药品监管系统架构揭秘:海量溯源数据存储与查询 ...
前言
在刚刚过去的2018年,“毒疫苗”事件再次触及了大众的敏感神经,因为十年前的“毒奶粉”事件还历历在目。我们急需创建一个全国性的药品(食品)监控追踪体系。与此同时,近年来随着国家对医药行业的大力支持,中国的医疗事业也出现了跨越式的发展,大量的新型药品上市,极大的丰富了患者和消费者的选择范围。大量的药品在市面上流通,产生了大量的状态数据,且这类数据在爆发式的增长。如何高效的存储和溯源药品状态数据已经成为一个行业难题。传统方案常常采用比如MySQL数据库分库分表的方式,但是这个方案在开发、运维、可扩展性都有不少弊端。
业界开始越来越多的使用分布式的NoSQL方案来解决大数据的问题。比如阿里健康基于表格存储(Tablestore)推出了“码上放心” 药品监管码查询功能,解决了大众的药品查询需求。这仅仅是第一步,建立一个完善全国性药品追踪体系是一个艰巨而漫长的任务。借用网上的一句话,最终我们要实现药品的:“来源可查,去向可追,责任可究”。
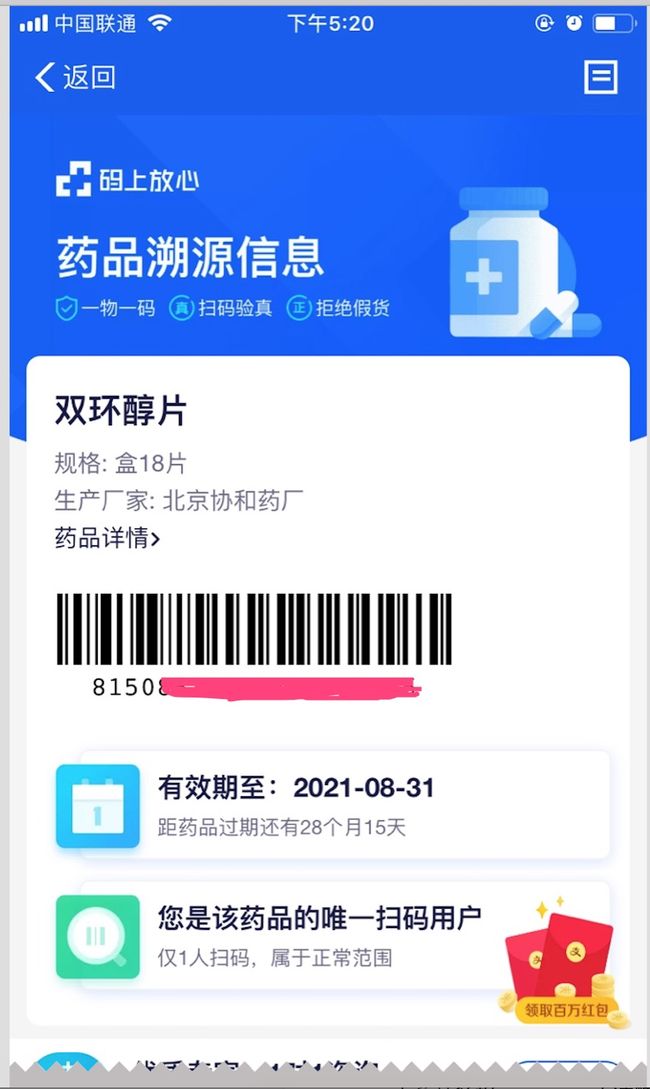
图1 码上放心 溯源截图
在整个药品监管体系中,药品本身的管理和药品轨迹溯源是药品监管体系的两大核心功能,本篇文章主要是介绍使用表格存储的Timestream模型快速高效的实现这两类功能。
核心需求
药品元数据
药品的元数据是指药品在上市之前的在国家药品监督管理局(CFDA)备案信息,记录了药品名称、分类、成分、批次、临床一期、二期、N期测试数据、自研或进口等详细信息,多达几十个字段。
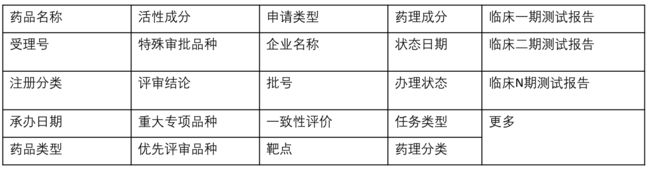 图2 药品元数据
图2 药品元数据
用户会通过页面或者APP的方式浏览和查询药品信息,这需要应用提供多种组合的查询方式,比如:
- 按照药品名称查询:比如查询“阿莫西林”为关键字的药品列表。
- 按照生产企业名称查询:比如之前的疫苗事件,我们可以查询生产企业为“长春长生生物科技股份有限公司”的药品列表。
- 按照时间维度,查询一个时间范围的数据:比如查询某个药企在2017年~2018年生产的抗生素批次。
- 按照某个地域或者范围查询:比如患者可以通过页面,搜索自己附近5公里内特定感冒药。又比如,我们在面对自然灾害时,我们可以使用Geo功能,查询最近范围的应急药品,紧急调往灾区。
上面只是列举的一些典型查询场景,药品备案信息中拥有大量的字段,使用者会从多个查询维度查询数据。因此在保证性能的前提下,提供丰富的查询功能成为元数据管理的主要技术难点。
状态数据
药品的状态数据是指药品在生产、流通过程中产生的状态数据,比如药品的原材料流通、药企生产药品过程中的状态、运输过程的轨迹、医院药店存储和使用数据等。
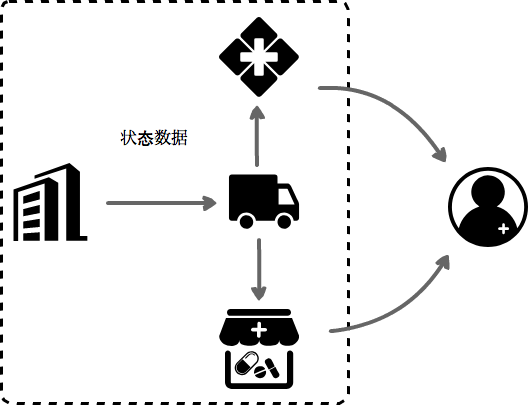 图3 常见状态数据
图3 常见状态数据
药品流通会产生大量的状态数据,这些数据需要持续的记录下来,后续才可以做到真正的药品溯源。我们先来罗列一下药品状态数据:
- 药企的状态数据:这里主要指药品依赖的原材料溯源信息和生产过程的环境数据。这些数据帮助企业监控药品生产状态,帮助药监局审计药品生产过程,在溯源过程中,结合元数据信息,可以让用户对药品有一个更全面的了解。
- 运输的轨迹状态数据:这个主要指药品的运输的产生的轨迹、存储容器高温低温异常事件。“轨迹溯源”可以基于这些数据实现。
- 药店、医院的库存数据:这个主要指药品在相关的医药机构流转和库存信息等,比如上面的“附近药品”查询就可以基于这个数据实现。
从上面的数据来源可知,一盒简单的药品在到送到患者手上之前,会有大量的流通环节,每个环节都会产生大量的状态数据。同时,中国市场药品的规模在万亿人民币级别,并且伴随每年有将近一成的增长,是全球第二大医药市场。要满足如此巨大的规模下的状态数据的存储,极高的写入吞吐、海量存储规模、可控的存储成本成为必须要解决的问题。
