语义分割总结 Semantic Segmentation Summary
图像语义分割: 机器自动从图像中分割出对象区域,并识别其中的内容
Object detection的输入是图像,输出是一个结果,或者说是一个值,一个概率值。
Semantic Segmentation所追求的是,输入是一张图片是,输出也是一张图片,学习像素到像素的映射
目前用于语义分割研究的两个最重要数据集是VOC2012和MSCOCO
语义分割的发展:
FCN->SegNet->DeconvNet->DilatedConvolutions->Hybrid Dilated Convolution ->DeepLab(v1&v2)->RefineNet->PSPNet->LargeKernel Matters->DeepLab(v3 & v3+)
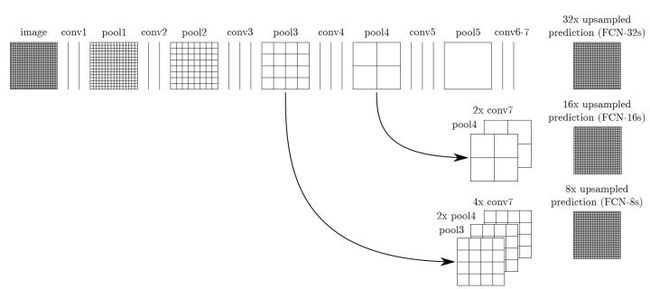
FCN网络
VGG16/ResNet101+upsampling(反卷积)+skip Layers
改进:
将端到端的卷积网络推广到语义分割中;
重新将预训练好的Imagenet网络用于分割问题中;
使用反卷积层进行上采样
提出了skip layers(跳跃连接)来改善上采样的粗糙程度。
步骤:
1、把传统网络如VGG等模型的最后FC层变成conv层,整张图片输入
2、为了得到与原图像size相同的分割图,需对最后一层特征图进行upsampling
3、采用skip layer的方法refine,用不同池化层结果进行upsampling,然后结合这些结果优化输出
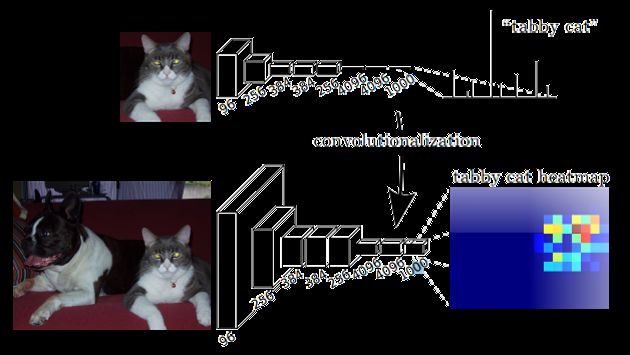
Skip layer(跳跃连接):
效果:

FCN进行upsampling的方法就是对feature map进行反卷积,低层和高层的feature map一起upsampling.
SegNet

整个结构就是一个encoder和一个decoder。前面的encoder就是采用的vgg-16的网络结构,而decoder和encoder基本上是对称结构
SegNet和FCN最大的不同就在于decoder的upsampling方法,上图结构中,注意,前面encoder每一个pooling层都把pooling indices保存,并且传递到后面对称的upsampling层(位置信息传到后面)
SegNet进行upsampling的方法和DeconvNet一样
DeconvNet
基于FCN改进,类似SegNet,添加了上池化uppooling操作

DeconvNet在后面卷积网络添加了两个FC层,用于加强对分类的预判,再到反卷积网络
在进行upsampling的时候,SegNet和DeconvNet基本上是一致的,都是进行了unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,pooling 之后需要接一个反卷积层.

