Spark 入门
Spark 官方提供了两种方式编写代码, 都比较重要, 分别如下
-
spark-shell
Spark shell 是 Spark 提供的一个基于 Scala 语言的交互式解释器, 类似于 Scala 提供的交互式解释器, Spark shell 也可以直接在 Shell 中编写代码执行
这种方式也比较重要, 因为一般的数据分析任务可能需要探索着进行, 不是一蹴而就的, 使用 Spark shell 先进行探索, 当代码稳定以后, 使用独立应用的方式来提交任务, 这样是一个比较常见的流程 -
spark-submit
Spark submit 是一个命令, 用于提交 Scala 编写的基于 Spark 框架, 这种提交方式常用作于在集群中运行任务
1. Spark shell 的方式编写 WordCount
1.1 准备文件
在node01中,创建 /export/data/wordcount.txt
hadoop spark flume
spark hadoop
flume hadoop
1.2 启动 Spark shell
cd /export/servers/spark
bin/spark-shell --master local[2]
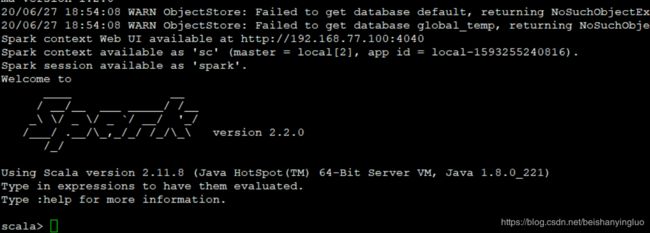
1.3 执行如下代码:
val sourceRdd = sc.textFile("file:///export/data/wordcount.txt")
val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
val result = aggCountRdd.collect
结果:
scala> val result = aggCountRdd.collect
result: Array[(String, Int)] = Array((spark,2), (hadoop,3), (flume,2))
上述代码中 sc 变量指的是 SparkContext, 是 Spark 程序的上下文和入口
正常情况下我们需要自己创建, 但是如果使用 Spark shell 的话, Spark shell 会帮助我们创建, 并且以变量 sc 的形式提供给我们调用

1.flatMap(_.split(" ")) 将数据转为数组的形式, 并展平为多个数据
2.map_, 1 将数据转换为元组的形式
3.reduceByKey(_ + _) 计算每个 Key 出现的次数
使用 Spark shell 可以快速验证想法
Spark 框架下的代码非常类似 Scala 的函数式调用
二 读取 HDFS 上的文件
2.1 上传文件到hdfs
cd /export/data
hdfs dfs -mkdir /dataset
hdfs dfs -put wordcount.txt /dataset/
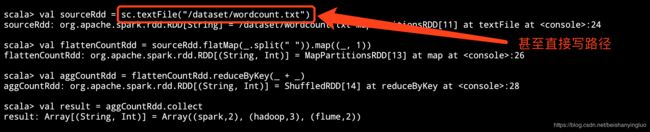
2.2 在 Spark shell 中访问 HDFS
val sourceRdd = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt")
val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
val result = aggCountRdd.collect
结果:
scala> val sourceRdd = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt")
sourceRdd: org.apache.spark.rdd.RDD[String] = hdfs://node01:8020/dataset/wordcount.txt MapPartitionsRDD[6] at textFile at <console>:24
scala> val flattenCountRdd = sourceRdd.flatMap(_.split(" ")).map((_, 1))
flattenCountRdd: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[8] at map at <console>:26
scala> val aggCountRdd = flattenCountRdd.reduceByKey(_ + _)
aggCountRdd: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[9] at reduceByKey at <console>:28
scala> val result = aggCountRdd.collect
result: Array[(String, Int)] = Array((spark,2), (hadoop,3), (flume,2))
如何使得 Spark 可以访问 HDFS?
可以通过指定 HDFS 的 NameNode 地址直接访问, 类似于上面代码中的 sc.textFile("hdfs://node01:8020/dataset/wordcount.txt")
也可以通过向 Spark 配置 Hadoop 的路径, 来通过路径直接访问
1.在 spark-env.sh 中添加 Hadoop 的配置路径
export HADOOP_CONF_DIR="/etc/hadoop/conf"
2.在配置过后, 可以直接使用 hdfs:///路径 的形式直接访问