解决方案
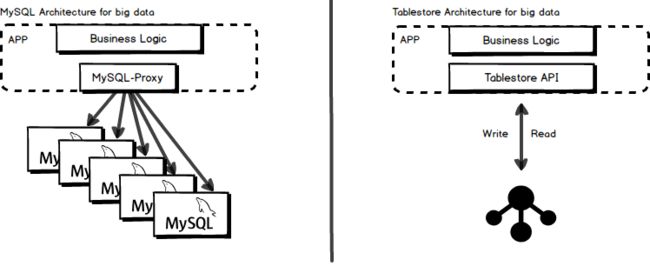
图4 MySQL分库分表 vs Tablestore
从对药品元数据管理和状态数据溯源的总结可知,要满足以上的功能和性能需求,单机已经无法满足要求,需要使用分布式的方案。一般传统的方案会采用MySQL分库分表的方案,但是这个方案在实际生产和运维中面临不少问题,比如:
- 扩容不方便,需要做数据的重新分布。
- 分布键变更很麻烦,分布键需要谨慎选择。
- SQL限制多,功能缺失多,无法充分发挥MySQL自身的优势。
- 传统的关系模型新增字段需要极大的成本,严重阻碍用户业务的扩展。
- 由于单个节点是孤立的节点,需要提供主备来保障数据的可靠性。无法像分布式的NoSQL一样实现自动的故障恢复,需要一个DBA来及时维护库的状态。
- 无法提供灵活的多字段查询,只能依赖二级索引和全表扫描Fliter实现多维查询功能,效率相对较低。
- 无法做到计算和存储分离,用户很难做到计算和存储均衡匹配,导致资源浪费。
- 无法原生支持Geo查询。
总结来看,从理论上能满足以上的功能需求,但是要想真正在生产中使用和维护好这套存储系统,只能说“想爱你并不容易”。在这种大数据的OLTP的场景下,业界一般选用分布式的NoSQL方案。因此我们推荐使用Tablestore一站式的解决以上问题。Tablestore是一款阿里自研的分布式NoSQL服务,提供多元索引支持丰富的查询需求,支撑超大规模的并发访问和低延迟的性能,可以很好的解决药品元数据管理和溯源的需求。
Timestream
Timestream是表格存储推出的最新数据模型,这个模型针对时序数据、轨迹数据、溯源数据,定义了一套简单清晰易用的API,细节可以参考《Tablestore Timestream:为海量时序数据存储设计的全新数据模型》。
在我们列举的药品监管场景中,药品的元数据可以非常简单的抽象为Timestream的元数据(Meta),状态数据抽象为Timestream的Data数据。本文作为一个实战文章,因此使用Timestream模型来快速高效的实现以上两个功能。
从上面的Timestream介绍文章可知,Timestream拥有几个核心概念,分别是:Name, Tag, Attribute, Timestamp, Point(Fields)。我们罗列一个表格,展示怎么将药品的相关数据映射到Timestream的模型中,如图所示:
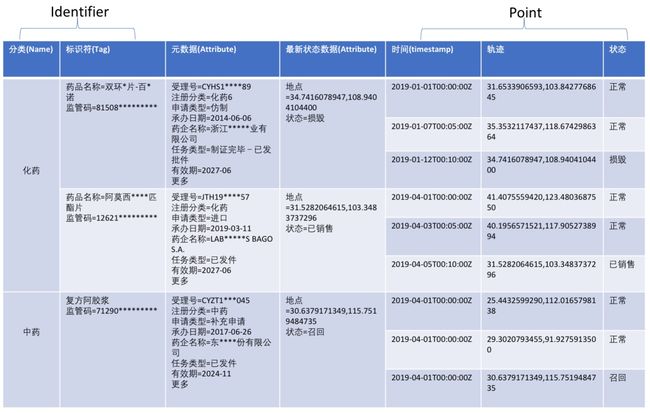
图5 模型转换图
- 分类(Name)+标识符(Tag): 这两个字段唯一决定一个药品数据。
- 元数据(Attribute): 药品的相关属性,当药品在登记在案时这个数据被持久化存储。
- 最新状态数据(Attribute): 如标题,药品最新的状态,比如上面的‘地点’信息,我们可以创建Geo的索引,用户地理信息的查询。
- 时间(Timestamp): 状态数据的发生时间。
- 轨迹、状态: 具体的状态数据,上面只是两个示例,实际上可以支持非常多的字段。
接下来我们通过一个可以运行的Demo,向大家展示怎么使用Timestream API实现元数据管理和溯源功能。
功能实现(Java)
功能列表
写入
- 药品元数据持久化,将药品的相关元数据信息存储到Tablestore中。
- 药品运输轨迹持久化,主要是运输和流转的轨迹,药品的实时状态等,并将Location(位置)作为Geo索引,方便后期的Geo查询。
查询
- 基本的药品详细信息查询,主要是根据用户输入条件,显示药品的元数据。
- 药品的防伪鉴定,结合生产日期,运输轨迹、销售状态和查询用户等数据对药品实行防伪鉴定。
- 查询指定地点范围内的特定药品。
- 药品轨迹重放
依赖
