SQLite 设计与概念
写在前面:谢谢各位的关注,没想到会有这么多人关注。高兴的同时,也感到压力,因为我接触SQLite也就几天,也没在实际开发中用过,只是最近项目的需求才来研究它,所以我很担心自己的文章是否会有错误,误导别人。但是我很想把自己的学习成果与大家分享,所以如果大家觉得我有不对的地方,望不吝赐教。
我原打算直接从VDBE入手的,因为它起着承上启下的作用,是整个SQLite的核心,并分析源码,但考虑到这是一个系列的文章,我希望能把问题说全,所以还是从基本概念入手,对于初学者,如果没有这些概念,是很继续下去的。好了,下面开始第二章,由于这一章内容很多,我将分两部分讨论,下面开始第一部分。
1、 API
由两部分组成: 核心API(core API) 和扩展API(extension API)
核心API的函数实现基本的数据库操作:连接数据库,处理SQL,遍历结果集。它也包括一些实用函数,比如字符串转换,操作控制,调试和错误处理。
扩展API通过创建你自定义的SQL函数去扩展SQLite。
1.1、SQLite Version 3的一些新特点:
(1)SQLite的API全部重新设计,由第二版的15个函数增加到88个函数。这些函数包括支持UTF-8和UTF-16编码的功能函数。
(2)改进并发性能。加锁子系统引进一种锁升级模型(lock escalation model),解决了第二版的写进程饿死的问题(该问题是任何一个DBMS必须面对的问题)。这种模型保证写进程按照先来先服务的算法得到排斥锁(Exclusive Lock)。甚至,写进程通过把结果写入临时缓冲区(Temporary Buffer),可以在得到排斥锁之前就能开始工作。这对于写要求较高的应用,性能可提高400%(引自参考文献)。
(3)改进的B-树。对于表采用B+树,大大提高查询效率。
(4)SQLite 3最重要的改变是它的存储模型。由第二版只支持文本模型,扩展到支持5种本地数据类型。
总之,SQLite Version 3与SQLite Vertion 2有很大的不同,在灵活性,特点和性能方面有很大的改进。
1.2、主要的数据结构(The Principal Data Structures)
SQLite由很多部分组成-parser,tokenize,virtual machine等等。但是从程序员的角度,最需要知道的是:connection, statements, B-tree和pager。它们之间的关系如下:

上图告诉我们在编程需要知道的三个主要方面:API,事务(Transaction)和锁(Locks)。从技术上来说,B-tree和pager不是API的一部分。但是它们却在事务和锁上起着关键作用(稍后将讨论)。
1.3、Connections和Statements
Connection和statement是执行SQL命令涉及的两个主要数据结构,几乎所有通过API进行的操作都要用到它们。一个连接(Connection)代表在一个独立的事务环境下的一个连接A (connection represents a single connection to a database as well as a single transaction context)。每一个statement都和一个connection关联,它通常表示一个编译过的SQL语句,在内部,它以VDBE字节码表示。Statement包括执行一个命令所需要一切,包括保存VDBE程序执行状态所需的资源,指向硬盘记录的B-树游标,以及参数等等。
1.4、B-tree和pager
一个connection可以有多个database对象---一个主要的数据库以及附加的数据库,每一个数据库对象有一个B-tree对象,一个B-tree有一个pager对象(这里的对象不是面向对象的“对象”,只是为了说清楚问题)。
Statement最终都是通过connection的B-tree和pager从数据库读或者写数据,通过B-tree的游标(cursor)遍历存储在页面(page)中的记录。游标在访问页面之前要把数所从disk加载到内存,而这就是pager的任务。任何时候,如果B-tree需要页面,它都会请求pager从disk读取数据,然后把页面(page)加载到页面缓冲区(page cache),之后,B-tree和与之关联的游标就可以访问位于page中的记录了。
如果cursor改变了page,为了防止事务回滚,pager必须采取特殊的方式保存原来的page。总的来说,pager负责读写数据库,管理内存缓存和页面(page),以及管理事务,锁和崩溃恢复(这些在事务一节会详细介绍)。
总之,关于connection和transaction,你必须知道两件事:
(1) 对数据库的任何操作,一个连接存在于一个事务下。
(2) 一个连接决不会同时存在多个事务下。
whenever a connection does anything with a database, it always operates under exactly one
transaction, no more, no less.
