RxJava 事件流之聚合
Aggregation
前面介绍了如何过滤掉不需要的数据、如何根据各种条件停止发射数据、如何检查数据是否符合某个条件。这些操作对数据流来说都是非常有意义的。 本节介绍如何根据数据流中的数据来生成新的有意义的数据。
本节的操作函数会使用源 Observable 中的事件流中的数据,然后把这些数据转换为其他类型的数据。返回结果是包含一个数据的 Observable。
如果你从头开始阅读本系列教程,则会发现前面代码中有很多重复的地方。 为了避免重复代码并且使代码更加简洁,方便我们聚焦要介绍的函数,从本节开始在示例代码中会引入一个自定义的 Subscriber 。该 Subscribe 用来订阅 Observable 并打印结果:
class PrintSubscriber extends Subscriber{
private final String name;
public PrintSubscriber(String name) {
this.name = name;
}
@Override
public void onCompleted() {
System.out.println(name + ": Completed");
}
@Override
public void onError(Throwable e) {
System.out.println(name + ": Error: " + e);
}
@Override
public void onNext(Object v) {
System.out.println(name + ": " + v);
}
}很简单的一个自定义实现,打印每个事件并使用一个 TAG 来标记是那个 Subscriber.
count
count 函数和 Java 集合中的 size 或者 length 一样。用来统计源 Observable 完成的时候一共发射了多少个数据。
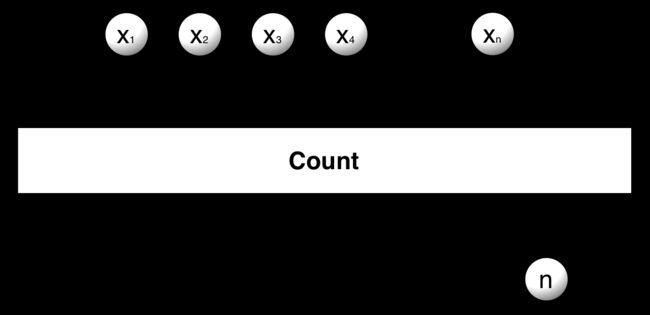
Observable values = Observable.range(0, 3);
values.subscribe(new PrintSubscriber("Values"));
values.count().subscribe(new PrintSubscriber("Count")); 结果:
Values: 0
Values: 1
Values: 2
Values: Completed
Count: 3
Count: Completed如果发射数据的个数超过了 int 最大值,则可以使用 countLong 函数。
first
first 类似于 take(1) , 发射 源 Observable 中的第一个数据。如果没有数据,则返回 ava.util.NoSuchElementException。还有一个重载的带有 过滤 参数,则返回第一个满足该条件的数据。
Observable values = Observable.interval(100, TimeUnit.MILLISECONDS);
values
.first(v -> v>5)
.subscribe(new PrintSubscriber("First")); 结果:
First: 6可以使用 firstOrDefault 来避免 java.util.NoSuchElementException 错误信息,这样如果没有发现数据,则发射一个默认的数据。
last
last 和 lastOrDefault 是和 first 一样的,区别就是当 源 Observable 完成的时候, 发射最后的数据。 如果使用重载的带 过滤参数的函数,则返回最后一个满足该条件的数据。 从后面开始,这种和前面功能非常类似的示例代码就省略了。但是你可以在示例代码中查看这些省略的示例。
single
single 只会发射源 Observable 中的一个数据,如果使用重载的带过滤条件的函数,则发射符合该过滤条件的那个数据。和 first 、last 不一样的地方是,single 会检查数据流中是否只包含一个所需要的的数据,如果有多个则会抛出一个错误信息。所以 single 用来检查数据流中是否有且仅有一个符合条件的数据。所以 single 只有在源 Observable 完成后才能返回。

Observable<Long> values = Observable.interval(100, TimeUnit.MILLISECONDS);
values.take(10) // 获取前 10 个数据 的 Observable
.single(v -> v == 5L) // 有且仅有一个 数据为 5L
.subscribe(new PrintSubscriber("Single1"));
values
.single(v -> v == 5L) // 由于源 Observable 为无限的,所以这个不会打印任何东西
.subscribe(new PrintSubscriber("Single2"));结果:
Single1: 5
Single1: Completed和前面的类似,使用 singleOrDefault 可以返回一个默认值。
Custom aggregators(自定义聚合)