com.aliyun.openservices
tablestore
4.11.2
Meta表的创建
对于一些固定且有特殊索引需求的字段,我们在创建Meta表的时候需要单独指定,比如“生产日期”、地理信息、状态数据等。
考虑到后面的扩展需求,我们增加一个扩展字段,“extension”,用于存储未定义的元数据。
以下示例只是给了部分元数据字段,用户可以根据自己的需求设置更多的索引字段。
public void createMetaTable() {
List index = new ArrayList();
index.add(new AttributeIndexSchema("produced_date", AttributeIndexSchema.Type.LONG));
index.add(new AttributeIndexSchema("period_of_validity", AttributeIndexSchema.Type.LONG));
index.add(new AttributeIndexSchema("loc", AttributeIndexSchema.Type.GEO_POINT));
index.add(new AttributeIndexSchema("links", AttributeIndexSchema.Type.KEYWORD));
index.add(new AttributeIndexSchema("status", AttributeIndexSchema.Type.KEYWORD));
index.add(new AttributeIndexSchema("extension", AttributeIndexSchema.Type.KEYWORD).setIsArray(true));
db.createMetaTable(index);
} Data表的创建
这个比较简单,只需要设定表名即可。因为我们是Schema Free的体系,不需要预先指定列,在写入的时候指定即可。
public void createDataTable() {
db.createDataTable(conf.getDataTableName());
}录入药品元数据和状态数据
元数据导入,我们将一个本地的csv文件中的数据导入到数据库中
public void importMeta() throws IOException {
TimestreamMetaTable metaTable = db.metaTable();
String [] fileHeader = {"分类", "名称", "监管号", "受理号", "生产日期", "有效日期", "注册分类", "申请类型", "企业名称", "任务类型"};
String csvFile = conf.getMetaFile();
CSVFormat format = CSVFormat.DEFAULT.withHeader(fileHeader).withIgnoreHeaderCase().withTrim();
Reader reader = Files.newBufferedReader(Paths.get(csvFile));
CSVParser csvParser = new CSVParser(reader, format);
for (CSVRecord r : csvParser.getRecords()) {
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder(r.get("分类"))
.addTag("名称", r.get("名称"))
.addTag("监管号", r.get("监管号"))
.build();
TimestreamMeta meta = new TimestreamMeta(identifier);
