高效Python爬虫技巧
1.1 需要登录的爬虫
通常情况下,你会发现自己想要抽取数据的网站存在登录机制。大部分情况下,网站会要求你提供用户名和密码用于登录。你可以从http://web:9312/dynamic(从dev机器访问)或http://localhost:9312/ dynamic(从宿主机浏览器访问)找到我们要使用的例子。如果使用"user"作为用户名,"pass"作为密码的话,你就可以访问到包含3个房产页面链接的网页。不过现在的问题是,要如何使用Scrapy执行相同的操作?
让我们使用Google Chrome浏览器的开发者工具来尝试理解登录的工作过程(见图1.1)。首先,打开Network选项卡(1)。然后,填写用户名和密码,并单击Login(2)。如果用户名和密码正确,你将会看到包含3个链接的页面。如果用户名和密码不匹配,将会看到一个错误页。
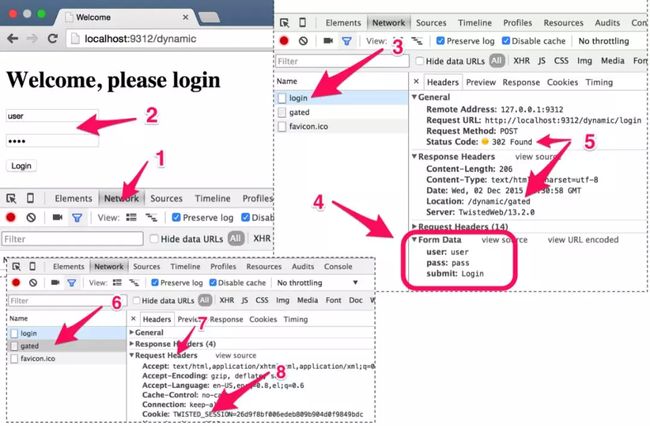
图1.1 登录网站时的请求和响应
当按下Login按钮时,会在Google Chrome浏览器开发者工具的Network选项卡中看到一个包含Request Method: POST的请求,其目的地址为http://localhost:9312/dynamic/login。
当你单击该请求时(3),可以看到发送给服务端的数据,包括Form Data(4),其中包含了我们输入的用户名和密码。这些数据都是以文本形式传输给服务端的。Chrome浏览器只是将其组织起来,向我们更好地显示这些数据。服务端的响应是302 Found(5),使我们跳转到一个新的页面:/dynamic/gated。该页面只有在登录成功后才会出现。如果尝试直接访问http://localhost:9312/dynamic/gated,而不输入正确的用户名和密码的话,服务端会发现你在作弊,并跳转到错误页,其地址是http:// localhost:9312/dynamic/error。服务端是如何知道你和你的密码的呢?如果你单击开发者工具左侧的gated(6),就会发现在Request Headers区域下面(7)设置了一个Cookie值(8)。
总之,即使是一个单一的操作,比如登录,也可能涉及包括POST请求和HTTP跳转的多次服务端往返。Scrapy能够自动处理大部分操作,而我们需要编写的代码也很简单。
我们从第3章中名为easy的爬虫开始,创建一个新的爬虫,命名为login,保留原有文件,并修改爬虫中的name属性(如下所示):
class LoginSpider(CrawlSpider):
name = 'login'
我们需要通过执行到http://localhost:9312/dynamic/login的POST请求,发送登录的初始请求。这将通过Scrapy的FormRequest类实现该功能。要想使用该类,首先需要引入如下模块。
from scrapy.http import FormRequest
然后,将start_urls语句替换为start_requests()方法。这样做是因为在本例中,我们需要从一些更加定制化的请求开始,而不仅仅是几个URL。更确切地说就是,我们从该函数中创建并返回一个FormRequest。
# Start with a login request
def start_requests(self):
return [
FormRequest(
"http://web:9312/dynamic/login",
formdata={"user": "user", "pass": "pass"}
)]
虽然听起来不可思议,但是CrawlSpider(LoginSpider的基类)默认的parse()方法确实处理了Response,并且仍然能够使用第3章中的Rule和LinkExtractor。我们只编写了非常少的额外代码,这是因为Scrapy为我们透明处理了Cookie,并且一旦我们登录成功,就会在后续的请求中传输这些Cookie,就和浏览器执行的方式一样。接下来可以像平常一样,使用scrapy crwal运行。
scrapy crawl login
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Redirecting (302) to <GET .../gated> from <POST .../login
DEBUG: Crawled (200) <GET .../data.php>
DEBUG: Crawled (200) <GET .../property_000001.html> (referer: .../data.