本节前面介绍的几个函数,和之前看到的也没太大区别。下面会介绍两个非常强大的操作函数,可以很方便的来扩展源 Observable。 之前所介绍的所有操作函数都可以通过这两个函数来实现。
reduce
你可能从 MapReduce 中了解过 reduce。该思想是使用源 Observable 中的所有数据两两组合来生成一个单一的 数据。在大部分重载函数中都需要一个函数用来定义如何组合两个数据变成一个。
public final Observable<T> reduce(Func2<T,T,T> accumulator)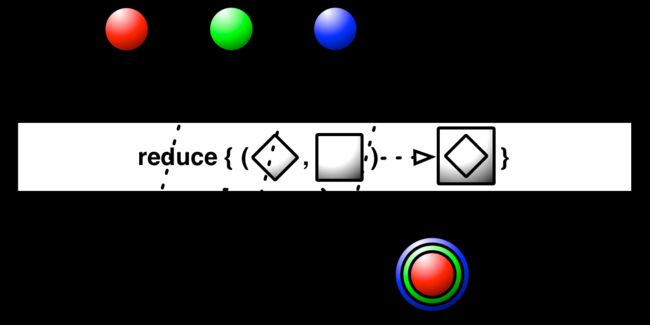
下面的示例是最好的解释。示例代码的第一个功能是对数据流中所有整数求和(0+1+2+3+4+…)。第二个功能是找出所有整数中最小的那个。
Observable values = Observable.range(0,5);
values
.reduce((i1,i2) -> i1+i2)
.subscribe(new PrintSubscriber("Sum"));
values
.reduce((i1,i2) -> (i1>i2) ? i2 : i1)
.subscribe(new PrintSubscriber("Min")); 结果:
Sum: 10
Sum: Completed
Min: 0
Min: CompletedRx 中的 reduce 和并行系统中的 reduce 不一样。在并行系统中的 reduce 是指,计算的取值是不相关的,这样多个机器可以独立并行工作。在 Rx 中是使用从数据流中第一个数据到最后一个数据(从左往右)中的数据来调用 参数 accumulator ,accumulator 用前一次返回的结果和下一个数据来再次调用 accumulator 。 下面这个重载函数更加暴露了这个设计意图。
public final Observable reduce(R initialValue, Func2super T,R> accumulator) accumulator 参数返回的数据类型和 源 Observable 的数据类型可能是不一样的。accumulator 的第一个参数为前一步 accumulator 执行的结果,而第二个参数为 下一个数据。 使用一个初始化的值作为整个处理流程的开始。下面的示例通过重新实现 count 函数来演示 reduce 的使用:
Observable values = Observable.just("Rx", "is", "easy");
values
.reduce(0, (acc,next) -> acc + 1)
.subscribe(new PrintSubscriber("Count")); 结果:
Count: 3
Count: Completed上面示例中的 accumulator 参数为 (acc,next) -> acc + 1 这个 Lambda 表达式,该表达式需要两个参数 acc 和next, 当第一个数据从 源 Observable 发射出来的时候,由于 Lambda 表达式还没有调用过,所以使用 初始值 0 来替代 acc ,使用第一个字符串“Rx” 来调用 accumulator 参数,这样 (acc,next) -> acc + 1 表达式返回的值就是 acc + 1 (而 acc 为初始值 0 ,所以返回 1, 可以看到 这个 next 参数 为源 Observable 的值在这里是没有用的);这样 源Observable 每次发射一个数据, Lambda 就把上一次的结果加1 返回。和 count 的功能一样。
对于前面只返回一个数据结果的操作函数,大部分都可以通过 reduce 来实现。对于那些 源 Observable 没有完成就返回的操作函数来说,是不能使用 reduce 来实现的。所以 可以用 reduce 来实现 last,但是用 reduce 实现的 all 函数和原来的 all 是不太一样的。
scan
scan 和 reduce 很像,不一样的地方在于 scan会发射所有中间的结算结果。
public final Observable<T> scan(Func2<T,T,T> accumulator)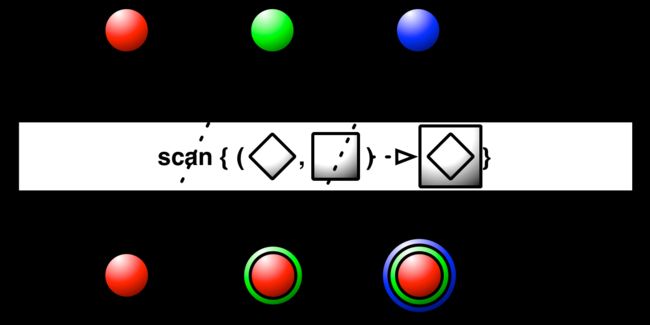
通过上图可以看到和 reduce 的区别, reduce 只是最后把计算结果发射出来,而 scan 把每次的计算结果都发射出来。
Observable values = Observable.range(0,5);
values
.scan((i1,i2) -> i1+i2)
.subscribe(new PrintSubscriber("Sum")); 结果:
Sum: 0
Sum: 1
Sum: 3
Sum: 6
Sum: 10
Sum: Completedreduce 可以通过 scan 来实现: reduce(acc) = scan(acc).takeLast() 。所以 scan 比 reduce 更加通用。
源 Observable 发射数据,经过 scan 处理后 scan 也发射一个处理后的数据,所以 scan 并不要求源 Observable 完成发射。下面示例实现了 查找已经发射数据中的最小值的功能:
Subject values = ReplaySubject.create();