反卷积
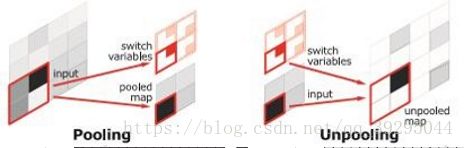
上池化的实现主要在于池化时记住输出值的位置,在上池化时再将这个值填回原来的位置,其他位置填0即OK。
DeconvNet进行upsampling的方法就是进行unpooling,就是需要根据之前pooling时的位置把feature map的值映射到新的feature map上,unpooling 之后需要接一个反卷积层.
DilatedConvolutions
扩大卷积核感受野来处理卷积,可以达到在不增加计算量的情况下增加感受域,弥补不进行池化处理后的精度问题
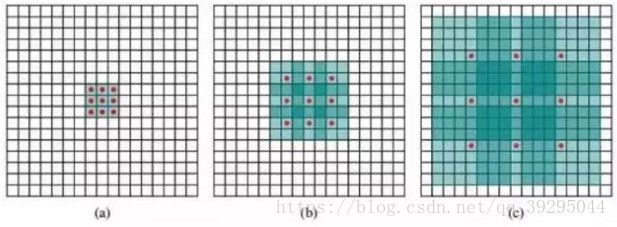
潜在问题 1:The Gridding Effect
假设我们仅仅多次叠加dilation rate 2 的 3 x 3 kernel 的话,则会出现这个问题:
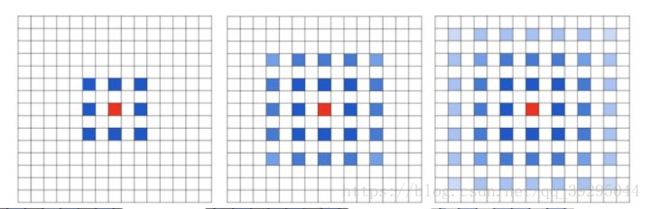
发现kernel 并不连续,也就是并不是所有的 pixel 都用来计算了,因此这里将信息看做 checker-board 的方式会损失信息的连续性。这对语义分割的像素级任务来说是致命的
潜在问题 2:Long-ranged information might be not relevant.
我们从dilated convolution 的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用大dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。如何同时处理不同大小的物体的关系,则是设计好 dilatedconvolution 网络的关键。
推出:HybridDilated Convolution
简单的例子: dilation rate [1, 2, 5] with 3 x 3 kernel (可行的方案)

