掌握Redis分布式锁的正确姿势

本文中案例都会在上传到git上,请放心浏览
git地址:https://github.com/muxiaonong/Spring-Cloud/tree/master/order-lock
本文会使用到 三台 redis 独立服务器,可以自行提前搭建好
前言
在Java中,我们对于锁会比较熟悉,常用的有 synchronized、Lock锁,在java并发编程中,我们通过锁,来实现当多个线程竞争同一个共享资源或者变量而造成的数据不一致的问题,但是JVM锁只能针对于单个应用服务,随着我们业务的发展需要,单体单机部署的系统早已演化成分布式系统,由于分布式系统的多线程、多进程而且分布在不同的机器上,这个时候JVM锁的并发控制就没有效果了,为了解决跨JVM锁并且能够控制共享资源的访问,于是有了分布式锁的诞生。
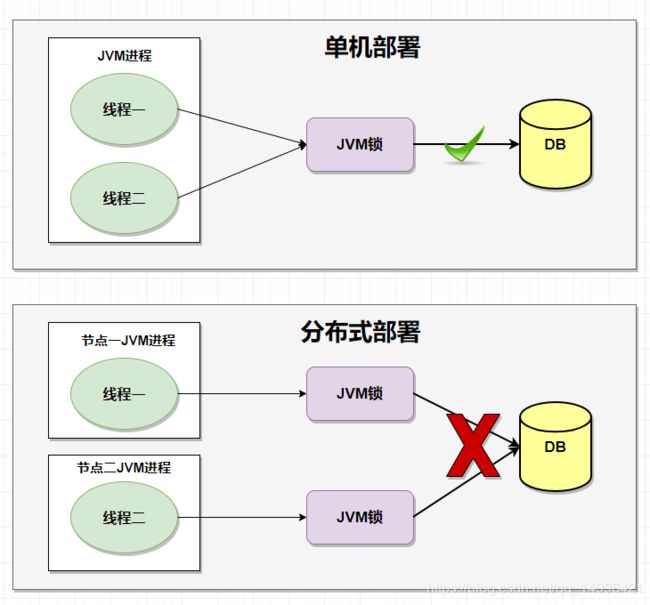
什么是分布式锁
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。在分布式系统中,常常需要协调他们的动作。如果不同的系统或是同一个系统的不同主机之间共享了一个或一组资源,那么访问这些资源的时候,往往需要互斥来防止彼此干扰来保证一致性,在这种情况下,便需要使用到分布式锁
为什么JVM锁在分布式下不可以呢?
我们通过代码来看一下就知道,为什么集群下jvm锁是不可靠的呢?我们模拟一下商品抢购的场景,A服务有十个用户去抢购这个商品,B服务有十个用户去抢购这个商品,当有其中一个用户抢购成功后,其他用户不可以在对这个商品进行下单操作,那么到底是A服务会抢到还是B服务会抢到这个商品呢,我们来看一下
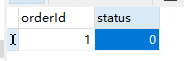
当其中有一个用户抢购成功后,status会变成1
GrabService:
public interface GrabService {
/**
* 商品抢单
* @param orderId
* @param driverId
* @return
*/
public ResponseResult grabOrder(int orderId, int driverId);
}
GrabJvmLockServiceImpl:
@Service("grabJvmLockService")
public class GrabJvmLockServiceImpl implements GrabService {
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId, int driverId) {
String lock = (orderId+"");
synchronized (lock.intern()) {
try {
System.out.println("用户:"+driverId+" 执行下单逻辑");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("用户:"+driverId+" 下单成功");
}else {
System.out.println("用户:"+driverId+" 下单失败");
}
} finally {
}
}
return null;
}
}
OrderService :
public interface OrderService {
public boolean grab(int orderId, int driverId);
}
OrderServiceImpl :
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private OrderMapper mapper;
public boolean grab(int orderId, int driverId) {
Order order = mapper.selectByPrimaryKey(orderId);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
if(order.getStatus().intValue() == 0) {
order.setStatus(1);
mapper.updateByPrimaryKeySelective(order);
return true;
}
return false;
}
}
这里我们模拟集群环境,启动两个端口,8004和8005进行访问
这里我们用jmeter进行测试
如果不会jmeter的可以看我之前对tomcat进行压测的文章:tomcat优化
项目启动顺序:先启动 Server-eureka注册中心、在启动 8004和8005端口
测试结果:

这里我们可以看到 8004 服务和 8005 服务 同时都有一个用户去下单成功这个商品,但是这个商品只能有一个用户能够去抢到,因此jvm锁如果是在集群或分布式下,是无法保证访问共享变量的数据同时只有一个线程访问的,无法解决分布式,集群环境的问题。所以需要使用到分布锁。
分布式锁三种实现方式
分布式锁的实现方式总共有三种:
- 基于数据库实现分布式锁
- 基于缓存(Redis)实现分布式锁
- 基于Zookeeper实现分布式锁
今天,我们主要讲的是基于Redis实现的分布式锁
reids实现分布式锁有三种方式
1、基于redis的 SETNX 实现分布式锁
2、Redisson实现分布式锁
4、使用redLock实现分布式锁
目录结构:
方式一:基于 SETNX 实现分布式锁
将key的值设为value ,当且仅当key不存在。
若给定的key已经存在,则SETNX不做任何动作。
setnx:当key存在,不做任何操作,key不存在,才设置
加锁:
SET orderId driverId NX PX 30000
上面的命令如果执行成功,则客户端成功获取到了锁,接下来就可以访问共享资源了;而如果上面的命令执行失败,则说明获取锁失败。
释放锁:
关键,判断是不是自己加的锁。
GrabService :
public interface GrabService {
/**
* 商品抢单
* @param orderId
* @param driverId
* @return
*/
public ResponseResult grabOrder(int orderId, int driverId);
}
GrabRedisLockServiceImpl :
@Service("grabRedisLockService")
public class GrabRedisLockServiceImpl implements GrabService {
@Autowired
StringRedisTemplate stringRedisTemplate;
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId , int driverId){
//生成key
String lock = "order_"+(orderId+"");
/*
* 情况一,如果锁没执行到释放,比如业务逻辑执行一半,运维重启服务,或 服务器挂了,没走 finally,怎么办?