DEBUG: Scraped from <200 .../property_000001.html>
{'address': [u'Plaistow, London'],
'date': [datetime.datetime(2015, 11, 25, 12, 7, 27, 120119)],
'description': [u'features'],
'image_urls': [u'http://web:9312/images/i02.jpg'],
...
INFO: Closing spider (finished)
INFO: Dumping Scrapy stats:
{...
'downloader/request_method_count/GET': 4,
'downloader/request_method_count/POST': 1,
...
'item_scraped_count': 3,
我们可以在日志中看到从dynamic/login到dynamic/gated的跳转,然后就会像平时那样抓取Item了。在统计中,可以看到1个POST请求和4个GET请求(一个是前往dynamic/gated索引页,另外3个是房产页面)。
如果使用了错误的用户名和密码,将会跳转到一个没有任何项目的页面,并且此时爬取过程会被终止,如下面的执行情况所示。
scrapy crawl login
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Redirecting (302) to <GET .../dynamic/error > from <POST .../
dynamic/login>
DEBUG: Crawled (200) <GET .../dynamic/error>
...
INFO: Spider closed (closespider_itemcount)
这是一个简单的登录示例,用于演示基本的登录机制。大多数网站都会拥有一些更加复杂的机制,不过Scrapy也都能够轻松处理。比如,一些网站要求你在执行POST请求时,将表单页中的某些表单变量传输到登录页,以便确认Cookie是启用的,同样也会让你在尝试暴力破解成千上万次用户名/密码的组合时更加困难。图1.2所示即为此种情况的一个示例。

图1.2 使用一次性随机数的一个更加高级的登录示例的请求和响应情况
比如,当访问http://localhost:9312/dynamic/nonce时,你会看到一个看起来一样的页面,但是当使用Chrome浏览器的开发者工具查看时,会发现页面的表单中有一个叫作nonce的隐藏字段。当提交该表单时(提交到http://localhost:9312/ dynamic/nonce-login),除非你既传输了正确的用户名/密码,又提交了服务端在你访问该登录页时给你的nonce值,否则登录不会成功。你无法猜测该值,因为它通常是随机且一次性的。这就表示要想成功登录,现在就需要请求两次了。你必须先访问表单页,然后再访问登录页传输数据。当然,Scrapy同样拥有内置函数可以帮助我们实现这一目的。
我们创建了一个和之前相似的NonceLoginSpider爬虫。现在,在start_requests()中,将返回一个简单的Request(不要忘记引入该模块)到表单页面中,并通过设置其callback属性为处理方法parse_welcome()手动处理响应。在parse_welcome()中,使用了FormRequest对象的辅助方法from_response(),以创建从原始表单中预填充所有字段和值的FormRequest对象。FormRequest.from_response()粗略模拟了一次在页面的第一个表单上的提交单击,此时所有字段留空。
该方法对于我们来说非常有用,因为它能够毫不费力地原样包含表单中的所有隐藏字段。我们所需要做的就是使用formdata参数填充user和pass字段以及返回FormRequest。下面是其相关代码。
# Start on the welcome page
def start_requests(self):
return [
Request(
"http://web:9312/dynamic/nonce",
callback=self.parse_welcome)
]
# Post welcome page's first form with the given user/pass
def parse_welcome(self, response):
return FormRequest.from_response(
response,
formdata={"user": "user", "pass": "pass"}
)
我们可以像平时一样运行爬虫。
$ scrapy crawl noncelogin
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Crawled (200) <GET .../dynamic/nonce>
DEBUG: Redirecting (302) to <GET .../dynamic/gated > from <POST .../
dynamic/login-nonce>
DEBUG: Crawled (200) <GET .../dynamic/gated>
...
INFO: Dumping Scrapy stats:
{...
'downloader/request_method_count/GET': 5,
'downloader/request_method_count/POST': 1,
...
'item_scraped_count': 3,
可以看到,第一个GET请求前往/dynamic/nonce页面,然后是POST请求,跳转到/dynamic/nonce-login页面,之后像前面的例子一样跳转到/dynamic/gated页面。关于登录的讨论就到这里。该示例使用两个步骤完成登录。只要你有足够的耐心,就可以形成任意长链,来执行几乎所有的登录操作。
5.2 使用JSON API和AJAX页面的爬虫
有时,你会发现自己在页面寻找的数据无法从HTML页面中找到。比如,当访问http://localhost:9312/static/时(见图5.3),在页面任意位置右键单击inspect element(1, 2),可以看到其中包含所有常见HTML元素的DOM树。但是,当你使用scrapy shell请求,或是在Chrome浏览器中右键单击View Page Source(3, 4)时,则会发现该页面的HTML代码中并不包含关于房产的任何信息。那么,这些数据是从哪里来的呢?
