个投保人,第一个投保人同时满足两个条件: 1. 他在 2015 年的投保金额 TIV_2015 为 '10' ,与第三个和第四个投保人在 2015 年的投保金额相同。 2. 他所在城市的经纬度是独一无二的。 第二个投保人两个条件都不满足。他在 2015 年的投资 TIV_2015 与其他任何投保人都不相同。 且他所在城市的经纬度与第三个投保人相同。基于同样的原因,第三个投保人投资失败。 所以返回的结果是第一个投保人和最后一个投保人的 TIV_2016 之和,结果是 45 。
select round(sum(i1.tiv_2016),2) "TIV_2016"
from insurance i1
where i1.tiv_2015 in
(select tiv_2015
from insurance i2
where i1.pid != i2.pid) and (i1.lat,i1.lon) not in (select lat,lon
from insurance i3
where i1.pid != i3.pid);
586. 订单最多的客户
在表 orders 中找到订单数最多客户对应的 customer_number 。
数据保证订单数最多的顾客恰好只有一位。
表 orders 定义如下:
| Column | Type | |-------------------|-----------| | order_number (PK) | int | | customer_number | int | | order_date | date | | required_date | date | | shipped_date | date | | status | char(15) | | comment | char(200) |
样例输入
| order_number | customer_number | order_date | required_date | shipped_date | status | comment | |--------------|-----------------|------------|---------------|--------------|--------|---------| | 1 | 1 | 2017-04-09 | 2017-04-13 | 2017-04-12 | Closed | | | 2 | 2 | 2017-04-15 | 2017-04-20 | 2017-04-18 | Closed | | | 3 | 3 | 2017-04-16 | 2017-04-25 | 2017-04-20 | Closed | | | 4 | 3 | 2017-04-18 | 2017-04-28 | 2017-04-25 | Closed | |
样例输出
| customer_number | |-----------------| | 3 |
解释
customer_number 为 '3' 的顾客有两个订单,比顾客 '1' 或者 '2' 都要多,因为他们只有一个订单 所以结果是该顾客的 customer_number ,也就是 3 。
进阶: 如果有多位顾客订单数并列最多,你能找到他们所有的 customer_number 吗?
select c_n "customer_number"
from (select c_n,dense_rank() over(order by cn desc) rn
from (select customer_number c_n,count(*) cn
from orders
group by customer_number))
where rn=1;
595. 大的国家
这里有张 World 表
+-----------------+------------+------------+--------------+---------------+ | name | continent | area | population | gdp | +-----------------+------------+------------+--------------+---------------+ | Afghanistan | Asia | 652230 | 25500100 | 20343000 | | Albania | Europe | 28748 | 2831741 | 12960000 | | Algeria | Africa | 2381741 | 37100000 | 188681000 | | Andorra | Europe | 468 | 78115 | 3712000 | | Angola | Africa | 1246700 | 20609294 | 100990000 | +-----------------+------------+------------+--------------+---------------+
如果一个国家的面积超过300万平方公里,或者人口超过2500万,那么这个国家就是大国家。
编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
例如,根据上表,我们应该输出:
+--------------+-------------+--------------+ | name | population | area | +--------------+-------------+--------------+ | Afghanistan | 25500100 | 652230 | | Algeria | 37100000 | 2381741 | +--------------+-------------+--------------+
select name,population,area
from world
where area>3000000 or population>25000000;
这个题感觉没啥意思。。。
596. 超过5名学生的课
有一个courses 表 ,有: student (学生) 和 class (课程)。
请列出所有超过或等于5名学生的课。
例如,表:
+---------+------------+ | student | class | +---------+------------+ | A | Math | | B | English | | C | Math | | D | Biology | | E | Math | | F | Computer | | G | Math | | H | Math | | I | Math | +---------+------------+
应该输出:
+---------+ | class | +---------+ | Math | +---------+
Note:
学生在每个课中不应被重复计算。
select class
from courses
group by class
having count(distinct student)>=5;
这道题需要注意下最后note,因为数据集中有重复的student选了同一门class。
597. 好友申请 I :总体通过率
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。现在给如下两个表:
表: friend_request
| sender_id | send_to_id |request_date| |-----------|------------|------------| | 1 | 2 | 2016_06-01 | | 1 | 3 | 2016_06-01 | | 1 | 4 | 2016_06-01 | | 2 | 3 | 2016_06-02 | | 3 | 4 | 2016-06-09 |
表: request_accepted
| requester_id | accepter_id |accept_date | |--------------|-------------|------------| | 1 | 2 | 2016_06-03 | | 1 | 3 | 2016-06-08 | | 2 | 3 | 2016-06-08 | | 3 | 4 | 2016-06-09 | | 3 | 4 | 2016-06-10 |
写一个查询语句,求出好友申请的通过率,用 2 位小数表示。通过率由接受好友申请的数目除以申请总数。
对于上面的样例数据,你的查询语句应该返回如下结果。
|accept_rate| |-----------| | 0.80|
注意:
-
通过的好友申请不一定都在表
friend_request中。在这种情况下,你只需要统计总的被通过的申请数(不管它们在不在原来的申请中),并将它除以申请总数,得到通过率 -
一个好友申请发送者有可能会给接受者发几条好友申请,也有可能一个好友申请会被通过好几次。这种情况下,重复的好友申请只统计一次。
-
如果一个好友申请都没有,通过率为 0.00 。
解释: 总共有 5 个申请,其中 4 个是不重复且被通过的好友申请,所以成功率是 0.80 。
进阶:
-
你能写一个查询语句得到每个月的通过率吗?