values
.subscribe(new PrintSubscriber("Values"));
values
.scan((i1,i2) -> (i1
.distinctUntilChanged()
.subscribe(new PrintSubscriber("Min"));
values.onNext(2);
values.onNext(3);
values.onNext(1);
values.onNext(4);
values.onCompleted(); 结果:
Values: 2
Min: 2
Values: 3
Values: 1
Min: 1
Values: 4
Values: Completed
Min: CompletedAggregation to collections(把数据聚合到集合中)
使用 reduce 可以把源Observable 发射的数据放到一个集合中:
Observable values = Observable.range(10,5);
values
.reduce(
new ArrayList(),
(acc, value) -> {
acc.add(value);
return acc;
})
.subscribe(v -> System.out.println(v)); reduce 的参数初始值为 new ArrayList(), Lambda 表达式参数把源Observable 发射的数据添加到这个 List 中。当 源Observable 完成的时候,返回这个 List 对象。
结果:
[10, 11, 12, 13, 14]上面的示例代码其实并不太符合 Rx 操作符的原则,操作符有个原则是不能修改其他对象的状态。所以符合原则的实现应该是在每次转换中都创建一个新的 ArrayList 对象。下面是一个符合原则但是效率很低的实现:
.reduce(
new ArrayList<Integer>(),
(acc, value) -> {
ArrayList<Integer> newAcc = (ArrayList<Integer>) acc.clone();
newAcc.add(value);
return newAcc;
})collect
上面每一个值都创建一个新对象的性能是无法接受的。为此, Rx 提供了一个 collect 函数来实现该功能,该函数使用了一个可变的 accumulator 。需要通过文档说明你没有遵守 Rx 的原则使用不可变对象,避免其他人误解:
Observable values = Observable.range(10,5);
values
.collect(
() -> new ArrayList(),
(acc, value) -> acc.add(value))
.subscribe(v -> System.out.println(v)); 结果:
[10, 11, 12, 13, 14]通常你不需要像这样手工的来收集数据, RxJava 提供了很多操作函数来实现这个功能。
toList
前一个示例代码可以这样实现:
Observable values = Observable.range(10,5);
values
.toList()
.subscribe(v -> System.out.println(v)); toSortedList
toSortedList 和前面类似,返回一个排序后的 list,下面是该函数的定义:
public final Observable> toSortedList()
public final Observable> toSortedList(
Func2super T,? super T,java.lang.Integer> sortFunction) 可以使用默认的比较方式来比较对象,也可以提供一个比较参数。该比较参数和 Comparator 接口语义一致。
下面通过一个自定义的比较参数来返回一个倒序排列的整数集合:
Observable values = Observable.range(10,5);
values
.toSortedList((i1,i2) -> i2 - i1)
.subscribe(v -> System.out.println(v)); 结果:
[14, 13, 12, 11, 10]toMap
toMap 把数据流 T 变为一个 Map
public final Observable> toMap(
Func1super T,? extends K> keySelector)
public final Observable> toMap(
Func1super T,? extends K> keySelector,
Func1super T,? extends V> valueSelector)
public final Observable> toMap(
Func1super T,? extends K> keySelector,
Func1super T,? extends V> valueSelector,
Func0extends java.util.Map> mapFactory) keySelector 功能是从一个值 T 中获取他对应的 key。valueSelector 功能是从一个值 T 中获取需要保存 map 中的值。mapFactory 功能是创建该 map 对象。