3.在配置过后, 也可以直接使用路径访问
三 编写独立应用提交 Spark 任务
3.1 创建工程
创建 IDEA 工程
增加 Scala 支持
右键点击工程目录
![]()
选择增加框架支持

选择 Scala 添加框架支持
3.2 编写 Maven 配置文件 pom.xml
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<slf4j.version>1.7.16</slf4j.version>
<log4j.version>1.2.17</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
因为在 pom.xml 中指定了 Scala 的代码目录, 所以创建目录 src/main/scala 和目录 src/test/scala
创建 Scala object WordCount
3.3 编写代码 - 本地运行

本地自己建一个文件!!
package com.xu
import junit.framework.Test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCout {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[6]").setAppName("spark_context")
val sc: SparkContext = new SparkContext(conf)
//2.读取文件计算词频
//val source:RDD[String] = sc.textFile("hdfs://node01:8020/dataset/wordcount.txt", 2)
val source:RDD[String] = sc.textFile("dataset/wordcount.txt", 2)
val words: RDD[String] = source.flatMap(line => line.split(" "))
val wordTulple:RDD[(String, Int)] = words.map { word => (word, 1)}
val wordsCount: RDD[(String, Int)] = wordTulple.reduceByKey { (x,y) => x + y }
println("11111111111111111111" + wordsCount.collect)
val result = wordsCount.collect()
result.foreach(item => println(item))
}
}
异常1:
Exception in thread "main" org.apache.spark.SparkException: An application name must be set in your configuration
没写有 setAppName!!
将文件的路径换为hdfs的路径,那么需要达成jar包,进行测试:
在 node01 中 Jar 包所在的目录执行如下命令:
cd /export/servers/spark/jars
spark-submit --master spark://node01:7077 \
--class cn.itcast.spark.WordCounts \
original-spark-0.1.0.jar
如何在任意目录执行 spark-submit 命令?
在 /etc/profile 中写入如下
export SPARK_BIN=/export/servers/spark/bin
export PATH=$PATH:$SPARK_BIN
执行 /etc/profile 使得配置生效
source /etc/profile
三种运行方式:
第一种: shell
- 作用
1.一般用作于探索阶段, 通过 Spark shell 快速的探索数据规律
2.当探索阶段结束后, 代码确定以后, 通过独立应用的形式上线运行
- 功能
1.Spark shell 可以选择在集群模式下运行, 还是在线程模式下运行
2.Spark shell 是一个交互式的运行环境, 已经内置好了 SparkContext 和 SparkSession 对象, 可以直接使用
3.Spark shell 一般运行在集群中安装有 Spark client 的服务器中, 所以可以自有的访问 HDFS
第二种:本地运行
- 作用
1.在编写独立应用的时候, 每次都要提交到集群中还是不方便, 另外很多时候需要调试程序, 所以在 IDEA 中直接运行会比较方便, 无需打包上传了
- 功能
1.因为本地运行一般是在开发者的机器中运行, 而不是集群中, 所以很难直接使用 HDFS 等集群服务, 需要做一些本地配置, 用的比较少
2.需要手动创建 SparkContext
第三种:集群运行
- 作用
1.正式环境下比较多见, 独立应用编写好以后, 打包上传到集群中, 使用spark-submit来运行, 可以完整的使用集群资源
- 功能
1.同时在集群中通过spark-submit来运行程序也可以选择是用线程模式还是集群模式
2.集群中运行是全功能的, HDFS 的访问, Hive 的访问都比较方便
3.需要手动创建 SparkContext