1.5、核心API
核心API 主要与执行SQL命令有关,本质上有两种方法执行SQL语句:prepared query 和wrapped query。Prepared query由三个阶段构成:preparation,execution和finalization。其实wrapped query只是对prepared query的三个过程包装而已,最终也会转化为prepared query的执行。
1.5.1、连接的生命周期(The Connection Lifecycle)
和大多数据库连接相同,由三个过程构成:
(1) 连接数据库(Connect to the database):
每一个SQLite数据库都存储在单独的操作系统文件中,连接,打开数据库的C API为:sqlite3_open(),它的实现位于main.c文件中,如下:
int sqlite3_open(const char *zFilename, sqlite3 **ppDb)
{
return openDatabase(zFilename, ppDb, SQLITE_OPEN_READWRITE | SQLITE_OPEN_CREATE, 0);
}
当连接一个在磁盘上的数据库,如果数据库文件存在,SQLite打开一个文件;如果不存在,SQLite会假定你想创建一个新的数据库。在这种情况下,SQLite不会立即在磁盘上创建一个文件,只有当你向数据库写入数据时才会创建文件,比如:创建表、视图或者其它数据库对象。如果你打开一个数据,不做任何事,然后关闭它,SQLite会创建一个文件,只是一个空文件而已。
另外一个不立即创建一个新文件的原因是,一些数据库的参数,比如:编码,页面大小等,只在在数据库创建前设置。默认情况下,页面大小为1024字节,但是你可以选择512-32768字节之间为 2幂数的数字。有些时候,较大的页面能更有效的处理大量的数据。
(2) 执行事务(Perform transactions):
all commands are executed within transactions。默认情况下,事务自动提交,也就是每一个SQL语句都在一个独立的事务下运行。当然也可以通过使用BEGIN..COMMIT手动提交事务。
(3) 断开连接(Disconnect from the database):
主要是关闭数据库的文件。
1.5.2、执行Prepared Query
前面提到,预处理查询(Prepared Query)是SQLite执行所有SQL命令的方式,包括以下三个过程:
(1) Prepared Query:
分析器(parser),分词器(tokenizer)和代码生成器(code generator)把SQL Statement编译成VDBE字节码,编译器会创建一个statement句柄(sqlite3_stmt),它包括字节码以及其它执行命令和遍历结果集的所有资源。
相应的C API为sqlite3_prepare(),位于prepare.c文件中,如下:
int sqlite3_prepare(
sqlite3 *db, /* Database handle. */
const char *zSql, /* UTF-8 encoded SQL statement. */
int nBytes, /* Length of zSql in bytes. */
sqlite3_stmt **ppStmt, /* OUT: A pointer to the prepared statement */
const char **pzTail /* OUT: End of parsed string */
){
int rc;
rc = sqlite3LockAndPrepare(db,zSql,nBytes,0,ppStmt,pzTail);
assert( rc==SQLITE_OK || ppStmt==0 || *ppStmt==0 ); /* VERIFY: F13021 */
return rc;
}
(2) Execution:
虚拟机执行字节码,执行过程是一个步进(stepwise)的过程,每一步(step)由sqlite3_step()启动,并由VDBE执行一段字节码。由sqlite3_prepare编译字节代码,并由sqlite3_step()启动虚拟机执行。在遍历结果集的过程中,它返回SQLITE_ROW,当到达结果末尾时,返回SQLITE_DONE。
(3) Finalization:
