java导入excel的各自方式分析之easyexcel详解(大文档excel导入避免内存溢出)
导入excel进行数据解析,是日常项目中很经常见到的需求。
网上有各种解决方案,现在进行汇总,踩完了坑。
目前常见的导入excel的工具库有poi和jxl
poi功能丰富,但是较为复杂,jxl简单,但是功能不丰富。
但是poi和jxl的导入解析,都有一个致命的问题,就是在大数据量的时候容易内存溢出。当导入6万条数据的时候,内存能占用到100M,如果有20个人一起导入,服务很可能就挂了。
在生产环境是很危险的。
原因:
excel内部存储数据其实也是以xml形式存储。poi和jxl一般情况下都是以DOM形式解析excel。会一次性读取整个xml,然后在内存中存储为树形数据结构,每个xml标记为一个node(节点)。
这样做的好处就是处理简单,处理哪个数据就get哪个节点。
但是同样,这样会消耗大量内存。
为了解决这个问题,poi提供了一种sax形式的解析excel, sax为simple api xml 是一种以流的形式读取xml的接口。 即读入一部分,就处理一部分,而不是一次性读入整个文档。
easyexcel是阿里开源的一个解析xml的框架,底层也是用的poi的sax形式解析,但是封装了一层,简化了操作,对用户使用友好。且在导入的时候 ,丢弃了了文档的样式内容并且解压在硬盘完成,进一步减少了内存的占用
使用前最好咨询下最新版,或者到mvn仓库搜索先easyexcel的最新版。
首先引入
com.alibaba
easyexcel
1.0.0-RELEASE
easyexcel核心功能
读任意大小的03、07版Excel不会OO]
读Excel自动通过注解,把结果映射为java模型
读Excel支持多sheet
读Excel时候是否对Excel内容做trim()增加容错
写小量数据的03版Excel(不要超过2000行)
写任意大07版Excel不会OOM
写Excel通过注解将表头自动写入Excel
写Excel可以自定义Excel样式 如:字体,加粗,表头颜色,数据内容颜色
写Excel到多个不同sheet
写Excel时一个sheet可以写多个Table
写Excel时候自定义是否需要写表头
使用easyexcel解析03、07版本的Excel只是ExcelTypeEnum不同,其他使用完全相同,使用者无需知道底层解析的差异。
无java模型直接把excel解析的每行结果以List返回 在ExcelListener获取解析结果
读excel代码示例如下:
@Test
public void testExcel2003NoModel() {
InputStream inputStream = getInputStream("loan1.xls");
try {
// 解析每行结果在listener中处理
ExcelListener listener = new ExcelListener();
ExcelReader excelReader = new ExcelReader(inputStream, ExcelTypeEnum.XLS, null, listener);
excelReader.read();
} catch (Exception e) {
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
ExcelListener示例代码如下:
/* 解析监听器,
* 每解析一行会回调invoke()方法。
* 整个excel解析结束会执行doAfterAllAnalysed()方法
*
* 下面只是我写的一个样例而已,可以根据自己的逻辑修改该类。
* @author jipengfei
* @date 2017/03/14
*/
public class ExcelListener extends AnalysisEventListener {
//自定义用于暂时存储data。
//可以通过实例获取该值
private List有java模型映射
java模型写法如下:
public class LoanInfo extends BaseRowModel {
@ExcelProperty(index = 0)
private String bankLoanId;
@ExcelProperty(index = 1)
private Long customerId;
@ExcelProperty(index = 2,format = "yyyy/MM/dd")
private Date loanDate;
@ExcelProperty(index = 3)
private BigDecimal quota;
@ExcelProperty(index = 4)
private String bankInterestRate;
@ExcelProperty(index = 5)
private Integer loanTerm;
@ExcelProperty(index = 6,format = "yyyy/MM/dd")
private Date loanEndDate;
@ExcelProperty(index = 7)
private BigDecimal interestPerMonth;
@ExcelProperty(value = {"一级表头","二级表头"})
private BigDecimal sax;
}
@ExcelProperty(index = 3)数字代表该字段与excel对应列号做映射,也可以采用 @ExcelProperty(value = {“一级表头”,“二级表头”})用于解决不确切知道excel第几列和该字段映射,位置不固定,但表头的内容知道的情况。
@Test
public void testExcel2003WithReflectModel() {
InputStream inputStream = getInputStream("loan1.xls");
try {
// 解析每行结果在listener中处理
AnalysisEventListener listener = new ExcelListener();
ExcelReader excelReader = new ExcelReader(inputStream, ExcelTypeEnum.XLS, null, listener);
excelReader.read(new Sheet(1, 2, LoanInfo.class));
} catch (Exception e) {