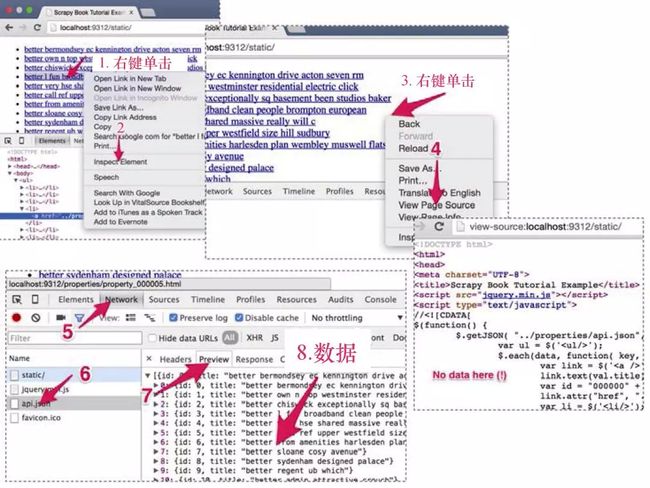
图1.3 动态加载JSON对象时的页面请求与响应
与平常一样,遇到这类例子时,下一步操作应当是打开Chrome浏览器开发者工具的Network选项卡,来看看发生了什么。在左侧的列表中,可以看到加载本页面时Chrome执行的请求。在这个简单的页面中,只有3个请求:static/是刚才已经检查过的请求;jquery.min.js用于获取一个流行的Javascript框架的代码;而api.json看起来会让我们产生兴趣。当单击该请求(6),并单击右侧的Preview选项卡(7)时,就会发现这里面包含了我们正在寻找的数据。实际上,http://localhost:9312/properties/api.json包含了房产的ID和名称(8),如下所示。
[{
"id": 0,
"title": "better set unique family well"
},
... {
"id": 29,
"title": "better portered mile"
}]
这是一个非常简单的JSON API的示例。更复杂的API可能需要你登录,使用POST请求,或返回更有趣的数据结构。无论在哪种情况下,JSON都是最简单的解析格式之一,因为你不需要编写任何XPath表达式就可以从中抽取出数据。
Python提供了一个非常好的JSON解析库。当我们执行import json时,就可以使用json.loads(response.body)解析JSON,将其转换为由Python原语、列表和字典组成的等效Python对象。
我们将第3章的manual.py拷贝过来,用于实现该功能。在本例中,这是最佳的起始选项,因为我们需要通过在JSON对象中找到的ID,手动创建房产URL以及Request对象。我们将该文件重命名为api.py,并将爬虫类重命名为ApiSpider,name属性修改为api。新的start_urls将会是JSON API的URL,如下所示。
start_urls = (
'http://web:9312/properties/api.json',
)
如果你想执行POST请求,或是更复杂的操作,可以使用前一节中介绍的start_requests()方法。此时,Scrapy将会打开该URL,并调用包含以Response为参数的parse()方法。可以通过import json,使用如下代码解析JSON对象。
def parse(self, response):
base_url = "http://web:9312/properties/"
js = json.loads(response.body)
for item in js:
id = item["id"]
url = base_url + "property_%06d.html" % id
yield Request(url, callback=self.parse_item)
前面的代码使用了json.loads(response.body),将Response这个JSON对象解析为Python列表,然后迭代该列表。对于列表中的每一项,我们将URL的3个部分(base_url、property_%06d以及.html)组合到一起。base_url是在前面定义的URL前缀。%06d是Python语法中非常有用的一部分,它可以让我们结合Python变量创建新的字符串。在本例中,%06d将会被变量id的值替换(本行结尾处%后面的变量)。id将会被视为数字(%d表示视为数字),并且如果不满6位,则会在前面加上0,扩展成6位字符。比如,id值为5,%06d将会被替换为000005,而如果id为34322,%06d则会被替换为034322。最终结果正是我们房产页面的有效URL。我们使用该URL形成一个新的Request对象,并像第3章一样使用yield。然后可以像平时那样使用scrapy crawl运行该示例。
scrapy crawl api
INFO: Scrapy 1.0.3 started (bot: properties)
...