VDBE关闭statement,释放资源。相应的C API为sqlite3_finalize()。
通过下图可以更容易理解该过程:

最后以一个具体的例子结束本节,下节讨论事务。
#include < stdlib.h >
#include " sqlite3.h "
#include < string .h >
int main( int argc, char ** argv)
{
int rc, i, ncols;
sqlite3 * db;
sqlite3_stmt * stmt;
char * sql;
const char * tail;
// 打开数据
rc = sqlite3_open( " foods.db " , & db);
if (rc) {
fprintf(stderr, " Can't open database: %s\n " , sqlite3_errmsg(db));
sqlite3_close(db);
exit( 1 );
}
sql = " select * from episodes " ;
// 预处理
rc = sqlite3_prepare(db, sql, ( int )strlen(sql), & stmt, & tail);
if (rc != SQLITE_OK) {
fprintf(stderr, " SQL error: %s\n " , sqlite3_errmsg(db));
}
rc = sqlite3_step(stmt);
ncols = sqlite3_column_count(stmt);
while (rc == SQLITE_ROW) {
for (i = 0 ; i < ncols; i ++ ) {
fprintf(stderr, " '%s' " , sqlite3_column_text(stmt, i));
}
fprintf(stderr, " \n " );
rc = sqlite3_step(stmt);
}
// 释放statement
sqlite3_finalize(stmt);
// 关闭数据库
sqlite3_close(db);
return 0 ;
}
/Files/hustcat/2008/Learn.rar
2、 事务(Transaction)
2.1、事务的周期(Transaction Lifecycles)
程序与事务之间有两件事值得注意:
(1) 哪些对象在事务下运行——这直接与API有关。
(2) 事务的生命周期,即什么时候开始,什么时候结束以及它在什么时候开始影响别的连接(这点对于并发性很重要)——这涉及到SQLite的具体实现。
一个连接(connection)可以包含多个(statement),而且每个连接有一个与数据库关联的B-tree和一个pager。Pager在连接中起着很重要的作用,因为它管理事务、锁、内存缓存以及负责崩溃恢复(crash recovery)。当你进行数据库写操作时,记住最重要的一件事:在任何时候,只在一个事务下执行一个连接。这些回答了第一个问题。
一般来说,一个事务的生命和statement差不多,你也可以手动结束它。默认情况下,事务自动提交,当然你也可以通过BEGIN..COMMIT手动提交。接下来就是锁的问题。
2.2、锁的状态(Lock States)
锁对于实现并发访问很重要,而对于大型通用的DBMS,锁的实现也十分复杂,而SQLite相对较简单。通常情况下,它的持续时间和事务一致。一个事务开始,它会先加锁,事务结束,释放锁。但是系统在事务没有结束的情况下崩溃,那么下一个访问数据库的连接会处理这种情况。
在SQLite中有5种不同状态的锁,连接(connection)任何时候都处于其中的一个状态。下图显示了相应的状态以及锁的生命周期。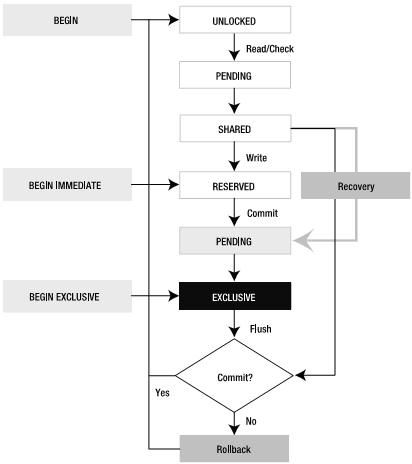
关于这个图有以下几点值得注意:
(1) 一个事务可以在UNLOCKED,RESERVED或EXCLUSIVE三种状态下开始。默认情况下在UNLOCKED时开始。
(2) 白色框中的UNLOCKED, PENDING, SHARED和 RESERVED可以在一个数据库的同一时存在。
(3) 从灰色的PENDING开始,事情就变得严格起来,意味着事务想得到排斥锁(EXCLUSIVE)(注意与白色框中的区别)。
虽然锁有这么多状态,但是从体质上来说,只有两种情况:读事务和写事务。
2.3、读事务(Read Transactions)