* 加超时时间
*/
// boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId+"");
// if(!lockStatus) {
// return null;
// }
/*
* 情况二:加超时时间,会有加不上的情况,运维重启
*/
// boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId+"");
// stringRedisTemplate.expire(lock.intern(), 30L, TimeUnit.SECONDS);
// if(!lockStatus) {
// return null;
// }
/*
* 情况三:超时时间应该一次加,不应该分2行代码,
*
*/
boolean lockStatus = stringRedisTemplate.opsForValue().setIfAbsent(lock.intern(), driverId+"", 30L, TimeUnit.SECONDS);
if(!lockStatus) {
return null;
}
try {
System.out.println("用户:"+driverId+" 执行抢单逻辑");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("用户:"+driverId+" 抢单成功");
}else {
System.out.println("用户:"+driverId+" 抢单失败");
}
} finally {
/**
* 这种释放锁有,可能释放了别人的锁。
*/
// stringRedisTemplate.delete(lock.intern());
/**
* 下面代码避免释放别人的锁
*/
if((driverId+"").equals(stringRedisTemplate.opsForValue().get(lock.intern()))) {
stringRedisTemplate.delete(lock.intern());
}
}
return null;
}
}
这里可能会有人问,如果我业务的执行时间超过了锁释放的时间,会怎么办呢?我们可以使用守护线程,只要我们当前线程还持有这个锁,到了10S的时候,守护线程会自动对该线程进行加时操作,会续上30S的过期时间,直到把锁释放,就不会在进行续约了,开启一个子线程,原来时间是N,每隔N/3,在去续上N
关注点:
- key,是我们的要锁的目标,比如订单ID。
- driverId 是由我们的商品ID,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的。即一个订单被一个用户抢。
- NX表示只有当orderId不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。
- PX 30000表示这个锁有一个30秒的自动过期时间。当然,这里30秒只是一个例子,客户端可以选择合适的过期时间。
- 这个锁必须要设置一个过期时间。 否则的话,当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分区,导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了。antirez在后面的分析中也特别强调了这一点,而且把这个过期时间称为锁的有效时间(lock validity time)。获得锁的客户端必须在这个时间之内完成对共享资源的访问。
- 此操作不能分割。
SETNX orderId driverId
EXPIRE orderId 30
虽然这两个命令和前面算法描述中的一个SET命令执行效果相同,但却不是原子的。如果客户端在执行完SETNX后崩溃了,那么就没有机会执行EXPIRE了,导致它一直持有这个锁。造成死锁。
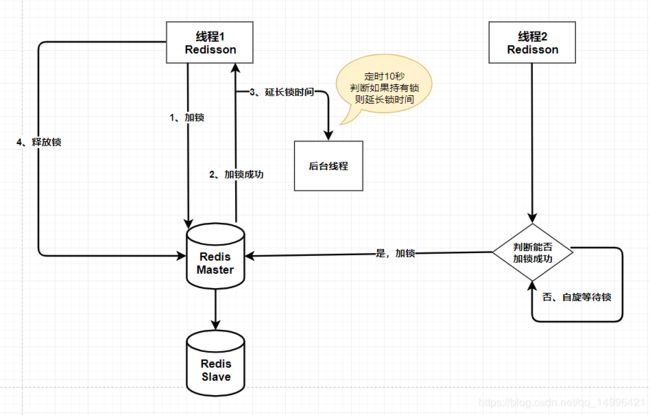
方式二:基于redisson实现分布式锁
流程图:
代码实现:
@Service("grabRedisRedissonService")
public class GrabRedisRedissonServiceImpl implements GrabService {
@Autowired
RedissonClient redissonClient;
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId , int driverId){
//生成key
String lock = "order_"+(orderId+"");
RLock rlock = redissonClient.getLock(lock.intern());
try {
// 此代码默认 设置key 超时时间30秒,过10秒,再延时
rlock.lock();
System.out.println("用户:"+driverId+" 执行抢单逻辑");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("用户:"+driverId+" 抢单成功");
}else {
System.out.println("用户:"+driverId+" 抢单失败");
}
} finally {
rlock.unlock();
}
return null;
}
}
关注点:
-
redis故障问题。