} finally {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
带模型解析与不带模型解析主要在构造new Sheet(1, 2, LoanInfo.class)时候包含class。Class需要继承BaseRowModel暂时BaseRowModel没有任何内容,后面升级可能会增加一些默认的数据。
写Excel
每行数据是List无表头
OutputStream out = new FileOutputStream("/Users/jipengfei/77.xlsx");
try {
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX,false);
//写第一个sheet, sheet1 数据全是List 无模型映射关系
Sheet sheet1 = new Sheet(1, 0);
sheet1.setSheetName("第一个sheet");
writer.write(getListString(), sheet1);
writer.finish();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
每行数据是一个java模型有表头----表头层级为一
生成Excel格式如下图

模型写法如下:
public class ExcelPropertyIndexModel extends BaseRowModel {
@ExcelProperty(value = "姓名" ,index = 0)
private String name;
@ExcelProperty(value = "年龄",index = 1)
private String age;
@ExcelProperty(value = "邮箱",index = 2)
private String email;
@ExcelProperty(value = "地址",index = 3)
private String address;
@ExcelProperty(value = "性别",index = 4)
private String sax;
@ExcelProperty(value = "高度",index = 5)
private String heigh;
@ExcelProperty(value = "备注",index = 6)
private String last;
}
@ExcelProperty(value = “姓名”,index = 0) value是表头数据,默认会写在excel的表头位置,index代表第几列。
@Test
public void test1() throws FileNotFoundException {
OutputStream out = new FileOutputStream("/Users/jipengfei/78.xlsx");
try {
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX);
//写第一个sheet, sheet1 数据全是List 无模型映射关系
Sheet sheet1 = new Sheet(1, 0,ExcelPropertyIndexModel.class);
writer.write(getData(), sheet1);
writer.finish();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
每行数据是一个java模型有表头----表头层级为多层级
生成Excel格式如下图:

java模型写法如下:
public class MultiLineHeadExcelModel extends BaseRowModel {
@ExcelProperty(value = {"表头1","表头1","表头31"},index = 0)
private String p1;
@ExcelProperty(value = {"表头1","表头1","表头32"},index = 1)
private String p2;
@ExcelProperty(value = {"表头3","表头3","表头3"},index = 2)
private int p3;
@ExcelProperty(value = {"表头4","表头4","表头4"},index = 3)
private long p4;
@ExcelProperty(value = {"表头5","表头51","表头52"},index = 4)
private String p5;
@ExcelProperty(value = {"表头6","表头61","表头611"},index = 5)
private String p6;
@ExcelProperty(value = {"表头6","表头61","表头612"},index = 6)
private String p7;
@ExcelProperty(value = {"表头6","表头62","表头621"},index = 7)
private String p8;
@ExcelProperty(value = {"表头6","表头62","表头622"},index = 8)
private String p9;
}
写Excel写法同上,只需将ExcelPropertyIndexModel.class改为MultiLineHeadExcelModel.class
一个Excel多个sheet写法
@Test
public void test1() throws FileNotFoundException {
OutputStream out = new FileOutputStream("/Users/jipengfei/77.xlsx");
try {
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX,false);
//写第一个sheet, sheet1 数据全是List 无模型映射关系
Sheet sheet1 = new Sheet(1, 0);
sheet1.setSheetName("第一个sheet");
writer.write(getListString(), sheet1);
//写第二个sheet sheet2 模型上打有表头的注解,合并单元格
