Python之Sklearn笔记——分类树
分类树
1.实例化,建立评估模型对象
2.通过模型接口训练模型
3.通过模型接口提取需要的信息
| from sklearn import tree | 导入需要的模块 |
|---|---|
| clf = tree.DecisionTreeClassifier() | 实例化 |
| result = clf.score(X_test,y_test) | 导入需要的模块 |
| clf = tree.DecisionTreeClassifier() | 导入测试集,从接口中调用需要的信息 |
wine数据库中有多个属性即wine.data,他们控制wine的分类即wine.target。当将他们分别作为表格的自变量,因变量打印出来,会得到以下结果
代码
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
wine = load_wine()
print(pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1))
结果如下(178组数据,13个属性,3个类别)
0 1 2 3 4 5 ... 8 9 10 11 12 0
0 14.23 1.71 2.43 15.6 127.0 2.80 ... 2.29 5.64 1.04 3.92 1065.0 0
1 13.20 1.78 2.14 11.2 100.0 2.65 ... 1.28 4.38 1.05 3.40 1050.0 0
2 13.16 2.36 2.67 18.6 101.0 2.80 ... 2.81 5.68 1.03 3.17 1185.0 0
3 14.37 1.95 2.50 16.8 113.0 3.85 ... 2.18 7.80 0.86 3.45 1480.0 0
4 13.24 2.59 2.87 21.0 118.0 2.80 ... 1.82 4.32 1.04 2.93 735.0 0
.. ... ... ... ... ... ... ... ... ... ... ... ... ..
173 13.71 5.65 2.45 20.5 95.0 1.68 ... 1.06 7.70 0.64 1.74 740.0 2
174 13.40 3.91 2.48 23.0 102.0 1.80 ... 1.41 7.30 0.70 1.56 750.0 2
175 13.27 4.28 2.26 20.0 120.0 1.59 ... 1.35 10.20 0.59 1.56 835.0 2
176 13.17 2.59 2.37 20.0 120.0 1.65 ... 1.46 9.30 0.60 1.62 840.0 2
177 14.13 4.10 2.74 24.5 96.0 2.05 ... 1.35 9.20 0.61 1.60 560.0 2
[178 rows x 14 columns]
建立决策树
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import pandas as pd
wine = load_wine()
X_train,X_test,Y_train,Y_test = train_test_split(wine.data,wine.target,test_size=0.3)
#导入数据,测试比例占30%
clf = tree.DecisionTreeClassifier(criterion='entropy')
#选取gini 或entropy 建立模型,生成决策树
clf = clf.fit(X_train,Y_train) # 训练ing
print(clf.predict(X_test)) # 输出预测值
print(Y_test)# 输出实际值
score = clf.score(X_test,Y_test) #求预测准确度
print(score)
输出结果如下
[1 1 1 1 0 1 1 0 1 1 1 2 0 1 0 1 1 2 1 1 1 0 1 0 0 1 0 2 2 0 2 1 1 1 1 0 0
1 0 0 0 0 1 0 0 1 2 2 0 0 2 1 0 0]
[1 1 1 1 0 1 1 0 1 1 1 2 0 1 0 1 1 2 1 1 1 0 1 0 0 1 0 2 2 1 2 1 1 1 1 0 0
1 0 0 0 0 1 0 0 1 2 2 0 0 2 1 0 0]
0.9814814814814815
运行多次的score的值都不一样,是因为X_train,X_test,Y_train,Y_test = train_test_split(wine.data,wine.target,test_size=0.3)
在分测试和训练集时是随机分的,所以最终的结果都不同
print(clf.feature_importances_)
#输出每个特征的贡献度对决策
'''
[0.015487 0.02560096 0. 0. 0.02086004 0.09438612
0.32703619 0. 0. 0.11427918 0. 0.02019919
0.38215133]
'''
print([*zip(feature_name,clf.feature_importances_)])
#将特征值和贡献度组合形成元组
'''
[('酒精', 0.0), ('苹果酸', 0.0952862829255716)
, ('灰', 0.0), ('灰的碱性', 0.0)
, ('镁', 0.0), ('总酚', 0.0)
, ('类黄酮', 0.44736728516836155)
, ('非黄烷类酚类', 0.0)
, ('花青素', 0.0), ('颜色强度', 0.1100323740621365)
, ('色调', 0.0), ('od280/od315稀释葡萄酒', 0.0)
, ('脯氨酸', 0.3473140578439304)]
'''
图片化决策树:
在pycharm中写好代码,复制粘贴至Jupyter。shift+回车可看到图片化的决策树
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import graphviz
wine = load_wine()
X_train,X_test,Y_train,Y_test = train_test_split(wine.data,wine.target,test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion='entropy'
,random_state=30 #控制拟合的稳定
,splitter='random') #控制分支的随机性,若果不加,每次会采用不纯度最低的节点进行分支
,max_depth = 3 #控制层数
, min_samples_leaf= 10 #控制叶子至少为10个
,min_samples_split= 20 #控制每个节点至少分20个
clf = clf.fit(X_train,Y_train)
feature_name = ['酒精','苹果酸','灰','灰的碱性','镁','总酚','类黄酮','非黄烷类酚类','花青素',
'颜色强度','色调','od280/od315稀释葡萄酒','脯氨酸']
dot_data = tree.export_graphviz(clf
,feature_names = feature_name
,class_names = ['红酒','白酒','葡萄酒']
,filled=True#控制框图的颜色填充
,rounded=True#控制框图的方圆
)
graph = graphviz.Source(dot_data)
graph
过拟合:在训练集上表现比测试集上表现得好(训练集不能代表整体)。
所以采用剪枝 :
max_depth = 3 #控制层数
min_samples_leaf= 10 #控制叶子至少为10个
min_samples_split= 20 #控制每个节点至少分20个
当不知道怎么调参数的时候
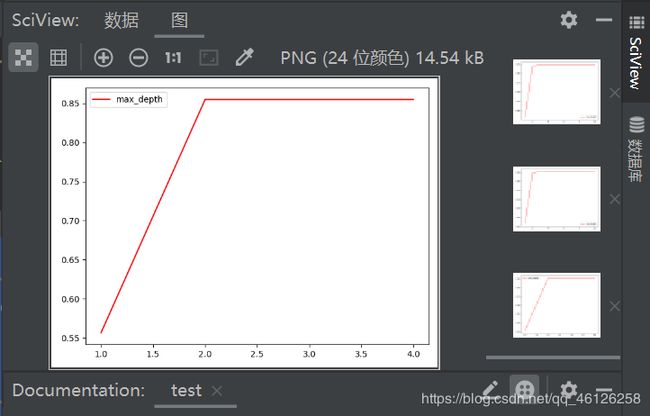
from sklearn import tree
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
wine = load_wine()
X_train,X_test,Y_train,Y_test = train_test_split(wine.data,wine.target,test_size=0.3)
test = []
for i in range(1,5):
clf = tree.DecisionTreeClassifier(criterion='entropy'
, random_state=40
, splitter='random'
, max_depth=i
, min_samples_leaf=10
, min_samples_split=20
)
clf = clf.fit(X_train, Y_train)
score = clf.score(X_train,Y_train)
test.append(score)
plt.plot(range(1,5),test,color="red",label="max_depth")
plt.legend()
plt.show()
得图片(推出max_depth=2.5时比较好)