meta.addAttribute("produced_date", r.get("生产日期"));
meta.addAttribute("period_of_validity", r.get("有效日期"));
List extension = new ArrayList();
extension.add("受理号=" + r.get("受理号"));
extension.add("注册分类=" + r.get("注册分类"));
extension.add("申请类型=" + r.get("申请类型"));
extension.add("企业名称=" + r.get("企业名称"));
extension.add("任务类型=" + r.get("任务类型"));
meta.addAttribute("extension", new Gson().toJson(extension));
metaTable.put(meta);
System.out.println(meta.toString());
}
} 状态数据导入,这里loc, links,status在Meta和Data都存储了一次,Meta表中存储主要是做后续的索引查询,Data表中存储主要是做
public void importData() throws Exception {
TimestreamMetaTable metaTable = db.metaTable();
TimestreamDataTable dataTable = db.dataTable(conf.getDataTableName());
String [] fileHeader = {"分类", "名称", "监管号", "生产日期", "位置", "环节", "状态"};
String csvFile = conf.getDataFile();
CSVFormat format = CSVFormat.DEFAULT.withHeader(fileHeader).withIgnoreHeaderCase().withTrim();
Reader reader = Files.newBufferedReader(Paths.get(csvFile));
CSVParser csvParser = new CSVParser(reader, format);
for (CSVRecord r : csvParser.getRecords()) {
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder(r.get("分类"))
.addTag("名称", r.get("名称"))
.addTag("监管号", r.get("监管号"))
.build();
TimestreamMeta meta = new TimestreamMeta(identifier);
String loc = toLocationString(r.get("位置"));
String links = r.get("环节");
String status = r.get("状态");
meta.addAttribute("loc", loc);
meta.addAttribute("links", links);
meta.addAttribute("status", status);
metaTable.update(meta);
Point point = new Point.Builder(this.getTimestamp(r, "生产日期"), TimeUnit.MILLISECONDS)
.addField("loc", loc)
.addField("links", links)
.addField("status", status)