Sheet sheet2 = new Sheet(2, 3, MultiLineHeadExcelModel.class, "第二个sheet", null);
sheet2.setTableStyle(getTableStyle1());
writer.write(getModeldatas(), sheet2);
//写sheet3 模型上没有注解,表头数据动态传入
List> head = new ArrayList>();
List headCoulumn1 = new ArrayList();
List headCoulumn2 = new ArrayList();
List headCoulumn3 = new ArrayList();
headCoulumn1.add("第一列");
headCoulumn2.add("第二列");
headCoulumn3.add("第三列");
head.add(headCoulumn1);
head.add(headCoulumn2);
head.add(headCoulumn3);
Sheet sheet3 = new Sheet(3, 1, NoAnnModel.class, "第三个sheet", head);
writer.write(getNoAnnModels(), sheet3);
writer.finish();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
一个sheet中有多个表格
@Test
public void test2() throws FileNotFoundException {
OutputStream out = new FileOutputStream("/Users/jipengfei/77.xlsx");
try {
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX,false);
//写sheet1 数据全是List 无模型映射关系
Sheet sheet1 = new Sheet(1, 0);
sheet1.setSheetName("第一个sheet");
Table table1 = new Table(1);
writer.write(getListString(), sheet1, table1);
writer.write(getListString(), sheet1, table1);
//写sheet2 模型上打有表头的注解
Table table2 = new Table(2);
table2.setTableStyle(getTableStyle1());
table2.setClazz(MultiLineHeadExcelModel.class);
writer.write(getModeldatas(), sheet1, table2);
//写sheet3 模型上没有注解,表头数据动态传入,此情况下模型field顺序与excel现实顺序一致
List> head = new ArrayList>();
List headCoulumn1 = new ArrayList();
List headCoulumn2 = new ArrayList();
List headCoulumn3 = new ArrayList();
headCoulumn1.add("第一列");
headCoulumn2.add("第二列");
headCoulumn3.add("第三列");
head.add(headCoulumn1);
head.add(headCoulumn2);
head.add(headCoulumn3);
Table table3 = new Table(3);
table3.setHead(head);
table3.setClazz(NoAnnModel.class);
table3.setTableStyle(getTableStyle2());
writer.write(getNoAnnModels(), sheet1, table3);
writer.write(getNoAnnModels(), sheet1, table3);
writer.finish();
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
##导出的例子
没有模板
OutputStream out = new FileOutputStream("/Users/jipengfei/2007.xlsx");
ExcelWriter writer = EasyExcelFactory.getWriter(out);
//写第一个sheet, sheet1 数据全是List 无模型映射关系
Sheet sheet1 = new Sheet(1, 3);
sheet1.setSheetName("第一个sheet");
//设置列宽 设置每列的宽度
Map columnWidth = new HashMap();
columnWidth.put(0,10000);columnWidth.put(1,40000);columnWidth.put(2,10000);columnWidth.put(3,10000);
sheet1.setColumnWidthMap(columnWidth);
sheet1.setHead(createTestListStringHead());
//or 设置自适应宽度
//sheet1.setAutoWidth(Boolean.TRUE);
writer.write1(createTestListObject(), sheet1);
//写第二个sheet sheet2 模型上打有表头的注解,合并单元格
Sheet sheet2 = new Sheet(2, 3, JavaModel1.class, "第二个sheet", null);
sheet2.setTableStyle(createTableStyle());
writer.write(createTestListJavaMode(), sheet2);
//写第三个sheet包含多个table情况
Sheet sheet3 = new Sheet(3, 0);
sheet3.setSheetName("第三个sheet");
Table table1 = new Table(1);
table1.setHead(createTestListStringHead());