DEBUG: Crawled (200) <GET ...properties/api.json>
DEBUG: Crawled (200) <GET .../property_000029.html>
...
INFO: Closing spider (finished)
INFO: Dumping Scrapy stats:
...
'downloader/request_count': 31, ...
'item_scraped_count': 30,
你可能会注意到结尾处的状态是31个请求——每个Item一个请求,以及最初的api.json的请求。
1.2.1 在响应间传参
很多情况下,在JSON API中会有感兴趣的信息,你可能想要将它们存储到Item中。在我们的示例中,为了演示这种情况,JSON API会在给定房产信息的标题前面加上"better"。比如,房产标题是"Covent Garden",API就会将标题写为"Better Covent Garden"。假设我们想要将这些"better"开头的标题存储到Items中,要如何将信息从parse()方法传递到parse_item()方法呢?
不要感到惊讶,通过在parse()生成的Request中设置一些东西,就能实现该功能。之后,可以从parse_item()接收到的Response中取得这些信息。Request有一个名为meta的字典,能够直接访问Response。比如在我们的例子中,可以在该字典中设置标题值,以存储来自JSON对象的标题。
title = item["title"]
yield Request(url, meta={"title": title},callback=self.parse_item)
在parse_item()内部,可以使用该值替代之前使用过的XPath表达式。
l.add_value('title', response.meta['title'],
MapCompose(unicode.strip, unicode.title))
你会发现我们不再调用add_xpath(),而是转为调用add_value(),这是因为我们在该字段中将不会再使用到任何XPath表达式。现在,可以使用scrapy crawl运行这个新的爬虫,并且可以在PropertyItems中看到来自api.json的标题。
1.3 30倍速的房产爬虫
有这样一种趋势,当你开始使用一个框架时,做任何事情都可能会使用最复杂的方式。你在使用Scrapy时也会发现自己在做这样的事情。在疯狂于XPath等技术之前,值得停下来想一想:我选择的方式是从网站中抽取数据最简单的方式吗?
如果你能从索引页中抽取出基本相同的信息,就可以避免抓取每个房源页,从而得到数量级的提升。
比如,在房产示例中,我们所需要的所有信息都存在于索引页中,包括标题、描述、价格和图片。这就意味着只抓取一个索引页,就能抽取其中的30个条目以及前往下一页的链接。通过爬取100个索引页,我们只需要100个请求,而不是3000个请求,就能够得到3000个条目。太棒了!
在真实的Gumtree网站中,索引页的描述信息要比列表页中完整的描述信息稍短一些。不过此时这种抓取方式可能也是可行的,甚至也能令人满意。
在我们的例子中,当查看任何一个索引页的HTML代码时,就会发现索引页中的每个房源都有其自己的节点,并使用itemtype="http://schema.org/Product"来表示。在该节点中,我们拥有与详情页完全相同的方式为每个属性注解的所有信息,如图5.4所示。
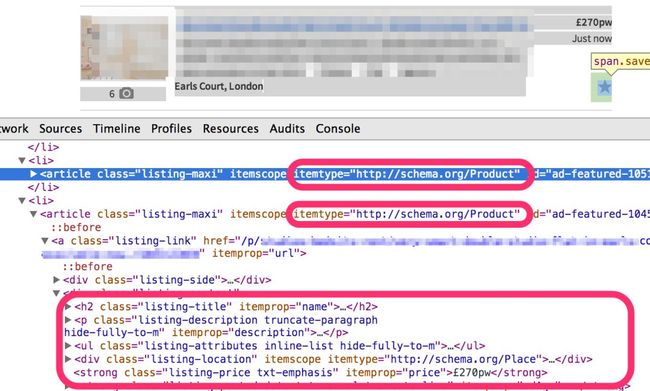
图5.4 从单一索引页抽取多个房产信息
我们在Scrapy shell中加载第一个索引页,并使用XPath表达式进行测试。
scrapy shell http://web:9312/properties/index_00000.html
在Scrapy shell中,尝试选取所有带有Product标签的内容:
p=response.xpath('//*[@itemtype="http://schema.org/Product"]')
len(p)
30
p
[<Selector xpath='//*[@itemtype="http://schema.org/Product"]' data=u'<li
class="listing-maxi" itemscopeitemt'...]