.build();
dataTable.asyncWrite(identifier, point);
System.out.println(point.toString());
}
dataTable.flush();
}
多维度查询药品溯源信息
1. 基本的药品详细信息查询,主要是根据用户输入条件,显示药品的元数据。我们这里根据药品分类、药品名称、生产企业来查询药品。
Filter filter = and(
Name.equal("中药"),
Tag.equal("名称", "复方阿胶"),
Attribute.in("extension", new String[]{"企业名称=山东****也有限公司"})
);
Iterator iter = metaTable.filter(filter).fetchAll();
while (iter.hasNext()) {
TimestreamMeta m = iter.next();
System.out.println(m);
} 2. 药品的防伪鉴定,结合生产日期,运输轨迹、销售状态和查询用户等数据对药品实行防伪鉴定。我们这里输入名称和药品监管码。
Filter filter = and(
Name.equal("中药"),
Tag.equal("名称", "复方阿胶"),
Tag.equal("监管号", "8160000000000019")
);
Iterator iter = metaTable.filter(filter).selectAttributes("status").fetchAll();
while (iter.hasNext()) {
TimestreamMeta m = iter.next();
System.out.println(m.getAttributeAsString("status"));
}
// 从查询的结果来看,药品处于召回中,有使用风险 3. 查询指定地点范围内的特定药品。比如查询使用者5KM范围的“阿莫西林”。
Filter filter = and(
Name.equal("化药"),
Tag.prefix("名称", "阿莫西林"),
Attribute.inGeoDistance("loc", "31.6533906593,103.8427768645", 5 * 1000)
);
Iterator iter = metaTable.filter(filter).fetchAll();
while (iter.hasNext()) {
TimestreamMeta m = iter.next();
System.out.println(m);
} 4. 药品轨迹重放,遍历指定药品的一个轨迹溯源信息。
TimestreamIdentifier identifier = new TimestreamIdentifier.Builder("化药")
.addTag("名称", "阿莫西林")
.addTag("监管号", "8150000000000000")
.build();
Iterator iter = dataTable.get(identifier).select("loc").fetchAll();
while (iter.hasNext()) {
Point p = iter.next();
System.out.println(p);
} 相关代码
可以在github上获取实现代码和示例代码,欢迎大家体验、使用以及给我们提出建议。
代码链接:https://github.com/aliyun/tablestore-examples/tree/master/demos/TraceMedicine
欢迎加入
如果您对表格存储、Timestream感兴趣,对模型使用有疑问、想探讨,欢迎加入【表格存储公开交流群】,群号:11789671。