writer.write1(createTestListObject(), sheet3, table1);
//写sheet2 模型上打有表头的注解
Table table2 = new Table(2);
table2.setTableStyle(createTableStyle());
table2.setClazz(JavaModel1.class);
writer.write(createTestListJavaMode(), sheet3, table2);
//关闭资源
writer.finish();
out.close();
有模板
InputStream inputStream = new BufferedInputStream(new FileInputStream("/Users/jipengfei/temp.xlsx"));
OutputStream out = new FileOutputStream("/Users/jipengfei/2007.xlsx");
ExcelWriter writer = EasyExcelFactory.getWriterWithTemp(inputStream,out,ExcelTypeEnum.XLSX,true);
//写第一个sheet, sheet1 数据全是List 无模型映射关系
Sheet sheet1 = new Sheet(1, 3);
sheet1.setSheetName("第一个sheet");
//设置列宽 设置每列的宽度
Map columnWidth = new HashMap();
columnWidth.put(0,10000);columnWidth.put(1,40000);columnWidth.put(2,10000);columnWidth.put(3,10000);
sheet1.setColumnWidthMap(columnWidth);
sheet1.setHead(createTestListStringHead());
//or 设置自适应宽度
//sheet1.setAutoWidth(Boolean.TRUE);
writer.write1(createTestListObject(), sheet1);
//写第二个sheet sheet2 模型上打有表头的注解,合并单元格
Sheet sheet2 = new Sheet(2, 3, JavaModel1.class, "第二个sheet", null);
sheet2.setTableStyle(createTableStyle());
writer.write(createTestListJavaMode(), sheet2);
//写第三个sheet包含多个table情况
Sheet sheet3 = new Sheet(3, 0);
sheet3.setSheetName("第三个sheet");
Table table1 = new Table(1);
table1.setHead(createTestListStringHead());
writer.write1(createTestListObject(), sheet3, table1);
//写sheet2 模型上打有表头的注解
Table table2 = new Table(2);
table2.setTableStyle(createTableStyle());
table2.setClazz(JavaModel1.class);
writer.write(createTestListJavaMode(), sheet3, table2);
//关闭资源
writer.finish();
out.close();
web下载实例写法
public class Down {
@GetMapping("/a.htm")
public void cooperation(HttpServletRequest request, HttpServletResponse response) {
ServletOutputStream out = response.getOutputStream();
ExcelWriter writer = new ExcelWriter(out, ExcelTypeEnum.XLSX, true);
String fileName = new String(("UserInfo " + new SimpleDateFormat("yyyy-MM-dd").format(new Date()))
.getBytes(), "UTF-8");
Sheet sheet1 = new Sheet(1, 0);
sheet1.setSheetName("第一个sheet");
writer.write0(getListString(), sheet1);
writer.finish();
response.setContentType("multipart/form-data");
response.setCharacterEncoding("utf-8");
response.setHeader("Content-disposition", "attachment;filename="+fileName+".xlsx");
out.flush();
}
}
}
测试数据分析


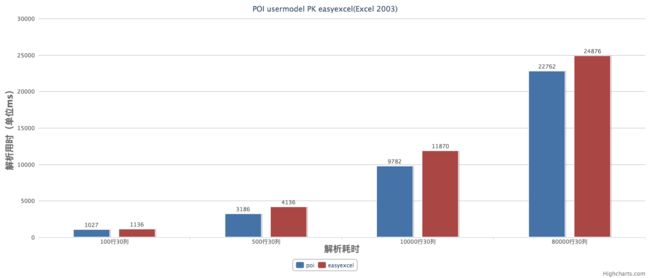
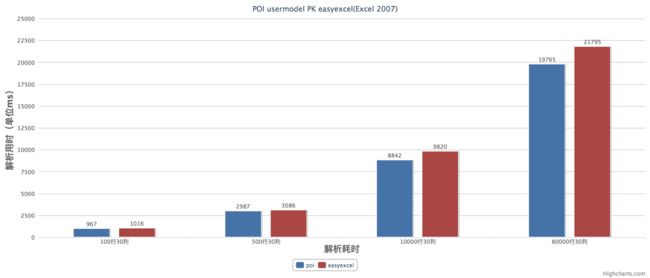
从上面的性能测试可以看出easyexcel在解析耗时上比poiuserModel模式弱了一些。主要原因是我内部采用了反射做模型字段映射,中间我也加了cache,但感觉这点差距可以接受的。但在内存消耗上差别就比较明显了,easyexcel在后面文件再增大,内存消耗几乎不会增加了。但poi userModel就不一样了,简直就要爆掉了。想想一个excel解析200M,同时有20个人再用估计一台机器就挂了。
感谢,感恩
参考文档汇总:
https://blog.csdn.net/weixin_42330218/article/details/81368034
https://blog.csdn.net/weixin_42330218/article/details/81458443
https://blog.csdn.net/l081307114/article/details/46009015
https://github.com/alibaba/easyexcel