可以看到我们得到了一个包含30个Selector对象的列表,每个对象指向一个房源。在某种意义上,Selector对象与Response对象有些相似,我们可以在其中使用XPath表达式,并且只从它们指向的地方获取信息。唯一需要说明的是,这些表达式应该是相对XPath表达式。相对XPath表达式与我们之前看到的基本一样,不过在前面增加了一个'.'点号。举例说明,让我们看一下使用.//*[@itemprop="name"][1]/text()这个相对XPath表达式,从第4个房源抽取标题时是如何工作的。
selector = p[3]
selector
<Selector xpath='//*[@itemtype="http://schema.org/Product"]' ... '>
selector.xpath('.//*[@itemprop="name"][1]/text()').extract()
[u'l fun broadband clean people brompton european']
可以在Selector对象的列表中使用for循环,抽取索引页中全部30个条目的信息。
为了实现该目的,我们再一次从第3章的manual.py着手,将爬虫重命名为"fast",并重命名文件为fast.py。我们将复用大部分代码,只在parse()和parse_items()方法中进行少量修改。最新方法的代码如下。
def parse(self, response):
# Get the next index URLs and yield Requests
next_sel = response.xpath('//*[contains(@class,"next")]//@href')
for url in next_sel.extract():
yield Request(urlparse.urljoin(response.url, url))
# Iterate through products and create PropertiesItems
selectors = response.xpath(
'//*[@itemtype="http://schema.org/Product"]')
for selector in selectors:
yield self.parse_item(selector, response)
在代码的第一部分中,对前往下一个索引页的Request的yield操作的代码没有变化。唯一改变的内容在第二部分,不再使用yield为每个详情页创建请求,而是迭代选择器并调用parse_item()。其中,parse_item()的代码也和原始代码非常相似,如下所示。
def parse_item(self, selector, response):
# Create the loader using the selector
l = ItemLoader(item=PropertiesItem(), selector=selector)
# Load fields using XPath expressions
l.add_xpath('title', './/*[@itemprop="name"][1]/text()',
MapCompose(unicode.strip, unicode.title))
l.add_xpath('price', './/*[@itemprop="price"][1]/text()',
MapCompose(lambda i: i.replace(',', ''), float),
re='[,.0-9]+')
l.add_xpath('description',
'.//*[@itemprop="description"][1]/text()',
MapCompose(unicode.strip), Join())
l.add_xpath('address',
'.//*[@itemtype="http://schema.org/Place"]'
'[1]/*/text()',
MapCompose(unicode.strip))
make_url = lambda i: urlparse.urljoin(response.url, i)
l.add_xpath('image_urls', './/*[@itemprop="image"][1]/@src',
MapCompose(make_url))
# Housekeeping fields
l.add_xpath('url', './/*[@itemprop="url"][1]/@href',
MapCompose(make_url))
l.add_value('project', self.settings.get('BOT_NAME'))
l.add_value('spider', self.name)
l.add_value('server', socket.gethostname())
l.add_value('date', datetime.datetime.now())
return l.load_item()
我们所做的细微变更如下所示。
-
ItemLoader现在使用selector作为源,而不再是Response。这是ItemLoaderAPI一个非常便捷的功能,能够让我们从当前选取的部分(而不是整个页面)抽取数据。 -
XPath表达式通过使用前缀点号(.)转为相对XPath。
-
我们必须自己编辑
Item的URL。之前,response.url已经给出了房源页的URL。而现在,它给出的是索引页的URL,因为该页面才是我们要爬取的。我们需要使用熟悉的.//*[@itemprop="url"][1]/@href这个XPath表达式抽取出房源的URL,然后使用MapCompose处理器将其转换为绝对URL。
小的改变能够节省巨大的工作量。现在,我们可以使用如下代码运行该爬虫。
scrapy crawl fast -s CLOSESPIDER_PAGECOUNT=3
...
INFO: Dumping Scrapy stats:
'downloader/request_count': 3, ...
'item_scraped_count': 90,...
和预期一样,只用了3个请求,就抓取了90个条目。如果我们没有在索引页中获取到的话,则需要93个请求。这种方式太明智了!
如果你想使用scrapy parse进行调试,那么现在必须设置spider参数,如下所示。
$ scrapy parse --spider=fast http://web:9312/properties/index_00000.html
...
STATUS DEPTH LEVEL 1 <<<
# Scraped Items --------------------------------------------
[{'address': [u'Angel, London'],
... 30 items...
# Requests ---------------------------------------------------
[<GET http://web:9312/properties/index_00001.html>]
正如期望的那样,parse()返回了30个Item以及一个前往下一索引页的Request。请使用scrapy parse随意试验,比如传输--depth=2。
本文摘自《精通Python爬虫框架Scrapy》