-
你能求出每一天的累计通过率吗?
select round(nvl(cn1/decode(cn2,0,1,cn2),0),2) "accept_rate"
from (select count(*) cn1
from (select distinct requester_id, accepter_id
from request_accepted)),(select count(*) cn2
from (select distinct sender_id, send_to_id
from friend_request));
601. 体育馆的人流量
X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号(id)、日期 (date)、 人流量 (people)。
请编写一个查询语句,找出高峰期时段,要求连续三天及以上,并且每天人流量均不少于100。
例如,表 stadium:
+------+------------+-----------+ | id | date | people | +------+------------+-----------+ | 1 | 2017-01-01 | 10 | | 2 | 2017-01-02 | 109 | | 3 | 2017-01-03 | 150 | | 4 | 2017-01-04 | 99 | | 5 | 2017-01-05 | 145 | | 6 | 2017-01-06 | 1455 | | 7 | 2017-01-07 | 199 | | 8 | 2017-01-08 | 188 | +------+------------+-----------+
对于上面的示例数据,输出为:
+------+------------+-----------+ | id | date | people | +------+------------+-----------+ | 5 | 2017-01-05 | 145 | | 6 | 2017-01-06 | 1455 | | 7 | 2017-01-07 | 199 | | 8 | 2017-01-08 | 188 | +------+------------+-----------+
Note:
每天只有一行记录,日期随着 id 的增加而增加。
select distinct a.*
from stadium a,stadium b,stadium c
where a.people>=100 and b.people>=100 and c.people>=100 and ((a.id = b.id-1 and b.id = c.id -1) or
(a.id = b.id-1 and a.id = c.id +1) or
(a.id = b.id+1 and b.id = c.id +1))
order by a.id;
摘自Derrick。
602. 好友申请 II :谁有最多的好友
在 Facebook 或者 Twitter 这样的社交应用中,人们经常会发好友申请也会收到其他人的好友申请。
表 request_accepted 存储了所有好友申请通过的数据记录,其中, requester_id 和 accepter_id 都是用户的编号。
| requester_id | accepter_id | accept_date| |--------------|-------------|------------| | 1 | 2 | 2016_06-03 | | 1 | 3 | 2016-06-08 | | 2 | 3 | 2016-06-08 | | 3 | 4 | 2016-06-09 |
写一个查询语句,求出谁拥有最多的好友和他拥有的好友数目。对于上面的样例数据,结果为:
| id | num | |----|-----| | 3 | 3 |
注意:
-
保证拥有最多好友数目的只有 1 个人。
-
好友申请只会被接受一次,所以不会有 requester_id 和 accepter_id 值都相同的重复记录。
解释:
编号为 '3' 的人是编号为 '1','2' 和 '4' 的好友,所以他总共有 3 个好友,比其他人都多。
进阶:
在真实世界里,可能会有多个人拥有好友数相同且最多,你能找到所有这些人吗?
select id,num
from (select id,count(*) num,dense_rank() over(order by count(*) desc) rn
from (select requester_id id,accepter_id
from request_accepted
union all
select accepter_id id,requester_id
from request_accepted)
group by id)
where rn=1;
未完待续。。。