来看看一个示例:
有这么一个 Person 对象:
class Person {
public final String name;
public final Integer age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}下面的代码使用 Person 的 name 作为 key, Person 作为 map 的value:
Observable values = Observable.just(
new Person("Will", 25),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMap(person -> person.name)
.subscribe(new PrintSubscriber("toMap")); 结果:
toMap: {Saul=Person@7cd84586, Nick=Person@30dae81, Will=Person@1b2c6ec2}
toMap: Completed还可以用 Person 的 age 作为map 的value:
Observable values = Observable.just(
new Person("Will", 25),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMap(
person -> person.name,
person -> person.age)
.subscribe(new PrintSubscriber("toMap")); 结果:
toMap: {Saul=35, Nick=40, Will=25}
toMap: Completed还可以自定义如何生成这个 map 对象:
values
.toMap(
person -> person.name,
person -> person.age,
() -> new HashMap())
.subscribe(new PrintSubscriber("toMap"));最后一个参数为工厂函数,每次一个新的 Subscriber 订阅的时候, 都会返回一个新的 map 对象。
toMultimap
通常情况下多个 value 的 key 可能是一样的。 一个 key 可以映射多个 value 的数据结构为 multimap,multimap 的 value 为一个集合。该过程被称之为 “grouping” (分组)。
public final Observable>> toMultimap(
Func1super T,? extends K> keySelector)
public final Observable>> toMultimap(
Func1super T,? extends K> keySelector,
Func1super T,? extends V> valueSelector)
public final Observable>> toMultimap(
Func1super T,? extends K> keySelector,
Func1super T,? extends V> valueSelector,
Func0extends java.util.Map>> mapFactory)
public final Observable>> toMultimap(
Func1super T,? extends K> keySelector,
Func1super T,? extends V> valueSelector,
Func0extends java.util.Map>> mapFactory,
Func1super K,? extends java.util.Collection> collectionFactory) 下面是通过 age 来分组 Person 的实现:
Observable values = Observable.just(
new Person("Will", 35),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMultimap(
person -> person.age,
person -> person.name)
.subscribe(new PrintSubscriber("toMap")); 结果:
toMap: {35=[Will, Saul], 40=[Nick]}
toMap: CompletedtoMultimap 的参数和 toMap 类似,最后一个 collectionFactory 参数是用来创建 value 的集合对象的,collectionFactory 使用 key 作为参数,这样你可以根据 key 来做不同的处理。下面示例代码中没有使用这个 key 参数:
Observable values = Observable.just(
new Person("Will", 35),
new Person("Nick", 40),
new Person("Saul", 35)
);
values
.toMultimap(
person -> person.age,
person -> person.name,
() -> new HashMap(),