我们先来看看SELECT语句执行时锁的状态变化过程,非常简单:一个连接执行select语句,触发一个事务,从UNLOCKED到SHARED,当事务COMMIT时,又回到UNLOCKED,就这么简单。
考虑下面的例子(为了简单,这里用了伪码):
db = open('foods.db')
db.exec('BEGIN')
db.exec('SELECT * FROM episodes')
db.exec('SELECT * FROM episodes')
db.exec('COMMIT')
db.close()
由于显式的使用了BEGIN和COMMIT,两个SELECT命令在一个事务下执行。第一个exec()执行时,connection处于SHARED,然后第二个exec()执行,当事务提交时,connection又从SHARED回到UNLOCKED状态,如下:
UNLOCKED→PENDING→SHARED→UNLOCKED
如果没有BEGIN和COMMIT两行时如下:
UNLOCKED→PENDING→SHARED→UNLOCKED→PENDING→ SHARED→UNLOCKED
2.4、写事务(Write Transactions)
下面我们来考虑写数据库,比如UPDATE。和读事务一样,它也会经历UNLOCKED→PENDING→SHARED,但接下来却是灰色的PENDING,
2.4.1、The Reserved States
当一个连接(connection)向数据库写数据时,从SHARED状态变为RESERVED状态,如果它得到RESERVED锁,也就意味着它已经准备好进行写操作了。即使它没有把修改写入数据库,也可以把修改保存到位于pager中缓存中(page cache)。
当一个连接进入RESERVED状态,pager就开始初始化恢复日志(rollback journal)。在RESERVED状态下,pager管理着三种页面:
(1) Modified pages:包含被B-树修改的记录,位于page cache中。
(2) Unmodified pages:包含没有被B-tree修改的记录。
(3) Journal pages:这是修改页面以前的版本,这些并不存储在page cache中,而是在B-tree修改页面之前写入日志。
Page cache非常重要,正是因为它的存在,一个处于RESERVED状态的连接可以真正的开始工作,而不会干扰其它的(读)连接。所以,SQLite可以高效的处理在同一时刻的多个读连接和一个写连接。
2.4.2 、The Pending States
当一个连接完成修改,就真正开始提交事务,执行该过程的pager进入EXCLUSIVE状态。从RESERVED状态,pager试着获取PENDING锁,一旦得到,就独占它,不允许任何其它连接获得PENDING锁(PENDING is a gateway lock)。既然写操作持有PENDING锁,其它任何连接都不能从UNLOCKED状态进入SHARED状态,即没有任何连接可以进入数据(no new readers, no new writers)。只有那些已经处于SHARED状态的连接可以继续工作。而处于PENDING状态的Writer会一直等到所有这些连接释放它们的锁,然后对数据库加EXCUSIVE锁,进入EXCLUSIVE状态,独占数据库(讨论到这里,对SQLite的加锁机制应该比较清晰了)。
2.4.3、The Exclusive State
在EXCLUSIVE状态下,主要的工作是把修改的页面从page cache写入数据库文件,这是真正进行写操作的地方。
在pager写入modified pages之前,它还得先做一件事:写日志。它检查是否所有的日志都写入了磁盘,而这些通常位于操作的缓冲区中,所以pager得告诉OS把所有的文件写入磁盘,这是由程序synchronous(通过调用OS的相应的API实现)完成的。
日志是数据库进行恢复的惟一方法,所以日志对于DBMS非常重要。如果日志页面没有完全写入磁盘而发生崩溃,数据库就不能恢复到它原来的状态,此时数据库就处于不一致状态。日志写入完成后,pager就把所有的modified pages写入数据库文件。接下来就取决于事务提交的模式,如果是自动提交,那么pager清理日志,page cache,然后由EXCLUSIVE进入UNLOCKED。如果是手动提交,那么pager继续持有EXCLUSIVE锁和保存日志,直到COMMIT或者ROLLBACK。
总之,从性能方面来说,进程占有排斥锁的时间应该尽可能的短,所以DBMS通常都是在真正写文件时才会占有排斥锁,这样能大大提高并发性能。