CRF、MRF、G-CRF技术作为输出结果的优化后处理手段,解决像素与像素之间的逻辑关系的问题
Eg:“天空”和 “鸟” 这样的像素在物理空间是相邻的概率,应该要比 “天空” 和 “鱼” 这样像素相邻的概率大,那么天空的边缘就更应该判断为鸟而不是鱼(从概率的角度)
通过这样的技术优化求解,把明显不符合事实识别判断剔除,替换成合理的解释,得到对FCN等的图像语义预测结果的优化,生成最终的语义分割结果
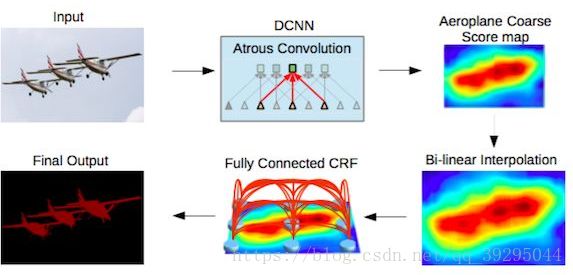
DeepLab v1 & v2:
VGG+Atrous convolution(空卷)+ASPP+Bi-linear+CRF
1、经过改进的DCNN(带空洞卷积和ASPP模块)得到粗略预测结果,即Aeroplane Coarse Score map
2、通过双线性插值扩大到原本大小,即Bi-linear Interpolation
3、通过全连接的CRF细化预测结果,得到最终输出Final Output
RefineNet:
1、残差卷积网络提取特征
2、通过MPR使用高分辨率的特征改善上一层输出的低分辨率特征
3、链式残差池化得到输出
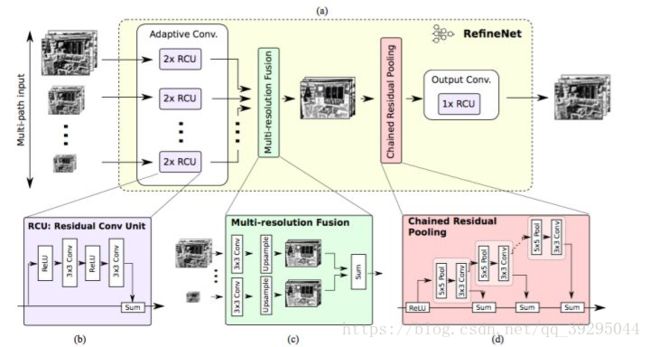
链式残差池化设计本意:
使用侧支上的一系列的pooling来获取背景信息(通常尺寸较大)。直连通路上的ReLU可以在不显著影响梯度流通的情况下提高后续pooling的性能,同时不让网络的训练对学习率很敏感。
PSPNet:
基于FCN和dilated work
1、CNN特征提取
2、通过金字塔池化模块,多子任务方式提取局部特征,上采样,结果融合一起形成最后的特征表达
3、把上一部的特征表达送到卷积层进行每一像素的预测
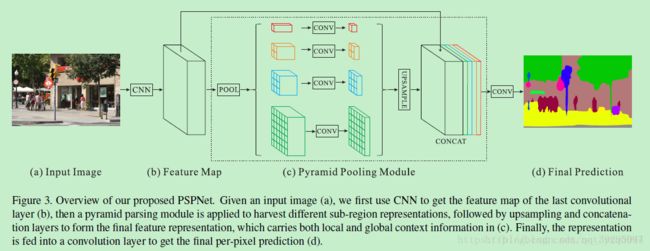
PPM:
全局平均池化有一定的局限。 改用金字塔池化模块:
四种不同的尺度 1x1, 2x2, 3x3, 6x6
每个尺度下的filter个数为1/N【N为卷积网络最后输出的通道个数】
pooling操作后,接1x1卷积
将不同尺度的特征上采样upsample
然后把金字塔池化出特征和全局池化特征进行concat串联所有特征,作为金字塔池化的特征输出
Large Kernel Matters:

multiscalar的score map不断融合相加
Global Convolutional Network 是增大kernel size获得更大的感受野,使用了 K x 1和1 x K的卷积核,计算量小,参数少
Boundery Refinement是增加边缘信息
Deeplab v3 & v3+:
deeplab v3 :基于deeplab v2,结合了Hybrid Dilated Convolution的思路,对DCNN层的ASPP引入多尺度空洞卷积改进
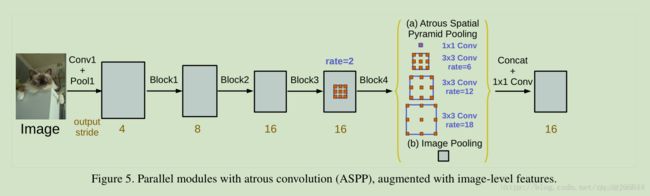
deeplab v3+:
通过添加一个简单但有效的解码器模块来扩展 Deeplabv3,改进为DeepLab-v3+,从而改善分割结果,特别是用于对象边界检测时。我们进一步将深度可分离的卷积应用于空洞空间金字塔池化(atrous spatial pyramid pooling)和解码器模块,从而形成了一个用于语义分割的更快速、更强大的编—解码器网络

Deeplab系列总结:
• DeepLabv1:结合之前的语义分割网络,使用空洞卷积(atrous convolution)进行语义分割
• DeepLabv2:基于 DeepLabv1 的优化,使用空洞空间金字塔池化(atrous spatial pyramid pooling,ASPP)对物体进行有效的分割,加上CRF优化
• DeepLabv3:采用多比例的带孔卷积级联或并行来捕获多尺度背景,基于图像特征优化 ASPP
• DeepLabv3+ :对 DeepLabv3 的扩展,包括一个简单而高效的改善分割结果的解码器模块