(key) -> new ArrayList()) // 没有使用这个 key 参数
.subscribe(new PrintSubscriber("toMap")); 注意事项
这些操作函数都有非常有限的用法。这些函数只是用来给初学者把数据收集到集合中使用的,并且内部使用传统的方式来处理数据。这些方式不应该在实际项目中实现,因为他们和使用 Rx 的理念并不相符。
groupBy
groupBy 是 toMultimap 函数的 Rx 方式的实现。groupBy 根据每个源Observable 发射的值来计算一个 key, 然后为每个 key 创建一个新的 Observable并把key 一样的值发射到对应的新 Observable 中。
public final Observable> groupBy(Func1super T,? extends K> keySelector) 
返回的结果为 GroupedObservable。 每次发现一个新的key,内部就生成一个新的 GroupedObservable并发射出来。和普通的 Observable 相比 多了一个 getKey 函数来获取 分组的 key。来自于源Observable中的值会被发射到对应 key 的 GroupedObservable 中。
嵌套的 Observable 导致方法的定义比较复杂,但是提供了随时发射数据的优势,没必要等源Observable 发射完成了才能返回数据。
下面的示例中使用了一堆单词作为源Observable的数据,然后根据每个单词的首字母作为分组的 key,最后把每个分组的 最后一个单词打印出来:
Observable values = Observable.just(
"first",
"second",
"third",
"forth",
"fifth",
"sixth"
);
values.groupBy(word -> word.charAt(0))
.subscribe(
group -> group.last()
.subscribe(v -> System.out.println(group.getKey() + ": " + v))
); 上面的代码使用了嵌套的 Subscriber,在 Rx 前传 中 我们介绍了 Rx 功能之一就是为了避免嵌套回调函数,所以下面演示了如何避免嵌套:
Observable values = Observable.just(
"first",
"second",
"third",
"forth",
"fifth",
"sixth"
);
values.groupBy(word -> word.charAt(0))
.flatMap(group ->
group.last().map(v -> group.getKey() + ": " + v)
)
.subscribe(v -> System.out.println(v)); 结果:
s: sixth
t: third
f: fifth下一章会介绍这里使用的 map 和 flatMap 操作函数。
Nested observables
嵌套的 Observable 可能一开始看起来比较迷糊,但是他们有很多使用的场景。很好很强大,比如:
- Partitions of Data (分区数据)
你可以把来至于一个源Observable 的数据分为多个 Observable并分别给多个资源去处理。分区数据对于聚合数据也是有用的,通常使用 groupBy 函数来实现该功能。 - 在线游戏服务器
例如魔兽世界有很多服务器。每个新的值代表一个服务器上线了。而嵌套的 Observable 值是每个服务器的延迟时间,这样用户就可以看到每个服务器是否可用的信息的。如果一个服务器挂了,则嵌套的Observable通过发射一个完成信号标记服务器挂了。 - 金融数据流
交易市场每天都有开市和闭市的时间。当开市了就提供每个市场的价格信息流,闭市了就标记完成了。 - 聊天室
用户可以加入一个聊天室(源 Observable 里面有很多个聊天室),加入聊天室后可以留言(聊天室本身为嵌套的 Observable,在该 Observable中保存留言数据),然后还可以离开聊天室(结束 嵌套的 Observable 数据流)。 - 文件监视器
文件夹中的文件可以监视其修改操作。嵌套的 Observable 可以代表对每个文件所做的操作,删除文件代表嵌套的 Observable 完成了。
nest
当和 嵌套的 Observable 打交道的时候,就要使用 nest 函数了。nest 函数把一个普通的非 嵌套 Observable 变为一个嵌套的 Observable。 nest 把一个源 Observable 变为一个嵌套的 Observable 发射出去就结束了。
image
Observable.range(0, 3)
.nest()
.subscribe(ob -> ob.subscribe(System.out::println));结果:
0
1
2上面的示例只是为了演示 nest 操作,实际没球用!! 如果从其他地方获取了一个非 嵌套的 Observable,但是使用的时候需要使用 嵌套的 Observable,则你可以通过 nest 函数来转换。
本文出自 云在千峰 http://blog.chengyunfeng.com/?p=962