如果redis故障了,所有客户端无法获取锁,服务变得不可用。为了提高可用性。我们给redis 配置主从。当master不可用时,系统切换到slave,由于Redis的主从复制(replication)是异步的,这可能导致丧失锁的安全性1.客户端1从Master获取了锁。
2.Master宕机了,存储锁的key还没有来得及同步到Slave上。
3.Slave升级为Master。
4.客户端2从新的Master获取到了对应同一个资源的锁。客户端1和客户端2同时持有了同一个资源的锁。锁的安全性被打破。
-
锁的有效时间(lock validity time),设置成多少合适?如果设置太短的话,锁就有可能在客户端完成对于共享资源的访问之前过期,从而失去保护;如果设置太长的话,一旦某个持有锁的客户端释放锁失败,那么就会导致所有其它客户端都无法获取锁,从而长时间内无法正常工作。应该设置稍微短一些,如果线程持有锁,开启线程自动延长有效期
方式三:基于RedLock实现分布式锁
针对于以上两点,antirez设计了Redlock算法
Redis的作者antirez给出了一个更好的实现,称为Redlock,算是Redis官方对于实现分布式锁的指导规范。Redlock的算法描述就放在Redis的官网上:
https://redis.io/topics/distlock
目的:对共享资源做互斥访问
因此antirez提出了新的分布式锁的算法Redlock,它基于N个完全独立的Redis节点(通常情况下N可以设置成5),意思就是N个Redis数据不互通,类似于几个陌生人
代码实现:
@Service("grabRedisRedissonRedLockLockService")
public class GrabRedisRedissonRedLockLockServiceImpl implements GrabService {
@Autowired
private RedissonClient redissonRed1;
@Autowired
private RedissonClient redissonRed2;
@Autowired
private RedissonClient redissonRed3;
@Autowired
OrderService orderService;
@Override
public ResponseResult grabOrder(int orderId , int driverId){
//生成key
String lockKey = (RedisKeyConstant.GRAB_LOCK_ORDER_KEY_PRE + orderId).intern();
//红锁
RLock rLock1 = redissonRed1.getLock(lockKey);
RLock rLock2 = redissonRed2.getLock(lockKey);
RLock rLock3 = redissonRed2.getLock(lockKey);
RedissonRedLock rLock = new RedissonRedLock(rLock1,rLock2,rLock3);
try {
rLock.lock();
// 此代码默认 设置key 超时时间30秒,过10秒,再延时
System.out.println("用户:"+driverId+" 执行抢单逻辑");
boolean b = orderService.grab(orderId, driverId);
if(b) {
System.out.println("用户:"+driverId+" 抢单成功");
}else {
System.out.println("用户:"+driverId+" 抢单失败");
}
} finally {
rLock.unlock();
}
return null;
}
}
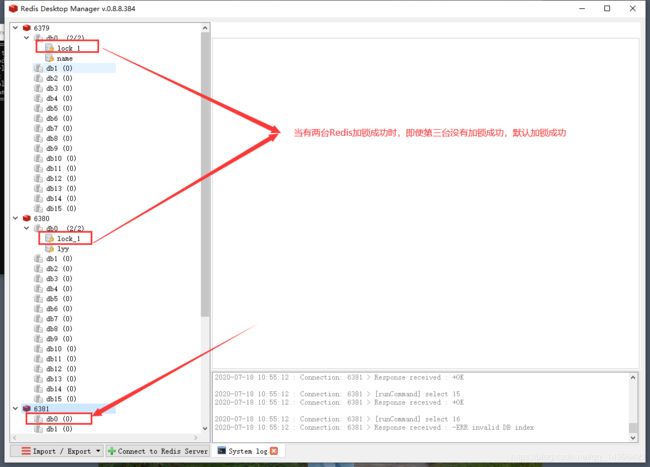
运行Redlock算法的客户端依次执行下面各个步骤,来完成 获取锁 的操作:
- 获取当前时间(毫秒数)。
- 按顺序依次向N个Redis节点执行 获取锁 的操作。这个获取操作跟前面基于单Redis节点的 获取锁 的过程相同,包含value driverId ,也包含过期时间(比如
PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个 获取锁 的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。 - 客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有
- 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,比如:五台机器如果加锁成功三台就默认加锁成功,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败
- 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
- 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起 释放锁 的操作(即前面介绍的Redis Lua脚本)。
上面描述的只是 获取锁 的过程,而 释放锁 的过程比较简单:客户端向所有Redis节点发起 释放锁 的操作,不管这些节点当时在获取锁的时候成功与否。
总结
到这里redis分布式锁就讲完了,具体使用哪一种类型的分布式锁需要看公司业务的,流量大的可以使用RedLock实现分布式锁,流量小的可以使用redisson,后面会讲解Zookeeper实现分布式锁,喜欢的小伙伴可以关注我,对本文内容有疑问或者问题的同学可以留言,小农看到了会第一时间回复,谢谢大家,大家加油